📄 FDCNet: Frequency Domain Channel Attention and Convolution for Lipreading
#视觉语音识别 #频域处理 #注意力机制 #数据增强
🔥 8.5/10 | 前25% | #视觉语音识别 | #频域处理 | #注意力机制 #数据增强
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Qianxi Yan(浙江大学)
- 通讯作者:Qifei Zhang(浙江大学)
- 作者列表:
- Qianxi Yan(浙江大学)
- Qifei Zhang*(浙江大学,通讯作者)
- Lei Zhang(中国科学院大学)
- Linkun Yu(日本早稻田大学生产系统研究生院)
- Lei Sheng(宁波市知识产权保护中心)
💡 毒舌点评
论文的亮点在于视角新颖,首次系统性地将频域协同处理(频域增强与频谱引导的注意力)引入唇读前端,为处理唇部动作的混合频率信号提供了合理的理论框架。短板是创新点SGCA和FADC的具体交互机制在图中未清晰展示,且92.2%到92.5%的提升虽达成SOTA,但幅度有限,难以断言是质变而非量变。
🔗 开源详情
- 代码:论文中未提及任何代码仓库链接或开源计划。
- 模型权重:论文中未提及公开的模型权重。
- 数据集:使用的是公开的LRW数据集,但论文未说明其获取方式(标准公开数据集)。
- Demo:未提及。
- 复现材料:提供了详细的训练配置(数据增强、优化器、学习率、调度策略等),但未提供最终的模型检查点、训练日志或详细的配置文件。论文中未提及开源计划。
- 论文中引用的开源项目:论文引用了多个已发表的方法(如ResNet, TSM, TCN, DC-TCN等)作为基线,但未明确说明其实现或代码来源。
📌 核心摘要
问题:传统唇读前端方法主要在空间域提取特征,难以有效处理唇部动作这种混合了低频宏观轮廓和高频细节的复杂信号,导致关键信息提取不足。
方法:提出一个频域协同网络(FDCNet)。其核心是两个模块:(1)频域自适应卷积(FADC),在频域通过动态加权的多尺度卷积核对不同频率成分进行差异化增强;(2)频谱引导的通道注意力(SGCA),利用完整的傅里叶幅度谱作为全局描述符,来筛选具有判别力的特征通道。
创新:首次在唇读前端中构建了“频域增强+频谱引导通道滤波”的统一处理管道。SGCA克服了传统全局平均池化(GAP)丢失高频信息的局限,FADC实现了内容自适应的频率调制。
实验:在LRW基准数据集上,FDCNet达到了92.5% 的准确率,超越了之前最优方法TCSAM-ResNet-18+DC-TCN(92.2%)。消融实验证实了SGCA(+0.32%)和FADC(+0.11%)各自的有效性。与多种注意力机制的对比表明SGCA的优越性。
表1:与SOTA方法对比
网络架构 准确率 (%) 3D-CNN [10] 61.1 ResNet-18 [1] 83.0 ResNet-34+BiGRU [16] 83.4 ResNet-50+TCN [2] 84.8 ResNet-18+MS-TCN [3] 85.3 ResNet-18+TSM+BiGRU [19] 86.2 EfficientNet+TCN+Transformer [17] 89.5 ResNet-18+DC-TCN [4] 92.1 TCSAM-ResNet-18+DC-TCN [18] 92.2 FDCNet (Ours) 92.5 表2:消融实验结果
方法配置 准确率 (%) 基线 (ResNet-18 + DenseTCN) 92.1 基线 + SGCA 92.42 基线 + FADC 92.21 FDCNet 92.5 表3:注意力机制对比
方法 全局描述符 准确率 (%) 基线 - 92.1 ECA [20] GAP 92.19 TA [18] GAP 92.25 SE [8] GAP 92.28 FCANet [9] DCT 92.3 SGCA (Ours) FFT 92.42
意义:为唇读乃至更广泛的视觉语音识别任务的前端特征提取提供了新的技术方向和有效工具,证明了频域分析在该领域的潜力。
局限:模型复杂度和计算开销可能增加(论文未详细讨论)。SGCA与FADC如何最优地协同工作(如级联顺序、是否并行)尚待更深入探索。性能提升虽创新但幅度有限。
🏗️ 模型架构
FDCNet采用经典的“前端特征提取 + 后端时序建模”两阶段架构。
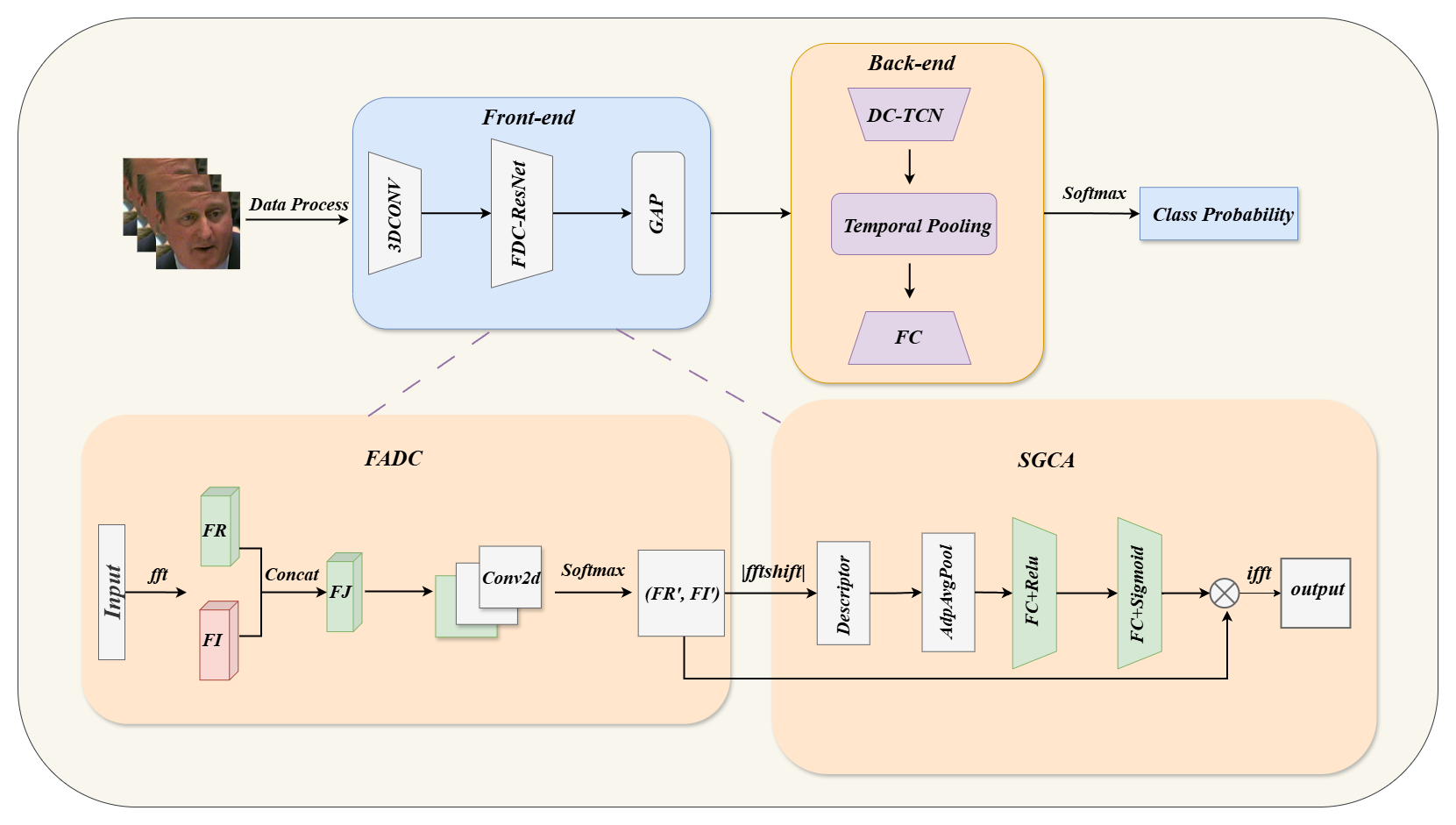 图1: FDCNet架构示意图。前端(左)负责时空特征提取,核心是嵌入在ResNet-18残差块中的FADC和SGCA模块;后端(右)使用DenseTCN进行时序建模,最终输出词类别概率。
图1: FDCNet架构示意图。前端(左)负责时空特征提取,核心是嵌入在ResNet-18残差块中的FADC和SGCA模块;后端(右)使用DenseTCN进行时序建模,最终输出词类别概率。
前端特征提取:
- 输入:对齐并裁剪后的96×96灰度唇部区域视频序列。
- 初始处理:通过一个5×5×7的3D卷积提取初步的时空特征。
- 骨干网络与模块嵌入:以ResNet-18为骨干。关键创新在于,从Stage 2到Stage 5的每个残差块中,都依次嵌入了FADC模块和SGCA模块。这两个模块协同工作,执行“频域增强与通道滤波”。
- 数据流:在每个残差块内,输入特征图首先进入FADC。FADC将特征转换到频域,通过动态加权的多尺度卷积核(1×1和两个3×3)对频率成分进行增强,输出增强后的频域特征。然后,这些频域特征被送入SGCA。SGCA将特征重新构造为复频谱,计算其幅度谱作为全局描述符,生成通道注意力权重,最终输出加权后的特征(并返回空间域)。
- 后端时序建模:
- 前端输出的特征向量与词边界信息结合,输入DenseTCN网络。DenseTCN利用时间注意力机制捕捉序列依赖性,输出T×C1维度的时序特征。
- 通过时序池化将特征聚合为1×C2维度的向量。
- 最后通过全连接层和Softmax函数,生成对500个词类别的概率分布。
关键设计选择及其动机:在前端ResNet的多个阶段嵌入频域模块,旨在让模型在不同抽象层次上都能对混合频率信号进行自适应处理,从而更充分地提取从低频轮廓到高频细节的多层次判别信息。
💡 核心创新点
频谱引导的通道注意力(SGCA)机制:
- 是什么:一种使用完整的傅里叶幅度谱(而非GAP)作为全局描述符的通道注意力模块。
- 之前局限:传统SE、ECA等注意力使用GAP,等价于提取直流分量,会平均掉高频纹理信息,而这对于区分/p/, /b/, /m/等视觉相似音素至关重要。FCANet使用DCT,但其预定义的“Top-16”频率选择策略不灵活,且与后续FFT处理存在域不匹配。
- 如何起作用:SGCA接收FADC输出的频域特征,将其恢复为复频谱,计算中心化后的幅度谱。该谱图包含了从低频到高频的所有信息,作为全局描述符来生成通道注意力权重。
- 收益:相比基于GAP的注意力,在LRW上准确率提升显著(例如比SE高0.14%)。实验证明SGCA是性能提升的主要贡献者且参数高效。
频域自适应卷积(FADC)模块:
- 是什么:一种将特征增强操作转移到频域,并通过动态加权的多尺度卷积核进行内容自适应处理的模块。
- 之前局限:空间域卷积核难以同时优化提取低频宏观轮廓和高频精细特征。
- 如何起作用:首先通过2D-FFT将特征图解耦为实部(主导低频)和虚部(主导高频)。然后维护三个专家卷积核(1×1和两个3×3),通过一个轻量级注意力机制(MLP+GAP)根据输入动态生成权重,对频域特征进行加权组合。
- 收益:实现了对输入内容敏感的频率调制,在消融实验中带来0.11%的准确率提升。
频域协同处理管道:
- 是什么:在前端网络的多个阶段,级联使用FADC(频域增强)和SGCA(频域引导的通道滤波),形成一个统一的处理流程。
- 之前局限:单一模块或空间域方法难以协同处理频率和通道信息。
- 如何起作用:FADC先对不同频率成分进行差异化增强,SGCA再利用增强后的完整频谱信息进行通道选择,两者互补。
- 收益:共同使FDCNet在LRW数据集上达到92.5%的SOTA准确率。
🔬 细节详述
训练数据:
- 数据集:Lip Reading in the Wild (LRW) [10]。
- 规模:500个词类别。训练集488,766样本,验证集25,000样本,测试集25,000样本。
- 预处理:检测面部关键点,对齐唇部区域,从图像中裁剪出96×96像素的嘴部区域并转换为灰度图。
- 数据增强:训练时随机裁剪至88×88像素并水平翻转;使用标签平滑[11]、Mixup[12]、TimeMask[13]。
损失函数:论文中未明确说明损失函数的名称或公式。根据任务(500类分类)和最终输出层(Softmax),可以推断使用的是交叉熵损失(Cross-Entropy Loss),但论文未提及。
训练策略:
- 学习率:初始学习率0.0003。
- 优化器:AdamW,权重衰减0.0004。
- 训练轮数:79个epoch。
- 调度策略:余弦学习率调度器(Cosine Scheduler)[15]。
- Batch Size:24(使用2张GPU,推测单卡12)。
- 其他:端到端训练;引入词边界信息作为辅助信息[14]。
关键超参数:
- 模型架构:前端为嵌入了FADC/SGCA的ResNet-18,后端为DenseTCN。
- FADC中专家卷积核数量:K=3。
- 词类别数:500。
训练硬件:
- GPU:2块NVIDIA RTX 4080。
- 训练时长:论文中未说明。
推理细节:论文中未说明解码策略、温度、beam size等推理细节。
正则化或稳定训练技巧:使用了标签平滑、Mixup、TimeMask等数据增强方法作为正则化手段。
📊 实验结果
论文在Lip Reading in the Wild (LRW)数据集上进行了主要实验,评估指标为词识别准确率。
主要性能对比: 论文提供了与多种先进方法的对比(见表1)。FDCNet以92.5%的准确率超越了之前所有方法,包括最强基线TCSAM-ResNet-18+DC-TCN(92.2%),达到了新的SOTA。
消融实验: 论文进行了系统的消融研究(见表2),验证了每个核心组件的贡献。
- 基线(ResNet-18 + DenseTCN)准确率为92.1%。
- 单独加入SGCA模块,准确率提升至92.42%(+0.32%),表明频谱引导的通道注意力效果显著。
- 单独加入FADC模块,准确率提升至92.21%(+0.11%),表明频域自适应卷积有效。
- 同时使用两个模块(FDCNet),达到最佳性能92.5%。结果表明两个模块的贡献具有互补性。
注意力机制对比: 论文将SGCA与多种主流通道注意力机制进行了对比(见表3)。
- 使用GAP作为描述符的SE、TA、ECA准确率在92.19%-92.28%之间。
- 使用DCT的FCANet准确率为92.3%。
- SGCA使用完整的FFT幅度谱,取得了92.42%的最高准确率,证实了其在保留高频信息方面的优势。
⚖️ 评分理由
- 学术质量:6.5/7:论文问题定义清晰,技术方案(频域协同处理)具有新颖性和合理性。两个核心模块(SGCA, FADC)设计有创新,且相互配合。实验设计规范,包括了与SOTA的对比、消融实验和注意力机制对比,结果可信,有力支撑了结论。主要扣分点在于:1)创新幅度相对有限(绝对性能提升0.3%);2)架构图(图1)未能清晰展示FADC和SGCA在残差块内的具体连接与数据流。
- 选题价值:1.5/2:视觉语音识别是语音技术的重要组成部分,具有明确的应用前景。频域分析为该任务的前端特征提取提供了新的视角,研究方向有价值。但相比通用的语音识别或大模型,任务领域相对垂直。
- 开源与复现加成:0.5/1:论文提供了详细的实验设置(数据、预处理、训练策略、数据增强),为复现打下了良好基础。然而,未提供代码、模型权重或详细的复现指南,这降低了结果的可复现性,也限制了社区的跟进与验证。