📄 Enhancing Automatic Drum Transcription with Online Dynamic Few-Shot Learning
#音乐信息检索 #少样本学习 #领域适应 #实时处理
✅ 7.0/10 | 前25% | #音乐信息检索 | #少样本学习 | #领域适应 #实时处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Philipp Weyers (Fraunhofer Institute for Integrated Circuits (IIS), Germany)
- 通讯作者:未说明(论文中作者列表后未明确标注通讯作者)
- 作者列表:Philipp Weyers (Fraunhofer IIS), Christian Uhle (Fraunhofer IIS & International Audio Laboratories Erlangen), Meinard Müller (Fraunhofer IIS & International Audio Laboratories Erlangen), Matthias Lang (Fraunhofer IIS)。
💡 毒舌点评
亮点是首次在ADT中提出一种无需人工标注、支持流式处理的在线自适应方法,将少样本学习从“学习新类”巧妙地转化为“适配已知类的音色”,思路清晰且工程价值明确。短板在于,消融分析揭示其宣称的“在线自适应”带来的实际性能提升在部分数据集上有限,大部分性能增益其实来自离线训练阶段的优化(如第二阶段训练),这使得在线部分的贡献显得有些“锦上添花”而非核心突破。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:论文中使用了STAR Drums, MDB Drums, ENST Drums, RBMA13等数据集,但未说明是否提供或如何获取。
- Demo:未提及。
- 复现材料:论文给出了较为详细的模型结构描述、训练阶段、损失函数、超参数优化值和评估设置,有助于复现,但未提供训练脚本或配置文件。
- 论文中引用的开源项目:引用了mir_eval库用于评估。
- 总体:论文中未提及任何开源计划或资源发布。
📌 核心摘要
该论文旨在解决自动鼓转录(ADT)中鼓音色高度多样化、但同一首歌内音色相对一致的挑战,导致即使SOTA模型泛化能力也有限的问题。其核心方法是在线动态少样本学习(Online Dynamic FSL),在推理时同时运行两个转录分支:一个基于训练好的基础原型(BaseOnly),另一个使用从当前歌曲中动态检测到的鼓点作为支持集,通过少样本原型生成器创建自适应原型(AdaptedClass)。最终将两个分支的分类得分加权平均,用于生成最终的转录结果。与已有动态FSL方法相比,其新意在于首次实现了无需预知完整歌曲、在推理过程中实时进行逐歌曲适配,适用于流式场景。主要实验在三个数据集(MDB, ENST, RBMA13)和两个网络架构(CNN, CRNN)上验证,平均相对性能提升约4.4%。该方法的实际意义在于为实时音乐处理(如卡拉OK伴奏生成、音乐编辑)提供了更精准的鼓点识别能力。其主要局限性是,在某些数据集上,在线适配带来的直接增益相比仅通过改进训练阶段获得的增益要小,且对基础性能就较差的鼓类(如镲片、铃铛)改善有限。
🏗️ 模型架构
模型整体架构如图1所示。它以梅尔频谱图块作为输入,逐帧输出鼓点转录结果。
各组件及数据流如下:
- 嵌入网络:输入为梅尔频谱图块(CNN处理25帧, CRNN处理200帧)。通过卷积层(+可选的GRU层)和线性层,将输入映射到256维的潜在空间,输出帧级的潜在表示。
- 基础类分类器:接收嵌入网络的潜在表示,与训练好的每个鼓类的基础原型(可学习向量)及一个共享的负类原型计算余弦相似度,经softmax转换为每个类别的基础分类概率($p_{base,k}$)。
- 峰选与环形缓冲区:对基础类分类器的输出概率序列进行峰选(基于局部极大值和阈值),初步检测出鼓点时间。将检测到鼓点附近(支持集)的5个潜在表示存储在每个类别的环形缓冲区中,形成该歌曲的支持集。
- 少样本原型生成器:这是一个基于多头自注意力机制的网络。它使用环形缓冲区中的支持集作为查询(Query),学习到的键(Key)作为参数,基础类原型作为值(Value)。结合一个对支持集嵌入的平均值分量,通过可学习的权重矩阵加权求和,为每个鼓类生成一个自适应原型。这个原型旨在捕捉当前歌曲特定的鼓音色特征。
- 自适应类分类器:结构与基础类分类器相同,但使用少样本原型生成器产生的自适应原型进行分类,得到自适应分类概率($p_{adapt,k}$)。
- 加权平均与最终峰选:将两个分类器的输出概率按公式 $p_k = (1 - \alpha) \cdot p_{adapt,k} + \alpha \cdot p_{base,k}$ 进行加权平均。α是一个可调参数(在验证集上优化)。对最终的平均概率再次进行峰选,得到最终的鼓点转录时间估计。
关键设计选择:
- 双分支并行:结合了稳定但固定的基线知识(基础原型)和灵活但可能不稳定的实时适配(自适应原型),通过加权平均平衡二者。
- 无需网络权重更新:自适应过程仅通过生成新的原型实现,不更新嵌入网络或分类器的权重,保证了实时处理的可行性。
- 基于峰选生成支持集:自动化过程,避免了人工标注。
💡 核心创新点
- 在线测试时适配:首次在ADT中实现了无需完整歌曲、无需人工标注的逐歌曲在线音色适配,使系统能够适应流式输入,这是从“动态少样本学习”到“在线动态少样本学习”的关键扩展。
- 适配而非新类学习:重新定义了少样本学习在ADT中的角色——从学习未见类别转变为对已知类别进行音色微调,避免了推理时对每个类都需要支持样本的限制。
- 改进的少样本原型生成器:采用多头注意力机制(代替单头),允许模型同时关注支持集中不同部分的信息来构建更鲁棒的自适应原型。
- 双分支决策融合:巧妙地将基线模型(无适配)和适配模型的输出进行加权平均,既保留了模型的基础知识,又引入了歌曲特定的优化,在鲁棒性和适应性之间取得平衡。
🔬 细节详述
- 训练数据:使用STAR Drums数据集。该数据集通过音乐源分离和重合成技术创建,包含与原始非鼓音轨混合的、具有精确真实标注的合成鼓音轨。支持8个鼓类。
- 损失函数:两个训练阶段均使用二元交叉熵损失。为处理类别不平衡,采用了样本欠采样、类别权重和目标展宽技术。
- 训练策略:
- 第一阶段:使用重合成的鼓音轨数据,训练嵌入网络和基础类原型。
- 第二阶段:使用STAR Drums的原始混合音频(带伪标签)继续训练基础原型和嵌入网络(论文指出继续微调有益),同时训练少样本原型生成器。在本阶段,对于每个批次,随机选一个类,用其自适应原型替换基础原型进行分类(仅用自适��原型,不用加权平均)以高效训练生成器。支持集由数据集中随机选取的该类别的5个样本组成。
- 关键超参数:
- 潜在表示/原型维度:256
- 支持集大小:5
- 自注意力头数:2
- CNN:5个卷积层(256个3x3滤波器),实例归一化,最大池化,ELU激活。处理25帧。
- CRNN:在CNN基础上增加3个GRU层(60个隐藏状态)。处理200帧。
- 线性层:3个,前两个使用tanh激活。
- 峰选参数:前向看帧数为2,阈值(基础分支)在验证集上优化(CNN: 0.63, CRNN: 0.78)。
- 融合权重α:在验证集上优化(CNN: 0.72, CRNN: 0.60)。
- 最终峰选阈值:在验证集上优化(CNN与CRNN均为0.65)。
- 训练硬件:论文中未提及。
- 推理细节:支持实时流式处理。自适应原型根据环形缓冲区的内容在每个新鼓点检测后更新。
- 正则化技巧:未明确提及如Dropout等标准正则化方法,但训练过程中的两阶段策略和特定的数据处理(如类别不平衡处理)起到了稳定训练的作用。
📊 实验结果
评估在三个数据集(MDB Drums, ENST Drums, RBMA13)上进行,转录8个鼓类,使用全局F-measure(微观平均)作为指标,容差窗口±50ms。
主要对比结果(表1:全局F-measure)
| 模型 | MDB | ENST | RBMA |
|---|---|---|---|
| CNN-BaseOnly | 0.719 | 0.713 | 0.608 |
| CNN-OracOFSL | 0.733 | 0.732 | 0.663 |
| CNN-OFSL | 0.738 | 0.741 | 0.643 |
| CRNN-BaseOnly | 0.761 | 0.743 | 0.617 |
| CRNN-OracOFSL | 0.784 | 0.782 | 0.697 |
| CRNN-OFSL | 0.793 | 0.783 | 0.648 |
- 结论:提出的OFSL方法(在线动态FSL)在所有数据集和两种架构上均优于BaseOnly基线。例如,CRNN在MDB上从0.761提升至0.793,在ENST上从0.743提升至0.783。ORACOFSL(使用真实鼓点创建支持集)性能通常最佳,表明支持集的质量很重要。OFSL在MDB和ENST上甚至略优于ORACOFSL,可能是因为其支持集过滤掉了软性或非代表性鼓点。
起始点偏移鲁棒性分析(表2:RBMA13数据集)
| 模型 | σ=0.00s | σ=0.05s | σ=0.1s | σ=0.2s |
|---|---|---|---|---|
| CNN-OracOFSL | 0.663 | 0.656 | 0.650 | 0.641 |
| CRNN-OracOFSL | 0.697 | 0.681 | 0.650 | 0.629 |
- 结论:在模拟现实起始点估计噪声时,性能下降温和。当噪声标准差σ达到0.1秒时,CRNN性能从0.697降至0.650,表明系统对中等程度的起始点噪声具有鲁棒性。
支持集大小影响(表3:三数据集平均全局F-measure)
| 模型 | N=1 | N=2 | N=5 | N=10 |
|---|---|---|---|---|
| CRNN-OracOFSL | 0.758 | 0.746 | 0.754 | 0.732 |
| CRNN-OFSL | 0.731 | 0.733 | 0.741 | 0.732 |
- 结论:对于有理想支持集的ORACOFSL,单样本(N=1)效果最好。而对于实际的OFSL,使用多个样本(N=5)略有帮助,可能因为多样本减轻了单个不准确样本的影响。
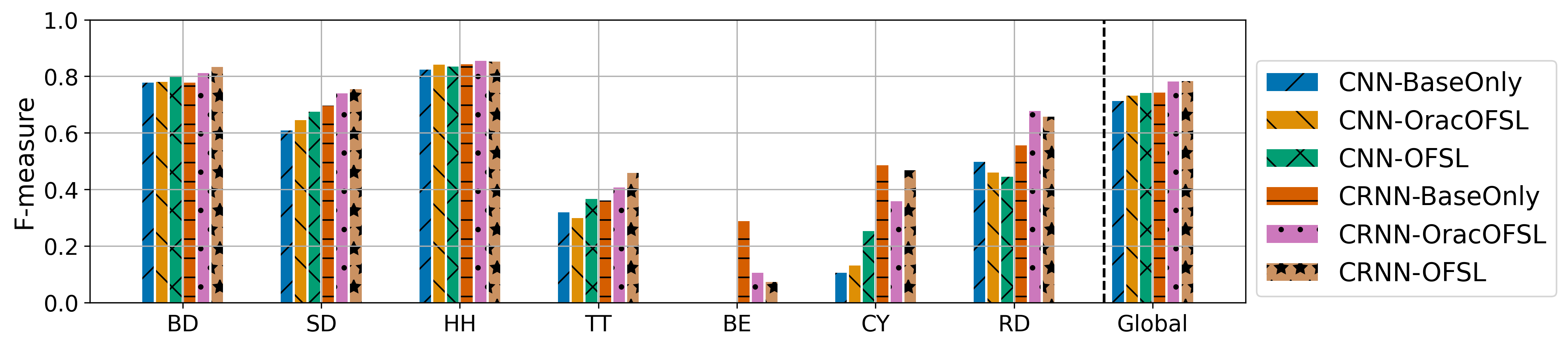
分类别性能分析(图2)
- 结论(以ENST数据集为例):在线动态FSL(OFSL)对基础性能已经较好的类别(如低音鼓BD、军鼓SD、踩镲HH)有稳定提升,而对基础性能较差的类别(如铃铛BE、镲片CY、叮叮镲RD)改善有限。这表明在线适配更依赖于模型已有的一定识别能力。
关键消融结论:论文指出,总增益中很大一部分(约4.4%的平均相对提升)实际上来自第二阶段使用原始混合数据的训练,而非在线适应本身。在线适应在RBMA13数据集上(当使用理想起始点时)展现出巨大潜力,但在MDB和ENST上增益相对较小。
⚖️ 评分理由
- 学术质量:6.0/7。创新点明确且实用,技术方案(双分支、注意力原型生成)设计合理。实验较为充分,在三个数据集和两个模型上验证,并进行了鲁棒性和支持集大小等消融分析。然而,部分结论略显保守(如承认大部分增益来自训练阶段),且对于在线适应部分贡献的量化分析可以更深入。
- 选题价值:1.5/2。自动鼓转录是音乐信息检索的一个具体但重要的子任务。本文提出的在线自适应方法具有明确的实时应用价值(如流媒体音乐处理、实时效果器)。方法论(在线动态FSL)也可能推广到其他音频分类任务。对专门从事音频/音乐研究的读者有较高参考价值。
- 开源与复现加成:-0.5/1。论文详细描述了模型架构、训练过程和关键超参数,为复现提供了良好基础。然而,论文中未提及是否公开代码、模型权重或数据集获取方式,这显著影响了复现的便利性,因此给予负分。