📄 Forward Convolutive Prediction for Frame Online Monaural Speech Dereverberation based on Kronecker Product Decomposition
#语音增强 #信号处理 #Kronecker分解 #在线处理
✅ 7.5/10 | 前50% | #语音增强 | #信号处理 | #Kronecker分解 #在线处理
学术质量 7.5/7 | 选题价值 1.5/2 | 复现加成 -1.0 | 置信度 中
👥 作者与机构
- 第一作者:Yujie Zhu(武汉大学电子信息学院)
- 通讯作者:未说明
- 作者列表:Yujie Zhu(武汉大学电子信息学院),Jilu Jin(西北工业大学CIAIC),Xueqin Luo(西北工业大学CIAIC),Wenxing Yang(上海理工大学东方泛血管器械创新学院),Zhong-Qiu Wang(南方科技大学计算机科学与工程系),Gongping Huang(武汉大学电子信息学院),Jingdong Chen(西北工业大学CIAIC),Jacob Benesty(加拿大魁北克大学INRS-EMT)
💡 毒舌点评
亮点:本文成功地将计算复杂的长线性预测滤波器,通过Kronecker积(KP)分解为两个短滤波器的乘积,并提供了有效的自适应更新算法,在保持或略微提升性能(在P值较大时)的同时,显著降低了计算量,为实时单通道去混响提供了更可行的工程方案。短板:论文的核心贡献是将现有的KP分解框架“嫁接”到FCP方法上,属于一个系统集成的创新,而非底层理论的突破。此外,第一阶段的DNN(GTCRN)是现成的架构,并未提出新的网络设计。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的VCTK数据集,但未提及本工作特有的数据或预处理脚本。
- Demo:未提及。
- 复现材料:论文提供了关键算法伪代码(Algorithm 1)和部分超参数设置(如K, K1, K2, α1, α2),为复现提供了基础。但缺失了DNN训练细节(损失函数、具体架构参数、训练时长等),使得完整复现非常困难。
- 论文中引用的开源项目:提到了GTCRN模型,但未提供其具体实现链接或出处引用。
📌 核心摘要
这篇论文针对单通道语音去混响中计算复杂度高的问题,提出了基于Kronecker积(KP)分解的前向卷积预测(FCP)方法。其核心思想是将原本很长的线性预测滤波器,建模为两个长度短得多的滤波器的KP,从而大幅减少参数量和计算负担。与传统的FCP方法相比,新方法在滤波器更新阶段引入了KP分解框架,并通过基于递归最小二乘(RLS)的自适应算法迭代更新这两个短滤波器。实验在模拟的混响环境(VCTK数据集)中进行,结果表明,当KP分解的阶数P选择合适(如P=4或5)时,KP-FCP方法在PESQ和FWSNR等指标上能够达到甚至超过传统FCP的性能,同时计算复杂度显著降低。例如,在T60=400ms条件下,KP-FCP(P=5)的PESQ为1.837,优于FCP(online)的1.709。该研究为资源受限场景下的实时单通道语音去混响提供了一种高效的解决方案。主要局限性在于,第一阶段的神经网络部分采用了现有架构,且KP分解阶数P的选择需要权衡性能与效率。
🏗️ 模型架构
本文提出的系统是一个两阶段的帧在线单通道语音去混响框架,如图1所示。
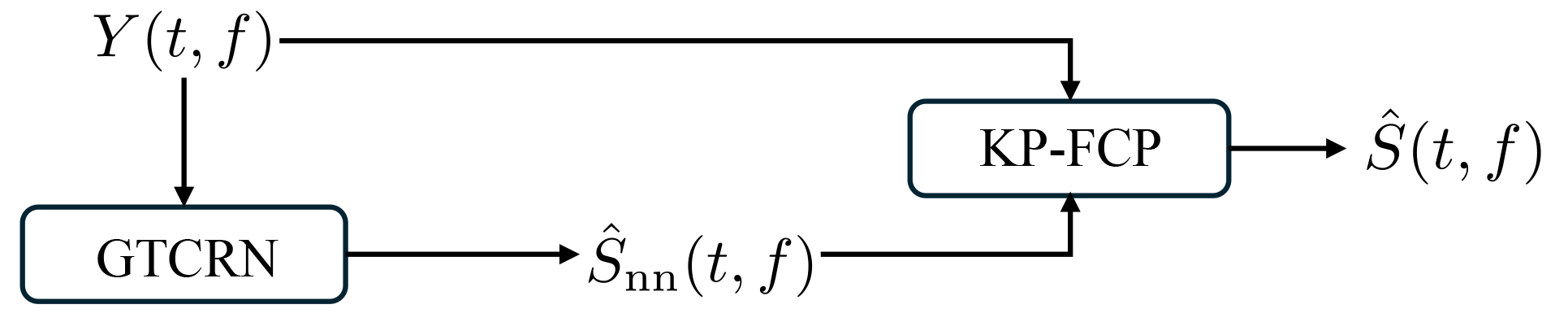
第一阶段:直达声估计
- 输入:带噪混响语音信号的STFT表示
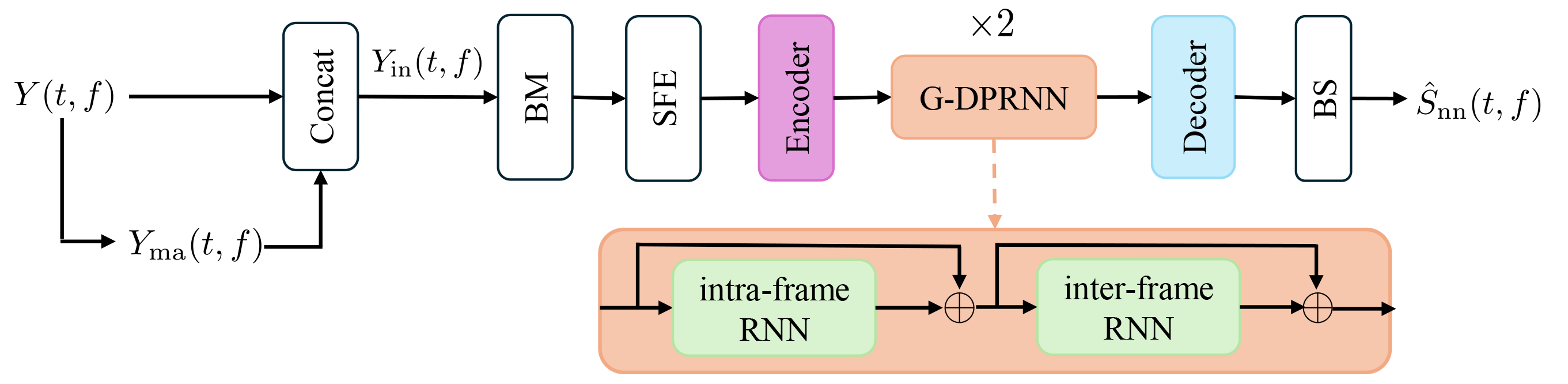
Y(t, f)及其幅度谱。 - 核心组件:一个因果的、基于分组时序卷积循环网络(GTCRN)的深度神经网络(DNN)。
- 内部流程:如图2所示,输入首先经过频带合并(BM)模块压缩高频信息;然后通过子带特征提取(SFE)模块重塑频率维度以捕捉跨频带关系;接着由编码器编码成紧凑的时频表征;随后通过两个分组双路径循环网络(G-DPRNN)模块分别对帧内和帧间依赖关系建模(其中帧间建模使用单向GRU以确保因果性);最后解码器与频带分离(BS)操作预测出直达声分量
Ŝnn(t, f)。 - 设计动机:在线、因果设计,确保处理当前帧时不依赖未来信息,适用于流式应用。
第二阶段:基于KP-FCP的残余混响抑制
- 输入:观测信号
Y(t, f)和第一阶段估计的直达声Ŝnn(t, f)。 - 核心思想:不再直接优化一个长滤波器
g(t, f),而是将其建模为两个短滤波器g1(t, f)和g2(t, f)的KP(公式5),即g(t, f) = Σp g2,p(t, f) ⊗ g1,p(t, f)。这利用了线性预测滤波器可能存在的低秩特性。 - 算法流程(Algorithm 1):这是一个逐帧、逐频点的在线迭代算法,基于RLS思想。对于当前时刻
t和频率f:- 计算误差
e1(t, f),它是观测信号与通过g1和g2重构的混响估计之间的差。 - 根据误差更新与
g1相关的逆协方差矩阵Φ^{-1}_{ŝ2}和滤波器系数g1。 - 类似地,计算误差
e2(t, f)并更新g2。 - 最终去混响信号通过
Ŝ(t, f) = Ŝnn(t, f) + Y(t, f) - g₂ᴴ(t, f)ŝ₁(t, f)得到。
- 计算误差
- 数据流:第一阶段DNN输出的
Ŝnn向后馈入第二阶段,用于构建ŝ1和ŝ2向量(公式16-17),并在每一步迭代中用于更新两个短滤波器g1和g2。
💡 核心创新点
- KP分解框架应用于FCP:首次将Kronecker积分解框架引入到前向卷积预测(FCP)单通道去混响方法中,用于参数化高阶线性预测滤波器。这是本文最核心的架构创新。
- 计算复杂度的显著降低:通过将长度为K的滤波器分解为两个长度分别为K1和K2的短滤波器(K=K1*K2),将算法的计算复杂度从传统FCP的O(K²K1)降低到KP-FCP的O(P²K2² + P²K1²)(表1)。在P值较小时,计算量优势明显。
- 有效的在线自适应更新算法:提供了一套完整的、基于RLS思想的自适应算法(Algorithm 1),用于在线迭代更新分解后的两个短滤波器
g1和g2,使得该方法能够在帧在线模式下工作。 - 性能与效率的可调谐权衡:通过调整KP分解的阶数P,可以在计算复杂度和去混响性能之间进行灵活权衡。实验表明,当P≥4时,KP-FCP的性能可以达到或超过传统FCP(图4,表2)。
🔬 细节详述
- 训练数据:
- 数据集:VCTK数据集。
- 规模:训练集包含34,647条语音,测试集包含872条语音。
- 预处理:所有语音重采样至16kHz。
- 数据增强:使用图像法(image method)模拟不同混响条件。房间尺寸(5×5×3 至 10×10×4 m³),声源距离(0.5-2m),混响时间T60(0.3-0.8s)。添加高斯白噪声,信噪比SNR在20-30dB之间。STFT采用512点帧长,75%重叠。
- 损失函数:论文未明确说明训练DNN(GTCRN)所使用的损失函数。
- 训练策略:
- 优化器:AdamW。
- 学习率:初始学习率5e-4,每个epoch衰减0.98。
- 其他细节(如batch size, epoch数):未说明。
- 关键超参数:
- FCP/KP-FCP部分:滤波器总长度
K=81,分解后短滤波器长度K1=9,K2=9。 - KP-FCP算法:递归因子
α1=α2=0.95,初始化值δ=0.01。KP分解阶数P是主要变化参数(实验测试了P=3,4,5)。 - GTCRN部分:具体网络参数未详细说明,但计算量很低(约2.1 K MACs/TF单位)。
- FCP/KP-FCP部分:滤波器总长度
- 训练硬件:未说明。
- 推理细节:系统以帧在线(frame-online) 方式运行。DNN(GTCRN)逐帧产生
Ŝnn,随后KP-FCP算法在同一帧内迭代更新g1和g2并输出最终结果Ŝ。无需全局未来信息,适合流式处理。 - 正则化或稳定训练技巧:未明确说明,但递归算法中的
λ(t, f)(公式4)和逆协方差矩阵初始化为单位阵可能起到稳定作用。
📊 实验结果
主要实验设置:在VCTK测试集上,针对三种混响时间(T60=400ms, 500ms, 700ms)进行评估。指标为PESQ和频率加权分段信噪比(FWSNR),并报告相对于原始观测信号的增益(ΔPESQ, ΔFWSNR)。
计算复杂度对比(表1):
| 方法 | 复杂度 (MACs per TF unit) |
|---|---|
| FCP (online) | 16K² + 20K + 16 |
| KP-FCP | 16P²(K₁² + K₂²) + 8PK₁K₂ + 16PK₁ + 20PK₂ + 24 |
当 K=81, K1=K2=9 时,复杂度随P变化的曲线如图3所示。
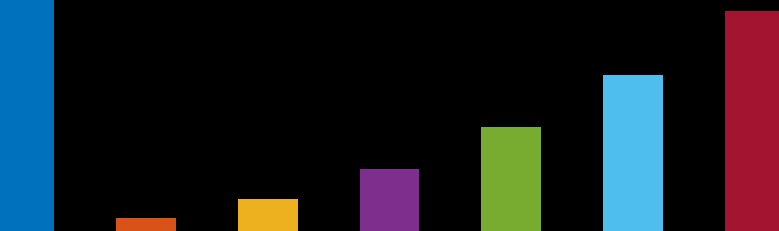 结论:当P < 6时,KP-FCP的计算量明显低于传统FCP。
结论:当P < 6时,KP-FCP的计算量明显低于传统FCP。
性能对比(表2):
| 方法 | T60 = 400 ms | T60 = 500 ms | T60 = 700 ms | |||
|---|---|---|---|---|---|---|
| PESQ | FWSNR (dB) | PESQ | FWSNR (dB) | PESQ | FWSNR (dB) | |
| observed | 1.411 | 1.661 | 1.344 | 1.003 | 1.258 | -0.075 |
| FCP (online) | 1.709 | 4.803 | 1.622 | 4.220 | 1.556 | 3.777 |
| KP-FCP (P=3) | 1.672 | 4.609 | 1.590 | 3.595 | 1.525 | 3.595 |
| KP-FCP (P=4) | 1.764 | 5.308 | 1.671 | 4.346 | 1.608 | 4.346 |
| KP-FCP (P=5) | 1.837 | 5.790 | 1.735 | 5.214 | 1.661 | 4.850 |
关键结论:
- 所有方法相较于原始观测信号均有显著提升。
- 随着P增大,KP-FCP性能持续提升。在P=3时,其性能略低于FCP (online)。
- 当P=4或P=5时,KP-FCP的性能达到甚至超过FCP (online)。例如,在T60=400ms时,KP-FCP (P=5)的PESQ(1.837)比FCP (1.709)高出0.128。
- 性能提升需要付出计算代价增加的代价(如图3所示)。
分段性能示例(图4):
(注:此处应引用原图,URL为pdf-image-page4-idx2,与图3相同,但描述内容不同。根据论文描述,图4是分段性能平滑曲线,显示KP-FCP在P=4,5时性能追上或超过FCP)
结论:KP-FCP在P=4和P=5时,在整个时间轴上的性能增益(PESQ和FWSNR)与FCP (online)持平或更优。
⚖️ 评分理由
- 学术质量:4.5/7:论文逻辑清晰,理论推导(KP分解与线性代数关系)正确,实验设计合理(模拟数据、多条件对比、消融P值),结果可信度高。主要扣分点在于创新属于技术整合(将已有的KP框架用于已有的FCP),而非提出全新的去混响理论或架构。
- 选题价值:1.5/2:解决的问题(单通道去混响计算量)是实际应用中真实存在的痛点,尤其对于嵌入式设备。论文提供了明确的效率提升方案。但该问题领域相对传统,非当前最前沿热点(如扩散模型、大模型赋能音频)。
- 开源与复现加成:-1.0/1:论文未提供任何代码、模型、训练脚本或详细配置,完全无法复现,因此给予最低的复现加成分数。