📄 FD-ARL: Feature Disentanglement with Adversarial-Reconstruction Learning for Cross-Subject Auditory Attention Decoding
#听觉注意力解码 #领域适应 #Transformer #脑电信号
✅ 7.5/10 | 前10% | #听觉注意力解码 | #领域适应 | #Transformer #脑电信号
学术质量 8.0/7 | 选题价值 8.5/2 | 复现加成 8.0 | 置信度 高
👥 作者与机构
- 第一作者:Yuan Liao(香港中文大学(深圳)人工智能学院,数据科学学院,深圳研究院)
- 通讯作者:Siqi Cai(哈尔滨工业大学(深圳)智能科学与工程学院)
- 作者列表:Yuan Liao(香港中文大学(深圳)人工智能学院,数据科学学院,深圳研究院)、Haoqi Hu(香港中文大学(深圳)人工智能学院,数据科学学院,深圳研究院)、Siqi Cai(哈尔滨工业大学(深圳)智能科学与工程学院)、Haizhou Li(香港中文大学(深圳)人工智能学院,数据科学学院,深圳研究院)
💡 毒舌点评
亮点:论文精准地抓住了跨被试脑电解码的核心痛点——“个体差异”与“任务相关性”的纠缠,并提出了一个逻辑自洽的“解耦”框架(特征拆分+对抗抹除身份+重建保留信息),实验上也取得了扎实的性能提升。短板:重建损失的具体作用机制(是防止信息丢失还是隐式正则化)讨论不足,且仅验证了跨被试泛化,未涉及跨范式(如噪声环境、听觉刺激参数变化)的泛化,限制了其结论的普遍性。
🔗 开源详情
- 代码:论文中提供了一个GitHub仓库链接
https://github.com/LiaoEuan/FD-ARL,但注明“将公开访问”,表明代码在论文发表时尚未正式开源。 - 模型权重:未提及。
- 数据集:评估使用的是公开数据集(KUL, DTU),论文中未提供获取方式的具体链接,但注明了来源参考文献。
- Demo:未提及。
- 复现材料:论文中提供了非常详细的模型架构、超参数设置(学习率、批量大小、优化器、网络维度等)和训练策略,这些信息对复现至关重要。
- 论文中引用的开源项目:论文中未明确列出依赖的开源工具或模型,主要基于自行实现的架构。
📌 核心摘要
- 问题:基于脑电图(EEG)的听觉注意力解码(AAD)模型在跨被试场景下泛化性能差,主要原因是个体间脑电信号差异大,且现有方法难以提取与任务相关且与个体无关的鲁棒特征。
- 方法核心:提出FD-ARL框架。首先用并行时空Transformer编码器提取EEG特征。然后,将特征解耦为任务相关码(ztask)和特定于被试的码(zsubj)。最后,通过对抗训练(利用梯度反转层)迫使ztask对被试身份不变,同时通过重建损失确保解耦过程保留关键信息。
- 创新点:这是首次将双分支Transformer与对抗-重建解耦方案相结合用于EEG-AAD。与传统领域对抗网络(DANN)不同,它不是将整个特征强制对齐,而是显式地分离出应保持不变的任务特征和应被忽略的个体特征。
- 主要实验结果:在KUL和DTU两个公开数据集上,采用严格的留一被试交叉验证(LOSO-CV)。FD-ARL在所有条件下均达到了最佳性能。例如,在KUL数据集2秒窗口下,准确率达74.6%,比此前最优的DARNet(71.9%)高出2.7个百分点。消融实验证明了每个模块(对抗、重建、时空分支)的贡献。
- 实际意义:该工作为解决BCI和神经辅助设备中的跨用户泛化问题提供了有效方案,推动了听觉注意力解码技术向实用化迈进。
- 主要局限性:研究仅聚焦于跨被试泛化,未探讨模型在更复杂声学环境(如高噪声、不同空间布局)下的鲁棒性;重建损失的具体作用机制可以进一步剖析;实验仅限于特定数据集的二分类(左/右)任务,结论的普适性有待更广泛验证。
🏗️ 模型架构
FD-ARL的整体架构(图1)分为两个阶段:并行时空特征编码和特征解耦与学习。
- 并行时空编码器:
- 输入:原始EEG信号
X ∈ R^{B×C×T},其中B是批量大小,C是通道数(64),T是时间点数。 - 时空特征嵌入:
- 时间分支:使用多尺度卷积层将输入转换为P个时间块,得到时间嵌入
E_T ∈ R^{B×P×D}。 - 空间分支:使用独立的轻量级卷积网络为每个通道生成一个独特的令牌嵌入,得到空间嵌入
E_S ∈ R^{B×C×D}。
- 时间分支:使用多尺度卷积层将输入转换为P个时间块,得到时间嵌入
- 上下文编码与融合:为嵌入添加可学习的位置编码。然后,分别通过两个独立的Transformer编码器处理,得到上下文表示
F_T和F_S。通过全局平均池化将时间表示汇总为向量f_t,通过注意力加权求和将空间表示汇总为向量f_s。将两者拼接并通过非线性投影,得到最终的融合特征表示f'_{fused} ∈ R^{B×2D}。
- 特征解耦模块:
- 解耦:将融合特征向量直接拆分为两半,得到任务相关码
z_{task} ∈ R^{B×D}和被试特异码z_{subject} ∈ R^{B×D}。 - 联合优化框架:通过三个损失函数约束这两个码:
- 任务分类损失 (L_task):使用任务分类器
C_y基于z_{task}进行分类,确保其判别性。 - 对抗不变性损失 (L_domain):使用领域分类器
C_d基于经过梯度反转层(GRL) 的z_{task}预测被试标签。GRL反转梯度,迫使z_{task}变得对被试身份不可区分。 - 重建保真度损失 (L_recon):使用解码器从完整的
f'_{fused}重建原始EEG信号X,使用MSE损失,确保解耦过程不丢失关键信息。
- 任务分类损失 (L_task):使用任务分类器
最终损失为加权和:L_total = L_task + λL_domain + βL_recon,其中λ动态增加,β固定为0.5。
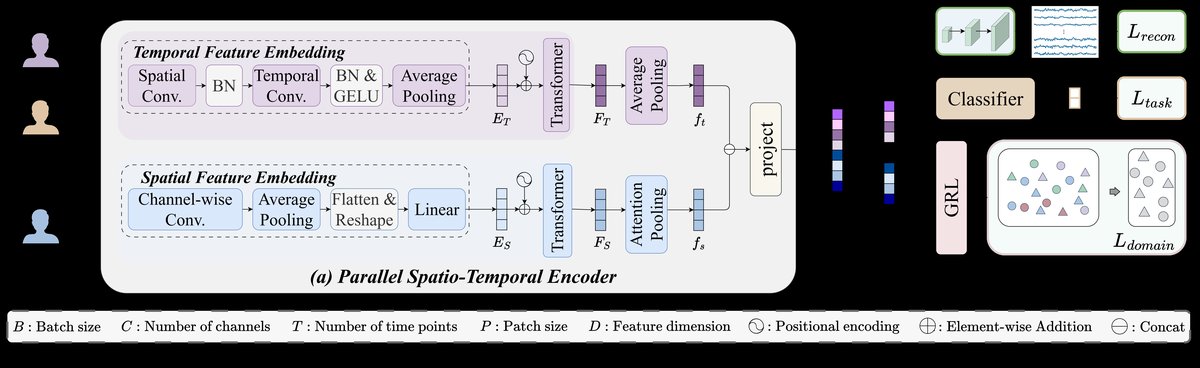 图1:FD-ARL框架整体架构图。(a) 并行时空特征提取器;(b) 特征解耦模块及联合损失优化。
图1:FD-ARL框架整体架构图。(a) 并行时空特征提取器;(b) 特征解耦模块及联合损失优化。
💡 核心创新点
- 特征解耦思想应用于EEG-AAD:首次明确将脑电信号特征显式地分解为“任务相关”和“被试特异”两个独立成分,这比传统DANN将整个特征向量强制对齐的方法更精细,避免了可能的任务信息损失。
- 对抗-重建联合学习范式:创新性地将对抗学习(用于去除被试身份)与重建学习(用于保留信息)结合,共同指导解耦过程。重建损失作为正则化,防止对抗训练过度扭曲特征导致信息丢失。
- 并行时空Transformer编码器:采用双分支结构分别处理时间动态和空间拓扑信息,并通过Transformer进行上下文建模,比单一结构或传统CNN/LSTM能更全面地捕捉EEG的复杂时空特性。
🔬 细节详述
- 训练数据:
- 数据集:KUL数据集(16被试,64通道EEG,双耳听双语音流)和DTU数据集(18被试,64通道EEG,带背景噪声,双语音流±60°)。
- 预处理:将原始EEG分割成1秒或2秒的短时窗。未说明是否进行了滤波、伪迹去除等其他预处理。
- 数据增强:未说明。
- 损失函数:
- L_task:交叉熵损失。
- L_domain:交叉熵损失,作用于经过GRL的特征。
- L_recon:均方误差(MSE)损失,重建原始EEG信号。
- 权重:λ从0动态增加到1;β=0.5。
- 训练策略:
- 优化器:AdamW,初始学习率 1e-4,权重衰减 1e-3。
- 训练轮数:100 epochs。
- 批量大小:64。
- 学习率调度:ReduceLROnPlateau。
- 关键超参数:
- 通道数 C=64,嵌入维度 D=128,时间块数 P=16。
- 并行Transformer编码器各包含2层,每层8个注意力头。
- 训练硬件:未说明。
- 推理细节:未说明具体解码策略(如滑动窗口、阈值),仅提到用短时窗进行预测。
- 正则化技巧:除了显式的L_domain和L_recon,未提及其他正则化方法。
📊 实验结果
论文在KUL和DTU数据集上,采用留一被试交叉验证,评估了1秒和2秒时间窗口下的解码准确率。
表1:跨被试听觉注意力解码性能对比
| 数据集 | 模型 | 1秒窗口准确率 (%) | 2秒窗口准确率 (%) |
|---|---|---|---|
| KUL | CNN | 56.8 ± 5.58 | 59.5 ± 8.21 |
| SSF-CNN | 59.3 ± 6.69 | 60.8 ± 8.40 | |
| MBSS-FCC | 62.7 ± 8.08 | 64.7 ± 8.62 | |
| DGSD | 63.6 ± 8.00 | – | |
| DBPNet | 61.1 ± 8.26 | 62.3 ± 7.37 | |
| DARNet | 69.9 ± 11.82 | 71.9 ± 13.01 | |
| FD-ARL (ours) | 74.5 ± 14.73 | 74.6 ± 14.04 | |
| DTU | CNN | 51.8 ± 3.03 | 52.9 ± 3.42 |
| SSF-CNN | 52.3 ± 3.50 | 53.4 ± 4.16 | |
| MBSS-FCC | 52.5 ± 4.35 | 53.9 ± 5.80 | |
| DGSD | 55.2 ± 4.07 | – | |
| DBPNet | 55.5 ± 6.33 | 55.8 ± 6.11 | |
| DARNet | 55.6 ± 4.13 | 55.6 ± 4.04 | |
| FD-ARL (ours) | 57.7 ± 4.68 | 58.1 ± 4.42 |
关键结论:FD-ARL在所有设置下均取得最优性能。在KUL数据集2秒窗口下,比次优的DARNet高2.7%;在DTU数据集2秒窗口下,高2.5%。
消融实验(DTU数据集,2秒窗口):
| 方法 | 准确率 (%) | 变化 (∆%) |
|---|---|---|
| FD-ARL (ours) | 58.1 ± 4.42 | – |
| w/o Adv (无对抗) | 56.1 ± 4.59 | -2.0 |
| w/o Rec (无重建) | 57.2 ± 4.96 | -0.9 |
| w/o Adv-Rec (无对抗与重建) | 55.8 ± 4.43 | -2.3 |
| w/o Spat (无空间分支) | 56.8 ± 5.48 | -1.3 |
| w/o Temp (无时间分支) | 50.5 ± 8.21 | -7.6 |
关键结论:去除时间分支性能下降最大(-7.6%),表明时间建模最关键。对抗训练(-2.0%)比重建损失(-0.9%)贡献更大,但二者协同(-2.3%)能带来最大收益。
可视化分析(图2):
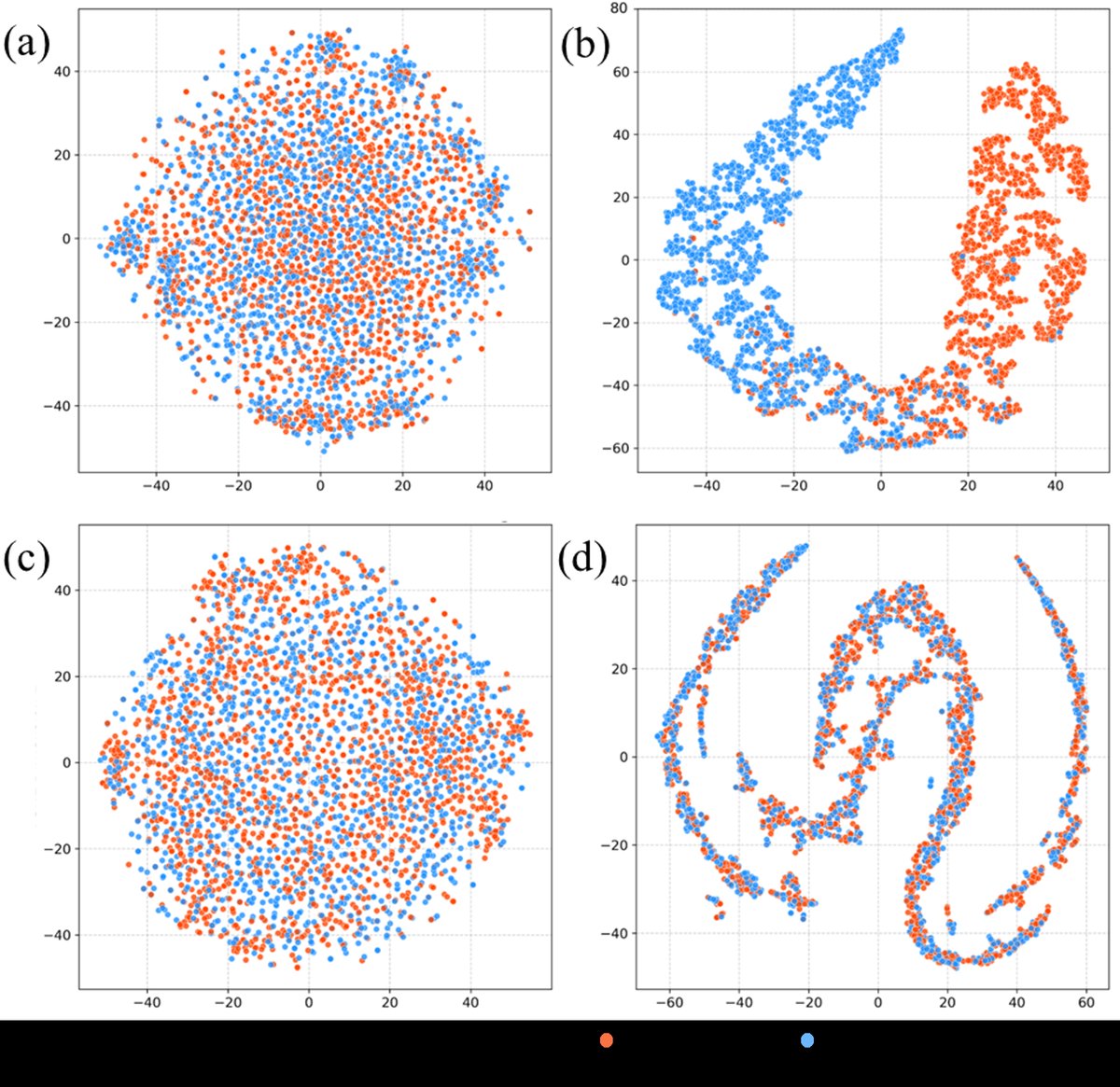 图2:t-SNE可视化对比。左列为原始EEG数据,右列为FD-ARL学习到的任务相关码z_task。可以看出,原始数据在不同注意力条件下高度重叠,而z_task形成了清晰可分的聚类,证明了模型有效过滤了被试特异性噪声,提取了核心注意模式。
图2:t-SNE可视化对比。左列为原始EEG数据,右列为FD-ARL学习到的任务相关码z_task。可以看出,原始数据在不同注意力条件下高度重叠,而z_task形成了清晰可分的聚类,证明了模型有效过滤了被试特异性噪声,提取了核心注意模式。
⚖️ 评分理由
- 学术质量:6.2/7。论文提出了逻辑严谨、有理论支撑的框架,技术实现正确(双分支Transformer、GRL、重建解码器)。实验设计科学(LOSO-CV),对比基线充分,消融研究完整,结果具有说服力。创新点明确且有效。
- 选题价值:1.8/2。跨被试脑电解码是BCI领域的核心挑战,直接影响助听器等设备的实用性。该研究直接面向这一瓶颈,具有重要的理论和应用价值。
- 开源与复现加成:-0.5/1。优势:论文提供了清晰的架构图、完整的损失函数公式、详细的超参数设置,并承诺公开代码(链接已提供)。劣势:代码尚未发布,缺乏预训练模型权重、训练硬件信息和一键复现的脚本,增加了完全复现的难度。