📄 Face-Voice Association with Inductive Bias for Maximum Class Separation
#说话人验证 #跨模态 #归纳偏置 #对比学习 #基准测试
✅ 7.0/10 | 前25% | #说话人验证 | #归纳偏置 | #跨模态 #对比学习
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文作者列表未按顺序标注第一作者,但根据惯例,Marta Moscati排在首位)
- 通讯作者:未说明(论文中未明确标注通讯作者)
- 作者列表:Marta Moscati¹, Oleksandr Kats¹, Mubashir Noman², Muhammad Zaigham Zaheer², Yufang Hou³, Markus Schedl¹’⁴, Shah Nawaz¹
- ¹ Johannes Kepler University Linz, Austria
- ² MBZUAI, UAE
- ³ IT:U Interdisciplinary Transformation University Austria
- ⁴ Linz Institute of Technology, Austria
💡 毒舌点评
亮点:论文巧妙地将一个原本用于单模态分类任务的“最大类分离归纳偏置”技术迁移并适配到了多模态的人脸-语音关联领域,且通过扎实的消融实验证明了它与正交约束损失结合后的“1+1>2”效果,思路新颖且有效。 短板:归纳偏置矩阵的构造(公式1)需要预先知道总说话人数量(Ns),这可能导致其在动态或开放世界的说话人识别场景中应用受限,论文未探讨这一关键限制的缓解方案。
🔗 开源详情
- 代码:提供了代码仓库链接:https://github.com/hcai-mms/MSM-face-voice
- 模型权重:未提及是否公开本文方法训练好的模型权重。论文中使用的预训练编码器(FaceNet, Ecapa-tdnn)是公开模型,但未指定具体版本。
- 数据集:实验使用的是公开基准数据集(VoxCeleb, MAV-Celeb),如何获取论文中未重复说明,但这些是标准数据集。
- Demo:未提及在线演示。
- 复现材料:论文给出了主要的训练细节:使用Quadro RTX 6000 GPU,训练50 epoch,batch size 512,Adam优化器,初始学习率10^-4,指数衰减。这为复现提供了足够信息。
- 论文中引用的开源项目:主要依赖预训练模型FaceNet和Ecapa-tdnn,二者均为公开可用的开源模型。
📌 核心摘要
- 解决的问题:现有人脸-语音关联方法主要依靠损失函数(如对比损失、三元组损失)来拉近同类、推远异类表示,但这些方法在处理大规模数据时计算复杂度高,且分类损失本身不足以产生具有强判别性的嵌入空间。
- 方法核心:提出了一种将“最大类分离”作为归纳偏置的方法。在多模态表示(由面部和语音嵌入加权平均得到)之后、最终的说话人分类层之前,插入一个固定的、非学习的矩阵(由公式1递归构建)。该矩阵预先最大化了不同类(说话人)之间的理论分离度。
- 创新点:
- 首次应用:这是首次将“最大类分离归纳偏置”应用于多模态学习任务(人脸-语音关联),而非仅限于单模态分类。
- 协同设计:证明了该归纳偏置矩阵与正交约束损失结合使用时效果最佳,该损失强制同说话人表示对齐,不同说话人表示正交。
- SOTA性能:在两个标准任务(跨模态验证、跨模态匹配)和两个基准数据集(VoxCeleb, MAV-Celeb)上取得了当前最优性能。
- 主要实验结果:
- VoxCeleb跨模态验证(EER↓):本文方法(Ours)在“已见-已听”配置下达到13.9%,优于之前最优方法Single Stream Network (17.2%);在“未见-未听”配置下达到22.9%,优于之前最优方法FOP (24.9%)。
- MAV-Celeb跨模态验证(EER↓):本文方法在总体(All)上达到17.7%,与最优方法Audio-visual持平;在英语(English)子集上达到16.5%,取得最优。
- VoxCeleb跨模态匹配:在所有测试的画廊大小(2到10)下,本文方法的匹配准确率均高于其他SOTA方法。
- 消融实验:仅用分类损失(CE)的效果一般;仅用归纳偏置矩阵(MSM)会降低性能;但分类损失+正交损失(FOP)与归纳偏置矩阵结合(Ours)时性能最佳,证明了三者的协同作用。
- 实际意义:该方法提升了人脸-语音跨模态关联的准确性,对于增强基于生物特征的身份认证系统、改善多模态内容检索和匹配的可靠性具有直接价值。
- 主要局限性:
- 归纳偏置矩阵的维度依赖于训练集的总说话人数量(Ns),可能限制了模型对训练时未见过的新说话人的泛化能力。
- 未研究该方法在说话人数量变化时的性能表现,也未验证其在其他多模态任务上的有效性。
- 方法将归纳偏置矩阵应用于当前SOTA模型,但未探究其对其他架构模型的普适性。
🏗️ 模型架构
整体架构如图1所示,是一个双分支、共享嵌入空间的多模态模型。
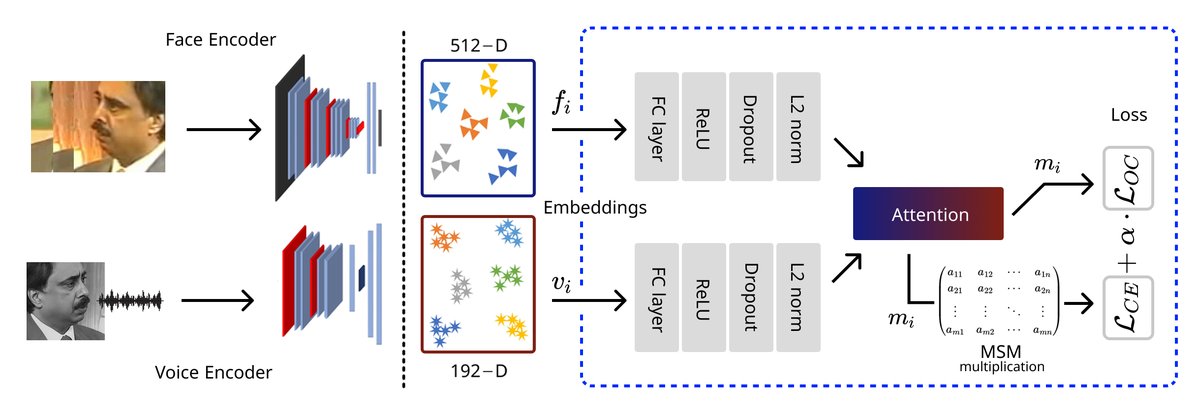
完整流程与组件:
- 输入:一个视频片段
i,包含人脸图像和语音音频。 - 特征提取(预训练,冻结):
- 人脸编码器:使用预训练的FaceNet,输入单帧图像,输出人脸特征向量。
- 语音编码器:使用预训练的Ecapa-tdnn,输入音频信号,输出语音特征向量。
- 注:这两个编码器的参数在整个训练过程中保持冻结,不参与更新。
- 嵌入投影网络(可学习):
- 人脸和语音特征向量分别通过一个独立的全连接层(输出维度
d=128,ReLU激活)、一个Dropout层,最后进行L2归一化。 - 输出得到维度为128的面部嵌入
f_i和语音嵌入v_i。
- 人脸和语音特征向量分别通过一个独立的全连接层(输出维度
- 多模态融合:
- 将
f_i和v_i进行加权平均,得到多模态表示m_i。权重是可学习的,在训练过程中调整。 m_i的维度被设为Ns - 1,其中Ns是训练集中的总说话人数量。这是为了与后续的归纳偏置矩阵匹配。
- 将
- 归纳偏置层(固定,非学习):
- 这是本文的核心创新组件。将多模态表示
m_i(维度Ns-1) 与一个固定的、最大类分离矩阵P_{Ns-1}(维度(Ns-1)×Ns) 相乘。 - 矩阵
P_{Ns-1}通过一个递归公式(公式1)预先计算,其设计目标是使Ns个类(说话人)在Ns-1维空间中具有最大化的理论分离度。 - 输出得到最终的logits向量
ĉ_i(维度Ns),表示对每个说话人的分类得分。
- 这是本文的核心创新组件。将多模态表示
- 输出:
- 训练时:logits
ĉ_i用于计算交叉熵损失。 - 推理时:
- 跨模态验证:使用L2归一化后的嵌入
f_i和v_i计算余弦相似度cos(f_i, v_i),通过阈值判断是否匹配。 - 跨模态匹配:对于给定的语音探针
v_i,计算其与画廊中所有人脸嵌入f_j的余弦相似度,选择相似度最高的作为匹配结果。
- 跨模态验证:使用L2归一化后的嵌入
- 训练时:logits
关键设计选择:
- 使用预训练编码器:利用在大规模人脸/语音数据上预训练的模型提取基础特征,是迁移学习的标准做法,能有效利用已有知识。
- 固定维度映射与归纳偏置:将多模态表示
m_i的维度硬性设置为Ns-1,并乘以固定矩阵。这一设计直接来源于单模态分类的工作[12],旨在通过几何约束预设一个良好的类间分离结构,作为训练的“导航图”。 - 加权平均融合:一种简单有效的多模态融合方式,权重可学习以自动调整两种模态的贡献。
💡 核心创新点
- 将“最大类分离归纳偏置”引入多模态学习:这是本文最核心的创新。之前该技术仅用于单模态分类(如图像分类)。作者首次将其适配到多模态的人脸-语音关联任务中,通过一个固定的几何约束矩阵,在训练开始前就为不同说话人的多模态表示预设了最大化的类间分离。这提供了一种不同于传统损失函数的、新的优化引导思路。
- 证明归纳偏置与正交约束损失的强协同效应:消融实验(表3)表明,单独使用归纳偏置矩阵(MSM)甚至会降低性能,但当它与针对多模态对齐和分离设计的正交约束损失(
L_OC)结合时(“Ours”),能带来最大的性能提升。这揭示了归纳偏置提供宏观结构引导,而损失函数进行微观细节优化的互补关系。 - 在两项标准任务和两个基准上实现SOTA:论文不仅提出了方法,还通过严格的实验验证了其有效性。在VoxCeleb和MAV-Celeb数据集的跨模态验证和匹配任务上,均报告了优于现有方法的性能,证明了该技术在该领域的适用性和先进性。
🔬 细节详述
- 训练数据:
- VoxCeleb:包含超过100,000个短片,来自1,251位名人的采访视频。使用与先前工作[3]相同的训练、验证、测试划分。评估设置包括“已见-已听”(Seen-Heard)和“未见-未听”(Unseen-Unheard)两种配置。
- MAV-Celeb:包含70位不同名人的多语言视频(英语、乌尔都语)。用于研究语言对人脸-语音关联的影响。使用与先前工作[23, 24, 25]相同的划分。
- 损失函数:
- 交叉熵损失 (
L_CE):标准的说话人分类损失,公式2。目标是让模型正确预测每个实例的说话人标签。对batch内所有实例的损失求和。 - 正交约束损失 (
L_OC):公式3。该损失有两部分:a) 最小化同一说话人不同实例表示m_i,m_j的余弦距离(即拉近同类);b) 最大化不同说话人表示m_i,m_k的余弦距离(即推远异类,且目标是正交)。两项求和后取绝对值。 - 总损失:
L = L_CE + α * L_OC。α是超参数,在验证集上调整以优化性能。
- 交叉熵损失 (
- 训练策略:
- 优化器:Adam优化器。
- 学习率:初始学习率为
10^-4,采用指数衰减。 - 批量大小:512。
- 训练轮数:50个epoch。
- 关键超参数:
- 嵌入维度
d:128。 - 归纳偏置矩阵的维度:
(Ns-1) x Ns,其中Ns为训练集总说话人数(VoxCeleb为1251)。 - 正交损失权重
α:在验证集上选择(论文中未给出具体值)。
- 嵌入维度
- 训练硬件:一块Quadro RTX 6000 GPU。
- 推理细节:跨模态验证中,使用固定的阈值将余弦相似度分数转换为二分类结果;跨模态匹配中,直接选择相似度最高的候选者。
- 正则化:使用了Dropout层(位于嵌入投影网络中)。
📊 实验结果
跨模态验证(主要指标:EER↓, AUC↑)
- VoxCeleb数据集(表1):
| Method | Seen-Heard EER↓ | Seen-Heard AUC↑ | Unseen-Unheard EER↓ | Unseen-Unheard AUC↑ |
|---|---|---|---|---|
| Learnable Pins [3] | 21.4 | 87.0 | 29.6 | 78.5 |
| Single Stream Net. [4] | 17.2 | 91.1 | 29.5 | 78.8 |
| FOP [5] | 19.3 | 89.3 | 24.9 | 83.5 |
| Ours | 13.9 | 93.7 | 22.9 | 85.0 |
结论:本文方法(Ours)在两个配置的所有指标上均取得最优。尤其在“已见-已听”配置下,EER从17.2%大幅降至13.9%。
- MAV-Celeb数据集(表2,指标为EER↓):
| Method | English EER↓ | Urdu EER↓ | All EER↓ |
|---|---|---|---|
| FOP [5] | 29.3 | 25.8 | 27.5 |
| Audio-visual [26] | 17.1 | 18.4 | 17.7 |
| Ours | 16.5 | 18.9 | 17.7 |
结论:本文方法在总体(All)上与最优方法Audio-visual持平(17.7%),并在英语子集上取得最优(16.5%),但在乌尔都语子集上略逊于Audio-visual(18.9% vs 18.4%)。
跨模态匹配
- VoxCeleb数据集匹配准确率(图2a):
- 图表显示了不同画廊大小(2��10)下的匹配准确率。本文方法(Ours)的曲线在所有画廊尺寸下均位于其他所有方法之上。
- 例如,在画廊大小为10时,本文方法的准确率约为65%,而其他方法大多低于60%。准确率随画廊增大而下降,但本文方法的下降幅度相对较小,表明其匹配信心更强。
消融实验(表3 & 图2b):
- VoxCeleb跨模态验证消融(表3):
| Method | Seen-Heard EER↓ | Seen-Heard AUC↑ | Unseen-Unheard EER↓ | Unseen-Unheard AUC↑ |
|---|---|---|---|---|
| CE | 17.2 | 90.6 | 24.6 | 83.2 |
| MSM | 21.4 | 87.4 | 37.8 | 65.8 |
| FOP* | 16.7 | 91.0 | 23.8 | 84.2 |
| Ours | 13.9 | 93.7 | 22.9 | 85.0 |
- 结论:
Ours(L_CE+L_OC+ 归纳偏置)是最佳组合。FOP*(L_CE+L_OC,无归纳偏置)是第二佳,证实了正交约束损失的有效性。MSM(L_CE+ 归纳偏置,无L_OC)性能显著下降,甚至不如仅用L_CE的CE,这强烈表明归纳偏置矩阵需要与正交约束损失配合才能生效。
- VoxCeleb跨模态匹配消融(图2b):趋势与验证任务一致,
Ours曲线最高,FOP*次之,CE和MSM较低且接近。
⚖️ 评分理由
- 学术质量(6.5/7):论文创新点明确且新颖(跨模态归纳偏置),技术路线清晰(双编码器+融合+偏置层),实验充分且对比有力(两个数据集,两个任务,详细消融)。主要扣分点在于技术本身并非颠覆性的基础模型创新,且归纳偏置矩阵对说话人数量的依赖可能限制其泛化潜力,论文未深入探讨此局限。
- 选题价值(1.5/2):人脸-语音关联是多模态身份识别的核心问题之一,具有明确的应用前景(安防、反欺诈)。该研究方向相对垂直,但持续受到关注。本文工作推进了该方向的技术边界。
- 开源与复现加成(0.5/1):提供了代码仓库链接,并给出了关键的训练超参数,这非常有利于社区复现。但未提供预训练模型权重(FaceNet, Ecapa-tdnn)的精确版本或下载链接,也未提供训练好的模型检查点,因此加成有限。