📄 Few-Shot Recognition of Audio Deepfake Generators using Graph-Based Prototype Adaptation
#音频深度伪造检测 #少样本学习 #图神经网络 #音频取证
✅ 7.5/10 | 前25% | #音频深度伪造检测 | #图神经网络 | #少样本学习 #音频取证
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Yupeng Tan (广西大学计算机、电子信息学院,广西人工智能学院)
- 通讯作者:Wei Xie (广西大学计算机、电子信息学院,广西人工智能学院)
- 作者列表:Yupeng Tan (广西大学计算机、电子信息学院,广西人工智能学院),Wei Xie (广西大学计算机、电子信息学院,广西人工智能学院)
💡 毒舌点评
本文巧妙地将图神经网络与转导学习范式结合,用于解决少样本音频深度伪造生成器识别中因数据稀缺导致的原型估计偏差问题,技术路线完整且实验结果显著优于基线。然而,其核心思想——利用无标签数据(查询集)的结构信息来优化有标签数据的原型表示——在少样本学习领域并非首创(如标签传播等),创新深度有限,且论文未提供任何开源代码或模型权重,对后续研究的可复现性构成障碍。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开模型权重。
- 数据集:使用了公开数据集ASVspoof2019 LA和MLAAD,论文未提及额外数据。
- Demo:未提供在线演示。
- 复现材料:论文提供了一些关键的超参数(如学习率、图top-k值、episode采样数),但缺少训练硬件信息、完整代码配置、权重文件以及Focal Loss和对比损失中的具体超参数(如γ, m)。
- 依赖的开源项目/模型:
- CLAP 音频编码器(论文引用[17])
- 图卷积网络基础架构(论文引用[18])
- Focal Loss(论文引用[19])
- 对比学习框架(论文引用[20])
- 消融实验中使用的RawNet3(论文引用[29])
- 总体评价:论文中未提及完整的开源计划。
📌 核心摘要
- 问题:在音频取证中,识别深伪造音频的具体生成器类型至关重要,但新兴生成器的有标签样本极少,传统少样本方法因数据稀疏导致原型估计偏差大、特征区分度低。
- 方法:提出基于图的原型适应框架。在每个少样本任务中,将支持集和查询集样本构建成一个联合图(基于样本间距离的稀疏连接),通过图适应模块进行信息传播和特征精炼,再估计更可靠的原型进行分类。
- 创新:1)采用转导学习范式,联合利用有标签和支持样本构建任务特定图;2)设计图适应模块,通过图卷积网络精炼特征并校准原型,缓解原型偏差;3)在元测试阶段引入对比损失进行自适应。
- 实验:在ASVspoof2019 LA和MLAAD数据集上的5-way设置中,GPA方法在所有shot数下均取得最优准确率,例如在ASV2019LA上5-shot相比最强基线提升3.17%,10-shot提升6.12%,20-shot提升8.28%。消融实验验证了各组件的必要性。
- 意义:为应对新出现的音频深伪造威胁提供了一种有效的少样本识别方案,增强了音频取证系统对未知生成器的适应能力。
- 局限性:方法依赖预训练的CLAP编码器和特定的图构建策略,计算复杂度随样本数增加;实验仅在两个数据集上进行,对更多样化生成器和真实场景的泛化能力有待验证。
🏗️ 模型架构
模型架构图如图2所示。
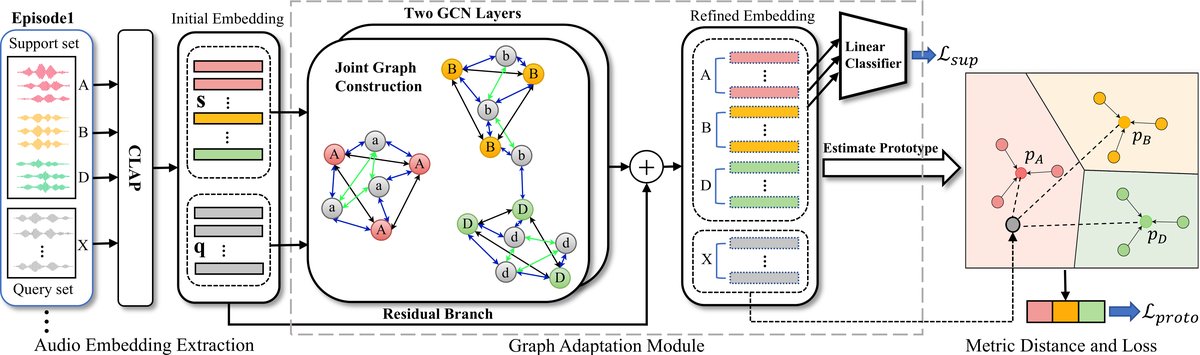
整体流程:对于一个N-way K-shot任务,输入是包含N×K个有标签样本的支持集S和N×M个无标签样本的查询集Q。所有音频样本首先通过预训练的CLAP音频编码器转换为d维嵌入向量。这些嵌入(支持集和查询集)被组织成一个联合图,其中节点是单个样本,边表示样本间的相似性。该图输入到图适应模块中进行处理。经过GAM精炼后,从属于各类的支持节点嵌入中计算出类原型(各类嵌入的均值)。最后,每个查询节点根据其与各类原型的欧氏距离进行分类。
主要组件:
- 预训练CLAP编码器:作为特征提取器,将原始音频转换为语义嵌入空间中的向量。
- 联合图构建模块:为每个任务动态构建图。节点对应所有样本(支持+查询)。边的建立遵循四条规则:同类支持节点间连接;每个支持节点连接其在查询集中的top-k最近邻;查询节点间连接top-k最近邻;所有节点添加自环。边权重为节点间欧氏距离的倒数。这种稀疏连接策略(复杂度O(kn))保留了关键结构,同时降低了计算量。
- 图适应模块:核心组件,由两层图卷积网络和一个残差连接构成。其作用是通过图上的消息传递,融合来自支持集和查询集的结构信息,精炼每个节点的嵌入表示,从而生成更鲁棒、更具区分性的特征,用于后续原型估计。处理后,对支持节点还会施加一个轻量级线性分类器进行显式监督(focal loss)。
- 原型估计与分类:从精炼后的支持节点嵌入中,为每个类别计算一个原型(均值向量)。查询节点通过计算到这些原型的距离进行分类。
数据流与交互:CLAP输出的原始嵌入 -> 构建联合图邻接矩阵 -> GAM通过两层GCN在图上传播信息并更新节点嵌入 -> 从精炼后的支持节点嵌入计算原型 -> 查询节点与原型距离计算分类概率。整个框架采用元学习训练范式。
💡 核心创新点
- 联合图与转导学习范式:
- 是什么:在少样本任务中,将有标签的支持样本和无标签的查询样本共同构建在一个图结构中进行分析。
- 之前局限:传统归纳式少样本方法(如ProtoNet)仅利用支持集估计原型,查询集数据被浪费。
- 如何起作用:查询样本虽然无标签,但包含关于生成器分布的结构信息。通过图连接,这些信息可以通过消息传递传播到支持节点,帮助优化原型。
- 收益:缓解了因支持样本少而导致的原型估计偏差(如图1所示),使原型更接近真实类分布。
- 图适应模块:
- 是什么:一个包含两层GCN和残差连接的模块,用于处理联合图,精炼节点嵌入。
- 之前局限:通用GCN可能不适应少样本场景下原型校准的需求。
- 如何起作用:在融合结构信息的同时,通过对支持节点施加显式监督(focal loss),确保精炼后的特征保持类别判别性。残差连接稳定训练并保留原始信息。
- 收益:生成了更具区分性的嵌入,增强了不同生成器间细微伪造痕迹的可分离性。
- 元测试时的自适应对比学习:
- 是什么:在元测试阶段,对遇到的少量新生成器支持样本,除了分类损失外,额外引入对比损失进行自适应微调。
- 之前局限:标准元测试直接应用元学习模型,对新类别的适应能力有限。
- 如何起作用:对比损失拉近同类样本、推远不同类样本,增强了特征的类内紧凑性和类间可分性。
- 收益:提升了模型对完全未见过的生成器的泛化能力。
🔬 细节详述
- 训练数据:
- 数据集:元训练使用ASVspoof2019 LA的划分(排除A16类型,剩余12类),元测试使用MLAAD的英文子集(训练15类,测试21类)。此外,MLAAD中使用了M-AILABS数据集的真实音频。
- 预处理:ASV2019LA音频未做额外预处理。MLAAD和M-AILABS音频被截断为5秒,并重采样至44.1kHz。
- 数据增强:论文中未提及使用数据增强技术。
- 损失函数:
- 支持分类损失 (Lsup):Focal Loss(公式4),用于支持节点显式分类。聚焦参数γ未在论文中明确给出数值。
- 原型损失 (Lproto):基于间隔的交叉熵损失(公式5),用于拉近查询节点与其真实类原型的距离,推远与其他类原型的距离。间隔m未在论文中明确给出数值。
- 总训练损失:Ltrain = λ1 Lsup + λ2 Lproto。权重λ1, λ2未在论文中明确给出数值。
- 对比损失 (Lcontrast):在元测试阶段使用(公式7),监督对比学习。间隔m(可能与Lproto中不同)未在论文中明确给出数值。
- 训练策略:
- 优化器:Adam。
- 训练步数:每个episode更新50步(元训练),元测试时在支持集上适应250步。
- 学习率:元训练:图卷积层0.001,线性分类器0.002。元测试适应:图卷积层0.0003,线性分类器0.001。
- Episode设置:采样2500个训练episode,6000个测试episode。每个任务的查询集每类提供15个样本。
- 任务设置:5-way N-shot (N=5,10,20)。
- 关键超参数:
- 图构建:top-k = 10。
- 嵌入维度d:由CLAP编码器决定(论文中未明确说明具体维度)。
- 图卷积层数:2层。
- 训练硬件:论文中未提供GPU型号、数量及训练时长。
- 推理细节:在元测试阶段,对每个任务,使用支持集(5,10,或20个样本/类)进行适应(250步),然后对查询集进行分类。分类依据是查询嵌入到各类原型的欧氏距离。
- 正则化技巧:图适应模块中的残差连接有助于稳定训练并防止信息丢失。
📊 实验结果
主要Benchmark结果: 在ASVspoof2019 LA和MLAAD数据集上的5-way设置结果如下表:
表1:在ASVspoof2019 LA和MLAAD上的准确率(%)
| 方法 | ASVspoof2019 LA (5-shot) | ASVspoof2019 LA (10-shot) | ASVspoof2019 LA (20-shot) | MLAAD (5-shot) | MLAAD (10-shot) | MLAAD (20-shot) |
|---|---|---|---|---|---|---|
| MatchingNet | 73.86 | 75.67 | 78.78 | 85.67 | 92.31 | 88.36 |
| RelationNet | 65.27 | 68.68 | 70.98 | 84.78 | 86.64 | 87.39 |
| ProtoNet | 75.17 | 79.52 | 80.93 | 89.96 | 91.44 | 92.26 |
| Treff-Adapter | 72.44 | 81.74 | 88.12 | 78.39 | 88.28 | 93.33 |
| PALM | 79.59 | 83.74 | 86.97 | 83.81 | 87.86 | 90.38 |
| SRML | 76.75 | 80.59 | 82.62 | 84.37 | 86.11 | 87.90 |
| DGPN | 83.80 | 85.40 | 85.40 | – | – | – |
| GPA (Ours) | 86.97 | 91.52 | 93.68 | 94.92 | 97.08 | 96.92 |
结论:GPA在所有设置下均取得最高准确率。在ASV2019LA上,相比最强基线DGPN,提升幅度为3.17% (5-shot) 至 8.28% (20-shot)。在MLAAD上,优势同样显著。
跨数据集评估(对应图3):
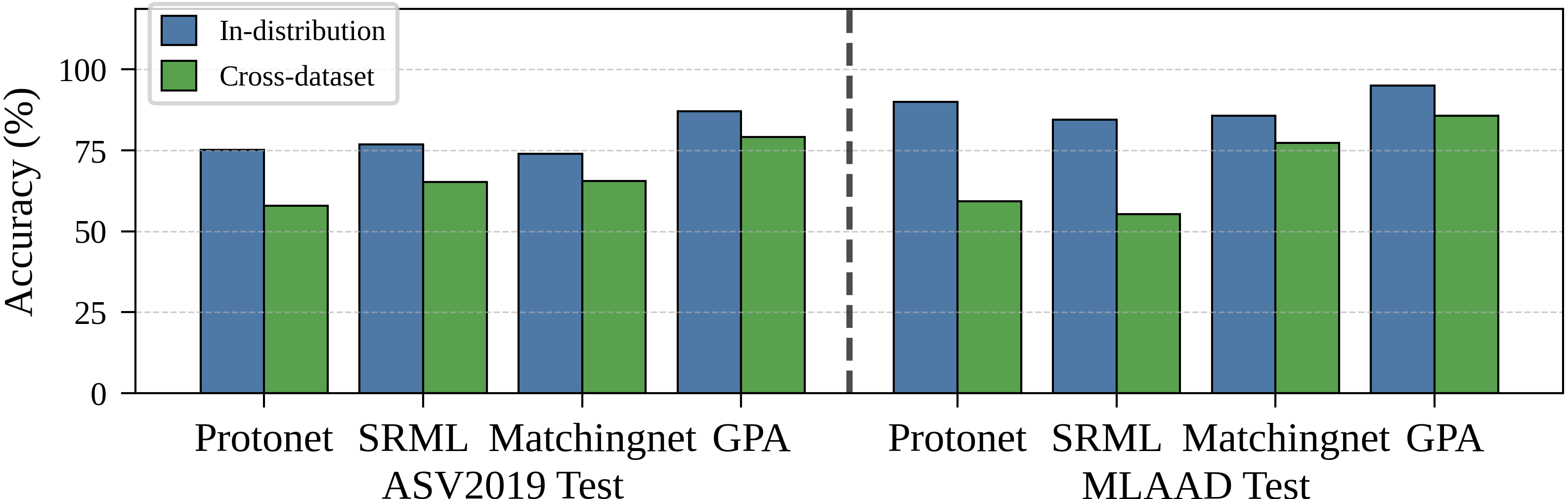 左图:模型在MLAAD训练集上训练,在ASV2019LA测试集上评估。GPA达到79.11%,优于所有基线。
右图:模型在ASV2019LA训练集上训练,在MLAAD测试集上评估。GPA达到85.70%,同样领先。
结论:尽管因分布差异导致绝对精度下降,但GPA通过利用查询样本结构信息校准原型,表现出更强的跨域泛化能力。
左图:模型在MLAAD训练集上训练,在ASV2019LA测试集上评估。GPA达到79.11%,优于所有基线。
右图:模型在ASV2019LA训练集上训练,在MLAAD测试集上评估。GPA达到85.70%,同样领先。
结论:尽管因分布差异导致绝对精度下降,但GPA通过利用查询样本结构信息校准原型,表现出更强的跨域泛化能力。
消融实验(表3,ASV2019LA):
| 设置 | 5-way 5-shot | 5-way 10-shot | 5-way 20-shot |
|---|---|---|---|
| A.1 (原始CLAP嵌入+原型分类) | 72.54 | 77.36 | 80.50 |
| A.2 (移除元训练) | 74.38 | 78.27 | 80.06 |
| A.3 (移除元测试时适应) | 80.14 | 83.85 | 84.86 |
| A.4 (用RawNet3替换CLAP) | 81.84 | 84.71 | 85.50 |
| A.5 (全连接图) | 87.02 | 91.69 | 93.86 |
| GPA (Ours, Top-k图) | 86.97 | 91.52 | 93.68 |
结论:
- 直接使用原始CLAP嵌入(A.1)性能最差。
- 移除元训练(A.2)或元测试适应(A.3)均导致性能显著下降,证明了它们的必要性。
- 用RawNet3替换CLAP(A.4)降低精度,说明CLAP嵌入的优势。
- 全连接图(A.5)性能略高于稀疏图,但其边数(10000-30625)是稀疏图(1148-4523)的数倍至数十倍,计算成本过高。本文提出的top-k稀疏图在性能和效率间取得了更好平衡。
细分类别性能(表2,ASV2019LA 5-way 5-shot): SRML在个别类型(如A00, A19)上达到极高准确率,但表现不稳定(如A07仅58.75%)。GPA在13个类型中的11个上达到86%以上,整体平均准确率86.97%,显示出更好的平衡性和鲁棒性。
⚖️ 评分理由
- 学术质量:6.0/7。论文技术方案完整、创新点清晰、实验对比全面且包含充分的消融分析,结果有显著提升。扣分点在于核心的“图传播优化原型”思想在机器学习领域(如转导学习、标签传播)并非全新概念,应用于音频少样本领域属于有效的组合与适配,但非基础性突破。
- 选题价值:1.5/2。音频深度伪造生成器识别��数字取证中的重要且前沿的垂直任务。论文针对数据稀缺这一核心挑战提出解决方案,具有明确的应用价值。因任务场景相对特定(集中于生成器分类),故给1.5分。
- 开源与复现加成:0.0/1。论文未提供代码、模型权重、数据集链接或完整的训练日志/检查点。虽然给出了主要超参数,但缺乏复现所需的关键材料,因此复现加成为0。