📄 Expressive Voice Conversion with Controllable Emotional Intensity
#语音转换 #数据增强 #注意力机制 #语音情感识别 #自监督学习
✅ 7.5/10 | 前25% | #语音转换 | #数据增强 | #注意力机制 #语音情感识别
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Nannan Teng(丝绸之路多语种认知计算联合国际研究实验室,新疆大学计算机科学与技术学院)
- 通讯作者:Ying Hu(丝绸之路多语种认知计算联合国际研究实验室,新疆大学计算机科学与技术学院)
- 作者列表:Nannan Teng(丝绸之路多语种认知计算联合国际研究实验室,新疆大学计算机科学与技术学院)、Ying Hu(丝绸之路多语种认知计算联合国际研究实验室,新疆大学计算机科学与技术学院)、Zhijian Ou(清华大学电机工程与应用电子技术系)、Sheng Li(东京科学大学工程学院)
💡 毒舌点评
这篇论文最亮眼的地方在于它清晰的“问题-方案”对应逻辑:用“特定属性增强”制造更鲁棒的特征,用“联合注意力”优雅地融合并控制说话人与情感风格,最后用“扰动归一化”来提升合成的表现力,模块设计环环相扣且动机明确。短板则在于情感控制的粒度仍显粗糙,一个标量α控制所有情绪类别的强度,缺乏对不同情绪(如“喜悦”与“愤怒”)可能具有不同强度响应曲线的建模,这在一定程度上限制了其实用性和精细度。
🔗 开源详情
- 代码:提供了代码仓库链接:
https://tengnn.github.io/ExpressiveVC/。 - 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用ESD英文数据集和RAVDESS数据集进行测试,这两个均为公开数据集,但论文未提供具体的获取或预处理脚本。
- Demo:提供了在线演示链接:
https://tengnn.github.io/ExpressiveVC/。 - 复现材料:论文提供了方法的基本描述和公式,但缺乏具体的训练细节(如优化器、学习率、批大小、训练时长)和模型配置信息。
- 引用的开源项目:论文未明确列出所有依赖项,但可以推断其使用了Wav2vec 2.0(用于特征提取)、以及可能的HiFi-GAN(作为声码器)等开源模型。
📌 核心摘要
- 解决的问题:现有的表现力语音转换(VC)方法要么专注于说话人身份和情感风格的迁移,要么专注于情感强度的可控调节,未能很好地将两者结合。本文旨在提出一个能同时实现高质量说话人转换、情感迁移,并允许用户精细控制目标情感强度的VC模型。
- 方法核心:提出了CEI-VC模型,包含三个关键组件:a) 特定属性增强(SAA):通过共振峰偏移和音高单调化等数据扰动策略,增强模型对说话人和情感特征的鲁棒性。b) 情感解耦与强度控制(EDIC)模块:利用解耦损失和基于联合注意力的风格融合机制,将说话人与情感特征分离,并引入可调参数α在推理时控制情感强度。c) 扰动自适应实例归一化(PbAdaIN):在归一化层中对风格特征施加扰动,提升合成语音的自然度和表现力。
- 与已有方法相比新在哪里:主要新意在于系统性地结合了数据增强、特征解耦与可控生成三个环节。具体创新包括:1)提出了针对性的SAA策略来同时扰动说话人和情感属性;2)设计了UDIA模块,通过联合注意力机制和可调参数实现情感强度的连续控制;3)提出了PbAdaIN,通过在特征归一化时引入可控噪声来增强表达力。
- 主要实验结果:在ESD英语数据集上的实验表明,CEI-VC在多项指标上优于5个对比模型。在Unseen-to-Unseen场景下,其自然度MOS(nMOS)为4.02,情感相似度MOS(eMOS)为3.30,情感嵌入余弦相似度(EECS)为0.6663,均为最佳或次佳。消融实验证明SAA、PbAdaIN和UDIA模块均对性能有显著贡献。通过调节参数α(0.2, 0.5, 0.9),转换语音的平均音高和情感分类准确率随强度增加而变化,验证了情感强度控制的有效性。
- 实际意义:该模型可应用于需要情感表现力和身份控制的语音合成场景,如个性化有声读物生成、影视配音、以及更自然的人机交互对话系统。
- 主要局限性:论文未讨论模型在极短语音或噪声环境下的鲁棒性;情感强度控制机制(标量α)可能对所有情绪类型过于简化;未公开模型权重和详细训练配置,限制了完全复现。
🏗️ 模型架构
本文提出的CEI-VC模型整体架构如图1所示。其核心是基于变分自编码器(VAE)和归一化流(Normalizing Flow)的框架,旨在学习并转换语音的说话人、情感和内容特征。
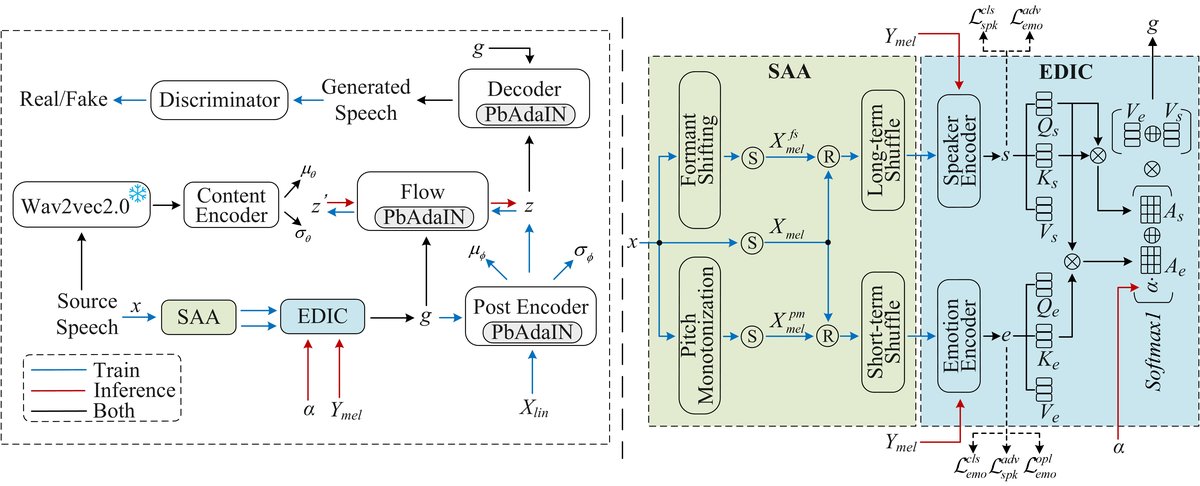
整体流程如下:
- 编码阶段:源语音的自监督表示(来自Wav2vec 2.0)输入内容编码器,生成先验分布
(μ_θ, σ_θ)。源语音的线性谱图X_lin输入后验编码器,生成后验分布(μ_ϕ, σ_ϕ),并从中采样隐变量z。归一化流模块用于将后验分布映射到先验分布。 - 风格提取与注入:
- SAA策略:源语音
x经过两个扰动分支(共振峰偏移和音高单调化),并与原始语音一起,通过短时傅里叶变换(STFT)得到三组梅尔谱图。在每条分支中,随机替换一半谱图并进行不同粒度的时间打乱,以部分保留原始信息并消除语言内容的干扰。最终输出两条增强后的梅尔谱图。 - EDIC模块:两条增强梅尔谱图分别输入说话人编码器和情感编码器,得到说话人嵌入
s和情感嵌入e。通过计算分类损失和对抗损失(使用梯度反转层)来实现特征解耦(式1)。为了保留情感信息,还应用了正交投影损失(式2)。最终,通过联合注意力机制(UA)(式3)融合s和e得到风格特征g。g被送入后验编码器、归一化流和解码器。 - PbAdaIN模块:解码器、后验编码器和流模块中的每个归一化层都被替换为PbAdaIN(式5,6)。它在标准的自适应实例归一化(AdaIN)基础上,对风格特征计算出的缩放
γ和偏移β参数添加可控噪声扰动,从而增强合成语音的表达力。
- SAA策略:源语音
- 解码与判别:解码器接收处理后的隐表示和注入的风格特征
g,生成梅尔谱图,再通过HiFi-GAN等声码器合成波形。判别器用于区分真实与合成语音,构成生成对抗网络的一部分。 - 推理阶段:将目标语音的梅尔谱图
Y_mel和手动设置的情感强度参数α输入EDIC模块,得到目标风格特征g。同时,通过逆向流将内容特征z'与g结合,生成保留源内容、具有目标说话人和情感的转换语音。
关键设计选择与动机:
- SAA:动机是增强模型对说话人和情感属性变化的鲁棒性,使其学习到更本质的内容特征。
- EDIC:动机是解决现有方法无法同时有效解耦风格和控制强度的问题。UA机制通过并行考虑“同说话人不同情感”和“同情感不同说话人”的差异,来实现更灵活的融合。参数
α在推理时提供了对情感强度的直观控制。 - PbAdaIN:动机是解决传统VC模型中风格融合不充分、表达力弱的问题。通过向风格参数添加高斯噪声扰动,可以增强生成的多样性和表现力。
💡 核心创新点
特定属性增强(SAA)训练策略:
- 是什么:一种数据增强方法,对源语音施加两种定向扰动(共振峰偏移扰动音色,音高单调化压制情感表达),并结合时间维度的打乱,生成多样化的训练样本。
- 局限:以往方法(如Lei等[12], Sato等[13])的扰动较为单一或随机。SAA则针对语音转换需要保留的“内容”和需要转换的“属性”(说话人/情感)设计了不同的扰动路径。
- 如何起作用:通过部分破坏和重组说话人与情感特征,迫使模型更关注语言内容,并提升对目标风格变化的泛化能力。
- 收益:消融实验(表2)显示,移除SAA后,所有指标均下降,证明其提升了模型鲁棒性和最终性能。
情感解耦与强度控制(EDIC)模块及联合注意力(UA)机制:
- 是什么:一个集成了特征解耦损失(式1,2)和可控风格融合的模块。UA机制是其核心,将情感与说话人的交叉注意力与说话人自注意力相结合,并引入强度参数
α。 - 局限:早期的情感VC方法(如Zhou等[9])或情感TTS方法(如Li等[10])通常独立处理风格转换或强度控制。EDIC尝试在一个框架内统一这两项任务。
- 如何起作用:解耦损失学习分离的
s和e。UA机制在推理时,通过α加权调整情感注意力部分,从而控制最终风格特征g中情感成分的强度。 - 收益:实验(图3)证明,通过调整
α(0.2, 0.5, 0.9),转换语音的音高和情感分类准确率呈现符合预期的变化,实现了连续的情感强度控制。t-SNE可视化(图2)也展示了特征解耦的效果。
- 是什么:一个集成了特征解耦损失(式1,2)和可控风格融合的模块。UA机制是其核心,将情感与说话人的交叉注意力与说话人自注意力相结合,并引入强度参数
扰动自适应实例归一化(PbAdaIN):
- 是什么:一种改进的归一化层,在AdaIN计算出的风格参数
γ和β上添加基于其标准差的可控高斯噪声。 - 局限:传统VITS类模型(如FreeVC[20], ConsistencyVC[2])使用简单的加法或AdaIN融合风格,表达力有限。
- 如何起作用:引入的扰动增加了训练时风格特征的随机性,使得解码器能够学习到更丰富、更鲁棒的风格表示,从而增强合成语音的表现力和自然度。
- 收益:消融实验(表2)显示,移除PbAdaIN后,自然度和情感相似度等指标明显下降,证明其有效提升了合成质量。
- 是什么:一种改进的归一化层,在AdaIN计算出的风格参数
🔬 细节详述
- 训练数据:
- 数据集:ESD英文数据集。包含10位说话人,5种情感类别(中性、惊讶、高兴、悲伤、愤怒),共350个语句。
- 预处理:源语音输入为Wav2vec 2.0的自监督表示和线性谱图。目标语音输入为梅尔谱图。具体采样率、帧长等参数未说明。
- 数据增强:核心即为SAA策略,包括共振峰偏移、音高单调化以及两种不同尺度的时间打乱(长时25帧块打乱,短时30帧块内10帧子块打乱)。
- 损失函数:
- 解耦损失
L_DIS(式1):包含说话人嵌入分类损失L_cls_spk、情感嵌入分类损失L_cls_emo,以及通过梯度反转层(GRL)计算的对抗性损失L_adv_emo和L_adv_spk,用于实现特征解耦。 - 正交投影损失
L_opl_emo(式2):约束同一情感类别的嵌入向量相似度高,不同类别的嵌入向量相似度低,以保留情感信息。 - 重建损失、KL散度、对抗损失:作为VAE和GAN框架的标配损失,论文中未详细列出公式,但推测存在。
- 解耦损失
- 训练策略:
- 优化器:未说明。
- 学习率:未说明。
- Batch Size:未说明。
- 训练步数/轮数:未说明。
- 调度策略:未说明。
- 关键超参数:
- 情感强度控制参数
α:训练时固定为1,推理时手动设置(如0.2, 0.5, 0.9)。 - PbAdaIN扰动强度
λ:训练时固定为0.3。
- 情感强度控制参数
- 训练硬件:未说明。
- 推理细节:
- 解码策略:基于VAE-Flow的逆向映射和声码器。
- 温度、Beam Size:未说明。
- 流式设置:未提及,应为非流式。
- 正则化或稳定训练技巧:
- 使用了梯度反转层(GRL)进行对抗训练以实现解耦。
- 使用了改进的Softmax1(分母加1)以引入“逃生机制”,防止训练崩溃(参考[18])。
- PbAdaIN本身可视为一种正则化方法,通过注入噪声防止过拟合。
📊 实验结果
主要实验对比(表1): 在Seen-to-Seen和Unseen-to-Unseen两个场景下,将CEI-VC与5个近期模型(Style-VC, ConsistencyVC, X-E-Speech, DDDM-VC, ExVC)进行对比。
| 模型 | 场景 | nMOS↑ | sMOS↑ | eMOS↑ | SECS↑ | EECS↑ | WER↓ |
|---|---|---|---|---|---|---|---|
| Style-VC | Seen-to-Seen | 3.51 | 3.45 | 3.67 | 0.8010 | 0.6642 | - |
| Unseen-to-Unseen | 3.09 | 2.53 | 2.42 | 0.6967 | 0.5816 | 17.80% | |
| ConsistencyVC | Seen-to-Seen | 3.78 | 3.84 | 3.97 | 0.8509 | 0.6583 | - |
| Unseen-to-Unseen | 3.78 | 3.05 | 3.02 | 0.7449 | 0.5899 | 12.76% | |
| X-E-Speech | Seen-to-Seen | 4.01 | 3.87 | 3.98 | 0.8467 | 0.6957 | - |
| Unseen-to-Unseen | 3.90 | 3.14 | 3.29 | 0.7217 | 0.6132 | 13.99% | |
| DDDM-VC | Seen-to-Seen | 4.10 | 4.04 | 4.01 | 0.8707 | 0.7390 | - |
| Unseen-to-Unseen | 3.96 | 3.37 | 3.20 | 0.7653 | 0.6342 | 14.20% | |
| ExVC | Seen-to-Seen | 4.00 | 4.03 | 4.00 | 0.8505 | 0.6990 | - |
| Unseen-to-Unseen | 3.94 | 3.26 | 3.18 | 0.7548 | 0.6257 | 12.30% | |
| CEI-VC | Seen-to-Seen | 4.19 | 4.03 | 4.05 | 0.8656 | 0.7629 | - |
| Unseen-to-Unseen | 4.02 | 3.39 | 3.30 | 0.7755 | 0.6663 | 12.59% |
- 关键结论:CEI-VC在大多数指标上取得了最佳或接近最佳的成绩。尤其在Unseen-to-Unseen场景(更具挑战性)下,其在自然度、说话人相似度、情感相似度和情感嵌入相似度上均为最优。在可懂度(WER)上略逊于ExVC(12.59% vs 12.30%),但优于其他模型。
消融实验(表2): 在Unseen-to-Unseen场景下,验证三个核心组件的有效性。
| 模型 | nMOS↑ | sMOS↑ | eMOS↑ | SECS↑ | EECS↑ | WER↓ |
|---|---|---|---|---|---|---|
| CEI-VC | 4.02 | 3.39 | 3.30 | 0.7755 | 0.6663 | 12.59% |
| - UA | 3.94 | 3.28 | 3.24 | 0.7562 | 0.6455 | 16.49% |
| - SAA | 3.97 | 3.21 | 3.20 | 0.7447 | 0.6346 | 14.83% |
| - PbAdaIN | 3.94 | 3.23 | 3.24 | 0.7455 | 0.6351 | 15.65% |
| - SAA, PbAdaIN | 3.96 | 3.10 | 3.03 | 0.7358 | 0.6181 | 14.39% |
- 关键结论:移除任何单一组件(UA, SAA, PbAdaIN)都会导致所有性能指标的下降,证明了每个组件的必要性。同时移除SAA和PbAdaIN导致性能进一步下降,表明它们之间可能存在一定的互补性。
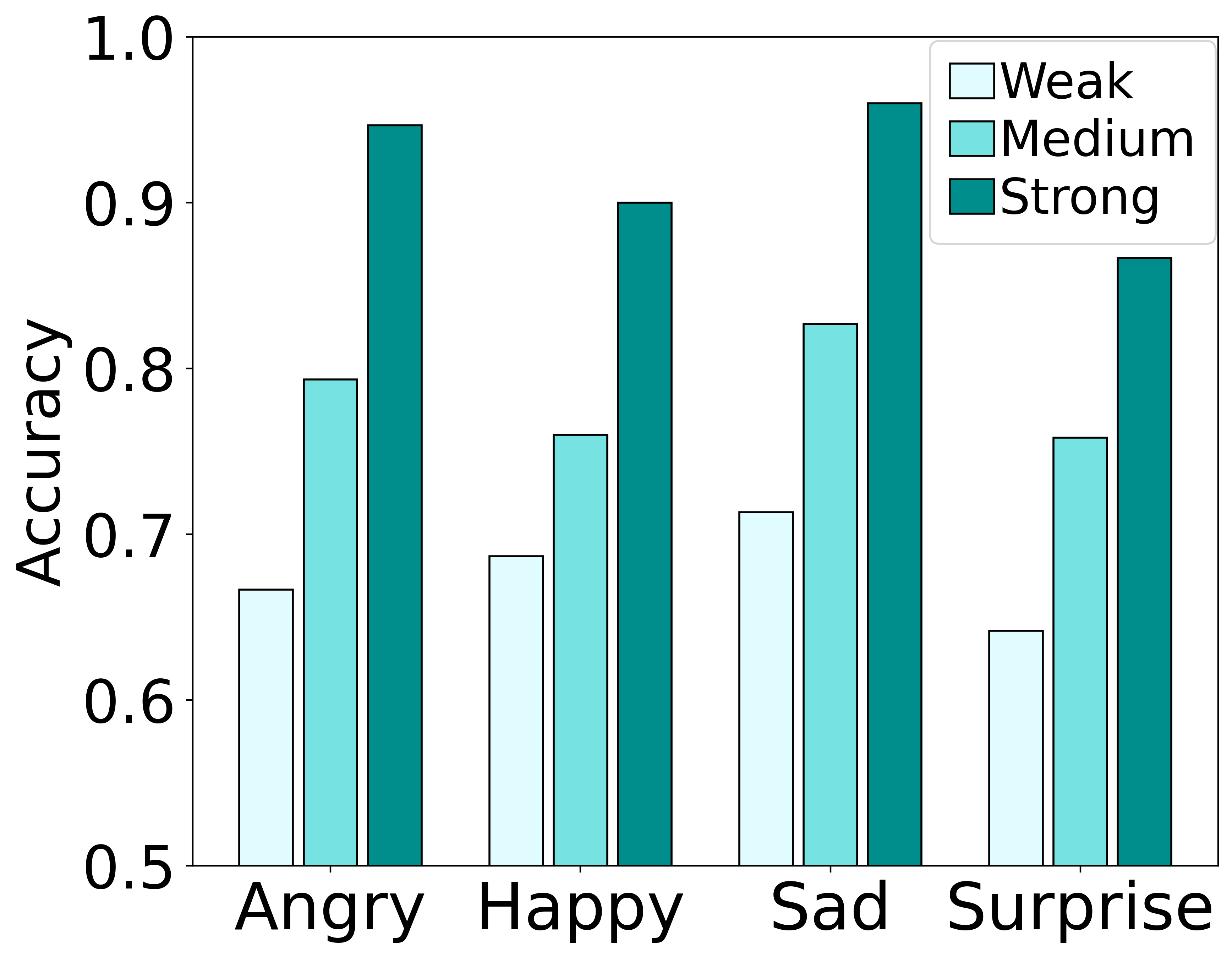
情感强度控制验证(图3):
通过设置不同的 α 值(0.2:弱, 0.5:中, 0.9:强),分析转换语音的平均音高和情感分类准确率。
- 关键结论:随着情感强度增加,除悲伤外,其他情绪的平均音高普遍上升;同时,情感分类的准确率也呈现上升趋势。这符合心理声学常识(如高兴、愤怒时音高较高),并定量地证明了模型能够通过参数
α有效控制输出语音的情感强度。
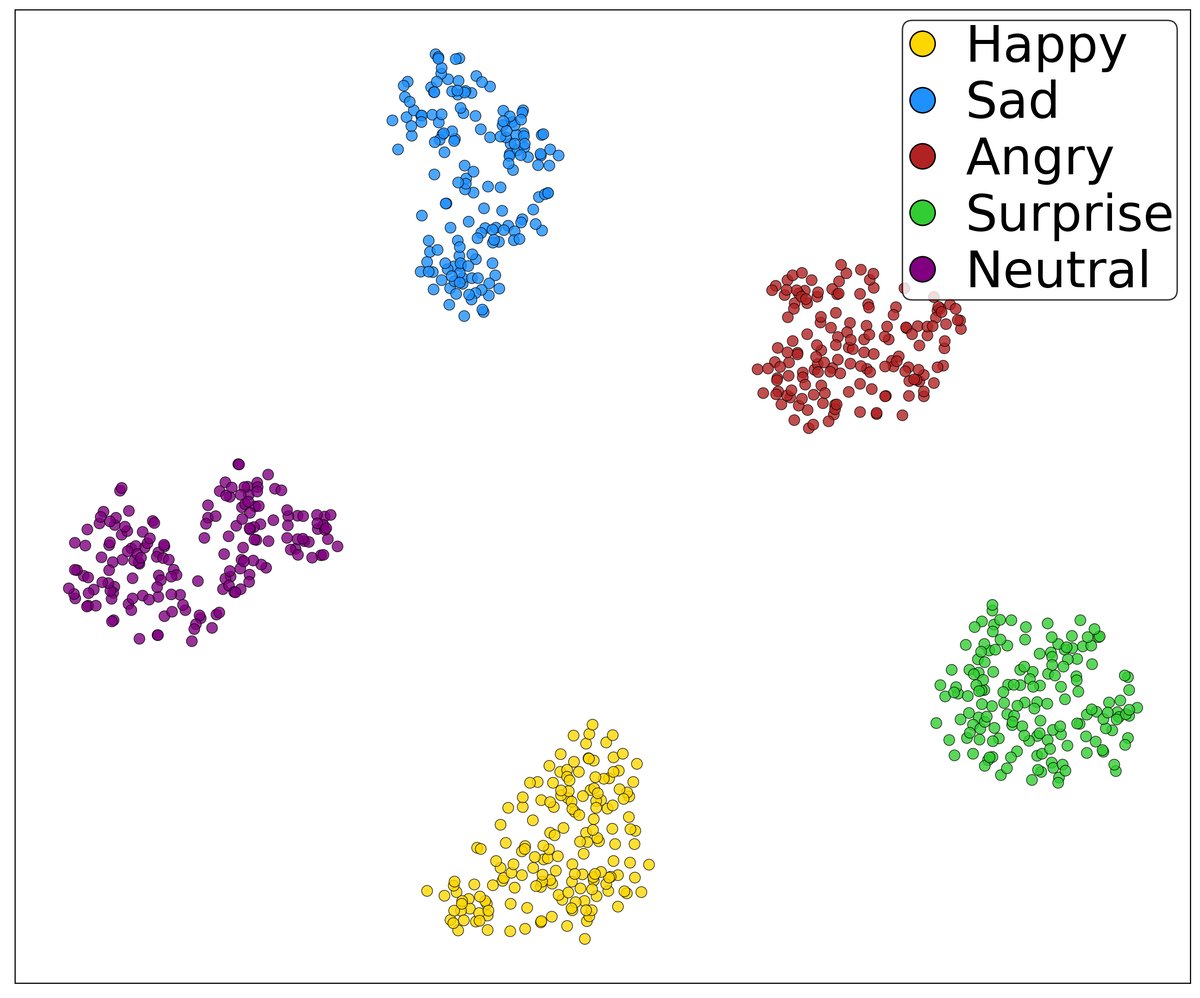
特征分布可视化(图2):
展示了说话人和情感特征在应用解耦损失 L_DIS 前后的t-SNE分布。
- 关键结论:应用
L_DIS后,说话人特征(左图)的聚类更加清晰,情感特征(右图)的类间分离度也得到提升,直观地验证了特征解耦的有效性。
⚖️ 评分理由
- 学术质量:6.0/7:本文的创新是组件级的、针对性的工程优化。SAA、UDIA和PbAdaIN三个模块设计思路清晰,动机明确,且通过充分的实验(对比实验、消融实验、控制变量实验)验证了其有效性。技术路线正确,结果可信。然而,这些创新更多是现有技术(数据增强、注意力机制、风格归一化)在语音转换任务上的巧妙组合与适配,而非提出全新的理论框架或算法突破。
- 选题价值:1.5/2:课题切中了语音合成领域对“情感可控性”和“高表现力”的迫切需求。将说话人转换与情感强度控制统一到一个模型中,具有明确的应用前景(如定制化语音内容创作)。任务本身是前沿且实际的。
- 开源与复现:0.5/1:论文明确提供了代码仓库链接(https://tengnn.github.io/ExpressiveVC/),这是重要的加分项。但论文中未提及模型权重、数据集获取方式(需自行下载ESD)、以及详细的训练超参数(如学习率、优化器),这增加了完全复现的难度。因此给予部分加分。