📄 Enhancing Speaker Verification with w2v-BERT 2.0 and Knowledge Distillation Guided Structured Pruning
#说话人验证 #预训练 #知识蒸馏 #模型压缩 #语音大模型
✅ 7.5/10 | 前25% | #说话人验证 | #知识蒸馏 | #预训练 #模型压缩
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Ze Li(武汉大学计算机科学学院, 苏州多模态智能系统市重点实验室)
- 通讯作者:Ming Li(武汉大学人工智能学院, 昆山杜克大学, 苏州多模态智能系统市重点实验室)
- 作者列表:Ze Li(武汉大学计算机科学学院, 苏州多模态智能系统市重点实验室)、Ming Cheng(武汉大学计算机科学学院, 苏州多模态智能系统市重点实验室)、Ming Li(武汉大学人工智能学院, 昆山杜克大学, 苏州多模态智能系统市重点实验室)
💡 毒舌点评
这篇论文是一次漂亮的大模型“落地”工程实践,成功地将w2v-BERT 2.0这个语言学预训练巨兽改造为说话人验证的利器,并达到了SOTA性能,同时不忘通过剪枝为实际部署铺路,展现了完整的研究闭环。然而,其核心创新更偏向于“技术选型与系统集成”的优秀范例,而非底层算法的突破,更像是用现有最好的工具(MFA, LoRA, 结构化剪枝)精心组装了一台高性能机器,虽然结果亮眼,但缺少让同行惊呼“原来可以这样”的独创性构思。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/ZXHY-82/w2v-BERT-2.0_SV。
- 模型权重:论文中未明确提及是否公开预训练或微调后的模型权重。
- 数据集:实验所用数据集(VoxCeleb, VoxBlink2, CN-Celeb, MUSAN, RIR Noise)均为公开数据集,但论文未提供数据集的获取指南或处理脚本。
- Demo:未提及在线演示。
- 复现材料:论文给出了详细的模型架构描述(包括各模块维度)、三阶段训练策略(含学习率、优化器、调度器、损失函数参数)、剪枝细节(损失函数、L0建模参数)等,为复现提供了核心框架。部分训练超参数(如batch size)和硬件信息缺失。
- 引用的开源项目:论文中引用的开源项目包括ECAPA-TDNN、MFA-Conformer、LoRA等,表明其实验���于这些公开的架构和代码思想。
📌 核心摘要
- 问题:现有说话人验证(SV)系统面临标注数据不足与模型复杂度之间的矛盾,且大规模预训练模型(PTM)的参数量过大,不利于实际部署。
- 核心方法:首次将基于Conformer架构、在4.5百万小时多语言数据上自监督训练的w2v-BERT 2.0 PTM用于SV任务。采用多尺度特征聚合(MFA)结构结合Layer Adapter处理PTM多层输出,并使用LoRA进行高效微调。为降低部署成本,应用知识蒸馏指导的结构化剪枝技术压缩PTM。
- 创新点:将w2v-BERT 2.0引入SV;提出“MFA + Layer Adapter + LoRA”的高效适配框架;实现了基于知识蒸馏的结构化剪枝,大幅压缩模型且性能损失极小。
- 主要结果:在Vox1-O测试集上达到0.12% EER,在Vox1-H上达到0.55% EER,超越了表1中列出的多种前沿方法。通过剪枝将模型参数减少约80%,在Vox1-O上的EER仅从0.14%增加至0.18%,性能退化仅0.04%。
- 实际意义:为使用超大型预训练模型解决SV问题提供了有效方案,并展示了如何将模型压缩至实际可用的规模,平衡了性能与效率。
- 局限性:尽管性能优越,但模型初始参数量巨大(约580M),剪枝后的模型(124M)依然较传统SV模型庞大。研究未深入探讨w2v-BERT 2.0中Conformer架构相比Transformer在SV任务上的具体优势机制,且未提供在其他更具挑战性场景(如极端噪声、跨语言)下的全面评估。
🏗️ 模型架构
论文的整体架构旨在将大规模预训练模型w2v-BERT 2.0适配到说话人验证任务,其核心流程如下:
- 特征提取与PTM编码:输入语音信号首先提取80维FBank特征,然后输入到冻结的w2v-BERT 2.0编码器中。该编码器包含24个Conformer层,输出每一层的特征表示
[h0, h1, ..., hL],其中hi是维度为D×T的帧级特征。 - 说话人嵌入提取(四种方案):
- Layer-wise Weighted Average:为每一层特征学习一个权重
wi,通过加权平均融合所有层输出,得到一个单一帧级特征H,再输入到ECAPA-TDNN中提取说话人嵌入。 - MFA (Multi-scale Feature Aggregation):将所有层的特征在维度上拼接,然后直接输入到注意力统计池化(ASP)模块,再通过线性层输出说话人嵌入
E。这种方法保留了所有层的信息。 - MFA + Layer Adapter:在MFA的基础上,在拼接前为每一层的输出
hi引入一个轻量级的Layer Adapter模块。该模块由两个线性层、层归一化和ReLU激活函数组成,先将特征从维度d投影到d‘,再映射回d‘,旨在将PTM的原始特征适配到SV任务域。 - LoRA + Layer Adapter + MFA:在上述架构基础上,进一步对PTM中每个Conformer层自注意力模块的查询(Query)和值(Value)权重矩阵应用低秩适应(LoRA)。LoRA通过注入可训练的低秩矩阵
A和B来更新原始权重W,在微调时只需训练这些少量新增参数。
- Layer-wise Weighted Average:为每一层特征学习一个权重
- 模型压缩:为部署需要,对上述微调后的PTM部分(不包括Layer Adapter等下游模块)进行知识蒸馏指导的结构化剪枝。采用教师-学生框架,教师模型为未剪枝的PTM,学生模型为目标剪枝模型。通过联合优化蒸馏损失(L1损失与余弦距离的加权和)和L0正则化项(通过Hard Concrete分布建模),对FFN中间维度、卷积通道数和注意力头数进行结构化稀疏化,以实现模型压缩。
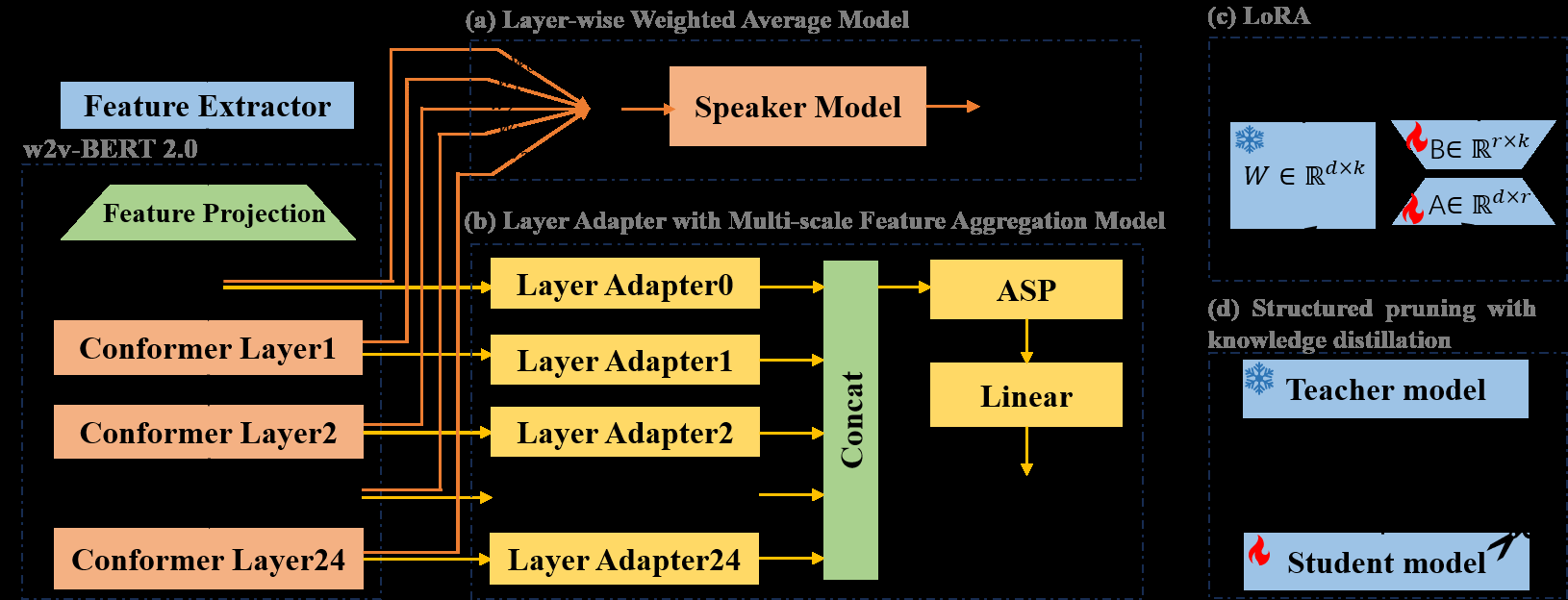
图1展示了整个系统的模块化架构。左侧(a)部分显示了MFA结构(或带Layer Adapter)的工作流程:w2v-BERT 2.0的多层输出经过适配(如Layer Adapter)后拼接,通过ASP和线性层得到说话人嵌入。右侧(b)部分展示了基于知识蒸馏的结构化剪枝流程:冻结的教师模型(原始w2v-BERT 2.0)指导可剪枝的学生模型,通过L0正则化和蒸馏损失联合优化,实现对模型结构(如FFN、卷积、注意力头)的稀疏化。
💡 核心创新点
- 将w2v-BERT 2.0引入说话人验证:w2v-BERT 2.0是一个基于Conformer架构、在超大规模多语言数据上联合优化对比学习与掩码预测的预训练模型。本文是首次将其应用于SV任务,并取得了SOTA性能,证明了该模型在说话人表征方面的强大潜力。
- 高效的模型适配框架(MFA + Layer Adapter + LoRA):针对PTM多层特征融合,采用了保留信息更全的MFA拼接策略,并引入轻量级Layer Adapter进行层间适配。同时,结合LoRA对PTM进行参数高效微调。该框架在保持高性能的同时,显著减少了可训练参数量(从65.6M降至6.2M或12.5M),并缓解了在大数据集上全参数微调的过拟合风险。
- 知识蒸馏指导的结构化剪枝:为解决大模型部署难题,采用了一种基于L0正则化和Hard Concrete分布的结构化剪枝方法,并在蒸馏损失的引导下进行。该方法能够精确控制FFN、卷积、注意力头等结构化组件的稀疏度,实现了在模型体积减少约80%的情况下,性能退化极小(仅0.04% EER)。
🔬 细节详述
- 训练数据:主要使用VoxCeleb2开发集和VoxBlink2数据集进行训练。评估使用VoxCeleb1的开发集和测试集(Vox1-O, Vox1-E, Vox1-H)。此外,还使用了CN-Celeb1&2的开发集进行跨语言/场景验证。
- 数据增强:在PTM冻结训练阶段,使用了在线数据增强,包括添加背景噪声(MUSAN数据集)和混响噪声(RIR Noise数据集),以及语速扰动(0.9x和1.1x)。在联合微调和大间距微调阶段停止了数据增强。
- 损失函数:下游说话人分类使用ArcFace损失,其在冻结训练阶段的margin和scale分别为0.2和32;在大间距微调阶段,margin增加到0.5。剪枝的蒸馏损失
L_distill结合了L1距离和余弦距离(权重相等)。 - 训练策略:分为三个阶段:1) PTM冻结训练:仅训练下游模块(如Layer Adapter, ASP等)。使用AdamW优化器,初始学习率1e-4,StepLR调度(每5轮衰减0.1至1e-5)。2) 联合微调:解冻整个PTM,学习率从1e-5余弦衰减到5e-6,共4个epoch。3) 大间距微调与评分校准:仅使用VoxCeleb2数据,采用大margin的ArcFace进行2个epoch微调,学习率从1e-5余弦衰减到5e-6。最后使用AS-norm和QMF进行评分校准。
- 关键超参数:w2v-BERT 2.0有24层Conformer,隐藏维度D未明确说明,但根据描述规模庞大。Layer Adapter的隐藏维度
d‘设为128。LoRA的秩r设为64,缩放因子α设为128。剪枝的目标稀疏度t约为80%。 - 训练硬件:论文未明确说明使用的GPU型号、数量及训练时长。仅提到由“Advanced Computing East China Sub-Center”提供计算资源。
- 推理细节:未详细说明解码策略等,但提到了输入帧长在训练不同阶段有变化(200-300帧,或500-600帧)。评估时使用了得分校准。
- 正则化技巧:除了数据增强,还使用了权重衰减(1e-4)、线性预热(5个epoch)等稳定训练的技巧。
📊 实验结果
主要基准与对比:论文在VoxCeleb1标准测试集(Vox1-O, Vox1-E, Vox1-H)和CN-Celeb测试集上评估了模型性能,主要指标为等错误率(EER)和最小检测成本函数(mDCF)。
表1:w2v-BERT 2.0说话人验证模型与其他模型的性能对比
| Frontend Model | Params | LMFT | Score Calibration | Vox1-O EER(%) | Vox1-O mDCF | Vox1-E EER(%) | Vox1-H EER(%) | CN-Celeb Test EER(%) |
|---|---|---|---|---|---|---|---|---|
| ECAPA-TDNN(C=1024) | 14.7M | × | × | 0.87 | 0.107 | 1.12 | 2.12 | - |
| CAM++ | 7.2M | × | × | 0.73 | 0.091 | 0.89 | 1.76 | 6.78 |
| ReDimNet-B6 | 15.0M | ✓ | ✓ | 0.37 | 0.030 | 0.53 | 1.00 | - |
| ResNet293 | 98.9M | ✓ | ✓ | 0.17 | 0.006 | 0.37 | 0.68 | - |
| HuBERT Large + ECAPA-TDNN | 317+8.8M | ✓ | ✓ | 0.59 | - | 0.65 | 1.23 | - |
| WavLM Large + ECAPA-TDNN | 317+8.8M | ✓ | ✓ | 0.38 | - | 0.48 | 0.99 | - |
| LAP+ASTP | 317+2.3M | ✓ | ✓ | 0.37 | 0.059 | 0.50 | 1.01 | - |
| LoRA Adapter MFA (本文) | 580+6.2M | ✓ | ✓ | 0.12 | 0.025 | 0.27 | 0.55 | - |
| LoRA Adapter MFA (本文, CN-Celeb训练) | 580+6.2M | - | - | - | - | - | - | 4.67 |
注:带的结果使用了VoxCeleb2和VoxBlink2数据训练。本文模型取得了最佳性能。*
表2:不同w2v-BERT 2.0模型架构的性能对比(Vox1-O EER)
| 模型 | 训练数据 | 可训练参数 | Vox1-O EER |
|---|---|---|---|
| ECAPA-TDNN (冻结PTM) | - | 580+8.8M | 0.49% |
| + 联合微调 + LMFT | VoxCeleb2 | 580+8.8M | 0.22% |
| MFA (冻结PTM) | - | 580+65.6M | 0.46% |
| + 联合微调 + LMFT | VoxCeleb2 | 580+65.6M | 0.26% |
| Adapter MFA (冻结PTM) | - | 580+6.2M | 0.43% |
| + 联合微调 + LMFT | VoxCeleb2 | 580+6.2M | 0.18% |
| LoRA Adapter MFA (冻结PTM) | VoxCeleb2 & VoxBlink2 | 580+12.5M | 0.27% |
| + 联合微调 (LoRA merge) + LMFT | VoxCeleb2 & VoxBlink2 | 580+6.2M | 0.14% |
消融实验表明,引入Layer Adapter和LoRA能显著降低参数量并提升性能。
表3:知识蒸馏引导的结构化��枝结果(基于VoxCeleb2和VoxBlink2训练的模型)
| 模型 | 稀疏度 | 参数 | MACs (1s) | FLOPs (1s) | LMFT | Vox1-O EER |
|---|---|---|---|---|---|---|
| LoRA Adapter MFA | 0% | 580+6.2M | 28.75G | 57.72G | × | 0.23% |
| ✓ | 0.14% | |||||
| 剪枝后模型 | ≈80% | 124+6.2M | 6.31G | 12.75G | × | 0.35% |
| ✓ | 0.18% |
剪枝后模型参数减少约80%,计算量(MACs/FLOPs)减少约78%,经LMFT后EER仅从0.14%退化到0.18%。
关键结论:
- w2v-BERT 2.0为SV任务提供了极强的表征基座,即使简单MFA也能达到0.26% EER。
- “Layer Adapter + MFA”比“Layer-wise Weighted Average”更能保留信息,效果更好。
- LoRA在融合大规模外部数据(VoxBlink2)训练时,能有效提升微调效率和性能,并缓解过拟合。
- 所提方法在多个测试集上达到了SOTA水平。
- 结构化剪枝在大幅降低模型复杂度的同时,保持了优异的性能。
⚖️ 评分理由
- 学术质量:5.5/7:论文工作完整,从模型选择、适配、微调到压缩形成了一个清晰的pipeline。实验设计严谨,有充分的消融实验和基线对比,结果可信度高。创新性主要体现在对最新大模型的成功应用和系统级优化上,而非提出新的理论或算法,属于扎实的工程与应用创新。
- 选题价值:1.5/2:研究如何利用大模型提升经典任务(说话人验证)的性能,并解决其部署瓶颈(模型压缩),课题具有明确的实用导向和前沿性。对于语音处理社区,探索不同大模型在下游任务中的适配方法具有参考价值。
- 开源与复现加成:0.5/1:论文提供了明确的代码仓库链接,这是巨大的加分项。论文中描述了训练三阶段、主要超参数和剪枝框架,但诸如具体的batch size、完整的学习率曲线、硬件配置等细节未完全披露,可能影响完全复现的效率。