📄 Fine-Tuning Bigvgan-V2 for Robust Musical Tuning Preservation
#音乐生成 #领域适应 #数据增强 #声码器 #鲁棒性
✅ 7.5/10 | 前25% | #音乐生成 | #领域适应 | #数据增强 #声码器
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文作者列表按字母顺序排列,未明确指出第一作者)
- 通讯作者:未说明(论文中未明确标注通讯作者)
- 作者列表:Hans-Ulrich Berendes(国际音频实验室埃尔兰根)、Ben Maman(国际音频实验室埃尔兰根)、Meinard Müller(国际音频实验室埃尔兰根)
💡 毒舌点评
亮点:论文精准地抓住了神经声码器在音乐处理中的一个“阿喀琉斯之踵”——调音偏差,并用一套非常工整的实验设计(构建调音均匀分布测试集、对比不同调音分布训练数据、结合客观指标与主观听测)给出了令人信服的解决方案,证明了即使低分辨率模型也能通过针对性适应达到高分辨率模型的性能。短板:其本质是对现有模型(BigVGAN-V2)的微调应用,核心方法(领域适应、数据增强)并非原创;此外,论文未开源代码和模型,复现依赖项目主页上的有限资源,对推动该方向的快速跟进略有阻碍。
🔗 开源详情
- 代码:论文中未提及代码链接。项目主页(https://www.audiolabs-erlangen.de/resources/MIR/2026-ICASSP-VocoderFineTuning)提供了一些音频示例,但未说明是否包含微调代码。
- 模型权重:未提及。微调后的模型权重未公开。
- 数据集:未公开。使用的内部古典音乐数据集未提供。
- Demo:项目主页提供了听测示例音频和更多示例,可视为一种有限形式的Demo。
- 复现材料:论文提供了微调的基本设置(数据集构建方法、训练步数、基线模型信息),但缺少关键的训练超参数(学习率、优化器等)、硬件配置和完整的数据处理/训练脚本。复现需要依赖BigVGAN-V2的官方代码库。
- 论文中引用的开源项目:
- BigVGAN-V2:作为基础和对比模型。
- Rubber Band库:用于音高偏移数据增强。
- librosa 和 libfmp:用于调音估计。
- 开源计划:论文中未提及明确的开源计划。
📌 核心摘要
本文针对神经声码器(以BigVGAN-V2为例)在处理非标准调音音频时产生的音高偏移(调音偏差)问题,提出了通过微调来缓解该问题的解决方案。方法核心是构建包含不同调音分布的训练数据集(自然调音分布、均匀调音分布、通过音高偏移增强的均匀调音分布),并在这些数据集上对BigVGAN-V2的80频段版本进行微调。与现有工作相比,新在首次系统研究了如何通过数据策略而非增加模型复杂度(如使用更高频段)来解决调音偏差问题,并证明了数据增强方法的有效性。主要实验结果表明,使用均匀分布数据(特别是通过音高偏移增强的数据)微调后,80频段模型的调音保持精度(平均偏差<3 cents)达到了未微调的128频段模型的水平,且主观听测显示微调模型在非标准调音(尤其是钢琴)下更受偏好。该工作的实际意义在于提供了一种计算高效且鲁棒的方案,使轻量级声码器能可靠地应用于多样化调音条件下的音乐合成。主要局限性在于该解决方案针对BigVGAN-V2模型,其泛化性到其他声码器架构有待验证;且研究局限于西方音乐系统,未涉及非西方调音体系。
🏗️ 模型架构
论文主要研究对象为BigVGAN-V2声码器,并未提出新的模型架构,而是对其进行微调。
- 模型基础:使用公开预训练的BigVGAN-V2模型,具体配置为80个梅尔频带(mel bands),采样率22.05 kHz。该模型基于生成对抗网络(GAN),从梅尔频谱图生成时域音频信号。
- 输入输出:输入为音频的梅尔频谱图(由80个梅尔频带构成),输出为重建的时域音频波形。
- 关键组件与数据流:BigVGAN-V2本身包含一个生成器和一个判别器。在微调过程中,主要优化生成器以使其能准确保持输入音频的调音信息。生成器的内部架构细节(如上采样层、残差块等)遵循原始BigVGAN-V2设计,论文中未详细展开,读者需参考原论文。
- 关键设计选择:选择80频段版本进行微调,因为它计算更轻量,但存在已知的调音偏差问题,这使得研究更具挑战性和实用价值。微调的目标是弥补低频段分辨率在调音信息保留上的不足。
- 架构图:论文中未提供描述该微调方法或模型内部细节的架构图。
💡 核心创新点
- 系统性的问题验证与解决方案:不仅证实了BigVGAN-V2 80频段版本存在调音偏差,更重要的是,系统地设计了基于不同调音分布训练数据的微调策略来解决此问题。相比之前仅观察到偏差现象的工作,本文提供了完整的解决方案。
- 证明了数据分布对调音鲁棒性的决定性影响:通过对比
Norm(自然分布)、Unif(均匀分布)和Unif-PS(音高偏移增强的均匀分布)三种训练数据,明确指出,训练数据中调音分布的多样性和均衡性是消除偏差的关键,而非单纯依赖模型参数量或频段分辨率。 - 实现了“低成本高性能”的优化:证明了经过针对性数据适应微调的轻量级80频段模型,可以达到与计算成本更高的128频段模型相当的调音保持性能,为资源受限场景提供了高效解决方案。
🔬 细节详述
- 训练数据:
- 来源:大型内部西方古典音乐录音数据集(包括室内乐、管弦乐、歌剧、独奏)。
- 预处理与筛选:使用两种调音估计器(
TempMatch和FreqHist)对所有录音进行调音估计。只保留两者估计差值≤5 cents的录音(约90%),以确保调音稳定、可检测,得到Full数据集。 - 数据集构建:
Test集:从Full中按调音值τ在[-50, 49]范围内均匀采样,每个τ值选取10个录音,共1000个,约70小时。Full-Train:Full中移除Test后的剩余部分。Norm训练集:从Full-Train中随机采样,复制其自然调音分布。Unif训练集:从Full-Train中采样,使其调音分布近似均匀。Unif-PS训练集:仅使用τ≈0的录音,通过Rubber Band库进行音高偏移(pitch-shift)增强,生成调音均匀分布的数据。
- 规模:每个训练子集约550小时。
- 损失函数:未说明。论文指出微调使用与原始BigVGAN-V2实现相同的超参数,推测其损失函数也应与原模型一致(包括生成器损失、判别器损失、特征匹配损失等)。
- 训练策略:
- 微调步数:100,000步(相比原始模型的500万步预训练较短,但已收敛)。
- 超参数:与原始BigVGAN-V2实现相同。
- 优化器/学习率/调度策略:未说明。
- 基线模型:使用公开的BigVGAN-V2 80频段(
BV2-80)和128频段(BV2-128,采样率44.1kHz)预训练模型。
- 关键超参数:主要对比配置为80梅尔频带 vs. 128梅尔频带。
- 训练硬件:未说明。
- 推理细节:未说明具体解码策略。评估时,对
Test集中所有音频计算其梅尔频谱图,然后使用各声码器模型进行“vocoding”(重建波形)。 - 评估指标:
- 调音偏差:计算原始调音
τ与重建音频调音̂τ之间的圆形差值δcirc(公式1),并报告平均绝对差µ(|δcirc|)。同时计算输入与输出调音分布之间的圆形Wasser斯坦距离(CWD)。 - 调音估计器:使用
TempMatch和FreqHist两种互补的估计器,分辨率1 cent。 - 主观评估:AB偏好测试,比较原始
BV2-80与微调模型生成的音频,让听众选择偏好的版本或无偏好。
- 调音偏差:计算原始调音
📊 实验结果
主要实验:调音保持评估(Table 1)
在均匀调音分布的Test集上评估:
| 模型 | µ(|δcirc|) [cents] | CWD |
| :— | :—: | :—: |
| | TempMatch | FreqHist | TempMatch | FreqHist |
|—|—|—|—|—|
| BV2-80 | 5.8 | 5.5 | 6.1 | 4.8 |
| BV2-80-Norm | 4.3 | 3.9 | 4.2 | 2.4 |
| BV2-80-Unif | 2.6 | 3.2 | 1.8 | 1.6 |
| BV2-80-Unif-PS | 2.4 | 2.9 | 1.3 | 1.4 |
| BV2-128 | 2.1 | 3.0 | 2.1 | 1.6 |
结论:未经微调的BV2-80偏差最大。微调后,使用均匀分布数据(Unif, Unif-PS)的模型偏差显著降低,达到甚至优于BV2-128的水平。
偏差分布可视化(Fig. 2 & Fig. 3)
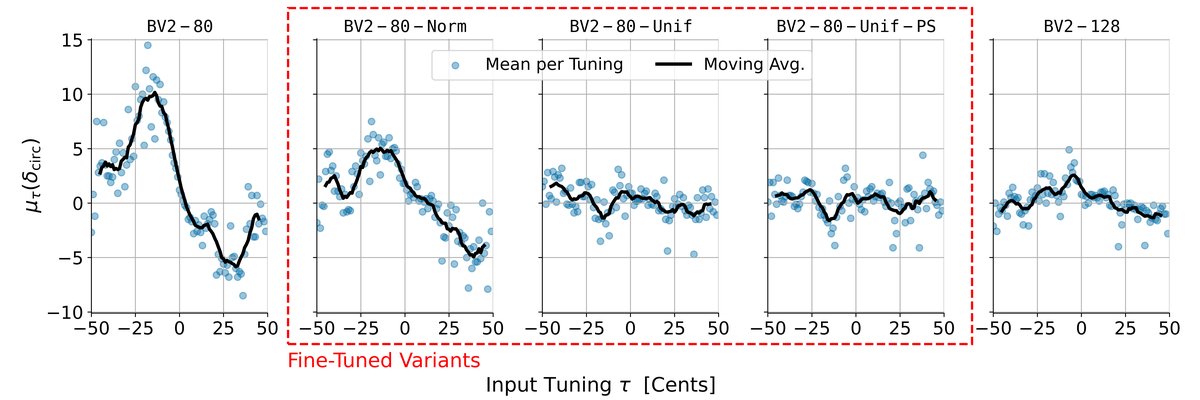 Fig. 2 显示了各模型在每个输入调音
Fig. 2 显示了各模型在每个输入调音τ下的平均偏差µτ(δcirc)。BV2-80在τ=-20和τ=+25附近出现峰值偏差,显示出向标准调音τ=0的偏移倾向。微调后的模型(如BV2-80-Unif)的偏差曲线更平坦,且波动范围缩小至±5 cents以内,与BV2-128表现相近。
Fig. 3 为调音散点图,显示了τ与̂τ的关系。(a) BV2-80的样本点明显偏离对角线(τ=̂τ),尤其在非标准调音区域。(b) BV2-80-Unif的样本点紧密围绕对角线分布,证明其调音保持能力大幅提升。
主观听测(Table 2 & Fig. 4)
| 模型 | 微调模型偏好 | BV2-80偏好 | 无偏好 |
|---|---|---|---|
| BV2-80-Unif | 33.75% | 8.75% | 57.50% |
| BV2-80-Unif-PS | 37.50% | 13.75% | 48.75% |
结论:在决定投票中,微调模型明显更受青睐。按乐器类型细分(Fig. 4,以BV2-80-Unif为例),对于钢琴片段,在非标准调音(τ= -39, 42)下,对微调模型的偏好显著高于无偏好选项;对于管弦乐片段,听众则普遍更倾向于选择“无偏好”。这表明调音偏差对听感的影响与乐器音高离散性有关。 |
⚖️ 评分理由
- 学术质量:5.5/7 - 论文技术路线正确,实验设计系统且严谨,数据集构建有巧思(尤其是均匀调音测试集),客观与主观评估相结合,结果清晰、可信。主要不足是创新点集中于应用和验证,而非方法学的突破。
- 选题价值:1.5/2 - 该问题(声码器调音偏差)是音乐合成领域一个具体但重要的痛点,直接影响合成质量。论文提出的解决方案具有明确的实际应用价值和参考意义。
- 开源与复现加成:0.5/1 - 论文提供了项目主页和示例音频,有助于理解和评估。但未公开代码、模型权重或详细训练脚本,复现依赖于官方BigVGAN的公开资源及论文描述,便利性一般。