📄 Frequency-Independent Ambisonics Upscaling Using Deep Learning
#空间音频 #深度学习 #音频信号处理
✅ 6.5/10 | 前50% | #空间音频 | #深度学习 | #音频信号处理
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Egke Chatzimoustafa(RWTH Aachen University, Institute of Communication Systems (IKS))
- 通讯作者:未说明
- 作者列表:Egke Chatzimoustafa(RWTH Aachen University, Institute of Communication Systems (IKS))、Peter Jax(RWTH Aachen University, Institute of Communication Systems (IKS))
💡 毒舌点评
亮点:该工作最大的亮点在于其巧妙的理论切入点——利用球谐函数在Ambisonics变换中与频率无关的特性,将复杂的全带提升任务分解为多个子带独立处理任务,这在概念上非常优雅且具有计算效率优势。 短板:最大的短板在于评估的“不彻底性”——论文将“物理准确性”(空间相似度)作为核心评价标准并取得了优势,却完全回避了空间音频领域至关重要的“感知准确性”(主观听测)评估,使得其声称的“对需要可靠空间表征的应用有益”的结论缺乏最终用户视角的支撑。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及。
- 数据集:训练数据为程序生成,方法已描述,但未提供生成脚本或数据。验证集使用公开数据集(EBU-SQAM),测试集使用公开数据集(HiFi-TTS, 乐器声音数据集),但论文未提供其处理后的版本或使用方式。
- Demo:未提及。
- 复现材料:提供了模型架构描述、关键超参数(隐藏层大小、学习率、训练轮数)和数据生成公式。但缺失代码、具体优化器配置、批次大小、训练硬件、调度器细节等关键复现信息。
- 引用的开源项目:引用了DirAC方法的开源代码[15]作为基线对比。引用了前期工作[21],但未说明其开源情况。
📌 核心摘要
- 要解决什么问题:高阶Ambisonics (HOA) 格式能提供更精准的空间声场还原,但其阶数受限于录音和回放硬件。本文旨在通过算法将低阶Ambisonics信号“提升”到高阶,以克服硬件限制。
- 方法核心是什么:提出了一种基于深度学习的序列式框架。核心创新在于利用Ambisonics信号基于球谐函数(SH)变换而具有频率独立性的特点,将时域HOA信号经短时傅里叶变换转换到时频域后,让模型独立地在每个频率子带内进行阶数提升。每个子带的提升由一个独立的双向GRU模型完成,序列式地从一阶逐步提升至目标高阶。
- 与已有方法相比新在哪里:相较于传统的参数化方法DirAC(依赖方向估计和启发式设计),本文方法直接从数据学习映射,避免了显式的参数估计。相较于作者前期工作的全带时域GRU模型,新方法通过子带独立处理,大幅降低了模型复杂度和参数量,并利用了问题的物理特性(SH的频率独立性)进行架构设计。
- 主要实验结果如何:
- 在合成测试数据(2-5个声源)上,所提模型在所有阶数和场景下,其空间相似性(η)的中位数和方差均优于DirAC和全带模型。例如,针对5个声源、提升到6阶时,所提模型中位η=87.5%,方差≤0.011;DirAC中位η=85.5%,方差≈0.029;全带模型中位η≈61%。
- 论文指出,所提模型相比DirAC实现了约63%的空间相似性方差减少,表明其估计更稳定、可靠。
- 论文展示了一个5声源案例(图3),所提模型的SRP图在声源定位上更清晰,伪影更少,对应其更高的空间相似度。
- 论文未提供真实世界测量数据上的具体数值,但声称“两种方法在真实测量数据上的平均表现相似”。
- 实际意义是什么:该方法为使用少量麦克风录音获得更精确空间表征的Ambisonics信号提供了一条可能的途径,尤其适用于需要高物理精度空间音频还原的VR/AR或专业音频制作场景。
- 主要局限性是什么:模型完全在合成数据上训练,其在复杂真实声场(如存在混响、噪声、扩散场)中的泛化能力未知;缺乏主观听感评估,无法证明其客观指标的优势能否转化为更好的人耳感知体验;对完全扩散声场的处理能力未讨论。
🏗️ 模型架构
论文提出的Ambisonics阶数提升系统采用序列化框架,整体流程如下:
- 输入与预处理:输入为一阶Ambisonics信号
x_{nm}^{(1)}(t)(4个通道)。首先通过短时傅里叶变换(STFT)将其转换到时频域,得到x_{nm}^{(1)}(λ, μ),其中λ是帧索引,μ是频率箱索引。 - 序列化提升框架:系统由
L = \hat{N}-1个独立模型组成,每个模型l(l=1,…,L) 负责将输入的l阶HOA信号提升到l+1阶。 - 单个模型
l的内部结构 (图1b):- 输入:
l阶HOA信号在时频域的实部和虚部:ℜ{ \hat{x}_{nm}^{(l)}(λ, μ) }和ℑ{ \hat{x}_{nm}^{(l)}(λ, μ) }。每个都是(l+1)^2维向量,对应l阶HOA的所有通道系数。 - 核心处理:模型
l内部包含一个双向门控循环单元(Bidirectional GRU)。其关键设计在于:模型权重在所有频率箱μ之间是共享的,但每个频率箱的输入被独立处理。这直接利用了球谐函数变换矩阵Y与频率无关的特性,是本文的核心架构创新。 - 输出层:一个全连接层(线性激活)将GRU的隐藏状态映射到下一阶的信号维度。
- 输出与拼接:模型输出估计的下一阶HOA信号的增量部分
˜{x}_{nm}^{(l+1)}(λ, μ)。将其与模型的输入拼接,即得到完整的l+1阶HOA信号估计\hat{x}_{nm}^{(l+1)}(λ, μ),其维度为(l+2)^2。
- 输入:
- 后续模型与迭代:模型
l的输出\hat{x}_{nm}^{(l+1)}作为下一个模型l+1的输入,过程迭代进行,直到达到目标阶数\hat{N}。 - 输出重构:最终得到的时频域信号
\hat{x}_{nm}^{(\hat{N})}(λ, μ)通过逆离散傅里叶变换(IDFT)和重叠相加法重构回时域信号。
关键设计选择及动机:
- 序列化逐阶提升:避免了直接预测高阶系数的巨大维度
( (\hat{N}+1)^2 - 4 ),将任务分解为多个小任务,降低了单个模型的学习难度。 - 子带独立处理:基于声场在频域上通常稀疏的假设(即每个频率子带仅有少数声源活跃),使模型可以为每个频率子带独立学习映射关系,提高了模型的灵活性和效率。
- 双向GRU:选择GRU而非CNN或Transformer,是因为其在捕获时序依赖方面高效,且对有限数据更鲁棒。双向结构可以同时利用过去和未来的上下文信息。
💡 核心创新点
- 基于物理特性的频率独立子带处理架构:这是最主要的创新。利用球谐函数变换矩阵
Y与频率k无关这一特性,设计了在频率子带维度共享权重、独立处理的神经网络。这打破了传统方法(如全带GRU)或常规深度学习模型在处理时频信号时通常跨频率卷积或关联的范式,使模型更轻量、更贴合问题的物理本质。 - 合成数据生成策略的扩展:在前期工作[21]的基础上,将固定频率的正弦谐波信号源扩展为时变频率
f(t)的正弦谐波信号(公式12)。这更好地模拟了现实音频信号的非平稳性,提升了训练数据的逼真度,是本文声称性能提升的重要基础。 - 低复杂度序列式深度学习框架:构建了一个端到端的深度学习系统,用多个轻量级GRU模型序列式地替代了传统算法(如DirAC)中复杂的、需要人工调参的方向估计和去相关处理。该框架简洁且计算高效。
🔬 细节详述
- 训练数据:
- 来源:完全由程序生成(合成数据)。
- 规模:15,000个声景,每个包含1-5个正弦波声源。采样率44.1kHz,总长约0.68小时。
- 生成模型:单个声源由一个带4次谐波(
Ξ=4)的时变正弦波信号定义(公式11-12),参数(幅度au、衰减βu、初相Δαu、基频f0)在指定区间内随机均匀采样。时变频率f(t)的振荡频率fv从[10, 80Hz]中随机采样。 - 声源放置:在单位球面上随机均匀采样方向
Θu。 - 验证集:从EBU-SQAM数据集[31]中随机选取真实乐器和语音信号,通过球谐变换(2)生成。规模约2000个样本(约0.09小时)。
- 损失函数:均方误差(MSE),用于训练模型输出与目标HOA系数之间的差异。
- 训练策略:
- 优化器:Adam优化器,初始学习率
10^{-4}。 - 学习率调度:如果连续10个epoch验证集无进展,则降低学习率(具体调度策略未说明)。
- 训练轮数:每个模型
l训练200个epoch以确保收敛。 - 批次大小:未明确说明。
- 优化器:Adam优化器,初始学习率
- 关键超参数:
- 模型大小:每个双向GRU的隐藏层大小
N_h = 128。 - 频域参数:STFT使用1024样本帧,50%重叠,汉宁窗,DFT点数为2048。
- 模型大小:每个双向GRU的隐藏层大小
- 训练硬件:论文中未提及。
- 推理细节:按照序列框架,输入数据依次通过训练好的L个模型,最后通过IDFT和重叠相加法重构时域信号。解码策略、温度等不适用。
- 正则化或稳定训练技巧:未明确提及,但使用了学习率调度和提前停止(patience=10)的策略。
📊 实验结果
实验设置:
- 测试集:为4种声源数量场景(2、3、4、5)和5种提升阶数(2到6)构建了独立的测试集。声源来自HiFi-TTS数据集[32](语音)和乐器声音数据集[33],随机放置在对应阶数的Fliege/Maier采样网格上。每个测试集约5000个样本(约0.23小时)。
- 基线方法:DirAC(使用其作者提供的开源代码[15]中的参数设置),以及作者前期的全带时域GRU模型[21](在同等规模的合成数据上训练)。
- 评估指标:空间相似性 (η)(公式9),衡量估计信号与目标信号的空间功率分布的相似度。
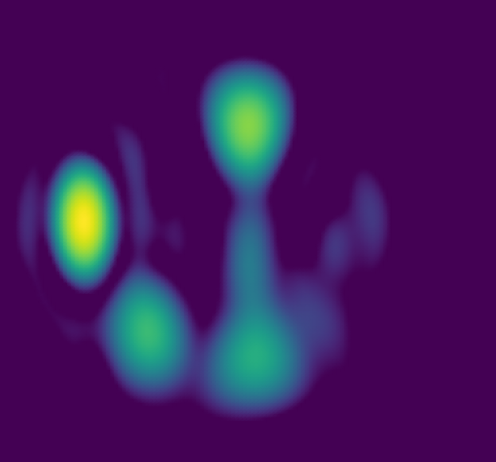
主要结果: 论文提供了箱线图(图2)展示各方法在不同场景和阶数下的空间相似性分布。
关键结论:
- 所提模型(Novel)在所有测试场景和阶数下,其中位空间相似性(箱线图中线)和分布方差(箱体长度和须线范围)均优于DirAC和全带模型。
- 定量对比示例(2声源,提升到2阶):所提模型的平均空间相似性比DirAC高约1.5%,比全带模型高约4.5%。
- 复杂场景下的优势:在更复杂的5声源场景中(提升到6阶),所提模型的中位η=87.5%,方差≤0.011;DirAC中位η≈85.5%,方差≈0.029;全带模型中位η≈61%,方差≈0.016。这显示了所提模型在保持高精度的同时,具有显著更低的方差(约63%的方差减少)。
- 性能趋势:所有方法的性能都随着提升阶数增加或声源数量增加而下降。全带模型的中位值在复杂场景下显著低于DirAC,表明其泛化能力不足。
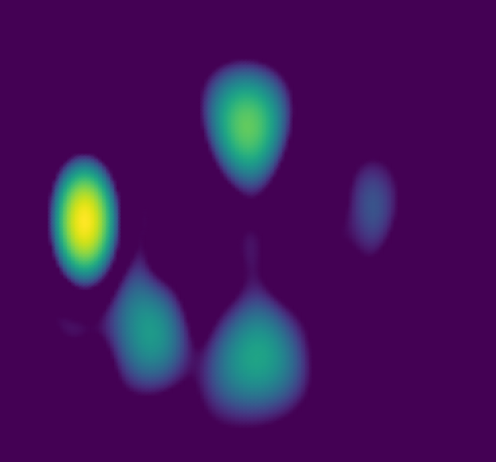
案例展示(SRP图): 论文展示了一个5声源场景的SRP图(图3),直观比较了输入、目标、DirAC估计和所提模型估计的空间能量分布。

图示分析:一阶输入(左上)空间分辨率低,无法区分5个声源。目标(右上)有5个清晰峰值。DirAC(左下)虽然捕捉了大部分峰值,但在某些声源之间(如小提琴2-3之间)出现了不应有的高能量区域。所提模型(右下)更准确地捕捉了所有峰值,同时有效抑制了虚假成分,空间分辨率更高。这与其更高的空间相似性值(86% vs DirAC的83%)相对应。
论文未说明的:
- 真实世界测量数据上的具体数值。
- 不同声源类型(语音/音乐)上的细分结果。
- 模型大小、计算复杂度、推理时间的对比。
- 消融实验(例如,比较子带独立与子带依赖模型,或不同时变频率数据的影响)。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了有物理依据的创新架构,并进行了系统的实验对比,结果显著。但完全缺乏主观评估是重大缺陷,使得“对应用有益”的论断站不住脚。实验仅限于特定合成数据生成方式下的测试,对真实复杂声场的泛化性证明不足。
- 选题价值:1.5/2:问题(HOA阶数限制)真实存在,方法(深度学习)有前景,应用(VR/空间音频)有市场。但研究方向相对垂直,且解决的是一个具体算法提升问题,影响力可能局限于空间音频处理社区的特定分支。
- 开源与复现加成:-0.5/1:论文未开源任何代码、模型或数据集。虽然描述了架构和训练细节,但对于深度学习工作而言,缺乏可执行代码和预训练模型使得独立复现的成本和不确定性很高。