📄 Fine-Tuning Large Audio-Language Models with Lora for Precise Temporal Localization of Prolonged Exposure Therapy Elements
#音频事件检测 #多模态模型 #语音生物标志物 #迁移学习
✅ 6.5/10 | 前50% | #音频事件检测 | #多模态模型 | #语音生物标志物 #迁移学习
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Suhas BN (College of Information Sciences & Technology, The Pennsylvania State University, USA)
- 通讯作者:论文中未明确标注通讯作者信息。
- 作者列表:
- Suhas BN (College of Information Sciences & Technology, The Pennsylvania State University, USA)
- Andrew M. Sherrill (Department of Psychiatry & Behavioral Sciences, Emory University, USA)
- Jyoti Alaparthi (Department of Psychiatry & Behavioral Sciences, Emory University, USA)
- Dominik Mattioli (School of Interactive Computing, Georgia Institute of Technology, USA)
- Rosa I. Arriaga (School of Interactive Computing, Georgia Institute of Technology, USA)
- Chris W. Wiese (School of Psychology, Georgia Institute of Technology, USA)
- Saeed Abdullah (College of Information Sciences & Technology, The Pennsylvania State University, USA)
💡 毒舌点评
亮点:论文精准地切入了一个真实且重要的临床痛点(PE疗法评估),并设计了一套从标注(LLM+人工验证)到建模(多模态微调)再到部署(隐私保护)的完整流水线,展现了扎实的领域应用思维。 短板:实验的说服力很大程度上受限于其“自产自销”——用自己定义的任务、自己标注(尽管经过验证)的数据、自己提出的数据划分来评估自己的方法,缺乏与领域内或更通用任务上现有SOTA方法的横向比较,使得“最佳MAE 5.3秒”的优越性难以完全确立。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文中提到微调后模型的目标是本地部署,但未提及是否公开微调后的权重。
- 数据集:论文使用的PE疗法会谈数据来自Emory大学,论文中明确提到数据处理在IRB批准的安全环境中进行,但未提及数据集是否公开及获取方式。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了详细的实验设置(优化器、学习率、LoRA参数等),但未提供预训练模型的具体版本、数据预处理脚本或训练配置文件。
- 论文中引用的开源项目:明确依赖并微调了 Qwen2-Audio(Qwen2-Audio-7B-Instruct)模型;使用了 Amazon HealthScribe 进行语音转录。
📌 核心摘要
- 要解决什么问题:自动化评估创伤后应激障碍(PTSD)的延长暴露(PE)疗法中治疗师对核心协议(如想象暴露及其处理)的遵循度,即“治疗师保真度”。这通常需要专家人工审核完整会谈录音,耗时耗力,难以规模化。
- 方法核心是什么:将问题定义为连续时间回归任务。使用预训练的大型音频-语言模型Qwen2-Audio-7B,通过QLoRA技术进行高效微调。模型输入为固定长度(如30秒)的音频片段及其对应转录文本,外加一个任务特定的文本提示(如“定位想象暴露的开始”)。模型输出为该事件在输入窗口内的归一化时间偏移(0.0-1.0)。
- 与已有方法相比新在哪里:是首批将音频-语言大模型应用于心理治疗保真度指标精确时间定位的工作之一。其创新点包括:1)将临床任务转化为适合多模态模型的连续回归问题;2)提出了一种结合LLM初步标注与人工验证的“软监督”标注流程,以降低数据标注成本;3)系统分析了输入上下文窗口大小和LoRA适配强度对时间定位精度的影响。
- 主要实验结果如何:在308个真实PE会谈数据集上,最佳配置(30秒窗口,LoRA秩=8)的平均绝对误差(MAE)为5.3秒(P1: 5.9±1.4s, P2: 5.0±1.8s, P3: 5.0±0.5s)。关键消融实验显示:a) 较短的输入窗口(30秒)显著优于长窗口(60秒、120秒),后者误差可能高出3-5倍;b) LoRA微调在所有设置下均优于仅训练回归头的基线,但在长窗口下较高的LoRA秩可能导致过拟合。
- 实际意义是什么:为临床督导和质量控制提供了一个可扩展、保护隐私的自动化工具。模型可本地运行,避免敏感的患者音频数据外泄。自动化的时间戳能帮助督导者快速定位关键治疗片段进行审查,将评估负担从“审查整小时录音”降低到“审查几分钟的标记片段”。
- 主要局限性是什么:1)方法高度依赖于特定的PE疗法框架和预设的三个评估阶段,对其他疗法或更细粒度行为的泛化性未知。2)数据集完全来自一个机构(Emory University),可能限制模型的外部效度。3)缺乏与更强��基线(如纯文本大模型、其他商用多模态模型)的对比,难以判断在通用多模态理解能力上的相对水平。
🏗️ 模型架构
该论文的整体架构是一个针对特定时间回归任务微调的音频-语言模型流水线。
完整输入输出流程:
- 输入准备:对于每个已知的治疗阶段边界(如P2的开始时间),从完整会话音频中截取一个固定长度(30/60/120秒)的音频片段
Aj,以及对应时间段的转录文本Tj。将边界的真实时间转换为相对于该窗口起始时间的归一化偏移量oj = (t_abs - t_start) / D_j,作为训练目标。 - 提示构造:构造一个任务特定的文本提示
P,例如:“以下音频和转录片段聚焦于‘会话中是否进行了延长暴露?’的开始。请识别该精确开始在给定片段中的归一化偏移(0.0到1.0)之间。” - 模型输入:将音频片段
Aj、转录文本Tj和提示P联合输入到模型中。Qwen2-Audio模型内部会处理这种交错的音频和文本输入。 - 模型输出与预测:模型
M输出一个预测的归一化偏移量o_hat_j。该值通过反归一化(o_hat_j * D_j + t_start)得到绝对时间戳的预测值。 - 损失计算:使用预测偏移量
o_hat_j与真实偏移量oj之间的均方误差(MSE)作为损失函数进行训练。
主要组件与数据流:
- 输入层:处理音频波形、转录文本和提示字符串,将它们转换为模型可处理的格式。
- Qwen2-Audio骨干网络:这是预训练的大型音频-语言模型,包含一个音频编码器和一个大语言模型主干。它负责理解音频的声学内容和转录的语义信息,并进行跨模态融合。其内部通过交叉注意力等机制联合建模音频和文本。
- LoRA适配器:在冻结的Qwen2-Audio大语言模型主干的特定层(如注意力层)注入低秩适配矩阵。这是参数高效微调(PEFT)的核心,允许只更新少量参数(适配器权重)来适应新任务。
- 回归头:一个新添加的、从头训练的组件。它接收大语言模型主干最后一个非填充令牌的最终隐藏状态作为输入。其结构为:
LayerNorm -> Linear (hidden_dim -> hidden_dim) -> ReLU -> Linear (hidden_dim -> 1) -> Sigmoid。Sigmoid函数确保输出值在[0,1]区间内,符合归一化偏移量的定义。
关键设计选择与动机:
- 使用音频-语言模型而非纯文本模型:动机在于治疗阶段的转换往往伴随着停顿、语调变化等副语言线索,这些信息在文本转录中会丢失,但音频中存在。端到端的多模态模型能利用这些更丰富的信号。
- 采用归一化偏移量回归而非分类或绝对时间回归:因为处理的是相对固定的短窗口(30-120秒),预测窗口内的相对位置比预测绝对时间更稳定,且能自然地实现数据增强(在已知边界附近随机采样窗口起始点)。
- 使用LoRA/QLoRA进行微调:动机是计算效率和隐私保护。QLoRA(量化+LoRA)允许在资源有限的设备(如笔记本电脑甚至手机)上运行微调后的模型,使得敏感的患者数据无需离开本地环境。
架构图:
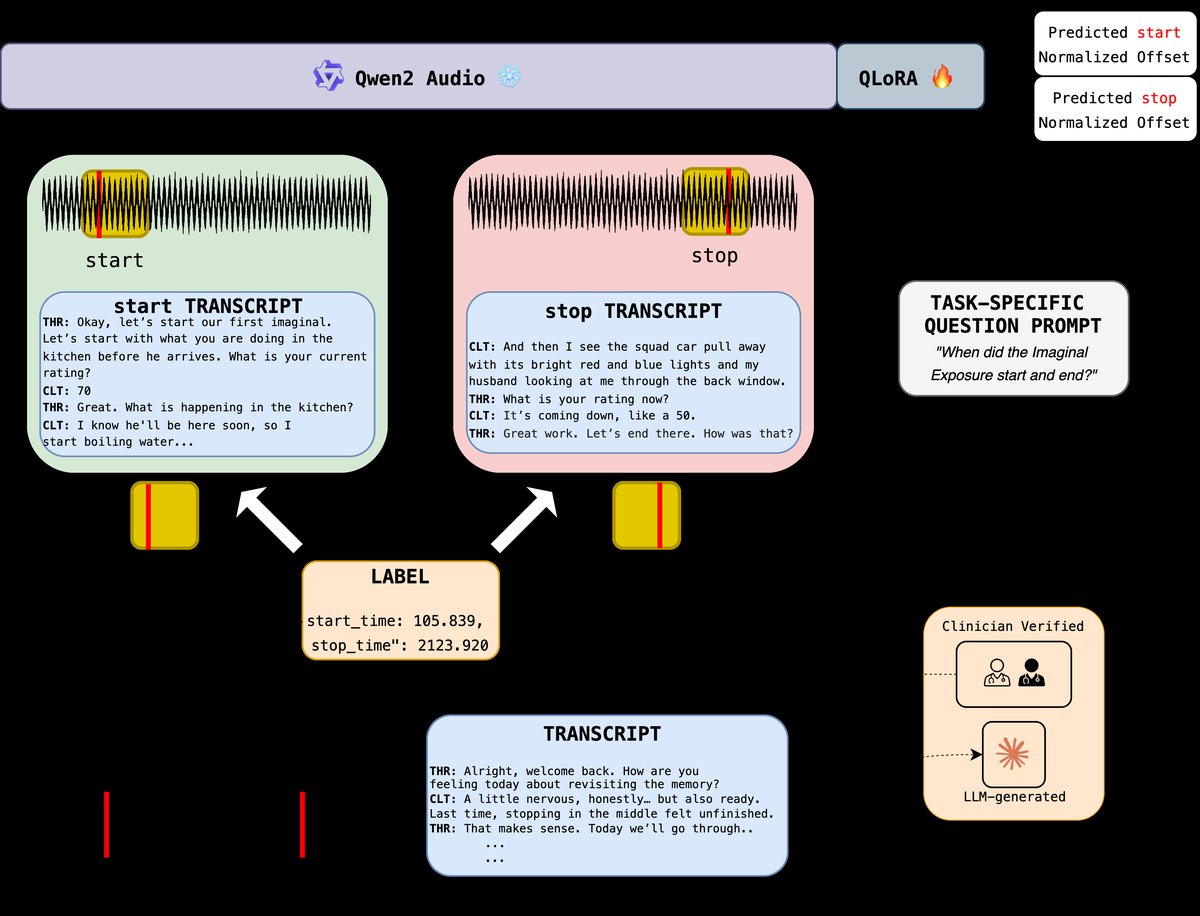
图2清晰地展示了流水线:左侧是输入(音频、转录、提示),中间是经过QLoRA微调的Qwen2-Audio模型(蓝色框内含LoRA适配器),右侧是回归头输出归一化偏移量。下方的流程说明了训练数据(音频-转录窗口)的构造方式,即围绕已知的标注边界点随机采样。
💡 核心创新点
- 临床心理治疗保真度的精确时间定位任务:首次明确地将PE疗法保真度评估从“是/否”或“好/差”的粗粒度分类,定义为需要秒级精度的连续时间定位回归任务。这更符合临床实际(阶段转换是连续过程),并为细粒度评估奠定了基础。
- 结合LLM与人工验证的“软监督”标注策略:针对高质量时间戳标注成本高的问题,创新性地采用零样本LLM从转录文本中初步提取时间戳,再由训练有素的评分者进行验证和修正。这平衡了标注效率与临床准确性,解决了该领域数据标注的瓶颈。
- 系统性地分析上下文粒度与模型适配的权衡:通过详尽的消融实验(窗口大小30/60/120秒,LoRA秩2/4/8),定量揭示了时间定位任务中“上下文”与“精度”的根本矛盾:更长的窗口提供更丰富的语义上下文,却会稀释边界信号,导致定位精度下降。这一发现对类似时间敏感的多模态任务具有指导意义。
- 面向隐私保护的端到端部署框架:不仅关注算法性能,更在设计之初就考虑了临床数据隐私。通过QLoRA将大型云端模型的能力“蒸馏”到可本地运行的量化模型中,确保患者音频数据始终留在安全的本地环境中,解决了临床AI落地的关键障碍。
🔬 细节详述
- 训练数据:
- 数据集:使用Emory大学录制的318个真实PE疗法会谈会话(经排除后保留308个)。平均时长约65分48秒。
- 预处理:音频从44.1-48kHz下采样至16kHz并归一化为WAV格式。转录使用Amazon HealthScribe生成,提供句子级时间戳和说话人标识。
- 数据划分:按会话级划分为训练集(216个)、验证集(45个)和测试集(47个),并确保各治疗阶段(P1, P2, P3)的分布平衡。
- 数据增强:在训练时,对于每个已知边界,会随机采样窗口中心,使得真实边界在窗口内的位置随机化,从而增强模型的鲁棒性。
- 损失函数:
- 名称:均方误差(Mean Squared Error, MSE)损失。
- 作用:衡量预测的归一化偏移量
o_hat_j与真实归一化偏移量oj之间的差异。优化目标是使该差异最小化。 - 论文中未提及损失函数的具体权重或其他复杂设计。
- 训练策略:
- 优化器:AdamW优化器。
- 学习率:
1 × 10^-4,采用余弦退火调度(cosine schedule),预热比例(warmup ratio)为0.1。 - 权重衰减:0.01。
- 训练轮数:最多10个epoch。
- 批大小:1。
- 早停策略:基于验证集MAE,耐心(patience)为3个epoch。
- 硬件与时间:论文中未提供具体的GPU型号、数量或训练时长。
- 关键超参数:
- 基础模型:Qwen2-Audio-7B-Instruct。
- 量化:4-bit NormalFloat (NF4) 量化,计算使用bfloat16精度。
- LoRA配置:应用于大语言模型组件,秩
r∈ {2, 4, 8},缩放因子α = 2r,丢弃率(dropout)为0.1。 - 回归头结构:LayerNorm -> Linear (维度未说明) -> ReLU -> Linear -> Sigmoid。
- 随机种子:使用三个随机种子(42, 78, 123)进行实验,报告平均值±标准差。
- 推理细节:
- 论文未提及推理时的特殊策略(如温度、beam size)。从任务性质看,是直接回归出一个连续值,无需解码策略。
- 模型在推理时处理单个音频-转录-提示输入,输出一个预测的偏移量。
- 正则化技巧:
- LoRA层本身带有的Dropout(0.1)。
- 使用早停防止过拟合。
- 使用权重衰减。
📊 实验结果
主要 Benchmark 和结果: 论文在一个自定义的内部数据集上评估,主要指标是平均绝对误差(MAE,单位:秒)。关键结果表格如下:
| 窗口配置 | 模型配置 | P1 平均 MAE | P1 开始 MAE | P1 结束 MAE | P2 平均 MAE | P2 开始 MAE | P2 结束 MAE | P3 平均 MAE | P3 开始 MAE | P3 结束 MAE |
|---|---|---|---|---|---|---|---|---|---|---|
| 30s | Head Only | 6.8 ± 0.1 | 6.4 ± 0.2 | 7.0 ± 0.3 | 7.2 ± 0.2 | 7.2 ± 0.2 | 7.3 ± 0.3 | 6.8 ± 0.2 | 7.7 ± 0.6 | 5.8 ± 0.4 |
| LoRA (r=2) | 5.8 ± 1.7 | 6.0 ± 1.5 | 5.6 ± 2.2 | 5.1 ± 2.3 | 5.7 ± 2.7 | 4.4 ± 2.3 | 4.8 ± 2.0 | 5.2 ± 3.0 | 4.4 ± 1.9 | |
| LoRA (r=4) | 6.2 ± 1.3 | 6.2 ± 2.0 | 6.0 ± 1.2 | 5.4 ± 2.0 | 5.4 ± 2.2 | 5.5 ± 2.0 | 4.9 ± 1.5 | 5.2 ± 2.0 | 4.6 ± 1.4 | |
| LoRA (r=8) | 5.9 ± 1.4 | 5.5 ± 1.5 | 6.4 ± 1.4 | 5.0 ± 1.8 | 5.2 ± 1.8 | 4.9 ± 1.8 | 5.0 ± 0.5 | 5.5 ± 1.8 | 4.4 ± 0.8 | |
| 60s | Head Only | 12.2 ± 0.8 | 11.5 ± 1.0 | 12.9 ± 0.7 | 13.9 ± 0.5 | 13.4 ± 2.2 | 14.4 ± 1.2 | 13.7 ± 0.6 | 15.3 ± 1.1 | 12.2 ± 0.6 |
| LoRA (r=2) | 11.3 ± 2.5 | 11.5 ± 2.9 | 11.2 ± 2.6 | 12.1 ± 3.1 | 12.8 ± 3.0 | 11.4 ± 3.3 | 12.1 ± 2.9 | 13.4 ± 2.6 | 10.8 ± 3.4 | |
| LoRA (r=4) | 11.9 ± 2.1 | 11.0 ± 2.1 | 12.7 ± 2.0 | 10.2 ± 2.0 | 10.5 ± 2.3 | 9.9 ± 2.1 | 11.6 ± 1.4 | 11.3 ± 1.0 | 11.8 ± 2.4 | |
| LoRA (r=8) | 9.9 ± 0.1 | 9.6 ± 0.8 | 10.2 ± 0.7 | 9.7 ± 0.6 | 10.2 ± 0.9 | 9.2 ± 0.4 | 10.0 ± 0.6 | 9.8 ± 1.6 | 10.1 ± 0.5 | |
| 120s | Head Only | 25.2 ± 2.2 | 25.0 ± 2.4 | 25.4 ± 2.0 | 27.4 ± 0.7 | 25.1 ± 1.3 | 29.6 ± 2.8 | 24.4 ± 2.7 | 28.1 ± 3.1 | 20.8 ± 2.4 |
| LoRA (r=2) | 20.7 ± 2.1 | 20.8 ± 2.0 | 20.5 ± 2.5 | 18.0 ± 2.3 | 17.5 ± 2.6 | 18.5 ± 2.3 | 21.4 ± 1.2 | 22.6 ± 0.9 | 20.2 ± 1.8 | |
| LoRA (r=4) | 20.7 ± 1.8 | 21.4 ± 2.1 | 19.9 ± 2.1 | 18.8 ± 2.1 | 18.3 ± 3.7 | 19.2 ± 1.9 | 21.0 ± 1.2 | 20.3 ± 2.4 | 21.7 ± 0.5 | |
| LoRA (r=8) | 20.1 ± 1.4 | 20.3 ± 1.2 | 19.8 ± 1.8 | 20.7 ± 1.9 | 21.7 ± 2.3 | 19.6 ± 1.5 | 22.3 ± 1.3 | 23.5 ± 3.5 | 21.2 ± 1.7 |
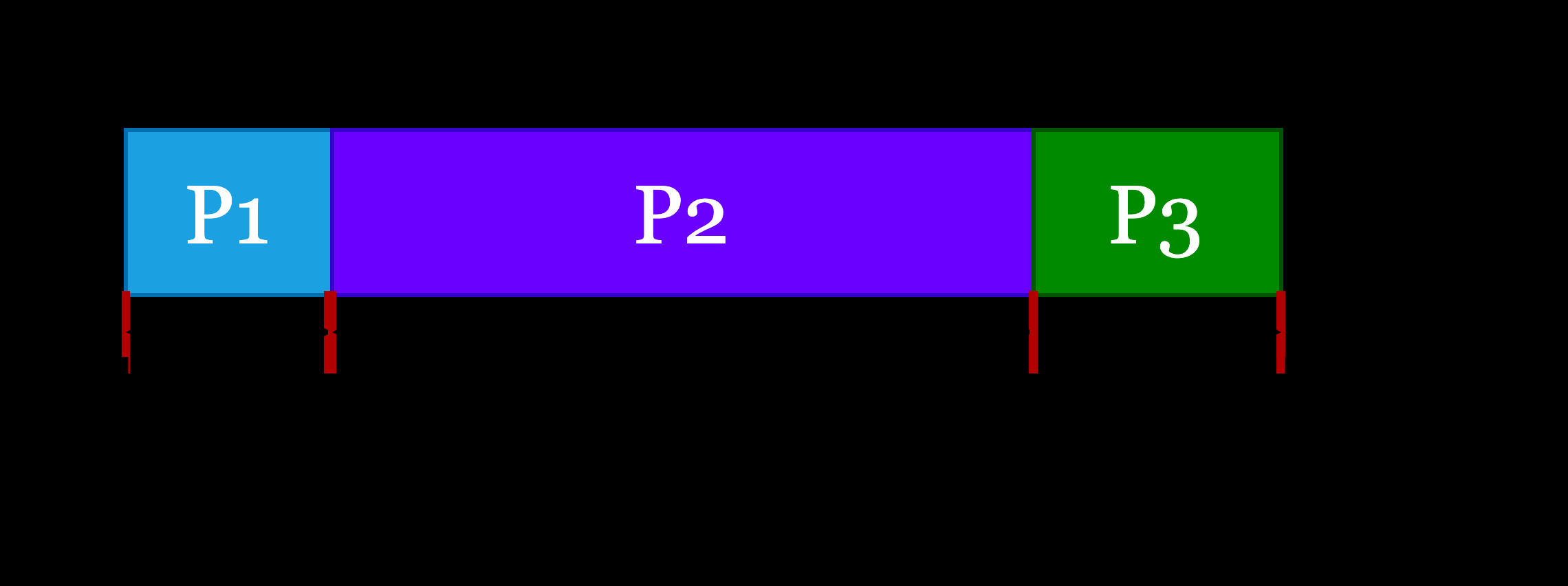 图1直观展示了典型PE会谈的阶段时间分布,说明了任务的背景和时间跨度。
图1直观展示了典型PE会谈的阶段时间分布,说明了任务的背景和时间跨度。
关键结论:
- 窗口大小是决定性因素:30秒窗口在所有配置下均显著优于60秒和120秒窗口。例如,使用“Head Only”模型,P1平均MAE从30秒的6.8秒恶化到60秒的12.2秒,再到120秒的25.2秒。这证实了“上下文粒度权衡”:更短的窗口能提供更锐利的边界定位。
- LoRA微调有效:在所有窗口大小下,LoRA微调普遍优于仅训练回归头的“Head Only”基线,尤其在60秒和120秒长窗口中,优势更明显(如60s窗口下P2平均MAE从13.9降至9.7秒)。这表明参数高效适配对于调整预训练模型的多模态表征至关重要。
- 最佳配置:30秒窗口 + LoRA (r=8) 是整体最佳配置,实现了平均5.3秒的MAE,达到了论文声称的“在评级者可接受的审查容差之内”的实用水平。
- 过拟合风险:在长窗口(120秒)下,较高的LoRA秩(r=8)在部分指标上反而劣于较低秩(如P2平均MAE,r=2为18.0秒,r=8为20.7秒)。这表明在上下文过长、信号稀释的情况下,更小的适配器可能泛化得更好。
与基线对比:论文的主要对比对象是自身的“Head Only”变体,用以证明LoRA微调的必要性。文中提到“先前使用独立音频和文本编码器的特征级融合尝试”效果不佳,但未提供这些基线的具体数据。因此,与外部SOTA方法的差距无法量化。
⚖️ 评分理由
- 学术质量:5.5/7:论文技术方案完整,从问题建模、数据标注到模型设计、实验分析逻辑清晰。创新点明确,尤其在任务定义和实验分析(上下文粒度)上有贡献。扣分主要因为:1)实验局限在一个特定、未公开的数据集上,且数据规模中等;2)缺乏与领域内或更通用任务上现有最强模型(如更强的多模态模型、专门的时间定位模型)的对比,使得性能评估的绝对水平难以定位;3)回归头的具体结构描述不够详细(如线性层维度)。
- 选题价值:1.0/2:选题具有明确的社会价值和临床意义,为心理治疗质量控制提供了新的技术工具。但其高度垂直的领域属性(仅限PE疗法)限制了其在更广泛的音频/语音处理研究社区中的直接影响力。对于专注于医疗AI或特定临床应用的读者,价值会更高。
- 开源与复现加成:0/1:论文明确使用了公开的预训练模型(Qwen2-Audio)和转录工具(HealthScribe),这为复现提供了基础。然而,核心的实验数据集、微调后的模型权重、以及用于生成训练数据的完整代码均未公开。这使得他人无法直接复现论文中的实验,只能重复类似的方法论。