📄 Enhancing Speech Intelligibility Prediction for Hearing Aids with Complementary Speech Foundation Model Representations
#语音增强 #预训练 #多任务学习 #模型评估
✅ 7.5/10 | 前25% | #语音增强 | #预训练 | #多任务学习 #模型评估
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Guojian Lin(南方科技大学)
- 通讯作者:Fei Chen(南方科技大学)
- 作者列表:Guojian Lin(南方科技大学),Xuefei Wang(南方科技大学),Ryandhimas E. Zezario(中央研究院),Fei Chen(南方科技大学)
💡 毒舌点评
本文的亮点在于系统性地验证了“特征级融合”优于“模型集成”这一策略,并通过消融实验清晰地展示了Whisper与WavLM特征在分布上的互补性。然而,该模型直接堆叠两个巨大的预训练模型(Whisper-Large v3 和 WavLM-Large),其计算复杂度和实际部署在助听器等边缘设备上的可行性,在论文中被完全忽视,这使得其实用价值大打折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开的ECR-SIPNet模型权重。
- 数据集:使用公开的CPC2数据集,但论文未说明其获取方式(通常需通过挑战赛官网获取)。
- Demo:未提供在线演示。
- 复现材料:论文给出了一定的训练细节(优化器、学习率、epoch数、输入预处理),但缺少关键超参数(如学习率调度、具体dropout比例、batch size)和硬件信息,复现信息不够充分。
- 论文中引用的开源项目:明确使用了预训练模型Whisper和WavLM。
📌 核心摘要
- 要解决什么问题:现有用于助听器(HA)的语音清晰度预测(SIP)模型大多依赖单一类型的基础模型表示(如仅用Whisper或WavLM),无法全面捕捉影响清晰度的多维度信息(如语义与声学噪声),从而限制了预测精度。
- 方法核心是什么:提出ECR-SIPNet模型,其核心是“特征级融合”策略。它将预训练Whisper(侧重语义)和WavLM(侧重声学与噪声鲁棒性)的嵌入表示,通过全连接层统一维度后,在特征维度上进行拼接,形成互补的特征表示,再输入到由双向长短期记忆网络(Bi-LSTM)和多头注意力机制构成的预测头中,进行帧级分数预测并平均得到最终清晰度分数。
- 与已有方法相比新在哪里:区别于先前通过集成学习(Ensemble)聚合不同模型预测结果的方法,本文首次探索并证明了在特征层面融合不同语音基础模型(SFM)的表示,能够更有效地学习跨模型的互补信息,从而提升预测性能。
- 主要实验结果如何:在Clarity Prediction Challenge 2(CPC2)数据集上,ECR-SIPNet显著超越了之前的SOTA系统。关键指标对比见下表:
| 系统 | RMSE (↓) | PCC (↑) |
|---|---|---|
| MBI-Net+ with FiDo [16] (先前SOTA) | 24.1 | 0.80 |
| ECR-SIPNet (本文方法) | 23.1 | 0.82 |
消融实验表明,特征维度拼接(Dim-Concat)的效果优于单特征模型(Whisper或WavLM)以及简单的预测结果平均或加权平均集成方法。
- 实际意义是什么:提高了助听器语音清晰度预测的准确性,这对于优化助听器算法、个性化验配以及语音质量评估具有直接的工程价值。同时,该研究为如何有效融合多个预训练模型的知识提供了方法论上的参考。
- 主要局限性是什么:模型由两个参数量巨大的基础模型驱动,计算开销高,难以满足助听器设备的实时、低功耗部署需求。此外,模型仅在CPC2这一个数据集上验证,其泛化能力未在其他场景或数据集上得到证明。
🏗️ 模型架构
模型整体架构如图1所示,可分为两个主要模块:
- 特征提取与融合模块:
- 输入:双通道(左、右声道)的语音波形,统一重采样至16kHz并零填充至9秒。
- 处理流程: a. 每个声道的语音分别通过预训练的 Whisper-Large v3 和 WavLM-Large 模型,提取其最后一个隐藏层的嵌入表示。Whisper输出维度为1280,WavLM输出维度为1024。 b. 通过两个独立的全连接层,将Whisper和WavLM的嵌入投影到统一的特征维度(论文中未明确指出最终统一维度,但下文提及投影到128维,存在矛盾,此处以“统一维度”概括)。 c. 将投影后的两个表示在特征维度上进行拼接(Dim-Concat),形成融合表示。 d. 将融合表示输入一个隐藏层大小为128的双向LSTM(Bi-LSTM),以建模帧级时序信息。 e. 通过一个全连接层将维度映射到128,随后进行dropout以防止过拟合。 f. 分别处理左右声道后,将两个声道的输出表示再次在特征维度上拼接。
- 预测头模块:
- 输入:拼接后的双声道特征表示。
- 处理流程: a. 通过一个具有8个注意力头的多头注意力(MHA)层,捕捉全局上下文关系。 b. 通过一个全连接层(输入128维,输出1维),将特征映射为帧级清晰度分数。 c. 沿帧级维度进行平均池化,得到最终的句子级语音清晰度预测分数。
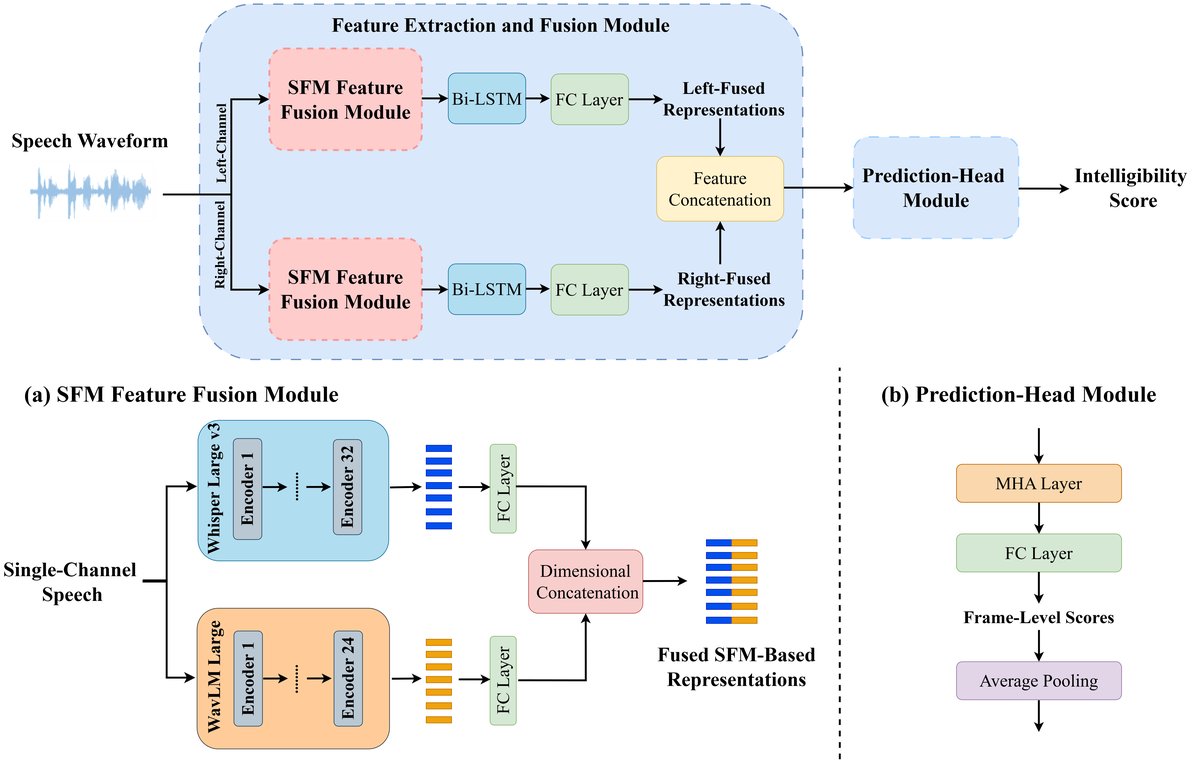 (图1展示了特征提取与融合模块(a)以及预测头模块(b)的详细结构,清晰地描绘了从双SFM特征提取、维度统一、拼接、Bi-LSTM处理到多头注意力预测的全过程。)
(图1展示了特征提取与融合模块(a)以及预测头模块(b)的详细结构,清晰地描绘了从双SFM特征提取、维度统一、拼接、Bi-LSTM处理到多头注意力预测的全过程。)
💡 核心创新点
- 特征级互补融合策略:首次提出并系统验证了在助听器语音清晰度预测任务中,将Whisper(全局语义信息)和WavLM(声学/噪声鲁棒性信息)的特征在特征维度拼接,比简单的模型集成(如预测分数平均)能更有效地利用互补信息,带来显著的性能提升(RMSE从23.5降至23.1)。
- 互补性分析与可视化:通过可视化(图2)和定量消融实验,明确证实了Whisper和WavLM的表示在特征分布上存在差异和互补性。WavLM在捕捉低级声学特征(如说话人音色、环境噪声)上更具优势,而Whisper则富含高级语义信息。
- 针对性的预测头设计:设计了一个结合Bi-LSTM(建模局部时序依赖)和多头注意力机制(建模全局上下文)的预测头,专门用于处理融合后的高维特征,并采用包含帧级和句子级的联合损失函数进行监督训练。
🔬 细节详述
- 训练数据:使用CPC2数据集,包含由20种不同助听器算法处理过的语音和听力受损听众的主观清晰度评分。数据集分为三个子集(Set 1, Set 2, Set 3),每个子集的训练集由CEC1.train和CEC2.train合并而成,并按90%/10%划分训练集和验证集。
- 损失函数:如公式(1)所示,是句子级MSE损失与帧级MSE损失的加权和。αI 控制帧级损失的权重。
LSI = (1/N) Σ [ (In - În)^2 + αI (1/Fu) * Σ (In - înl)^2 ]其中In是真实值,În是句子级预测,înl是第l帧的预测,Fu是总帧数。 - 训练策略:使用Adam优化器,学习率1e-4,训练50个epoch。
- 关键超参数:Whisper chunk size: 9秒;Bi-LSTM hidden size: 128;多头注意力头数: 8;dropout层存在但未说明具体比率。
- 训练硬件:论文中未提及。
- 推理细节:评估阶段不进行零填充。使用RMSE和PCC作为评估指标。
📊 实验结果
主要性能对比(表2):
| System | RMSE | PCC |
|---|---|---|
| BeHASPI [2] | 28.7 | 0.70 |
| MBI-Net+ [12] | 26.1 | 0.76 |
| E002 [13] | 25.3 | 0.77 |
| E011 [14] | 25.1 | 0.78 |
| MBI-Net+ with FiDo [16] | 24.1 | 0.80 |
| ECR-SIPNet | 23.1 | 0.82 |
在各测试子集上的细分结果(表3):
| Test Set | Model | RMSE | PCC |
|---|---|---|---|
| Test.1 | MBI-Net+ with FiDo | 26.7 | 0.75 |
| ECR-SIPNet | 26.2 | 0.76 | |
| Test.2 | MBI-Net+ with FiDo | 23.9 | 0.79 |
| ECR-SIPNet | 22.8 | 0.81 | |
| Test.3 | MBI-Net+ with FiDo | 21.4 | 0.85 |
| ECR-SIPNet | 19.8 | 0.87 | |
| All | MBI-Net+ with FiDo | 24.1 | 0.80 |
| ECR-SIPNet | 23.1 | 0.82 |
关键消融实验(表4):
| Method | Model | RMSE | PCC |
|---|---|---|---|
| 单特征模型 | ECR-SIPNet (WavLM) | 24.4 | 0.79 |
| ECR-SIPNet (Whisper) | 23.9 | 0.80 | |
| 集成方法 | ECR-SIPNet (Average) | 23.6 | 0.81 |
| ECR-SIPNet (Weighted Average) | 23.5 | 0.81 | |
| 特征融合 | ECR-SIPNet (Temp-Concat) | 24.0 | 0.80 |
| ECR-SIPNet (Dim-Concat) | 23.1 | 0.82 |
关键结论:
- ECR-SIPNet在所有测试子集及完整测试集上均显著优于先前SOTA(MBI-Net+ with FiDo)。
- 特征维度拼接(Dim-Concat)的效果最好,优于时间维度拼接(Temp-Concat),后者几乎没有提升。
- 特征级融合(Dim-Concat)的效果优于模型集成方法(Average, Weighted Average),证明了特征层面学习互补信息的有效性。
图表分析:
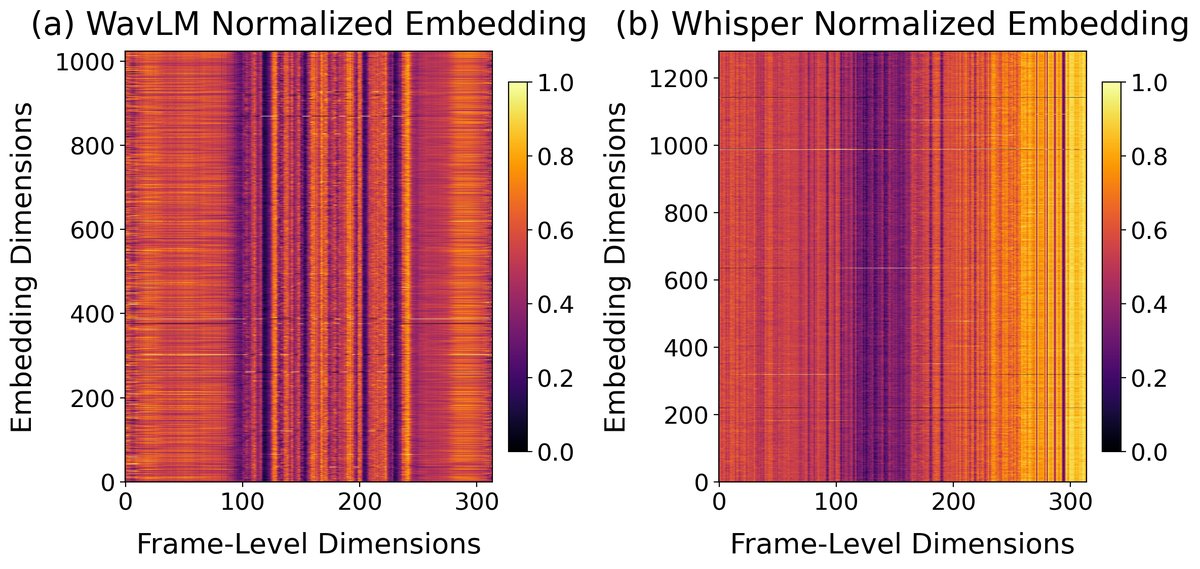 (图2通过可视化展示了同一语音波形下,WavLM和Whisper嵌入在特征维度上的分布模式差异。WavLM(左)在中心区域变化剧烈,边缘均匀,符合其捕捉声学细节的特性;Whisper(右)则呈现更复杂的高低值分布,反映其丰富的语义信息。这从数据分布角度支持了特征互补的假设。)
(图2通过可视化展示了同一语音波形下,WavLM和Whisper嵌入在特征维度上的分布模式差异。WavLM(左)在中心区域变化剧烈,边缘均匀,符合其捕捉声学细节的特性;Whisper(右)则呈现更复杂的高低值分布,反映其丰富的语义信息。这从数据分布角度支持了特征互补的假设。)
⚖️ 评分理由
- 学术质量:6.0/7:论文动机明确,方法设计合理,有系统的消融实验支持其核心主张(特征级融合优于模型集成)。技术上正确,实验结果显著。扣分点在于:1)对模型计算复杂度、实时性等工程实现关键问题完全未讨论;2)验证数据集单一,泛化性存疑;3)模型架构相对简单,创新性不算突破性。
- 选题价值:1.5/2:语音清晰度预测是助听器领域的核心问题,有明确的现实应用需求和价值。虽然这是一个相对垂直、小众的领域,但本文提出的融合策略对相关任务(如语音质量评估)有借鉴意义。
- 开源与复现加成:0.0/1:论文未提供代码、模型权重或详细的训练配置(如学习率调度、具体dropout率等),复现依赖于对两个大型预训练模型的使用,但论文本身并未开源其具体实施,复现成本较高。