📄 FUN-SSL: Full-Band Layer Followed by U-Net With Narrow-Band Layers for Multiple Moving Sound Source Localization
#声源定位 #U-Net #深度学习 #麦克风阵列
🔥 8.0/10 | 前25% | #声源定位 | #U-Net | #深度学习 #麦克风阵列
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文中未明确标注第一作者,作者列表按姓氏排序)
- 通讯作者:未说明(论文中未明确标注通讯作者)
- 作者列表:Yuseon Choi(光州科学技术院, Deeply Inc.)、Hyeonseung Kim(光州科学技术院)、Jewoo Jun(光州科学技术院)、Jong Won Shin(光州科学技术院)
💡 毒舌点评
亮点:论文的“性价比”极高,通过引入成熟的U-Net架构和深度可分离卷积,在模型参数量几乎不变的情况下,将计算复杂度(FLOPs)降低了近一半,同时定位精度还有小幅提升,这在面向实时部署的边缘计算场景下具有很强的吸引力。 短板:模型在更贴近真实、更具挑战性的LOCATA数据集上,性能相比基线IPDnet并未取得明显优势,这暗示其在极端复杂声学环境下的泛化能力或改进效果可能存在天花板,创新性稍显不足。
🔗 开源详情
- 代码:论文中未提及FUN-SSL的代码仓库链接。但提供了基线模型IPDnet的官方代码链接:https://github.com/Audio-WestlakeU/FN-SSL。
- 模型权重:未提及公开预训练模型权重。
- 数据集:论文使用了公开的模拟数据集生成方法和LOCATA挑战数据集,但未提供生成的模拟数据集本身。
- Demo:未提及在线演示。
- 复现材料:论文给出了充分的训练细节、网络参数配置(如通道数C1, C2)、以及关键的消融实验设计,为研究者复现工作提供了明确的指引。
- 论文中引用的开源项目:引用了IPDnet的官方代码仓库、gpuRIR(房间脉冲响应生成库)、LibriSpeech(语音语料库)、NOISEX-92(噪声数据库)。
📌 核心摘要
这篇论文针对多移动声源定位任务中现有高性能模型(如IPDnet)计算复杂度过高的问题,提出了一种名为FUN-SSL的新颖神经网络架构。其方法核心是将原有的全窄带处理块(FN-block)替换为“全带层+U-Net窄带层”(FUN-block),在保持全带处理以捕捉频间相关性的同时,利用U-Net结构在多个分辨率上高效地建模时序依赖。主要创新在于模块化设计和引入了模块间的跳跃连接以丰富信息流。实验结果表明,在模拟数据集上,FUN-SSL(0.8M参数)在粗粒度准确率(94.2%)、细粒度误差(1.9°)和误警率(5.8%)上均优于重新训练的IPDnet(0.7M参数,对应指标为93.0%、2.0°、7.1%),同时计算量(FLOPs)从19.4G/s降至10.8G/s。该工作的实际意义在于为资源受限设备(如麦克风阵列)上的实时多声源跟踪提供了更高效的解决方案。主要局限性在于其在真实世界LOCATA数据集上的性能与基线模型相当,未展现出显著优势。
🏗️ 模型架构
本文提出的FUN-SSL是一个端到端的深度学习模型,其整体架构和核心模块FUN-block的详细设计如下图所示。
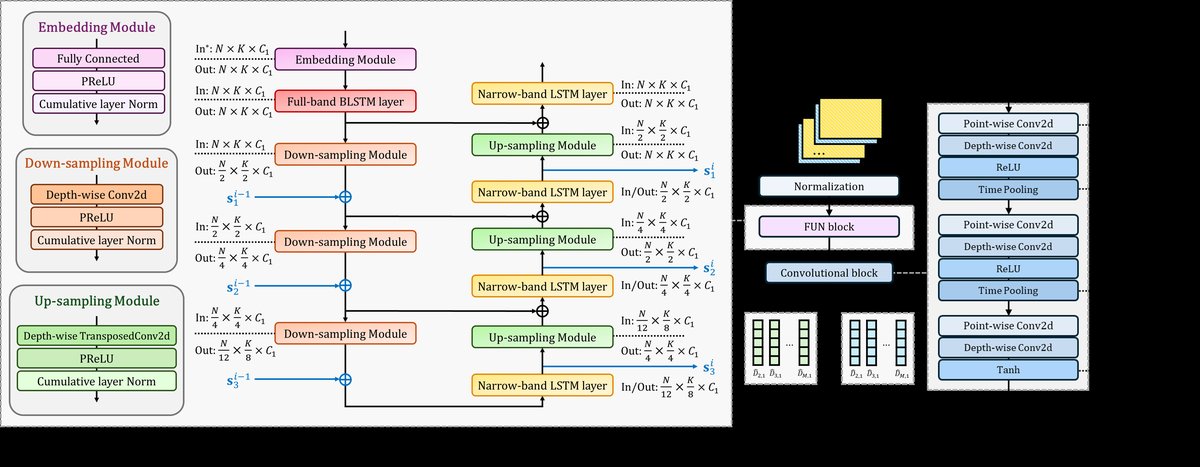
整体架构(图1上部):
- 输入:多通道音频信号的短时傅里叶变换(STFT)表示,形状为
N × K × 2M(帧数N,频率点K,麦克风数M,实虚部2)。输入经过拉普拉斯归一化。 - 处理主体:由一系列FUN块堆叠而成(论文中设置为B=2)。
- 输出头:最后一个FUN块的输出经过一个因果卷积块,其中使用了深度可分离卷积(先逐点卷积后深度卷积),最终输出各麦克风对关于Q个候选源的直接路径相对传递函数(DP-RTF)的实部和虚部估计值。
- 定位决策:估计的DP-RTF与所有可能方向的理论DP-RTF进行比对,以确定声源活动和到达方向(DoA)。
FUN块(图1下部详细结构):每个FUN块是模型的核心计算单元,旨在以更低的计算成本实现全带-窄带双路径处理。
- 嵌入模块:由全连接层、PReLU激活和累积层归一化(cLN)组成。其作用是通道混合,以补偿后续深度卷积仅在空间维度操作的局限。
- 全带层:一个双向LSTM(BLSTM)层,沿频率维度处理整个频谱,以捕捉不同频率之间的相关性。其输出
d_i^0进入U-Net结构。 - U-Net结构(多尺度窄带处理):
- 下采样路径:包含三个下采样模块,每个模块由一个2D深度卷积(核大小5×(2h_j),步长2×h_j)、PReLU和cLN组成。下采样因子依次为
h_1=2, h_2=2, h_3=3。这实现了时频表示的多分辨率降维。 - 窄带处理:在下采样路径的每个尺度以及瓶颈处,信号被送入一个窄带LSTM层,该LSTM沿时间轴操作,建模每个频率带内的时序动态。
- 上采样路径:包含三个上采样模块,每个模块由一个2D深度转置卷积(尺寸与对应下采样相反)、PReLU和cLN组成,用于将特征恢复到原始分辨率。
- 跳跃连接:U-Net内部跳跃连接将下采样路径的特征拼接到上采样路径的对应层。创新性的模块间跳跃连接:将当前第
i个FUN块的U-Net中,来自第i-1个块相同尺度的窄带LSTM输出s_{i-1}^j作为额外信息加到当前块下采样模块的输出d_i^j上(公式3),从而在不同处理块之间传递空间信息。
- 下采样路径:包含三个下采样模块,每个模块由一个2D深度卷积(核大小5×(2h_j),步长2×h_j)、PReLU和cLN组成。下采样因子依次为
- 输出:U-Net上��样路径最后一个窄带LSTM层的输出
s_i^0即为该FUN块的输出,并传递给下一个块。
💡 核心创新点
- 基于U-Net的多尺度窄带处理:用包含下采样-上采样路径和内部跳跃连接的U-Net替换了IPDnet中单一的窄带LSTM层。这使得模型能够以更少的参数和计算量,在多个时间分辨率上同时捕获时序依赖关系,平衡了全局上下文与局部细节。
- 高效的双路径模块设计(FUN块):保留了全带层处理频间关系的核心思想,但通过引入嵌入模块、深度卷积以及多尺度U-Net,将原始FN块的高计算复杂度显著降低。这是一种针对SSL任务特性的高效架构重新设计。
- 模块间多尺度跳跃连接:借鉴级联U-Net的思想,在相邻的FUN块之间,于U-Net的多个分辨率层级上建立跳跃连接。这允许空间和时频特征在深度方向上被更有效地重用和传播,丰富了后续模块的输入信息,增强了模型容量。
- 深度可分离卷积在输出端的应用:在最终的因果卷积块中,调整了深度可分离卷积的顺序(先逐点后深度),以适应上采样模块中深度卷积的特性,进一步优化了参数效率。
🔬 细节详述
- 训练数据:
- 模拟数据集:使用LibriSpeech语音与gpuRIR生成的房间脉冲响应卷结合成。混响时间(RT60)0.2-1.3秒,房间尺寸随机。最多2个静态/移动源,移动轨迹为带正弦扰动的直线。2个随机放置的麦克风(间距8cm)。噪声来自NOISEX-92的白噪声、嘈杂声、工厂噪声,信噪比-5至15 dB。训练集30万,验证集4千,测试集4千,每样本4.5秒。
- 真实数据集:LOCATA挑战数据集,使用固定麦克风阵列的两个移动源场景。
- 损失函数:排列不变训练(PIT)下的均方误差(MSE)损失,用于比较估计与目标的DP-RTF。
- 训练策略:
- 优化器:Adam。
- Batch size:16。
- 训练轮数:40 epochs。
- 学习率:初始0.001,指数衰减因子0.95。
- 关键超参数:
- FUN块数量B:2。
- BLSTM/卷积层通道维度C1=96, C2=128。
- STFT窗口:512样本,50%重叠。
- 源数Q=2。
- 训练硬件:未说明。
- 推理细节:DP-RTF估计每12帧进行一次(通过时间池化层)。声源活动检测阈值设定为使漏检率(MDR)和误警率(FAR)相等。
- 正则化技巧:使用了累积层归一化(cLN)和PReLU激活函数。
📊 实验结果
论文在模拟数据集和LOCATA真实数据集上进行了评估,主要对比模型为SRP-DNN和IPDnet。
表1. 模拟数据集上的性能与复杂度比较
| 模型 | 参数量 | FLOPs | 粗粒度准确率 | 细粒度误差 | 误警率 |
|---|---|---|---|---|---|
| SRP-DNN† [21] | 0.8 M | 2.3 G/s | 80.1% | 2.9° | 13.1% |
| IPDnet† [22] | 0.7 M | 19.4 G/s | 91.7% | 2.1° | 7.7% |
| IPDnet (重训练) | 0.7 M | 19.4 G/s | 93.0% | 2.0° | 7.1% |
| FUN-SSL | 0.8 M | 10.8 G/s | 94.2% | 1.9° | 5.8% |
| (†表示结果直接引自原论文) |
关键结论:FUN-SSL在所有评价指标上均优于重训练的IPDnet,同时计算复杂度(FLOPs)降低了约44%,参数量仅略有增加。SRP-DNN虽然计算轻量,但性能差距较大。
表2. 消融实验:FUN块数量的影响
| FUN块数量 | 参数量 | FLOPs | 粗粒度准确率 | 细粒度误差 | 误警率 |
|---|---|---|---|---|---|
| 1 | 0.4 M | 5.6 G/s | 91.9% | 2.2° | 8.1% |
| 2 | 0.8 M | 10.8 G/s | 94.2% | 1.9° | 5.8% |
| 3 | 1.2 M | 16.0 G/s | 94.5% | 1.9° | 5.9% |
关键结论:第二个FUN块带来了显著的性能提升,但第三个块的增益非常有限,表明模型在2个块时已接近其在该数据集上的容量上限。
表3. 与同计算量FN块模型的对比(架构有效性验证)
| 模块 | 参数量 | FLOPs | 粗粒度准确率 | 细粒度误差 | 误警率 |
|---|---|---|---|---|---|
| 2 FUN Blocks | 0.8 M | 10.8 G/s | 94.2% | 1.9° | 5.8% |
| 5 FN Blocks | 0.4 M | 10.8 G/s | 93.0% | 2.2° | 7.0% |
关键结论:在相同计算成本下,使用两个FUN块的模型性能优于使用五个FN块的模型,证明了性能提升源于FUN块本身的架构设计,而非单纯增加LSTM层数。
表4. LOCATA真实数据集上的性能(两个移动源,两个固定麦克风)
| 模型 | 粗粒度准确率 | 细粒度误差 | 误警率 |
|---|---|---|---|
| IPDnet | 89.1% | 1.9° | 11.0% |
| FUN-SSL | 88.9% | 2.1° | 10.9% |
关键结论:在未见过的真实场景数据上,FUN-SSL取得了与IPDnet几乎持平的性能,这验证了其泛化能力,也表明在该更具挑战性的场景下,架构带来的优势不再明显。
⚖️ 评分理由
- 学术质量:6.0/7。论文工作扎实,技术路线清晰,实验充分且具有说服力(包括对比、消融和真实数据评估)。创新点是有效的架构优化,但属于工程创新范畴,未涉及新的理论或核心算法突破。
- 选题价值:1.5/2。多移动声源定位是重要的基础研究问题,具有明确的应用场景和持续的研究需求。论文的成果直接推动了该领域在计算效率方面的进步。
- 开源与复现加成:0.3/1。论文提供了详细的训练配置、超参数,并引用了基线模型的开源代码,这对复现至关重要。但未提供本模型的代码或预训练权重,未能达到完全开源的标准。