📄 Fine-Grained Frame Modeling in Multi-Head Self-Attention for Speech Deepfake Detection
#语音伪造检测 #自监督学习 #模型评估 #Conformer
🔥 8.0/10 | 前25% | #语音伪造检测 | #自监督学习 | #模型评估 #Conformer
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Phuong Tuan Dat (河内科技大学信息与通信技术学院)
- 通讯作者:Nguyen Thi Thu Trang (河内科技大学信息与通信技术学院)
- 作者列表:Phuong Tuan Dat (河内科技大学信息与通信技术学院), Duc-Tuan Truong (南洋理工大学计算与数据科学学院), Long-Vu Hoang (河内科技大学信息与通信技术学院), Nguyen Thi Thu Trang (河内科技大学信息与通信技术学院)
💡 毒舌点评
亮点:论文将细粒度视觉分类的“投票选择”思想巧妙移植到语音领域,通过显式建模注意力头的“专长”并选择性聚合关键帧,有效解决了标准MHSA可能忽略局部伪造伪影的问题,方法新颖且有效。短板:高斯核增强的卷积核是固定的([1, 2, 3, 4, 3, 2, 1]),缺乏理论依据或可学习性分析;且所选关键帧数量v需人工调优,在不同音频长度或任务下可能不具备普适性。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用公开数据集(ASVspoof 2019, ASVspoof 2021, In-the-Wild),但未说明如何获取本文实验所用的具体版本或预处理后的数据。
- Demo:未提及。
- 复现材料:论文描述了模型架构和主要超参数(如
v=24),但未提供训练脚本、详细超参数(学习率、优化器等)、配置文件或检查点。复现需要较多额外工作。 - 引用的开源项目:论文中引用并依赖了预训练模型XLS-R作为特征提取器。
📌 核心摘要
- 问题:基于Transformer的语音深度伪造检测模型虽然强大,但其多头自注意力机制倾向于生成全局聚合特征,可能忽略或稀释伪造语音中局部、短暂的细微伪影,导致检测漏洞。
- 核心方法:提出细粒度帧建模(FGFM)框架,包含两个核心模块:a) 多头投票(MHV)模块:将每个注意力头视为弱学习器,通过投票机制为每个头选择信息量最大的
v个语音帧,并用高斯核卷积增强选择结果;b) 跨层精炼(CLR)模块:将不同层选出的关键帧与分类符拼接输入额外的Transformer块,并通过并行的交叉注意力进行双向信息交换和融合,最终用DAFF模块聚合得到精炼的分类特征。 - 创新点:首次将细粒度视觉分类中的内部集成学习(投票)思想应用于语音伪造检测,显式利用多头注意力头的多样性,并设计了跨层信息聚合机制来增强关键帧特征的表示。
- 主要实验结果:在ASVspoof 2021 LA、DF和In-the-Wild(ITW)三个基准测试上,FGFM将强基线XLSR-Conformer的EER分别从0.97%、2.58%、8.42%降低至0.90%、1.88%、6.64%,在ITW数据集上取得了当时的最优性能。消融实验证明MHV中的增强操作和CLR中的DAFF模块均对性能有显著贡献。
| 模型 | EER (%) | ||
|---|---|---|---|
| 21LA | 21DF | ITW | |
| XLSR-Conformer [17]† (基线) | 0.97 | 2.58 | 8.42 |
| + FGFM (本文) | 0.90 | 1.88 | 6.64 |
| XLSR-Mamba [28] | 0.93 | 1.88 | 6.71 |
| XLSR-SLS [26] | 5.08 | 1.92 | 7.46 |
| XLSR-AASIST [23] | 1.00 | 3.69 | 10.46 |
- 实际意义:为语音深度伪造检测提供了一种新的、可插拔的模块化改进方案,能有效提升现有MHSA基模型对局部伪影的敏感性,增强模型在跨域场景下的鲁棒性。
- 主要局限性:a) 引入了额外的计算开销(两个额外的Conformer块和复杂的模块);b) MHV模块中选择的帧数量
v是超参数,需要根据数据分布调整;c) 论文未提供代码,阻碍了快速验证和应用。
🏗️ 模型架构
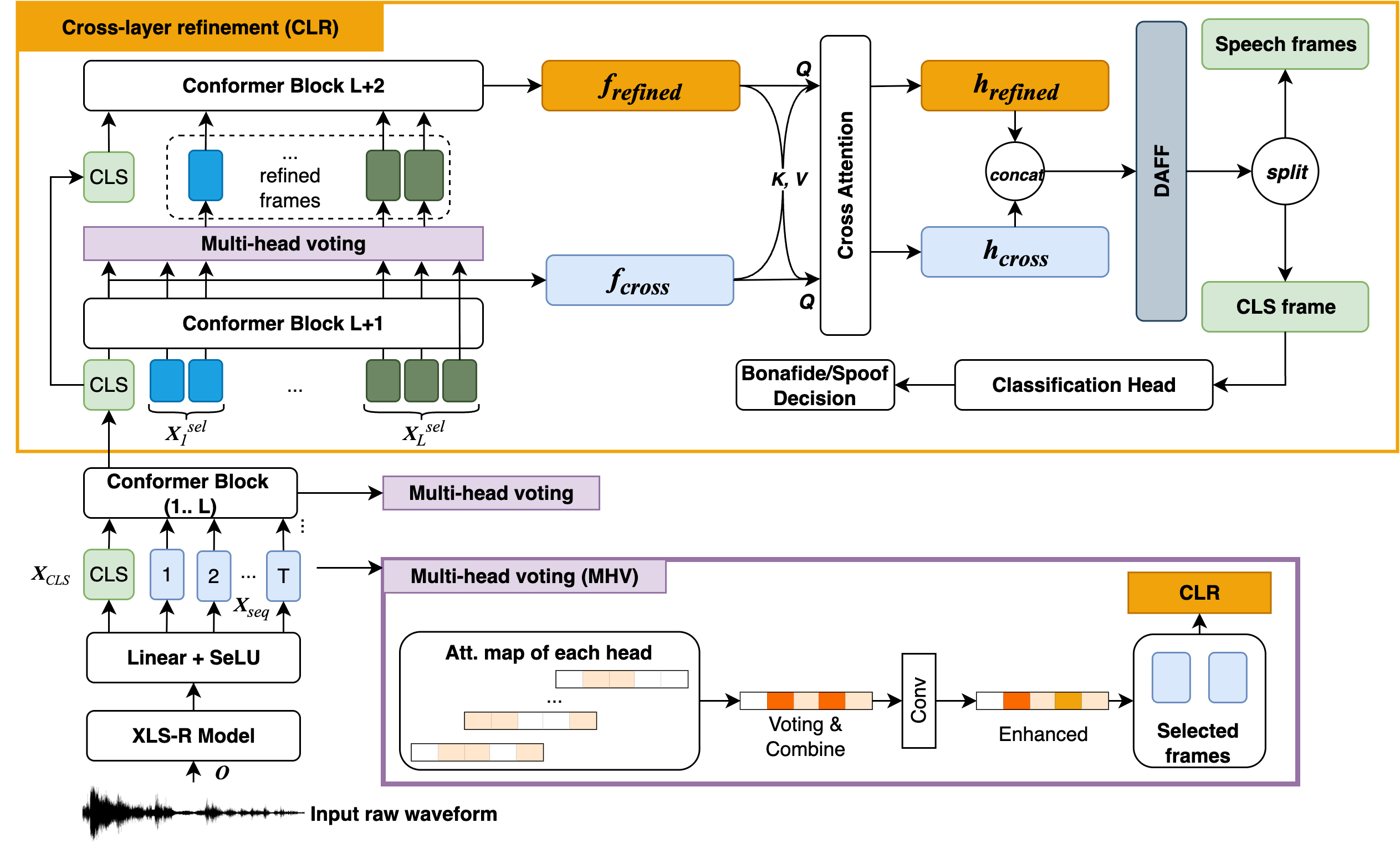 整体架构(如图1所示):本文的FGFM模型建立在XLSR-Conformer基线模型之上。流程如下:
整体架构(如图1所示):本文的FGFM模型建立在XLSR-Conformer基线模型之上。流程如下:
- 输入处理:输入语音信号经预训练的XLS-R模型提取帧级特征,再通过线性层投影。在序列前添加一个可学习的分类符
X_cls,构成完整的编码器输入。 - 基线编码器:输入序列通过L个(原文为4个)标准的Conformer块(内含MHSA),每个块输出中间表示。每个MHSA会产生K个头的注意力图。
- 细粒度帧建模(FGFM)核心:
MHV模块(应用于每个Conformer块的输出):针对每个注意力头(共K个),根据其注意力分数选择
v个得分最高的帧,标记为二进制掩码。将所有头的掩码相加,并用一维高斯核G=[1,2,3,4,3,2,1]进行卷积平滑,得到最终的精炼掩码M。根据此掩码从当前块的输出中选取v个关键帧表示X_sel^l。- CLR模块:在L个基线块之后,执行以下操作:
- 跨层聚合:将最后一个块的分类符
X_cls^L与所有前面各层选出的关键帧X_sel^1 ... X_sel^L拼接,输入第(L+1)个额外的Conformer块。该块的输出包含聚合了跨层信息的特征f_cross和新的关键帧X_sel^{L+1}。 - 精炼层:将
X_cls^L与X_sel^{L+1}拼接,输入第(L+2)个额外的Conformer块。该块的输出为精炼特征f_refined。 - 双向交叉注意力:
f_cross和f_refined分别作为查询、键、值,进行双向交叉注意力计算,交换信息,得到增强的h_cross和h_refined。 - 特征融合:将
[h_cross; h_refined]输入一个轻量级的DAFF块进行融合,输出最终的分类符特征。
- 跨层聚合:将最后一个块的分类符
- CLR模块:在L个基线块之后,执行以下操作:
- 分类:最终的分类符特征送入分类头,输出真伪概率。
💡 核心创新点
多头投票(MHV)帧选择机制:
- 是什么:将MHSA的每个注意力头视为一个“弱分类器”,通过类似bagging的投票策略,让每个头独立选择其认为重要的
v个帧,再综合所有头的结果来定位最关键的语音区域。 - 之前局限:标准MHSA对所有帧进行加权平均,无法显式地、选择性地聚焦于少数可能包含伪影的异常帧。
- 如何起作用:利用注意力头对不同声学模式敏感的特性,鼓励模型从多个视角挖掘异常信号。高斯核卷积有助于平滑选择结果,避免选择孤立的噪声帧。
- 收益:在多个基准测试上显著降低了EER,消融实验证明该模块(含高斯增强)对性能提升至关重要。
- 是什么:将MHSA的每个注意力头视为一个“弱分类器”,通过类似bagging的投票策略,让每个头独立选择其认为重要的
跨层精炼(CLR)模块:
- 是什么:通过额外的编码块,将不同深度层选出的关键帧信息进行拼接和融合,并利用双向交叉注意力促进跨层特征交互。
- 之前局限:基线模型中,不同层提取的特征直接传递,缺乏对各层选出的“关键证据”进行显式聚合和提炼的机制。
- 如何起作用:强制模型整合不同抽象层级上被认为重要的帧信息,并通过交叉注意力让这些信息相互“交流”和增强。
- 收益:与MHV协同工作,使得最终分类特征既包含了各层精炼的局部信息,又获得了跨层的上下文理解,提升了特征的判别力。消融实验显示去除DAFF模块(CLR的组成部分)会导致性能下降。
从视觉到语音的跨领域迁移:
- 是什么:成功将原本用于细粒度图像分类(如区分不同鸟类)的内部集成学习思想(多头投票)迁移到了语音伪造检测任务。
- 之前局限:该思想在语音领域未被充分探索和应用。
- 如何起作用:将语音帧视为“视觉区域”,伪造伪影视为“细微差异”,利用MHSA的多头特性模拟多视角观察。
- 收益:拓展了该思想的应用场景,并证明了其在捕捉语音中局部异常信号方面的有效性。
🔬 细节详述
- 训练数据:所有模型在ASVspoof 2019 LA训练集上训练。预处理细节未说明(如是否统一长度、采样率等)。
- 损失函数:论文未明确说明使用的损失函数,通常为二元交叉熵。
- 训练策略:论文指出“训练设置与基线保持一致”,但未提供具体的学习率、优化器、batch size、训练轮数等细节。
- 关键超参数:
- 基线Conformer块数:L=4。
- CLR模块额外Conformer块数:2个。
- MHSA头数K:未说明。
- MHV模块中每个头选择的帧数:
v=24(通过实验确定)。 - 高斯增强核:固定为
[1, 2, 3, 4, 3, 2, 1]。 - 模型隐藏维度D:未说明。
- 训练硬件:单块NVIDIA A40 GPU。训练时长未说明。
- 推理细节:未提及特殊解码策略或流式设置。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
- 主要基准对比:在ASVspoof 2021 LA (21LA), ASVspoof 2021 DF (21DF), In-the-Wild (ITW)三个数据集上进行测试,指标为EER(%)。本文方法(FGFM)在强基线XLSR-Conformer和XLSR-Transformer上均取得显著提升,并在ITW上取得最优结果。
| 模型 | EER (%) | ||
|---|---|---|---|
| 21LA | 21DF | ITW | |
| XLSR-Conformer [17]† (基线) | 0.97 | 2.58 | 8.42 |
| + FGFM (ours) | 0.90 | 1.88 | 6.64 |
| XLSR-Transformer (基线) | 1.96 | 2.43 | 6.59 |
| + FGFM (ours) | 1.82 | 2.37 | 6.31 |
| XLSR-Mamba [28] | 0.93 | 1.88 | 6.71 |
| XLSR-SLS [26] | 5.08 | 1.92 | 7.46 |
| XLSR-AASIST [23] | 1.00 | 3.69 | 10.46 |
| XLSR-AASIST2 [24] | 1.61 | 2.77 | - |
| XLSR-Conformer+TCM [18]† | 1.18 | 2.25 | 7.79 |
关键消融实验:
- 组件有效性:在XLSR-Conformer基线上,去除DAFF模块导致EER在21LA/21DF/ITW上分别上升8.2%/5.1%/2.7%的相对值;去除MHV中的高斯核增强导致EER分别上升15.6%/8.0%/5.1%的相对值。增加基线深度(L=6)反而性能下降,证明提升来自模块设计而非单纯增加容量。
- 投票数v的影响:
投票数v EER (%) 21LA 21DF ITW 16 1.34 2.04 7.04 24 0.98 1.98 6.82 32 1.69 2.27 6.73 40 1.71 2.84 6.66 注:此表数据对应图2下方的消融实验,具体EER数值与主表1中完整模型的数值(0.90, 1.88, 6.64)略有差异,可能源于实验设置的微小不同(如是否包含CLR模块)。 结果显示
v=24是平衡点,过多会引入无信息帧(如静音)。可视化分析:图2展示了MHV模块选择的帧(红色竖线)在真实和伪造语音频谱上的分布。可见模型倾向于选择语音能量高的区域,避免了静音段,这被认为是有效利用了关键信息。
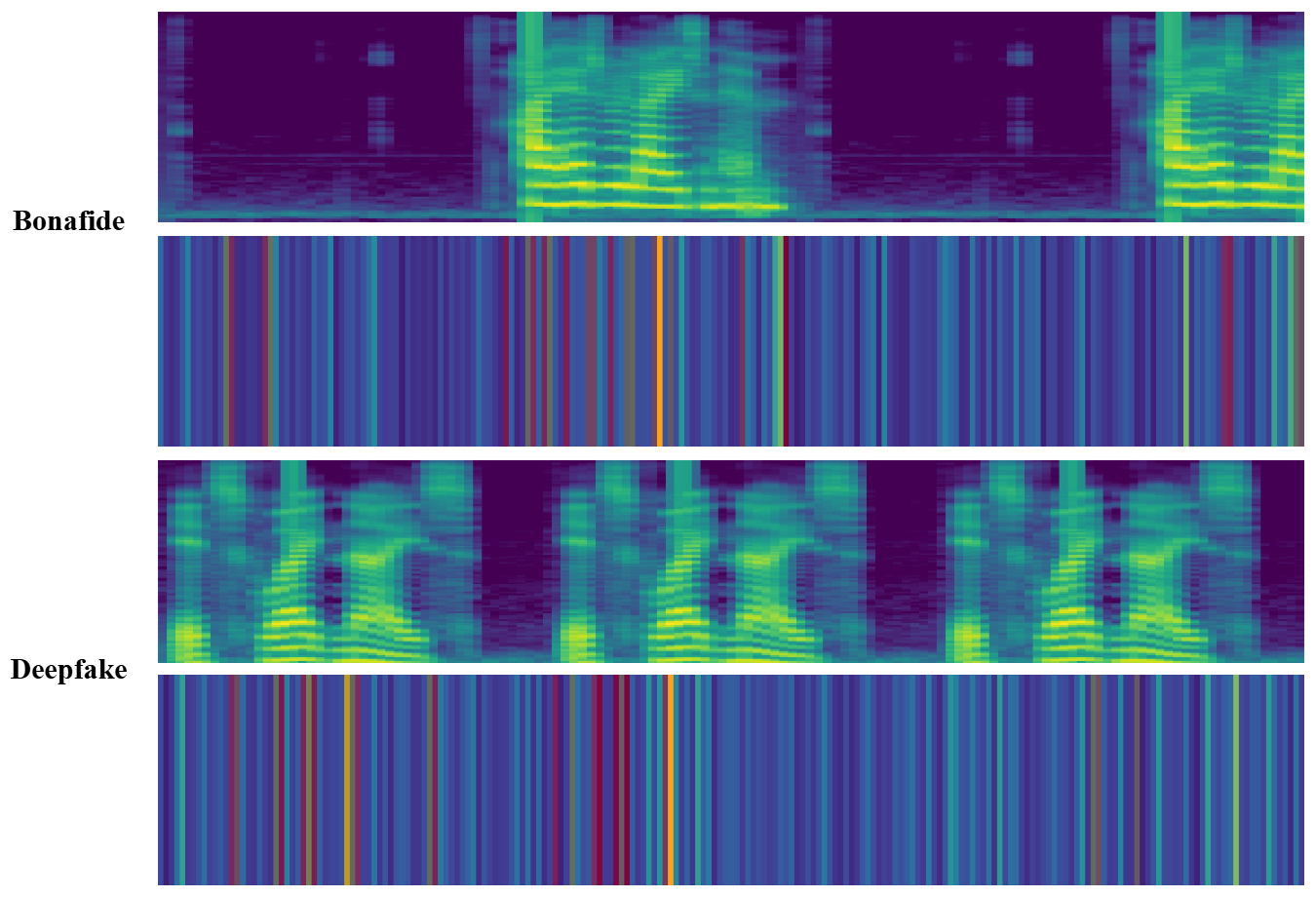 图2说明:MHV模块选择的帧(红色竖线)在真实(上)和伪造(下)语音频谱图上的分布。红色线集中在语音活动区域,表明模型能有效定位富含信息的语音帧。
图2说明:MHV模块选择的帧(红色竖线)在真实(上)和伪造(下)语音频谱图上的分布。红色线集中在语音活动区域,表明模型能有效定位富含信息的语音帧。
⚖️ 评分理由
- 学术质量:6.5/7:论文创新点(MHV, CLR)明确且有理论动机(利用注意力头多样性、捕获局部伪影),技术实现逻辑清晰。实验设计全面,包括与多个强基线的对比、跨域评估、以及详尽的消融研究来验证每个组件和关键超参数,证据充分,结论可靠。扣分点在于创新属于渐进式优化,且部分训练细节缺失。
- 选题价值:1.5/2:语音伪造检测是当前语音安全领域的核心挑战之一,具有重要的学术研究价值和广阔的工业应用前景(如金融、通讯安全)。本文聚焦于提升检测模型对细微伪影的敏感性,直接回应了该领域的需求。
- 开源与复现加成:0.0/1:论文未提及任何代码仓库、模型权重、训练脚本或详细配置文件的开源计划,仅描述了模型架构和实验设置概要,这为其他研究者的复现工作带来了较大障碍。