📄 Evaluating Pretrained Speech Embedding Systems for Dysarthria Detection Across Heterogenous Datasets
#语音生物标志物 #模型评估 #基准测试 #数据集
✅ 7.5/10 | 前50% | #语音生物标志物 | #模型评估 | #基准测试 #数据集
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Lovisa Wihlborg (SpeakUnique Ltd., UK)
- 通讯作者:未说明(论文页脚提供联系地址:SpeakUnique Ltd., 17 New Court, Lincoln’s Inn, London, WC2A 3LH, UK)
- 作者列表: Lovisa Wihlborg¹, Jemima Goodall¹, David Wheatley¹, Jacob J. Webber¹ (¹SpeakUnique Ltd., UK) Johnny Tam²,⁴, Christine Weaver²,⁴, Suvankar Pal²,⁴,⁵, Siddharthan Chandran²,⁴,⁵ (²Anne Rowling Regenerative Neurology Clinic, University of Edinburgh, UK; ⁴Euan MacDonald Centre for MND Research, UoE; ⁵UK Dementia Research Institute, UK) Sohan Seth³ (³Institute of Adaptive and Neural Computation, UoE, UK) Oliver Watts¹,², Cassia Valentini-Botinhao¹ (¹SpeakUnique Ltd., UK; ²Anne Rowling Regenerative Neurology Clinic, UoE, UK)
💡 毒舌点评
这篇论文像是一位严谨的“测评博主”,把17款热门语音嵌入模型放在6个公开的构音障碍数据集上“烤机”,还非常讲究地设置了统计检验来排除运气成分,其评估框架的稳健性值得肯定。然而,它的“创新”也仅限于测评方法本身,缺乏对“为何某些模型/数据集表现更好或更差”更深入的机制性分析,最终结论(跨数据集性能下降)虽符合预期但略显平淡。
🔗 开源详情
- 代码:论文中未提及代码链接。但评估依赖的预训练模型和数据集均为公开可用(链接见参考文献)。
- 模型权重:未提及新模型权重。评估的17个系统均为公开预训练模型(如Wav2Vec2, UniSpeech, x-vector等)。
- 数据集:论文中使用的6个数据集(EWA, EasyCall, Neurovoz, SSNCE, TORGO, UASpeech)均为公开数据集,获取方式见表1及参考文献链接。
- Demo:未提及。
- 复现材料:提供了详细的交叉验证设置(20次5折,按说话人分组)、分类器参数(1000棵树)以及特征提取流程。但未提供具体的训练脚本或配置文件。
- 论文中引用的开源项目:列出了大量依赖的开源工具/模型,包括:
Hugging Face Transformers(Wav2Vec2, UniSpeech等),SpeechBrain(CRDNN, ECAPA-TDNN, x-vector等),Librosa/openSMILE(eGeMAPSv2),scikit-learn(随机森林),Resemblyzer等。
📌 核心摘要
- 要解决的问题:构音障碍(Dysarthria)的语音检测研究受限于现有小型、有偏差的数据集,且模型评估缺乏统一标准,结果可靠性存疑。
- 方法核心:采用系统性评估框架。使用6个公开的异构数据集(覆盖不同语言和疾病),对17个预训练语音嵌入系统(涵盖自监督、ASR、说话人验证等多类)进行统一评估。采用20次5折交叉验证,并引入零假设分布进行统计检验,确保结果显著优于随机猜测。关键创新是进行了跨数据集评估(在一个数据集上训练,在另一个上测试)。
- 与已有方法相比新在哪里:不同于以往基于单一数据集的评估,本工作首次在大规模、多样化的公开数据集和模型上,系统性地研究了构音障碍检测任务的评估方法可靠性和模型泛化能力,并强调了数据集偏差可能对基准性能造成的严重影响。
- 主要实验结果:
- 数据集难度差异显著:无论使用何种模型,SSNCE数据集准确率普遍高于95%,而EWA数据集大部分低于65%,表明数据集本身特性对性能影响巨大。
- 模型表现:基于ASR任务预训练的模型平均表现最好;x-vector模型在跨数据集上性能波动最小;小巧的传统特征集(如DigiPsychProsody)性能接近大型神经网络。
- 泛化能力不足:在EWA和Neurovoz两个PD数据集间的跨数据集评估显示,准确率相比数据集内评估显著下降(例如,从Neurovoz训练迁移到EWA,准确率从约80%降至约51%)。
- 统计验证:超过92%的模型-数据集组合的准确率显著高于偶然水平(p<0.05,经Bonferroni校正)。
- 实际意义:为构音障碍检测领域的研究者提供了宝贵的评估基准和方法论指导。强烈提示在报告模型性能时,必须考虑数据集偏差,并应进行跨数据集验证,否则临床有效性存疑。
- 主要局限性:评估局限于17个特定的公开模型和6个数据集,未探索模型集成或针对医疗任务的微调。未对观察到的数据集难度差异进行深入的成因分析(如录音条件、疾病严重度标注等)。
🏗️ 模型架构
本文的核心并非提出一个新模型,而是评估一系列现有的语音嵌入系统。这些系统的整体流程相似,可概括为:
- 输入:原始语音波形(重采样至16kHz)。
- 嵌入提取:使用公开的预训练模型将变长语音转换为固定长度的向量表示(嵌入)。根据模型不同:
- 自监督模型(如Wav2Vec2Bert, UniSpeech-SAT):通过对比学习等自监督目标从大规模语音数据中学习通用表示。
- ASR模型(如Wav2Vec+Conf, CRDNN+CTC):基于自动语音识别任务预训练。
- 说话人验证(SV)模型(如TitaNet, ECAPA-TDNN, x-vector):旨在区分不同说话人的身份。
- 传统信号处理特征(如eGeMAPSv2):基于规则和声学知识的手工特征。
- 时间聚合:对于输出包含时间轴的模型(如CRDNN+CTC),取时间维度的平均值得到单一向量。
- 分类:将固定长度嵌入作为特征,输入到随机森林分类器(1000棵树,scikit-learn默认配置)中进行二分类(健康 vs. 构音障碍)。分类器在交叉验证中训练和评估。
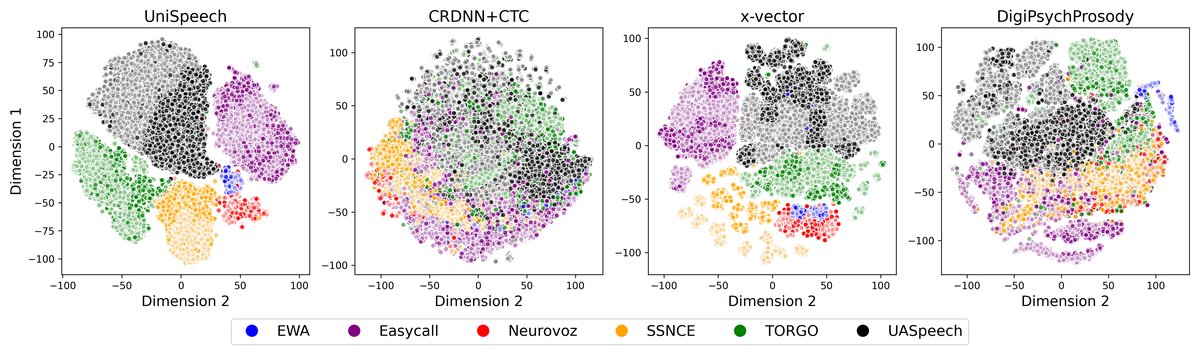 图1展示了UniSpeech、x-vector、DigiPsychProsody和CRDNN+CTC四种嵌入系统的t-SNE可视化。可以看出,UniSpeech和x-vector空间能清晰区分不同数据集,x-vector还能形成说话人聚类。相比之下,CRDNN+CTC的数据集分离度较低,但健康/障碍类别分离也不明显。这直观说明了不同嵌入系统的表征特性差异。
图1展示了UniSpeech、x-vector、DigiPsychProsody和CRDNN+CTC四种嵌入系统的t-SNE可视化。可以看出,UniSpeech和x-vector空间能清晰区分不同数据集,x-vector还能形成说话人聚类。相比之下,CRDNN+CTC的数据集分离度较低,但健康/障碍类别分离也不明显。这直观说明了不同嵌入系统的表征特性差异。
💡 核心创新点
- 稳健的统计评估框架:为每个“特征-任务”组合构建零假设分布(通过标签置换),并使用Welch’s t检验确认模型性能显著高于随机水平。这比简单报告单一准确率更能确保结论的可靠性,尤其是在小规模医疗数据集上。
- 跨数据集泛化评估:首次在构音障碍检测任务中,系统性地报告了模型在不同数据集间迁移时的性能下降。这直接揭示了当前基于单一数据集训练的模型在真实世界异构数据上的脆弱性,比单纯追求数据集内指标更具临床参考价值。
- 大规模异构基准测试:在统一协议下评估了17个涵盖不同技术路线(自监督、ASR、SV、传统特征)的模型和6个覆盖多语言、多疾病的数据集,为社区提供了迄今最全面的性能基线图谱。
🔬 细节详述
- 训练数据:评估使用的6个公开数据集见表1。关键预处理是统一重采样至16kHz。对于不平衡数据集,选取子集进行类别平衡(健康/障碍样本数大致相等),并在交叉验证中确保性别和年龄分布均衡。
- 损失函数:未说明。因为评估的是预训练模型,本文仅使用其提取特征,不涉及模型训练。最终分类器使用随机森林,其内部损失为基尼不纯度。
- 训练策略:
- 交叉验证:采用20次独立的5折交叉验证。为防止数据泄露,同一说话人的所有样本被强制分配到同一折。
- 分类器:
sklearn.ensemble.RandomForestClassifier,n_estimators=1000,固定随机种子,其他参数默认。 - 超参数搜索:未说明,使用了默认配置。
- 关键超参数:所评估的17个嵌入系统的参数量和嵌入维度见表2,范围从1.4M到635M参数,嵌入维度从21到1024不等。
- 训练硬件:未说明。
- 推理细节:对于有时间维度的嵌入,取时间平均池化为单一向量。分类时,对同一说话人的多个录音预测结果进行多数投票以获得最终标签。
- 正则化:未说明。随机森林本身有抗过拟合特性。
📊 实验结果
主要实验结果总结(基于准确率)
| 评估类型 | 关键发现与数据 |
|---|---|
| 数据集内(交叉验证) | 1. 性能范围:在SSNCE数据集上,多数模型准确率 > 95%;在EWA数据集上,多数模型准确率 < 65%。见下图。 |
| 2. 模型对比:ASR任务预训练模型(如CRDNN+CTC)平均表现最佳。x-vector在各数据集上性能变异最小。DigiPsychProsody(21维特征)性能接近复杂神经网络。 | |
| 跨数据集 | 1. Neurovoz (训练) -> EWA (测试):准确率从79.62%(数据集内)降至51.08%。 |
| 2. EWA (训练) -> Neurovoz (测试):准确率从60.27%(数据集内)降至54.08%。 | |
| 统计显著性 | 102个“系统-数据集”组合中,有94个的平均准确率显著高于零假设分布(p<0.05,Bonferroni校正后)。 |
图2左图按模型排列,显示每个模型在6个数据集上的准确率(点)及其四分位数范围(箱线图)。右图按数据集排列,显示每个数据集上17个模型的准确率分布。清晰展示了数据集间性能的巨大差异(如SSNCE vs. EWA)。
图3: 跨数据集 vs 数据集内准确率] 图3展示了在Neurovoz和EWA两个数据集上进行交叉迁移学习的结果。左图:在Neurovoz上训练的模型,其在Neurovoz内的性能(x轴)远高于在EWA上的性能(y轴)。右图:在EWA上训练的模型,其在EWA内的性能略高于在Neurovoz上的性能。所有点都低于对角线,直观证明了跨数据集泛化能力的损失。
⚖️ 评分理由
- 学术质量:5.5/7:技术正确性高,实验设计(多次交叉验证、零假设检验)严谨,系统性地揭示了当前研究范式中的关键问题(数据集偏差、泛化不足)。但核心贡献在于“评估”和“揭示问题”,而非解决这些问题,创新性有所局限。
- 选题价值:1.5/2:选题直接面向医疗AI落地的核心痛点,关注评估的可靠性和模型的泛化性,对于推动语音生物标志物研究具有重要的实践指导意义,与领域内研究者高度相关。
- 开源与复现加成:0.5/1:充分利用了现有的公开模型和数据,使得评估框架易于复现。但论文本身未提供新的代码或工具,复现的便利性主要依赖于第三方资源的维护。