📄 Estimating Hand-Related Features from Speech Using Machine Learning
#语音生物标志物 #传统机器学习 #跨模态
📝 5.0/10 | 前50% | #语音生物标志物 | #传统机器学习 | #跨模态
学术质量 4.5/7 | 选题价值 1.0/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Shraddha Revankar (IIIT Dharwad, 电子与通信工程系)
- 通讯作者:未说明
- 作者列表:Shraddha Revankar (IIIT Dharwad, 电子与通信工程系)、Chinmayananda A (IIIT Dharwad, 电子与通信工程系)、Nataraj K S (IIIT Dharwad, 电子与通信工程系)
💡 毒舌点评
本文提出了一个有趣且未被探索的跨模态关联问题——语音特征能否预测手部解剖特征,这种“不务正业”的探索精神值得肯定,并通过假设检验框架为结论提供了初步统计支持。然而,其主要短板在于“浅尝辄止”:研究仅停留在“是否相关”的层面,使用基础模型在有限数据上验证了关联的存在,却未深入探讨这种关联背后的神经或生理机制,且私有数据集的设置极大限制了其科学价值和可复现性。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:明确说明为私有数据集(“private dataset”),未提供公开获取方式。
- Demo:未提供在线演示。
- 复现材料:给出了RF和FFN模型的详细超参数设置,以及特征提取方法(OpenSMILE eGeMAPS, Librosa, MediaPipe),部分训练细节可复现。但由于核心数据私有,完整复现不可能。
- 论文中引用的开源项目:OpenSMILE [17], Librosa [18], MediaPipe [19]。
- 整体开源情况:论文中未提及开源计划。其核心数据不公开,是复现的主要障碍。
📌 核心摘要
问题:本文旨在探索语音特征与手部人体测量(AM)比例之间是否存在双向的可预测关系,即语音到手部(S2H)和手部到语音(H2S)的跨模态估计。
方法:研究收集了200名受试者的右手图像和语音录音,提取了18种手部AM比例和多种语音特征(如F0、能量、共振峰、抖动、闪烁等)。分别使用随机森林(RF)和前馈神经网络(FFN)模型进行S2H和H2S的回归估计,并采用配对t检验和特征重要性分析来评估结果。
创新:据作者称,这是首次系统性地研究语音特征与手部形态特征(如手指比例、掌宽)之间双向预测关系的工作,为跨模态关联研究开辟了一个新方向。
结果:
S2H方向:中指比例(ml/tl)和无名指比例(rl/tl)在两种模型下均被证明可从语音特征可靠预测;食指比例(il/tl)在RF模型下也可预测。而腕掌宽比例(wp/tl)、腕食指比例(wi/tl)等则难以预测。
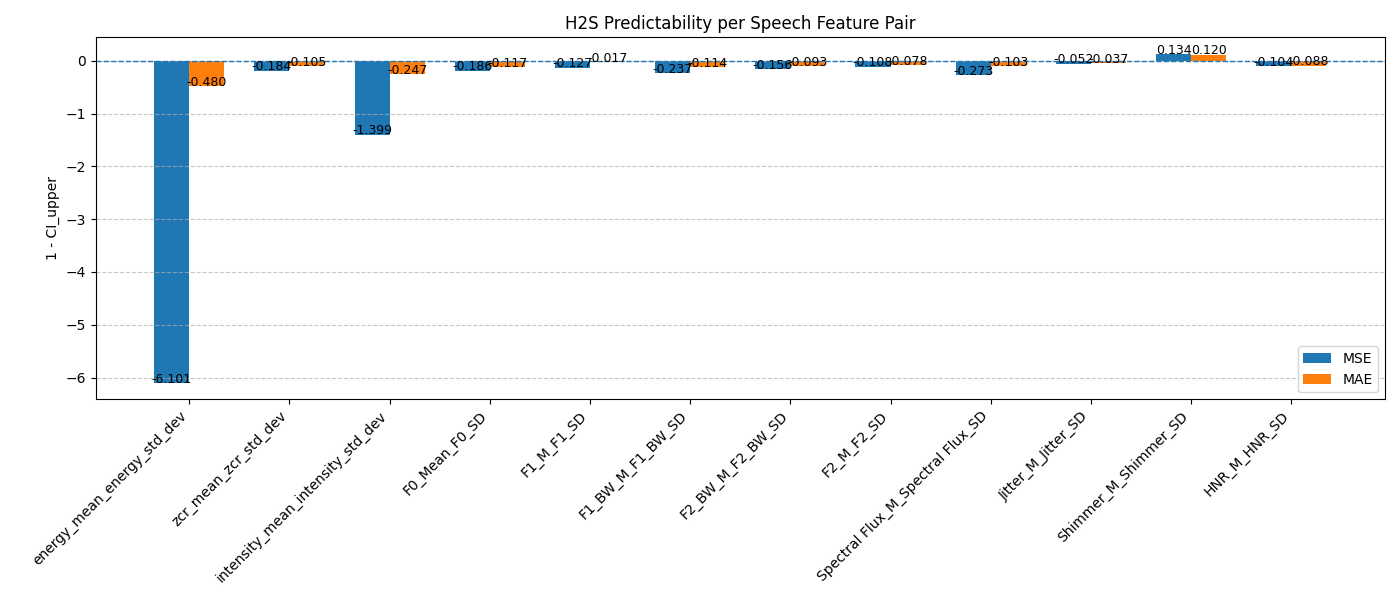
H2S方向:大多数语音特征无法从手部比例可靠预测,唯一例外是闪烁(Shimmer)的均值和标准差,显示出部分可预测性。
关键实验结果表格如下: 表2:S2H估计性能 (RF模型,交叉验证)
AM比率 MAPE(训练集/测试集)% SMAPE(训练集/测试集)% il/tl 3.23 / 9.16 3.20 / 8.97 ml/tl 3.10 / 8.51 3.08 / 8.35 rl/tl 3.32 / 8.98 3.30 / 8.79 ll/tl 3.56 / 9.52 3.53 / 9.34 pw/tl 4.11 / 11.20 4.07 / 11.03 wi/tl 3.61 / 9.50 3.58 / 9.33 wp/tl 3.83 / 10.23 3.79 / 10.05 表3:H2S估计性能 (RF模型,交叉验证)
语音特征 MSE(训练集/测试集) MAE(训练集/测试集) Energy 0.163 / 1.264 0.140 / 0.390 Shimmer 0.109 / 0.775 0.249 / 0.662 HNR (dB) 0.123 / 0.928 0.198 / 0.543 (其他特征结果类似,测试集MSE普遍在0.8-1.2之间)
意义:研究结果表明语音中可能编码了关于手部形态的潜在信息,这为法医学中从语音推断嫌疑人身体特征、神经科学中研究言语与运动控制的关联提供了新的可能性。
局限:研究局限于一个规模较小(200人)、人口学特征特定(印度学生,年龄18-22岁)的私有数据集,模型的泛化能力存疑;研究停留在相关性发现,未提供深入的生物学或神经科学机理解释。
💡 核心创新点
- 首次探索语音与手部形态的双向关联:这是本文最核心的创新。不同于以往语音到人脸(S2F)的研究,本文将语音与另一类具体的解剖特征——手部测量(手指长度、掌宽等比例)联系起来,并验证了双向预测的可能性,开辟了新的跨模态研究方向。
- 提出基于假设检验的评估框架:为证明模型的预测优于简单的基线估计(即训练集平均值),论文采用配对t检验,通过计算损失比率(
L_i / LB_i)的置信区间来判断可预测性。这为评估跨模态估计的有效性提供了一种统计严谨的方法,如图3和图4所示。
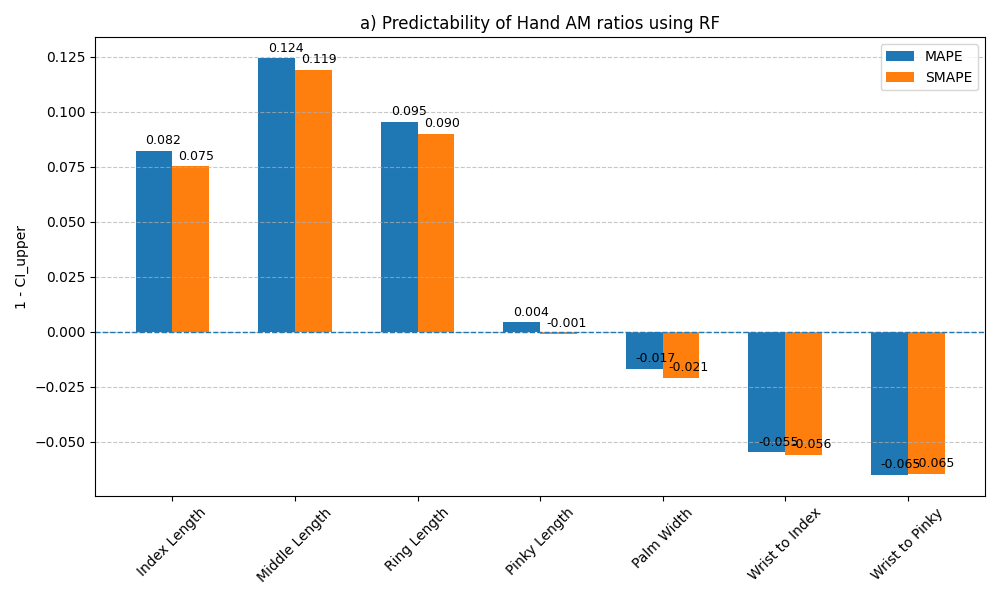
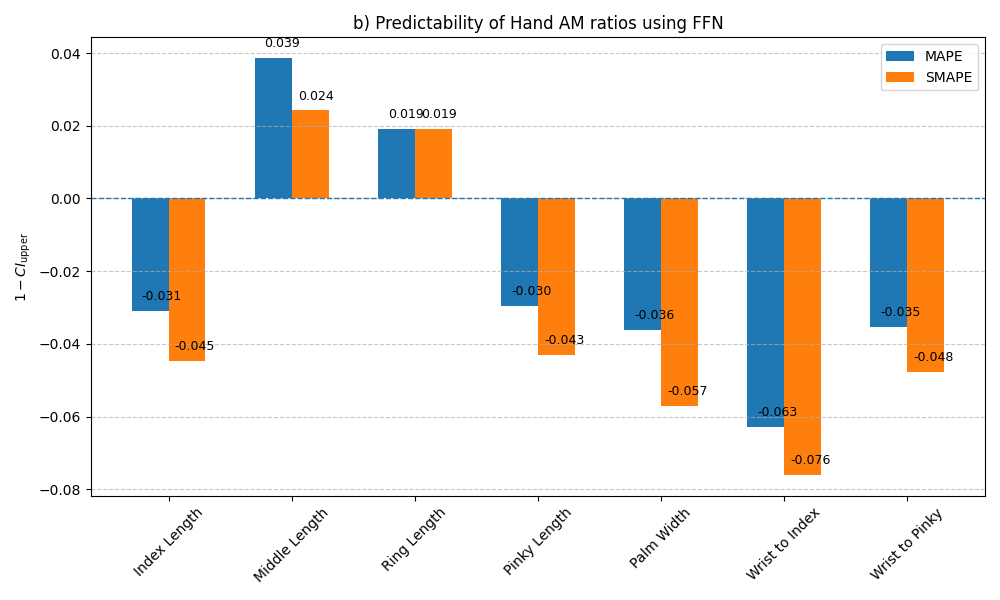
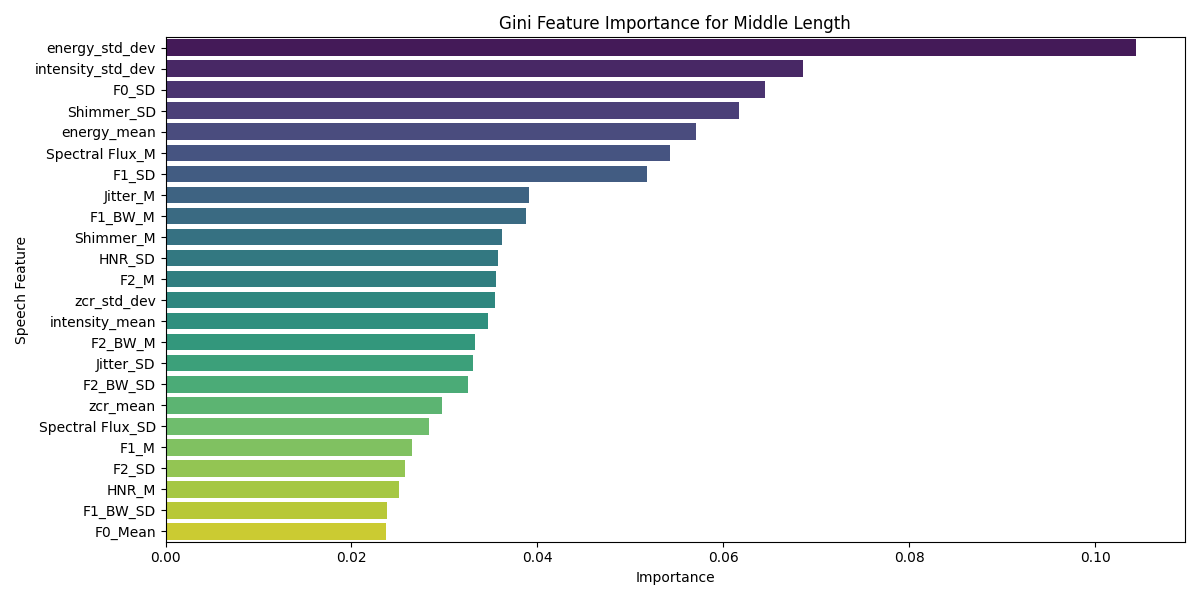
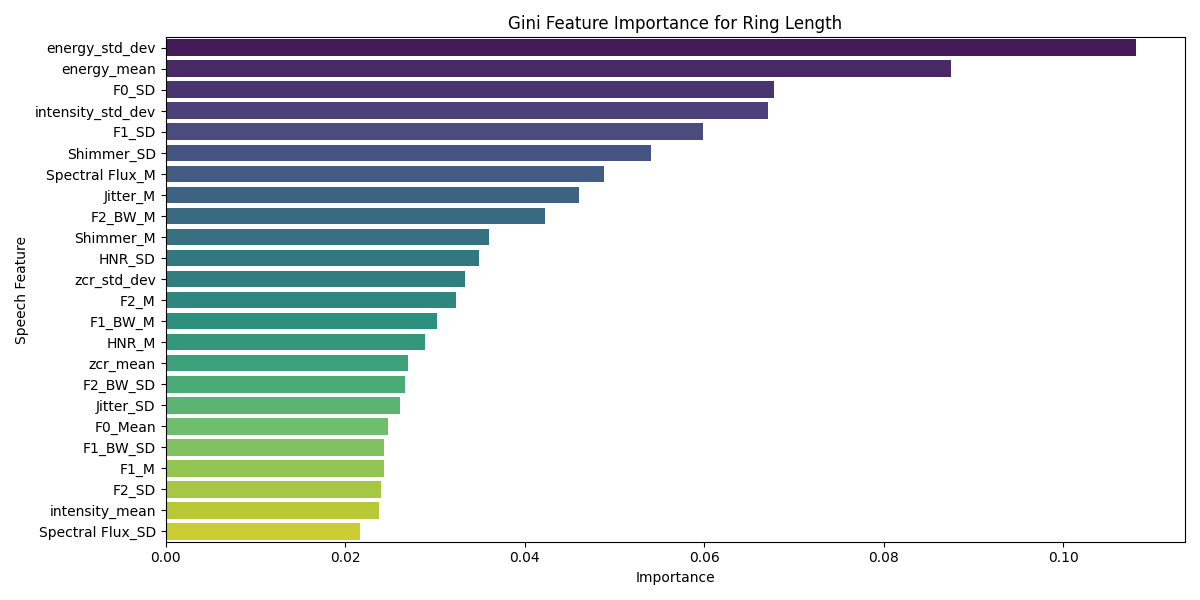
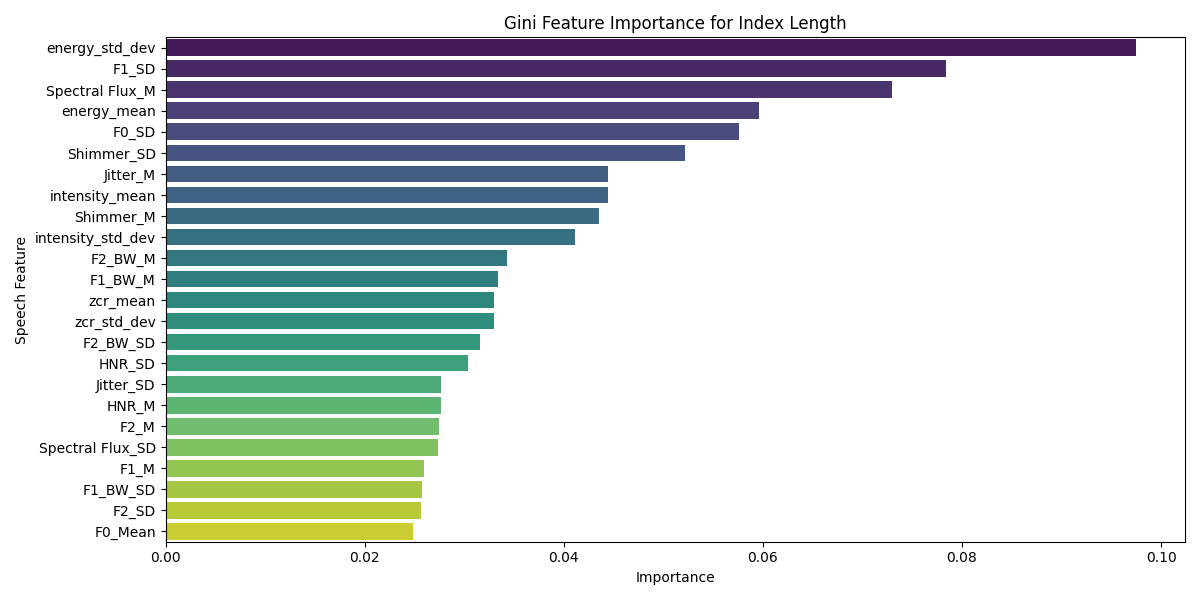
- 特征重要性分析揭示关键关联:通过RF模型的Gini指数分析,论文指出能量的变异性和闪烁(Shimmer)的变异性是预测手部AM比率(特别是中间三指比例)最重要的语音特征,为理解这种跨模态关联提供了具体线索。如图5、6、7所示。
🔬 细节详述
- 训练数据:
- 数据集:私有数据集,包含200名受试者(165男,35女)的右手手掌图像和语音录音。
- 来源:在IIIT Dharwad采集。受试者为18-22岁的学生,来自印度多个邦(如安得拉邦60人,马哈拉施特拉邦55人,卡纳塔克邦45人等)。
- 语音:在安静环境下,就随机主题用英语、印地语或卡纳达语说话25-30秒,采样率48kHz。
- 图像:使用手机在固定高度拍摄的右手手掌图像。
- 预处理:使用MediaPipe提取21个手部关键点,计算18个AM比率。语音特征使用OpenSMILE(eGeMAPS)和Librosa提取,包含F0、频谱通量、抖动、闪烁、HNR、共振峰等,并取其均值和标准差。所有特征进行均值-方差归一化。
- 损失函数:
- S2H:评估指标为对称平均绝对百分比误差(SMAPE)和平均绝对百分比误差(MAPE)。
- H2S:评估指标为均方误差(MSE)和平均绝对误差(MAE)。
- 模型训练本身使用标准的回归损失(如RF的
criterion=squared_error, FFN未明确但通常为MSE)。
- 训练策略:
- 使用5折交叉验证(RF)或固定训练/测试划分进行评估。
- RF超参数:
n_estimators=100,random_state=42,criterion='squared_error',min_samples_split=2,min_samples_leaf=1,max_features='sqrt',bootstrap=True。 - FFN超参数:三个隐藏层(128, 64, 32),ReLU激活,Adam优化器,学习率
10^-3,batch size 32,训练50个epoch。
- 关键超参数:未提供模型规模(参数量)信息。
- 训练硬件:未说明。
- 推理细节:不适用,本文为回归预测任务,未涉及生成或序列解码。
- 正则化:未特别提及,但RF和FFN的超参数设置(如
min_samples_leaf)隐含了正则化。
📊 实验结果
论文主要报告了两个方向回归任务的性能,并辅以假设检验和特征重要性分析。
- S2H结果:如表2所示,对于可预测的AM比率(如ml/tl),在测试集上的SMAPE约为8.35%。假设检验结果(图3)显示,
1-CIupper为正的比率(如ml/tl, rl/tl)在统计上显著优于基线,即可靠可预测。 - H2S结果:如表3所示,大多数语音特征的测试集MSE在0.8到1.3之间,MAE在0.6到0.9之间。假设检验结果(图4)显示,除了闪烁(Shimmer)的均值和标准差外,其他特征的
1-CIupper值为负,表明预测性能与基线无显著差异或更差。 - 关键消融/分析:论文没有进行模型复杂度的消融实验。核心分析在于通过假设检验区分“可预测”与“不可预测”的特征。
- 结果图表:图3和图4是关键结果图,分别总结了S2H和H2S方向各特征/比率的可预测性统计证据。图5、6、7是具体模型(RF)的特征重要性示例。
⚖️ 评分理由
- 学术质量:4.5/7:研究问题新颖,实验设计包含统计检验,结果有一定说服力。但模型方法(RF/FFN)过于基础,缺乏深度学习模型的探索;数据集规模小且受限;最重要的是,论文未能深入解释“为何”会存在这些关联,停留在统计现象描述层面,学术深度有限。
- 选题价值:1.0/2:选题角度独特,具有跨学科潜力。但应用范围非常小众(主要为法医和基础研究),对当前主流语音处理技术(如识别、合成)无直接贡献,读者相关性低。
- 开源与复现加成:-0.5/1:明确说明使用私有数据集且未提供获取途径,也未提供代码。这严重限制了研究的可复现性和社区验证价值,因此给予扣分。