📄 Enhancing Noise Robustness for Neural Speech Codecs Through Resource-Efficient Progressive Quantization Perturbation Simulation
#语音增强 #鲁棒性 #数据增强 #自监督学习
✅ 7.5/10 | 前25% | #语音增强 | #数据增强 | #鲁棒性 #自监督学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Rui-Chen Zheng(中国科学技术大学语音及语言信息处理国家工程研究中心)
- 通讯作者:Yang Ai*(中国科学技术大学语音及语言信息处理国家工程研究中心)
- 作者列表:Rui-Chen Zheng(中国科学技术大学语音及语言信息处理国家工程研究中心)、Yang Ai(中国科学技术大学语音及语言信息处理国家工程研究中心)、Hui-Peng Du(中国科学技术大学语音及语言信息处理国家工程研究中心)、Li-Rong Dai(中国科学技术大学语音及语言信息处理国家工程研究中心)
💡 毒舌点评
亮点:论文巧妙地将“噪声导致量化不稳定”这一现象从问题转化为解决方案——通过在训练时用概率采样主动模拟这种不稳定性,实现了“用扰动对抗扰动”的优雅思路,且完全不需要噪声数据,资源效率极高。 短板:实验主要聚焦于评估编解码器在编码-解码任务本身的抗噪性能,但对于其在更下游的、更复杂的任务(如基于离散码本的语音生成、语音大语言模型)中的鲁棒性影响,未作探索,这使得论文的实际价值论证链条不够完整。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开。
- 数据集:使用了公开的VCTK和DEMAND数据集,但论文中未说明是否提供了处理后的子集或生成脚本。
- Demo:论文中未提及在线演示,但提供了噪声样本的在线链接(https://zhengrachel.github.io/NoiseRobustAudioCodec/)用于感知评估。
- 复现材料:给出了关键的训练超参数(K=10, τ=5, 学习率)、模型配置(如Encodec 24kHz/6kbps)、以及渐进式训练的算法伪代码(算法1)。
- 论文中引用的开源项目:引用了Encodec[14]、WavTokenizer[22]、VCTK[23]、DEMAND[24]、UTMOS评估工具[27]等开源数据集和模型。
📌 核心摘要
- 问题:神经语音编解码器(如Encodec)在存在背景噪声的真实环境中性能会显著下降,因为轻微的输入噪声会导致量化码本(RVQ)的决策边界不稳定,产生错误的码字映射。
- 核心方法:提出一种资源高效的训练策略,在仅使用干净语音数据训练的前提下,通过模拟量化层的噪声扰动来增强鲁棒性。包含两个核心机制:(1) 距离加权概率Top-K采样:在训练时,替代确定性的最近邻选择,根据距离概率从Top-K个候选码字中采样;(2) 渐进式训练:从RVQ的最后一个量化器开始,逐层向前引入概率采样,实现从易到难的课程学习。
- 创新性:与传统需要嘈杂-干净配对数据的方法相比,本方法无需任何噪声数据,且通过在量化层面直接建模扰动,更具针对性和资源效率。与简单的随机采样相比,概率采样利用了距离信息,使扰动更符合真实噪声特性。
- 主要实验结果:在Encodec和WavTokenizer上的实验表明,该方法显著提升了噪声条件下的编解码性能。关键数据(来自表1):
模型 噪声条件 指标 基线值 提出方法值 提升 Encodec 15 dB SNR UTMOS 3.475 3.586 +0.111 Encodec 15 dB SNR SI-SDR 4.519 5.232 +0.713 Encodec 10 dB SNR UTMOS 3.243 3.352 +0.109 同时,该方法在干净语音上的编码质量也得到了提升(如Encodec的UTMOS从3.732提升至3.854)。 - 实际意义:提供了一种即插即用的训练增强策略,可低成本地提升现有神经语音编解码器在噪声环境下的可靠性,有利于其在移动通信、物联网及语音生成模型中的实际部署。
- 主要局限性:方法的有效性依赖于RVQ结构;实验未评估其对下游语音生成任务(如TTS)的影响;虽然对比了噪声数据微调的基线,但未与更多最新的编解码器鲁棒性方法进行对比。
🏗️ 模型架构
本文的核心并非提出一个新的编解码器模型架构,而是提出一种适用于现有神经语音编解码器的训练策略。该策略可应用于采用残差矢量量化(RVQ)的编解码器。
- 目标模型:论文主要以Encodec和WavTokenizer作为验证平台。两者都遵循编码器-量化器-解码器的基本框架。
- Encodec:一个可流式的编解码器,使用包含6个VQ的RVQ,每个VQ的码本大小为1024。其架构是典型的卷积编码器,通过多层RVQ进行残差量化,最后由卷积解码器重建波形。
- WavTokenizer:一个单码本(非RVQ)的编解码器,使用一个VQ,码本大小为4096。其架构可能更侧重于利用大码本捕捉更丰富的表示。
- 训练策略的介入点:该策略完全作用于量化器(VQ/RVQ)的训练阶段,不改变编码器和解码器的网络结构。在训练时,它改变了量化器输出
ˆz的获取方式(从确定性最近邻变为概率采样),从而让解码器学会对量化层的输入扰动(模拟噪声影响)保持鲁棒。 - 数据流与交互:
- 训练时:对于每个输入的干净语音特征
z,在RVQ的指定层(如第l层),计算其与所有码本向量的距离,并对Top-K个最近的候选码字根据公式(4)进行概率采样,得到量化结果ˆz。此ˆz被送入后续量化层或解码器。梯度通过采样操作回传。 - 推理时:恢复使用标准的确定性最近邻选择,以保证重建质量。
- 训练时:对于每个输入的干净语音特征
- 关键设计选择:
- 概率Top-K采样:动机是真实噪声更可能使特征在码本空间内发生局部偏移,而非全局随机跳转。因此,基于距离的概率分布能生成更“合理”的扰动。
- 渐进式训练:动机是RVQ的层级性——第一层编码主要结构,后续层编码细节。直接对第一层施加扰动可能导致训练崩溃。因此,从影响最小的最后一层开始,逐步向前推进,实现稳定的学习曲线。
💡 核心创新点
- 量化层扰动模拟作为数据增强:是什么:在训练时,通过在量化器输出端引入可控的、基于距离的概率采样,来模拟真实噪声对量化决策的扰动。之前局限:传统方法依赖噪声-干净数据对进行端到端微调,数据成本高且可能过拟合特定噪声。如何起作用:使解码器在训练中提前“见识”并适应量化输出的可能变化,从而学会生成更鲁棒的波形。收益:无需噪声数据,且提升对未知噪声的泛化能力(见表2, 表3)。
- 针对RVQ的渐进式训练策略:是什么:将扰动采样从RVQ的最后(最细节)一层逐步应用到第一层(最核心)的训练过程。之前局限:一次性对所有量化层施加扰动会破坏训练稳定性(文中“Direct Top-K”效果较差)。如何起作用:遵循从易到难的课程学习原则,让模型逐步适应从外围到核心的量化扰动。收益:保证了训练的稳定性和最终性能(见图2)。
- 资源高效与零样本泛化:是什么:整个策略仅依赖干净语音数据,并在推理时无任何额外开销。之前局限:噪声数据收集和标注成本高;基于噪声训练的模型可能损害干净语音性能。如何起作用:通过模拟量化内部扰动,间接、高效地注入鲁棒性。收益:训练成本低,且同时保持甚至提升了干净语音的编解码质量(表1),具有更好的通用性。
🔬 细节详述
- 训练数据:使用VCTK-0.92语料库的子集,遵循文献[17]的设置。数据经过语音活动检测(VAD)提取非静音段。
- 损失函数:论文中未明确说明编解码器训练所用的具体损失函数(如重构损失、对抗损失、特征匹配损失等)。这是信息缺失,但可推断是沿用Encodec和WavTokenizer原论文的损失组合。
- 训练策略:
- 基线训练:先使用传统最近邻策略在干净数据上训练Encodec和WavTokenizer直至收敛。
- 微调:使用提出的渐进式概率采样策略进行微调。学习率:微调学习率为1e-4(基线训练为3e-4)。
- 渐进过程:对于Encodec(N=6),从第6个VQ开始应用采样,逐步到第1个VQ。每个阶段更新梯度时,主要优化该VQ及其之后的组件(算法1)。
- 关键超参数:
- Top-K的K值:设为10。依据是初步分析发现大部分码字偏移发生在前10个最近候选内。
- 温度系数τ:设为5。τ=10过于平滑(接近随机),τ=1过于尖锐(接近最近邻),5是折中值。
- 训练硬件:论文中未说明。
- 推理细节:推理时完全使用标准的确定性最近邻量化,无额外开销。
- 正则化或稳定训练技巧:渐进式训练本身就是一种主要的稳定技巧。此外,使用了温度τ来控制扰动分布的平滑度。
📊 实验结果
主要对比实验(与标准基线): 表1提供了在噪声和干净语音上的全面对比。关键数据如核心摘要所示,所有指标均有统计显著性提升(p<0.05)。这表明方法在提升噪声鲁棒性的同时,也增强了干净语音的重建质量。
与强基线(噪声数据微调)的对比(表2): 该对比极具说服力。基线“Closest*”在测试集使用的噪声上进行过微调。 在匹配噪声下:Closest在某些指标(如PESQ)上更优,这是预期的上界。 在未见过的噪声下(表3):提出的方法在三种不在训练集中的噪声(DWASHING, OOFFICE, TCAR)上均优于Closest,证明了零样本泛化能力。 在干净语音上:提出方法性能优于或持平于Closest,而后者在干净语音上性能下降。
消融实验:
- 概率采样 vs. 随机采样(Proposed†):表2显示,概率采样在所有条件下均优于随机采样(Proposed†),证明了结构化扰动的重要性。
- 渐进式 vs. 直接应用(图2):图2展示了在渐进应用(从第6到第1 VQ)过程中PESQ和UTMOS的稳定上升。直接对所有VQ应用(Direct Top-K)的效果明显更差,验证了渐进策略的必要性。
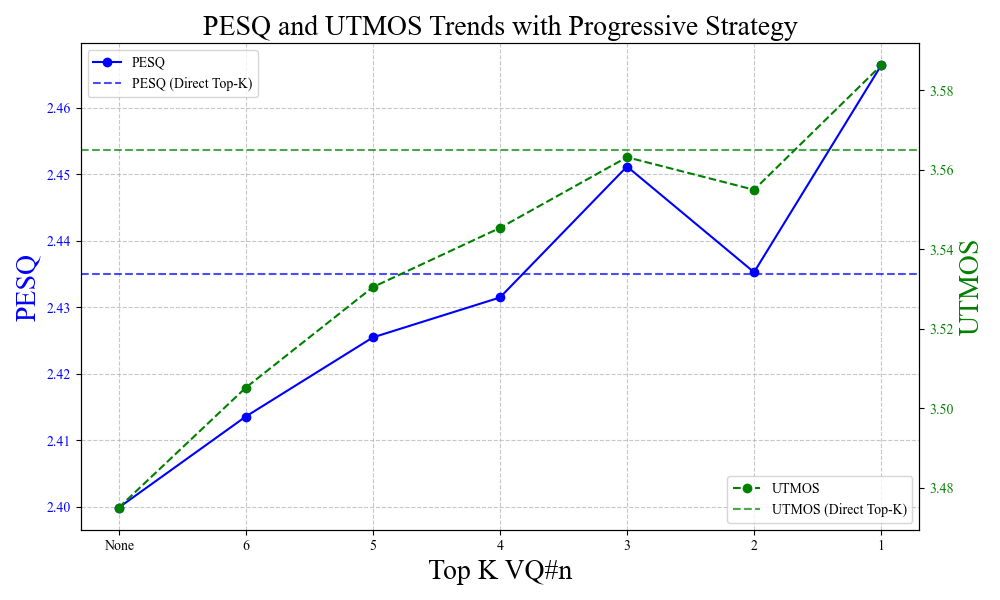 (图2说明:随着扰动从外围量化层向核心层逐步引入,语音质量评估指标呈现稳定上升趋势,证实了渐进式课程学习的有效性。)
(图2说明:随着扰动从外围量化层向核心层逐步引入,语音质量评估指标呈现稳定上升趋势,证实了渐进式课程学习的有效性。)
⚖️ 评分理由
- 学术质量:5.5/7 - 论文提出了一个设计精巧、动机明确的方法,并通过充分、严谨的实验进行了验证。创新属于有效的策略创新,而非开辟新方向,因此分数中等偏上。
- 选题价值:1.5/2 - 解决了一个实际且重要的问题(编解码器噪声脆弱性���,提出的方法具有高实用性(无需噪声数据、即插即用),对社区有直接价值。
- 开源与复现加成:0.5/1 - 提供了详细的实验设置和部分材料链接,但未开源核心代码和模型,限制了复现的便利性。