📄 FastAV: Efficient Token Pruning for Audio-Visual Large Language Model Inference
#音频问答 #大语言模型的压缩与加速 #音视频 #多模态模型
✅ 7.0/10 | 前25% | #音频问答 | #大语言模型的压缩与加速 | #音视频 #多模态模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Chaeyoung Jung(韩国科学技术院,Korea Advanced Institute of Science and Technology, South Korea)
- 通讯作者:未说明
- 作者列表:Chaeyoung Jung(韩国科学技术院)、Youngjoon Jang(韩国科学技术院)、Seungwoo Lee(韩国科学技术院)、Joon Son Chung(韩国科学技术院)
💡 毒舌点评
亮点:本文敏锐地发现了现有token剪枝研究在音视频大语言模型领域的空白,并首次提出了系统性的解决方案,其两阶段剪枝策略(全局剪枝+精细剪枝)在实验上取得了显著且一致的效率提升(>40% FLOPs降低),且不损害甚至能提升性能,这对于推动此类昂贵模型的实际部署具有明确的工程价��。 短板:技术路线本质上是对视觉token剪枝方法的“移植”和“拼接”(全局剪枝基于视觉工作常见的注意力回溯,精细剪枝基于LLM剪枝中常见的最后token分析),在剪枝机制本身上创新有限。此外,实验对比集中在自身设定的不同剪枝策略上,缺乏与更多元、更强的基线方法(如其他可能适用于多模态的剪枝或加速技术)的横向比较。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:论文中使用的AVQA、MUSIC-AVQA、AVHBench为公开数据集,但论文未说明具体获取或预处理方式。
- Demo:未提及。
- 复现材料:论文给出了关键超参数(剪枝层选择、P=20%、保留的token数量),描述了剪枝算法的公式和步骤,但未提供完整的配置文件、脚本或检查点。
- 论文中引用的开源项目:引用了VideoLLaMA2和video-SALMONN2作为基线模型,并链接了VideoLLaMA2的GitHub仓库(https://github.com/DAMO-NLP-SG/VideoLLaMA2/tree/audio_visual),但这是基线模型的仓库,而非FastAV的实现。
📌 核心摘要
- 要解决的问题:音视频大语言模型在处理包含音频、视频、文本的多模态输入时,token数量巨大,导致推理时内存消耗和计算成本剧增,限制了其实际应用。
- 方法核心:提出FastAV,一个两阶段的推理时token剪枝框架。第一阶段在中间层进行“全局剪枝”,利用注意力回溯机制分析token重要性,移除位置靠后、影响力较弱的大部分token(如2/3);第二阶段在后续层进行“精细剪枝”,基于最后一个查询token的注意力权重,逐层迭代移除最不重要的20% token。
- 与已有方法相比新在哪里:这是首个专门为音视频大语言模型设计的token剪枝框架。不同于直接应用在纯文本LLM或视觉-语言模型上的方法,FastAV综合考虑了音视频模态的特点,并通过注意力回溯揭示了此类模型在中间层后注意力集中于早期token的“锚定”模式,从而设计了针对性的剪枝策略。
- 主要实验结果:在VideoLLaMA2和video-SALMONN2两个模型上,FastAV将理论FLOPs降低了40%以上(见表1),同时推理速度提升约30%,内存占用降低。在AVQA, MUSIC-AVQA, AVHBench三个基准测试上,性能保持持平甚至有所提升(例如在AVHBench的AV匹配任务上,VideoLLaMA2的准确率从57.8%提升至69.0%)。消融实验表明,基于注意力回溯的全局剪枝策略优于随机剪枝和基于原始注意力权重的策略(表2),精细剪枝的剪枝比例P=20%为最优(表4)。
- 实际意义:使音视频大语言模型能够更高效地处理长视频、复杂音频等多模态长上下文输入,降低了部署的硬件门槛和延迟,有助于推动其在实时交互、边缘设备等场景的应用。
- 主要局限性:剪枝策略的有效性依赖于“注意力在中间层后集中于早期token”这一观察,该模式是否在所有音视频大语言模型和任务中普遍存在尚不明确。此外,论文未探讨该剪枝框架对模型训练或微调阶段的影响,也未提供理论保证证明性能不会在更极端的压缩下下降。
🏗️ 模型架构
FastAV本身并非一个独立的音视频大语言模型,而是一个应用于现有模型(如VideoLLaMA2、video-SALMONN2)推理阶段的加速框架。其整体流程如图3所示。
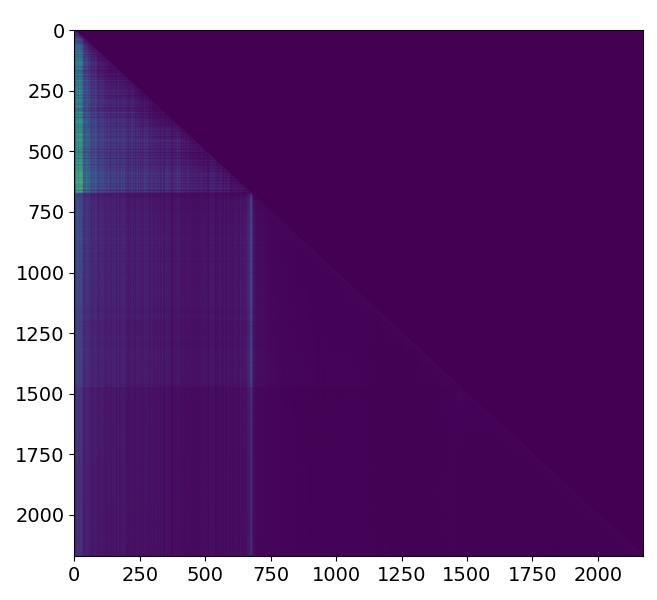 图3:FastAV框架概览。输入序列包含视频(X_vis)、音频(X_aud)和文本(X_lang)token。整体推理过程(a)在中间层(L/2)进行全局剪枝,在后续层进行精细剪枝。剪枝机制(b)展示了全局剪枝依据注意力回溯,精细剪枝依据最后查询token的注意力分析。
图3:FastAV框架概览。输入序列包含视频(X_vis)、音频(X_aud)和文本(X_lang)token。整体推理过程(a)在中间层(L/2)进行全局剪枝,在后续层进行精细剪枝。剪枝机制(b)展示了全局剪枝依据注意力回溯,精细剪枝依据最后查询token的注意力分析。
核心组件与流程:
- 输入:原始输入序列由视频编码器提取的M个视觉token、音频编码器提取的U个音频token和文本编码器生成的E个文本token拼接而成,总长度为K。
- 全局剪枝(Global Pruning):
- 时机:在模型中间层(例如28层模型的第14层)。
- 方法:计算从输入层到当前层的累积注意力回溯(Attention Rollout)。注意力回溯通过结合残差连接(公式2)和逐层矩阵乘法(公式3)得到,能更准确地反映信息传播路径。分析显示,在中间层,注意力权重高度集中在序列早期的token上(见图1,图2)。
- 操作:根据注意力回溯得分,移除序列中位置靠后(影响力较弱)的token。例如,在VideoLLaMA2中,保留前10个音频token,修剪其余;在video-SALMONN2中,保留前4帧对应的音视频token。此阶段移除约2/3的token。
- 精细剪枝(Fine Pruning):
- 时机:在全局剪枝后的每一层(第L/2 + 1层至最后一层)。
- 方法:利用当前层最后一个查询token(用于生成下一个token的token)的注意力权重。计算该查询token对所有剩余token的注意力得分(公式4),并取所有头的平均值作为重要性分数。
- 操作:在每一层,移除重要性分数最低的P%(默认为20%)的token。此过程逐层迭代,动态地、更精细地筛选token。
- 输出:经过两阶段剪枝后的token序列被送入后续层计算,最终用于自回归生成下一个token。
💡 核心创新点
- 首次系统分析音视频大语言模型中token的作用:通过注意力回溯可视化,揭示了此类模型在处理多模态输入时,其内部信息传播的关键模式——注意力在中间层后显著向序列早期token(“锚点”)集中(图1,图2)。这为理解模型行为和设计高效策略提供了实证依据。
- 提出面向音视频大语言模型的两阶段剪枝策略:结合“全局剪枝”和“精细剪枝”。前者利用宏观的、跨层累积的注意力回溯进行粗筛,移除大部分冗余token;后者利用微观的、当前层的最后token注意力进行精细筛选,在已压缩的序列上进一步优化计算。这种组合平衡了效率与效果。
- 实现与高效注意力机制的兼容性:FastAV的设计不依赖于存储和计算完整的注意力矩阵,仅需利用特定token(全局剪枝需分析累积注意力,精细剪枝仅需最后一个查询token的注意力),因此与FlashAttention等高效注意力优化技术完全兼容,确保了加速效果能够叠加。
🔬 细节详述
- 训练数据:论文中未说明FastAV框架本身的训练数据。所评估的基线模型(VideoLLaMA2, video-SALMONN2)的预训练数据未在本文详细给出。
- 损失函数:不适用。FastAV是推理时方法,不涉及训练。
- 训练策略:不适用。
- 关键超参数:
- 全局剪枝起始层:选择模型的中间层(如28层模型的第14层)。
- 精细剪枝比例P:默认设置为20%。
- 全局剪枝保留策略:根据具体模型架构和模态token排列顺序进行,如VideoLLaMA2保留前10个音频token,video-SALMONN2保留前4帧。
- 训练硬件:论文中未提及。
- 推理细节:
- 解码策略:自回归生成,论文未指定具体策略(如贪心、束搜索)。
- 剪枝操作:在模型前向传播的特定层动态执行,移除token后,剩余token参与后续层的计算。
- 正则化或稳定训练技巧:不适用。
📊 实验结果
主要结果对比(表1)
| 方法 | FLOPs↓ | Latency↓ | Memory↓ | MUSIC-AVQA↑ | AVQA↑ | AVHBench (AV hallucination↑/AV matching↑) |
|---|---|---|---|---|---|---|
| VideoLLaMA2 | 100 | 0.43s | 22G | 81.3 | 61.4 | 77.9 / 57.8 |
| w/ FastAV | 56 | 0.32s | 19G | 81.2 | 62.3 | 78.2 / 69.0 |
| video-SALMONN2 | 100 | 0.44s | 28G | NA | 57.6 | 64.5 / 50.8 |
| w/ FastAV | 58 | 0.29s | 21G | NA | 58.4 | 64.8 / 50.7 |
| 表1:FastAV在主要基准测试上的性能。理论FLOPs降低超过40%,推理延迟降低约30%,内存减少,同时精度保持或提升。 |
全局剪枝策略对比(表2,仅VideoLLaMA2 on AVHBench)
| 方法 | FLOPs | AV hallucination↑ | AV matching↑ | Avg |
|---|---|---|---|---|
| Vanilla | 100 | 77.9 | 57.8 | 70.7 |
| Random | 65 | 77.2 | 54.2 | 69.0 |
| Top attentive | - | 76.1 | 51.7 | 67.4 |
| Low attentive | - | 77.5 | 57.8 | 70.5 |
| Top informative | - | 72.3 | 50.9 | 64.7 |
| Low informative (Ours) | 65 | 78.7 | 67.7 | 74.5 |
| 表2:不同全局剪枝策略对比。基于注意力回溯的“低信息量”剪枝策略效果最佳。 |
精细剪枝策略对比(表3,仅VideoLLaMA2 on AVHBench)
| 方法 | FLOPs | AV hallucination↑ | AV matching↑ | Avg |
|---|---|---|---|---|
| Vanilla | 100 | 77.9 | 57.8 | 70.7 |
| Random | 56 | 76.1 | 54.9 | 68.5 |
| Top attentive | - | 74.5 | 52.8 | 66.8 |
| Low attentive (Ours) | 56 | 78.2 | 69.0 | 74.9 |
| 表3:不同精细剪枝策略对比。“低注意力”剪枝策略(移除注意力分数低的token)优于其他策略。 |
精细剪枝比例P消融实验(表4,仅VideoLLaMA2 on AVHBench)
| P (%) | FLOPs↓ | AV hallucination↑ | AV Matching↑ | Avg |
|---|---|---|---|---|
| 0 | 65 | 78.7 | 67.7 | 74.5 |
| 10 | 59 | 78.3 | 68.3 | 74.7 |
| 20 (Ours) | 56 | 78.2 | 69.0 | 74.9 |
| 30 | 54 | 78.3 | 68.5 | 74.8 |
| 表4:不同精细剪枝比例P的对比。P=20%在FLOPs和平均性能间取得最佳平衡。 |
层级选择分析(图4)
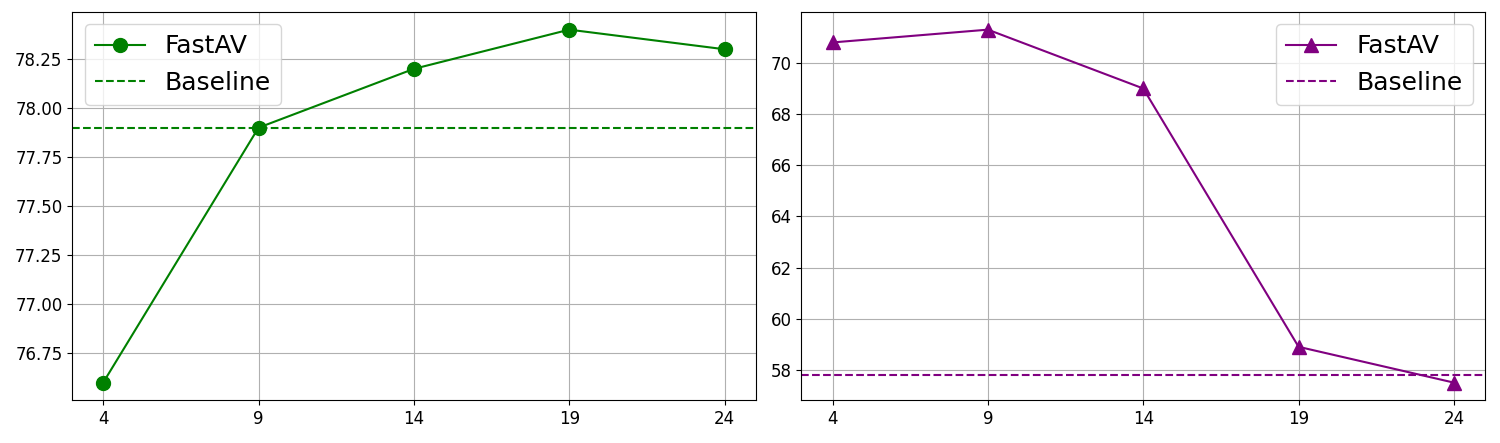 图4:VideoLLaMA2在AVHBench子任务上不同起始剪枝层的性能。在中间层(如第14层)开始剪枝,能在两项任务上取得最佳平衡。
图4:VideoLLaMA2在AVHBench子任务上不同起始剪枝层的性能。在中间层(如第14层)开始剪枝,能在两项任务上取得最佳平衡。
⚖️ 评分理由
- 学术质量:5.5/7:论文工作扎实,实验设计全面(主实验、多策略对比、消融实验),结果具有说服力。其贡献在于将token剪枝系统性地引入音视频大语言模型领域,并提供了有效的两阶段方案。然而,核心剪枝机制(注意力回溯、最后token分析)并非原创,创新更多体现在针对新问题的组合与适配上,且缺乏与更多基线方法的对比,因此分数未能进入优秀区间(7.5+)。
- 选题价值:1.5/2:选题直接命中多模态大模型部署的效率瓶颈,具有明确的实用价值和优化空间。音视频理解是当前AI的热点应用方向之一,因此研究价值被认可。但由于研究问题相对垂直(特定于AV-LLM的推理加速),其普适影响力略低于更基础的模型架构或训练方法研究。
- 开源与复现加成:0/1:论文未提供代码、模型或详细配置,无法直接复现,因此没有加成。