📄 Etude: Piano Cover Generation with a Three-Stage Approach — Extract, Structuralize, and Decode
#音乐生成 #生成模型 #自回归模型 #音乐信息检索
✅ 7.0/10 | 前25% | #音乐生成 | #自回归模型 | #生成模型 #音乐信息检索
学术质量 6.0/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Tse-Yang Chen(National Taiwan University)
- 通讯作者:论文中未明确标注通讯作者
- 作者列表:Tse-Yang Chen(National Taiwan University), Yuh-Jzer Joung(National Taiwan University)
💡 毒舌点评
论文的核心亮点在于三阶段解耦架构的设计非常巧妙,通过“提取-结构化解码”的流水线,强制让模型关注节拍对齐这一被以往工作忽视的关键,从而在主观听感上实现了质的飞跃(尤其是流畅度)。然而,其短板也显而易见:所构建的~4700首歌曲数据集虽然规模尚可,但高度集中于J-pop/K-pop,方法的泛化能力在其他音乐风格(如古典、爵士)上的有效性存疑,且“风格注入”的实际控制粒度和效果在论文中并未得到充分展示。
🔗 开源详情
- 代码:论文中明确提供了项目页面链接:
https://xiugapurin.github.io/Etude/,并声称所有代码将在该页面开源。 - 模型权重:论文中未明确提及是否公开训练好的模型权重。
- 数据集:论文描述了自行收集和筛选的数据集规模(4,752对,约500小时),但未明确说明是否公开原始音频数据集。仅提到代码、音频演示和完整手稿可在项目页面获取。
- Demo:项目页面提供了音频演示(Audio Demonstrations)。
- 复现材料:论文详细说明了数据集构建流程、模型架构细节(如GPT-NeoX参数配置)、训练超参数(学习率、批次大小、优化器、调度策略等),为复现提供了较好的信息基础。
- 论文中引用的开源项目:使用了Beat-Transformer[8]、MrMsDTW[14]、SyncToolbox[15]、GPT-NeoX[16]、AdamW[17]。
- 论文中未提及开源计划:论文中明确表示将在项目页面提供代码和演示,因此不能说未提及开源计划。但关于数据集和模型权重的公开情况,信息不完整。
📌 核心摘要
- 问题:现有深度学习自动钢琴编曲(APCG)模型在生成的钢琴谱中经常出现节奏不一致、拍子混乱等问题,导致音乐结构感缺失,整体质量不高。
- 核心方法:提出三阶段框架“Etude”。Extract阶段从原始音频中提取密集的、类MIDI的音乐事件特征;Structuralize阶段(与Extract并行)使用预训练Beat-Transformer提取精确的节拍框架(Fbeat);Decode阶段基于Transformer,以小节为单位,结合提取的特征(X)、风格向量和前四小节的上下文,自回归生成目标钢琴序列(Y)。
- 创新点:相比已有两阶段模型(如PiCoGen),新方法显式解耦了节拍检测,保证了结构一致性;设计了极简的Tiny-REMI标记化方案,移除了对APCG任务冗余的Token,降低了学习难度;引入了可控的风格向量,允许用户调节音乐织体和表情。
- 主要实验结果:在100首测试集上,Etude(默认设置)在主观平均分(OVL)上达到3.50(满分5),显著优于基线PiCoGen2(2.97)、AMT-APC(2.46)和Music2MIDI(2.27),且统计显著(p<0.001)。在所提出的结构相似度(WPD)、节奏网格一致性(RGC)和节奏模式复杂度(IPE)等客观指标上,也表现出更接近人类演奏的平衡状态。详细结果见下表。
模型 主观总体分 (OVL) ↑ 主观流畅度 (FL) ↑ WPD ↓ RGC ↓ IPE Human 3.92 ± 0.96 4.03 ± 1.02 0.49 0.042 10.13 Etude - Default 3.50 ± 0.99 3.73 ± 0.98 0.21 0.020 9.02 Etude - Prompted 3.46 ± 1.00 3.70 ± 1.05 0.23 0.026 9.11 Etude Extractor 3.33 ± 1.00 3.31 ± 1.13 0.12 0.028 10.62 PiCoGen2 [3] 2.97 ± 1.04 3.33 ± 1.12 1.00 0.059 7.97 AMT-APC [4] 2.46 ± 1.04 2.37 ± 1.11 0.09 0.114 10.69 Music2MIDI [5] 2.27 ± 1.07 2.29 ± 1.13 0.18 0.160 8.94 - 实际意义:该方法显著提升了自动钢琴编曲的音乐性和结构合理性,使其主观评价接近人类水平,为社交媒体内容创作、音乐教育辅助等应用提供了更强大的工具。
- 局限性:数据集主要基于流行音乐(J/K-pop),在其他音乐类型上的有效性未经验证;风格控制虽然引入,但仅以三个离散等级(低、中、高)实现,精细度和可控范围有限;论文未公开模型权重。
🏗️ 模型架构
Etude的整体架构(如图1所示)是一个清晰的三阶段流水线,旨在解耦自动钢琴编曲的复杂性。
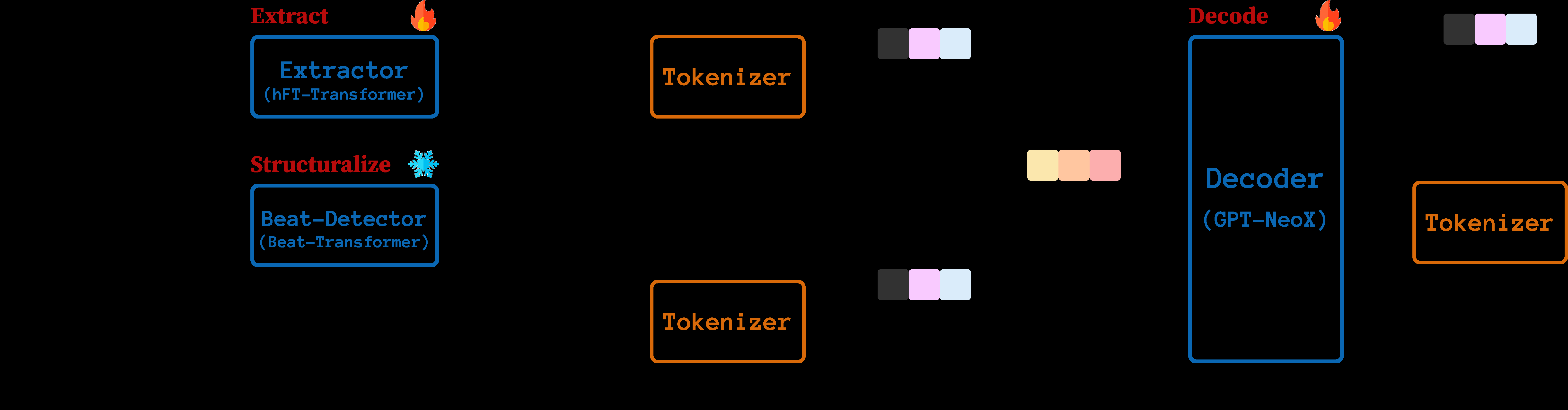
Extract Stage(提取阶段):
- 输入:原始音频。
- 组件:基于AMT-APC(一个微调过的自动音乐转录模型)的特征提取器。
- 功能:克服了早期两阶段模型使用简略领谱表示造成的信息瓶颈。它通过修改损失采样参数(θmatrix),鼓励模型输出一个密集的音乐事件地图(类MIDI特征序列X),而非稀疏的可演奏编排。这为下游的解码器提供了丰富的、未经过滤的源材料。
- 输出:密集的音乐特征序列 X。
Structuralize Stage(结构化阶段):
- 输入:原始音频(与Extract阶段并行处理)。
- 组件:预训练的Beat-Transformer模型。
- 功能:这是保证结构一致性的核心。它精确分析并提取音频中所有拍点(beats)和强拍(downbeats)的时间戳。
- 输出:一个节奏框架 Fbeat,��含了精确的拍号、速度(Tempo)和每小节的边界。这个框架被用作整个流程的“不变真值”,指导符号化数据的标记化与解码时的绝对时间恢复。
Decode Stage(解码阶段):
- 输入:特征序列 X(来自Extract),风格向量(Style Vectors),以及节奏框架 Fbeat(用于标记化)。
- 组件:一个Transformer解码器(采用GPT-NeoX架构)。
- 功能:这是最终的编曲生成器。它被训练来执行以小节为单位的翻译,将源特征 X 转化为目标钢琴序列 Y。训练采用“小节混洗”(bar-wise mix)策略:将每个歌曲的 [X1, Y1, X2, Y2, …] 交错成一条序列,并用Class ID区分。模型在生成第 i 小节的 Y_i 时,可以利用对应的 X_i 以及前四个小节的上下文。
- 可控性:每个小节对 (X_i, Y_i) 关联一组风格向量(相对复调度、相对节奏强度、相对音符延留),这些向量被离散化、嵌入并加到输入中,以控制编曲的织体和表现力。
- 输出:以Tiny-REMI格式标记化的目标钢琴序列 Y。
组件间数据流: 音频 → Extract → 特征序列 X; 音频 → Structuralize → 节奏框架 Fbeat。 X + 风格向量 + (基于Fbeat的标记化) → Decode → 目标序列 Y。 最后,利用Fbeat将Y(相对位置信息)解码回绝对时间的MIDI文件。
💡 核心创新点
- 显式解耦节拍检测与结构框架:这是本文最核心的贡献。之前的方法(如PiCoGen)试图让模型隐式学习节奏结构,效果不佳。Etude引入独立的Beat-Transformer提供精确的Fbeat,将“理解结构”和“生成音符”两个难题分离开,从根本上保证了输出在拍子、小节边界上的一致性。
- 针对任务的极简标记化方案(Tiny-REMI):标准REMI包含和弦、速度等Token。作者认为对于APCG任务,节拍信息已由Fbeat提供,和弦/速度对学习核心的音符排列关系是干扰。因此设计了只包含小节标记、16分音符位置、音高、时值和装饰音的Tiny-REMI,极大简化了序列建模任务。
- 引入可控的风格向量:为了解决“一对多”编曲问题,论文设计了三个相对风格属性(复调密度、节奏活跃度、连贯性)。通过离散化并在小节级别注入,允许用户在一定程度上引导生成的音乐织体和表情,增强了实用性和灵活性。
- 设计新的客观评估指标:提出了WPD(结构相似度)、RGC(节奏网格一致性)、IPE(节奏模式复杂度)三个指标,分别从宏观结构对齐、微观节奏精度和节奏多样性三个维度评估生成质量,补充了单纯依赖主观评估的不足。
🔬 细节详述
- 训练数据:收集了约7,700首流行歌曲与其钢琴伴奏的音频对,主要为J-pop和K-pop。经过长度差和同步质量(WP-std > 1.0)过滤后,使用PiCoGen2的弱对齐方法同步,最终得到4,752对,总时长约500小时。测试集为100首未见过的歌曲,平均分布于华语流行、J-pop、K-pop和西方流行音乐四个类别。
- 损失函数:论文未具体说明Extract阶段损失函数(θmatrix)的具体数学形式和权重设置,仅说明目的是产生密集特征图。对于Decode阶段,论文未明确提及使用的具体损失函数(如交叉熵等)。
- 训练策略:
- Extractor:基于AMT-APC架构,使用一对一的歌曲-伴奏对训练。10个epoch,batch size为2。未提及学习率等细节。
- Decoder:架构为GPT-NeoX,8层Transformer,8个注意力头,隐藏维度512,总参数量约25.5M。序列长度上限1024 tokens。优化器为AdamW,初始学习率2e-4,采用10个epoch的线性预热,之后进行余弦退火。训练100个epoch,batch size为128。
- 关键超参数:风格向量属性(复调、节奏强度、延留)被离散化为3个bin(0, 1, 2)。解码时使用小节混洗策略,上下文窗口大小为前4小节。
- 训练硬件:论文中未提供。
- 推理细节:解码过程是自回归的、以小节为单位的。对于每小节i,Decoder接收特征X_i和风格向量,结合前最多4对(X,Y)上下文,自回归生成Y_i的Token序列,直到遇到小节结束标记(Bar [EOS])。生成的(X_i, Y_i)对随后加入上下文窗口,用于下一小节的生成。
- 正则化技巧:论文未提及Dropout等具体正则化技巧。
📊 实验结果
评估指标:
- 目标指标:WPD(结构偏差,越低越好)、RGC(节奏网格偏差,越低越好)、IPE(节奏模式熵,适中为佳)。
- 主观指标:101名听众(分业余、中级、专家三组)对相似度(SI)、流畅度(FL)、动态表达(DE)、总体评分(OVL)进行1-5分评分。
主要结果(见下表):
| 模型 | WPD ↓ | RGC ↓ | IPE | 主观相似度(SI) ↑ | 主观流畅度(FL) ↑ | 主观动态表达(DE) ↑ | 主观总体分(OVL) ↑ |
|---|---|---|---|---|---|---|---|
| Human | 0.49 | 0.042 | 10.13 | 3.75 ± 1.10 | 4.03 ± 1.02 | 3.79 ± 1.06 | 3.92 ± 0.96 |
| Etude - Default | 0.21 | 0.020 | 9.02 | 3.16 ± 1.07 | 3.73 ± 0.98 | 3.46 ± 1.05 | 3.50 ± 0.99 |
| Etude - Prompted | 0.23 | 0.026 | 9.11 | 3.17 ± 1.10 | 3.70 ± 1.05 | 3.49 ± 1.06 | 3.46 ± 1.00 |
| Etude Extractor | 0.12 | 0.028 | 10.62 | 3.41 ± 1.01 | 3.31 ± 1.13 | 3.35 ± 1.03 | 3.33 ± 1.00 |
| PiCoGen2 [3] | 1.00 | 0.059 | 7.97 | 2.88 ± 1.13 | 3.33 ± 1.12 | 2.73 ± 1.14 | 2.97 ± 1.04 |
| AMT-APC [4] | 0.09 | 0.114 | 10.69 | 2.64 ± 0.99 | 2.37 ± 1.11 | 2.71 ± 1.13 | 2.46 ± 1.04 |
| Music2MIDI [5] | 0.18 | 0.160 | 8.94 | 2.56 ± 1.06 | 2.29 ± 1.13 | 2.24 ± 1.09 | 2.27 ± 1.07 |
关键结论:
- 主观评价:Etude的两个解码器版本(Default和Prompted)在总体分(OVL)、流畅度(FL)、动态表达(DE) 上均显著优于所有基线模型(p<0.001),其中Etude-Default在OVL和FL上取得最高分。这验证了三阶段架构在生成“更自然、更音乐化”输出上的成功。Etude Extractor在相似度(SI) 上最高,证明了其密集特征提取的有效性。
- 客观评价:结果表明人类演奏的指标并非极端值,而是平衡状态。Etude的解码器版本在RGC上取得最低分,说明其生成的节奏极其规整(甚至比人类更“准”)。在WPD上,Etude-Extractor和AMT-APC等转录导向模型分数最低(过于机械地对齐),而Etude解码器版本的分数更接近人类,表明其在结构忠实度与创造性之间取得了更好平衡。在IPE上,Etude版本介于过于单调(PiCoGen2)和过于混沌(AMT-APC)之间,也接近人类水平。
- 消融:Etude-Extractor(仅特征提取)与Etude-Decoder(完整生成)的对比显示,完整的生成流程能显著提升流畅度和总体音乐感,但可能略微牺牲绝对的结构���齐精度。
⚖️ 评分理由
- 学术质量:6.0/7:论文提出一个逻辑严密、针对性强的三阶段框架,有效解决了领域内一个明确的技术痛点。实验设计全面,提出了新的评估指标,并在主观评估上取得了令人信服的结果。主要不足在于,其核心的自回归生成架构并非原创,且评估数据集在音乐风格多样性上存在局限。
- 选题价值:1.0/2:自动钢琴编曲是音乐生成领域一个具体且有实用价值的子任务,论文工作对该垂直领域的技术发展有明确推动作用。但其应用范围和影响力相较于更通用的音频或语音任务较为狭窄。
- 开源与复现加成:0.0/1:论文提供了项目页面链接,声称将开源代码、数据集和音频示例,这是显著的加分项。同时,论文详细给出了模型架构和训练超参数,为复现提供了良好基础。然而,模型权重是否公开未明确,且未提供训练硬件信息,因此给予中性评分0分。