📄 Flexi-LoRA with Input-Adaptive Ranks: Efficient Finetuning for Speech and Reasoning Tasks
#语音识别 #大语言模型 #参数高效微调 #动态秩适应
✅ 7.5/10 | 前25% | #语音识别 | #参数高效微调 | #大语言模型 #动态秩适应
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zongqian Li(剑桥大学)
- 通讯作者:未说明
- 作者列表:Zongqian Li(剑桥大学)、Yixuan Su(剑桥大学)、Han Zhou(剑桥大学)、Zihao Fu(剑桥大学)、Nigel Collier(剑桥大学)
💡 毒舌点评
亮点:论文抓住了静态LoRA“一刀切”的痛点,通过一个轻量路由器实现输入感知的动态计算分配,思路清晰且实验全面,在QA、数学、语音三大任务上都跑通了,证明了方法的通用性和有效性。
短板:路由器的设计(基于池化嵌入和交叉熵分类)略显“经典”,缺乏对“输入复杂度”更深入的建模或学习,且论文更偏向经验性验证,理论层面的分析(如动态秩带来的泛化性保证)稍显不足。
🔗 开源详情
- 代码:论文中提供了代码仓库链接:
https://github.com/ZongqianLi/Flexi-LoRA。 - 模型权重:未提及公开的预训练或微调模型权重。
- 数据集:论文中使用的数据集均为公开标准数据集(MRQA, GSM8K, LibriSpeech等)。
- Demo:未提及。
- 复现材料:论文中描述了方法框架和主要实验设置,但未提供完整的训练脚本、超参数(如学习率、batch size、优化器)的详细配置或检查点。代码仓库可能包含更多信息。
- 论文中引用的开源项目:未明确提及引用的外部开源项目,但基于开源模型(LLaMA-3.2, Whisper)和标准数据集进行实验。
📌 核心摘要
这篇论文旨在解决传统LoRA微调方法中静态参数分配无法适应输入复杂度变化的问题。核心方法是提出Flexi-LoRA框架,它包含一个难度感知路由器,能根据输入的嵌入向量预测一个合适的LoRA秩(rank),并在训练和推理阶段都保持这种动态的秩分配,以实现输入自适应的参数资源分配。与已有动态秩方法(如AdaLoRA、DyLoRA)相比,Flexi-LoRA是首个在训练和推理时都保持基于路由器的样本级动态秩选择的框架,解决了先前方法在推理时使用固定秩或随机分配秩导致性能损失的问题。实验表明,在QA(MRQA)、数学推理(GSM8K等)和语音识别(LibriSpeech)任务上,Flexi-LoRA在使用显著更少参数(如QA任务仅用LoRA-8的29.59%参数)的情况下,性能持续优于静态LoRA和其他动态基线,尤其在需要严格推理链的数学任务上优势更明显。该方法的实际意义在于以一种更简洁的方式实现了类似混合专家(MoE)的“按需分配计算”效益,提升了微调的效率和性能。主要局限性在于路由机制相对简单,且论文未深入探讨动态秩选择的理论内涵。
🏗️ 模型架构
Flexi-LoRA的整体架构包含两个核心组件:一个难度感知路由器(Difficulty-aware Router) 和一个输入自适应LoRA(Input-adaptive LoRA) 模块。其工作流程如下(参考图2):
- 输入处理:对于输入序列,首先计算其token嵌入 \( H \),并通过池化操作(聚合非padding token的嵌入)得到整个序列的表示向量 \( h \)。
- 路由决策:序列表示 \( h \) 被输入路由器 \( R(h) \),路由器输出一个离散的秩值 \( r \)(例如2、4、8)。该路由器是一个可训练的模块,训练目标是根据样本的难度标签(如QA的F1分数、数学任务的准确率)进行分类。
- 自适应LoRA应用:预测的秩 \( r \) 被统一应用于所有Transformer层。对于每一层的权重更新,只使用对应秩 \( r \) 的LoRA矩阵 \( A_{r} \) 和 \( B_{r} \) 的前 \( r \) 行/列,计算增量 \( \Delta W = B_{r} A_{r} \)。最终的层输出为 \( H = W H_{prev} + \alpha_r \cdot (B_{r} A_{r} H_{prev}) \),其中 \( \alpha_r \) 是与秩相关的缩放因子。
- 训练与推理一致性:关键创新在于,训练和推理阶段都使用同一个路由器进行样本级的秩分配,从而保证了动态秩模式的一致性。而在同一个批次内,不同样本可以拥有不同的秩。
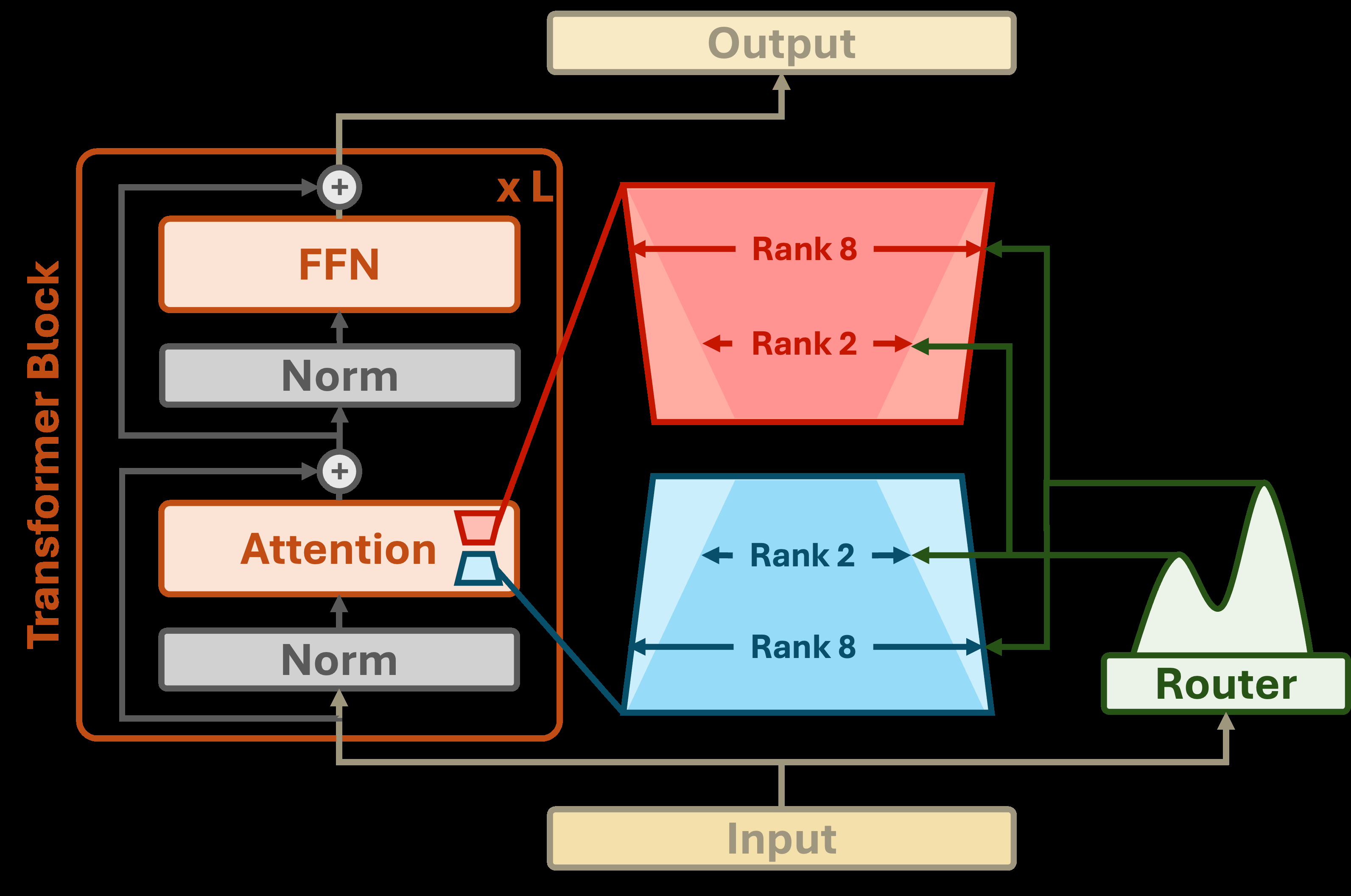 图2:Flexi-LoRA框架。路由器分析输入嵌入并为Transformer层输出秩分配(绿色箭头)。红蓝梯形代表LoRA的A、B矩阵,颜色深浅指示秩大小(深色=秩2,浅色=秩8)。路由器实现了基于输入复杂度的动态秩分配。
图2:Flexi-LoRA框架。路由器分析输入嵌入并为Transformer层输出秩分配(绿色箭头)。红蓝梯形代表LoRA的A、B矩阵,颜色深浅指示秩大小(深色=秩2,浅色=秩8)。路由器实现了基于输入复杂度的动态秩分配。
💡 核心创新点
- 首个训练-推理一致的输入自适应LoRA框架:以往的动态LoRA方法(AdaLoRA, DyLoRA)在推理时都使用固定秩,导致训练时的动态模式无法延续。Flexi-LoRA通过路由器实现了在训练和推理阶段都进行样本级动态秩选择,解决了这一不一致问题。
- 基于输入复杂度的动态参数分配:路由器学习将输入映射到不同的秩,使得简单输入使用小秩(省参数),复杂输入使用大秩(保性能),从而在平均上实现了更高的性能与参数效率。这与“一刀切”的静态秩分配形成本质区别。
- 实现了类MoE效益的更简洁方案:论文指出,Flexi-LoRA通过更简洁的实现(一个路由器+动态LoRA选择)达到了类似混合专家模型“按需分配计算能力”的好处,减少了参数冗余,提高了模型能力。
- 对动态秩重要性的深入实证发现:论文通过对比DyLoRA(训练动态,推理固定)和Flexi-LoRA(训练推理均动态),清晰地证明了训练-推理动态一致性对性能至关重要,尤其是在数学推理这类需要严格推理链的任务上(DyLoRA在数学任务上性能暴跌)。
🔬 细节详述
- 训练数据:
- QA任务:在MRQA训练集(包含SQuAD, TriviaQA等6个数据集)上训练,在MRQA测试集(包含BioASQ, DROP等6个数据集)上评估。
- 数学推理:在MetaMathQA的GSM8K子集上训练,在GSM8K(域内)、SVAMP、MultiArith、MAWPS(域外)上评估。
- 语音任务:使用LibriSpeech数据集。
- 损失函数:
- 路由器训练损失:带噪声的交叉熵损失 \( \mathcal{L}(\theta) = -\sum_i y_i \log(R(h_i + \epsilon)) \),其中 \( \epsilon \sim \mathcal{N}(0, \sigma^2) \),\( y_i \) 是基于任务指标(F1/准确率)划分的难度标签。
- 主任务损失:标准任务损失 \( \mathcal{L}_{task} = -\sum_i \log p(y_i | x_i) \)。
- 训练策略:论文未在提供的文本中明确说明具体的学习率、优化器、batch size等训练超参数。
- 关键超参数:
- 基础模型:LLaMA-3.2-1B-Instruct(主要结果),LLaMA-3.2-3B-Instruct(消融分析)。语音任务使用Whisper。
- 秩选择:Flexi-LoRA在秩集合{2, 4, 8}中动态选择。
- 训练硬件:论文中未提及。
- 推理细节:论文中未提及具体的解码策略(如beam search size)等。
- 正则化技巧:在路由器训练中加入了高斯噪声 \( \epsilon \) 以增强鲁棒性。
📊 实验结果
论文在QA、数学推理和语音识别三大类任务上进行了评估,主要结果如下:
QA任务(表2, MRQA测试集, LLaMA-3.2-1B-Instruct) Flexi-LoRA (2,8) 在平均F1和EM指标上均取得最佳成绩,同时参数量仅为LoRA-8的约29.6%。
模型 平均F1 平均EM 参数量 LoRA (Rank 8) 52.01 37.14 1703K AdaLoRA (Rank 8) 51.36 36.38 1703K DyLoRA (Rank 1-8) 45.40 30.05 1703K DyLoRA+ (Rank 1-8) 51.89 37.30 966K Flexi-LoRA (2,8) 52.37 37.41 504K 数学推理任务(表3) 在1B和3B模型上,Flexi-LoRA均以更少的参数取得了最高的平均准确率,且优势比QA任务更明显。DyLoRA性能急剧下降,凸显了推理时秩固定的问题。
模型 方法 平均准确率 参数量 LLaMA-3.2-1B LoRA (Rank 8) 63.17 1703K Flexi-LoRA (2,8) 66.56 533K LLaMA-3.2-3B LoRA (Rank 8) 82.37 4.58M Flexi-LoRA (2,8) 84.00 1.53M 语音识别任务(表4, LibriSpeech) 在语音识别任务上,Flexi-LoRA同样以极低的参数占比(0.15%)取得了与全量微调接近的性能,并显著优于固定秩LoRA(WER从17.85降至14.33)。
方法 WER↓ CER↓ ACC↑ 参数占比↓ LoRA (Rank 8) 17.85 5.30 82.15 0.58% Flexi-LoRA (2,8) 14.33 4.62 85.67 0.15%
性能-效率权衡图(图3):该图直观展示了Flexi-LoRA在QA和数学任务上均位于帕累托前沿,即在相同或更少参数下,性能优于其他PEFT方法。
性能-效率权衡图] 图3:不同参数高效微调方法在QA和数学任务上的性能-效率权衡。Flexi-LoRA(橙线)以更少的参数达到了更高的性能。
⚖️ 评分理由
- 学术质量:6.5/7。创新性明确,提出了首个训练-推理一致的输入自适应LoRA框架。技术路线正确,实验在三大类任务上全面验证了方法的有效性,结果可信且具有说服力。扣分点在于对“输入复杂度”的建模方法较简单,且部分实验细节(如语音)未充分展开分析。
- 选题价值:2.0/2。研究高效、自适应的微调方法,是当前大模型落地的核心需求之一,具有很强的前沿性和实际应用价值。其思路可迁移至其他领域。
- 开源与复现加成:0.5/1。提供了代码仓库链接是重要贡献,为复现奠定了基础。但论文正文未提供完整的训练脚本、超参数配置或模型权重,因此复现便利性有所欠缺。