📄 Enhanced Generative Machine Listener
#音频分类 #生成模型 #深度学习 #音频编码
✅ 7.0/10 | 前25% | #音频分类 | #生成模型 | #深度学习 #音频编码
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:未说明
- 通讯作者:未说明
- 作者列表:Vishnu Raj(Dolby Laboratories)、Gouthaman KV(Dolby Laboratories)、Shiv Gehlot(Dolby Laboratories)、Lars Villemoes(Dolby Laboratories)、Arijit Biswas(Dolby Laboratories)
💡 毒舌点评
亮点:论文将主观听测分数建模问题,从传统的单点预测提升到对分数概率分布(Beta分布)的建模,这一理论视角的升级更为本质,能自然处理分数的边界和偏态分布。短板:实验虽全面,但核心创新是改进损失函数(Beta loss)和数据扩展,缺乏对模型架构本身(如Inception块)的深入剖析或创新,且置信区间的预测价值未被定量验证,略显“画饼”。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开模型权重。
- 数据集:论文中提到了使用的训练集和测试集来源(如ODAQ),但未说明是否公开或如何获取其扩展的完整训练数据集。
- Demo:未提供在线演示。
- 复现材料:论文提供了较为详细的训练配置(GPU型号、batch size、优化器、学习率、训练步数、语谱图参数),但缺少网络具体架构配置、完整的预处理脚本和检查点信息。
- 论文中引用的开源项目:引用了多个公开的神经音频编解码器模型(如Encodec, Descript Audio Codec, MDCTNet),这些可能作为测试数据的一部分。也提到了PEAQ和ViSQOL的开源实现。
📌 核心摘要
- 问题:自动化的客观音频质量评估模型通常输出单一分数,无法捕捉主观评价中的内在不确定性和变异性,尤其是在边界或歧义情况下。
- 核心方法:提出GMLv2,一个基于Beta分布的生成式模型。它通过神经网络预测Beta分布的形状参数(α, β),从而联合估计期望的MUSHRA分数(分布均值)和不确定性(分布方差/形状)。
- 创新点:相较于使用高斯/逻辑斯蒂分布的GMLv1,Beta分布天然定义在[0,1]区间,完美匹配归一化的MUSHRA分数,无需后处理修正,且其灵活的形状能更好地拟合有偏或双峰的听众评分分布。
- 主要实验结果:在8个涵盖传统编解码器(AAC, Dolby AC-4等)和神经编解码器(Encodec, DAC等)的测试集上,GMLv2在皮尔逊相关性(Rp)、斯皮尔曼相关性(Rs)和离群点率(OR)上均显著优于PEAQ、ViSQOL-v3和重新训练后的GMLv1(见下表)。聚合Rp/Rs达到0.9526/0.9205,OR降至0.0964。
表1:主要实验结果对比
评测集 PEAQ (Rp/Rs) ViSQOL (Rp/Rs) GMLv1* (Rp/Rs/OR) GMLv2 (Rp/Rs/OR) USAC-1 0.47/0.40 0.81/0.84 0.91/0.90/0.045 0.92/0.90/0.045 USAC-2 0.42/0.20 0.77/0.78 0.89/0.84/0.067 0.93/0.89/0.067 USAC-3 0.56/0.62 0.82/0.90 0.92/0.92/0.046 0.94/0.93/0.046 Binaural 1 0.75/0.79 0.90/0.93 0.95/0.93/0.182 0.98/0.94/0.182 Binaural 2 0.42/0.56 0.96/0.85 0.98/0.91/0.012 0.99/0.91/0.012 NAC Mono 0.34/0.31 0.89/0.86 0.92/0.94/0.833 0.97/0.94/0.071 NAC Stereo 0.58/0.40 0.82/0.89 0.93/0.90/0.589 0.95/0.93/0.078 ODAQ 0.71/0.65 0.70/0.80 0.81/0.81/0.817 0.83/0.83/0.271 聚合 0.56/0.52 0.85/0.86 0.93/0.90/0.725 0.95/0.92/0.096 - 实际意义:为音频编码(特别是神经编解码器)的研发提供了一个更可靠、可解释的自动化质量评估工具,能够量化预测的不确定性,加速评估迭代。
- 主要局限性:(1) 论文中未提供模型权重和代码开源计划,复现依赖外部资源;(2) 虽然模型预测了分布参数,但文中明确指出“置信区间的定量评估留待未来工作”;(3) 模型架构主体沿用前作的Inception块,创新主要集中在损失函数和训练数据扩展。
🏗️ 模型架构
GMLv2是一个参考型深度学习模型,其输入为参考音频(x)和待测音频(˜x)的信号对,输出为预测的MUSHRA分数均值及其对应的Beta分布参数(α, β)。
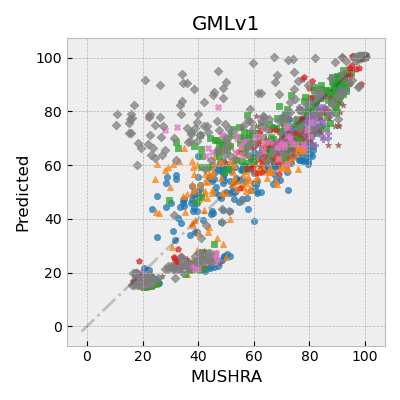 图1(论文图1):预测分数与真实MUSHRA分数的散点对比图。GMLv2(最右列)的预测点紧密围绕对角线(理想预测线),显示其在所有测试集上预测的一致性和准确性显著优于PEAQ和ViSQOL。
图1(论文图1):预测分数与真实MUSHRA分数的散点对比图。GMLv2(最右列)的预测点紧密围绕对角线(理想预测线),显示其在所有测试集上预测的一致性和准确性显著优于PEAQ和ViSQOL。
整体流程与关键组件:
- 特征提取:
- 对参考和待测信号分别进行声道转换(对于立体声/双耳信号,计算左L、右R、中M=(L+R)/2、边S=(L-R)/2声道)。
- 使用Gammatone滤波器组计算每声道的Gammatone语谱图(仅使用功率谱)。该滤波器模拟人耳耳蜗的滤波特性。
- 将所有参考和待测信号的Gammatone语谱图进行拼接,形成模型的输入特征。语谱图参数:窗口80ms,跳频20ms,32个通道,最低频率50Hz。
- 神经网络骨干:
- 网络架构基于Inception块。Inception结构通过多尺度卷积核并行捕获不同时间-频率尺度的特征,适合处理语谱图。
- 输入为拼接后的参考/待测语谱图对。
- 输出层与参数化:
- 网络的最终输出是一个全连接层,输出维度为2,即
ỹ = [˜α, ˜β]。 - 为了保证预测的Beta分布是单峰的(α, β > 1),通过公式
(2)对输出进行变换:α = 1 + exp(˜α),β = 1 + exp(˜β)。exp操作确保参数始终大于1。
- 网络的最终输出是一个全连接层,输出维度为2,即
- 推断输出:
- MUSHRA分数预测:计算Beta分布的均值
μ = α/(α+β),并缩放100倍得到最终分数(公式(6))。 - 不确定性量化:模型直接提供了描述分数分布形状的
α和β参数。方差Var[z] = αβ/[(α+β)²(α+β+1)]可用于表征预测的不确定性。论文中提到,置信区间的计算方法沿用GMLv1,即基于t分布,但定量验证未完成。
- MUSHRA分数预测:计算Beta分布的均值
💡 核心创新点
- 采用Beta分布作为输出概率模型:这是最核心的理论创新。传统的音频质量模型(如PEAQ、ViSQOL)输出单一确定性分数。GMLv1开始建模分布,但使用高斯/逻辑斯蒂分布(无界、对称)。MUSHRA分数是[0,100]间的有界分数,且听众分布可能不对称或被截断。Beta分布天然定义在[0,1]区间,且形状灵活(对称、左偏、右偏、钟形),无需人工修正即可完美拟合有界数据,这在统计上是更合理、更优的选择。
- 基于负对数似然的分布匹配训练:模型的损失函数是Beta分布的负对数似然(公式
(5)),而非传统的MSE或MAE。这使模型直接优化对听众分数分布的拟合度,而非仅仅逼近均值,从而能更好地捕获分布的整体形态和不确定性。 - 扩展的训练数据,覆盖神经音频编解码器(NAC):在GMLv1数据集基础上,加入了大量来自传统编解码器(AAC, AC-4等)和新型神经编解码器(Encodec, DAC, MDCTNet等)的MUSHRA测试数据,总数据量达82,191样本对。这显著增强了模型在现代音频编码技术上的泛化能力,是其在多个NAC测试集上表现优异的关键。
🔬 细节详述
- 训练数据:
- 来源与构成:包含传统立体声/双耳编解码器数据(AAC, HE-AAC, Dolby AC-4/Atmos)和神经音频编解码器数据(Encodec, Descript Audio Codec, MDCTNet及其神经增强版本)。
- 规模:总计82,191个(参考,待测)样本对。其中传统编解码器68,503对,神经编解码器14,688对。
- 预处理:音频采样率为48kHz,使用耳机进行主观测试。模型输入为Gammatone语谱图。
- 数据增强:论文未明确提及使用数据增强技术。
- 损失函数:Beta分布的负对数似然损失(公式
(5)):L(x, ˜x, s) = -(α-1)ln(s) - (β-1)ln(1-s) + ln B(α, β)。其中s是归一化到[0,1]的MUSHRA分数目标。该损失函数鼓励模型预测的Beta分布尽可能拟合真实分数s。 - 训练策略:
- 优化器:Adam优化器。
- 学习率:
1 × 10^-4。 - 批大小:8 per GPU。
- 训练步数:400,000步。
- 调度策略:论文未提及学习率调度策略。
- 关键超参数:语谱图窗口80ms,跳频20ms,32个滤波器通道,最低频率50Hz。网络核心为Inception块(具体层数、通道数未说明)。
- 训练硬件:2块NVIDIA A10G GPU。
- 模型选择:在验证集上选择最大化
Rp × Rs的检查点作为最佳模型。 - 正则化技巧:论文未提及使用Dropout、权重衰减等正则化技巧。
📊 实验结果
- 主要Benchmark与指标:
- 评测集:8个独立测试集(USAC-1/2/3, Binaural-1/2, NAC Mono, NAC Stereo, ODAQ),涵盖单声道、立体声、双耳音频,以及传统与神经编解码器。
- 评估指标:皮尔逊线性相关系数(Rp↑)、斯皮尔曼秩相关系数(Rs↑)、在95%置信区间下的离群点比例(OR↓)。 与SOTA对比:与PEAQ、ViSQOL-v3以及重新训练的GMLv1(GMLv1)对比。GMLv2在几乎所有测试集和聚合指标上都取得最佳结果。聚合Rp/Rs从GMLv1*的0.9284/0.9038提升至0.9526/0.9205,聚合OR从0.7247大幅下降至0.0964(具体数据见上文表格)。 关键消融实验:论文未进行明确的消融实验(如去掉Beta损失、只用部分数据等),但通过对比“使用相同扩展数据训练的GMLv1”与“GMLv2”,间接证明了从高斯/逻辑斯蒂分布切换到Beta分布带来的性能增益。
- 细分结果:GMLv2的优势在传统编解码器(如USAC系列)和神经编解码器(NAC Mono/Stereo)上均有体现,且在双耳音频(Binaural)和ODAQ(含各类失真)上也表现稳健,证明了其广泛的泛化能力。
- 可视化证据:论文提供了图1(散点图),直观展示了GMLv2的预测点相比PEAQ和ViSQOL更紧密地聚集在对角线周围,支持了其定量结果。
 (注:根据用户提供的图片列表,此图对应图2,但论文正文中未明确引用图2。可能为其他结果图。)
(注:根据用户提供的图片列表,此图对应图2,但论文正文中未明确引用图2。可能为其他结果图。)
 (注:根据用户提供的图片列表,此图对应图3,但论文正文中未明确引用图3。可能为其他结果图。)
(注:根据用户提供的图片列表,此图对应图3,但论文正文中未明确引用图3。可能为其他结果图。)
 (注:根据用户提供的图片列表,此图对应图4,但论文正文中未明确引用图4。可能为其他结果图。)
(注:根据用户提供的图片列表,此图对应图4,但论文正文中未明确引用图4。可能为其他结果图。)
⚖️ 评分理由
- 学术质量:6.5/7:创新性明确(Beta分布建模),技术路线正确且合理,实验设计非常全面(多数据集、多指标、多基线对比),数据规模大,结果有说服力。扣分点在于:网络架构主体非原创,是重要创新点之一(Beta分布)的理论应用,但缺少更深入的消融分析或理论探讨;此外,关于置信区间的承诺未能在本文兑现。
- 选题价值:1.5/2:音频质量评估是音频工程和编解码研发中的核心、高频需求。随着神经编解码器兴起,亟需新的评估工具。GMLv2直接面向此需求,潜在应用价值高,与工业界和学术界的音频/语音读者高度相关。扣分在于任务相对垂直和传统,并非当前最前沿的热点(如生成、理解)。
- 开源与复现加成:-0.5/1:论文未提供代码、模型权重、训练数据的开源链接或获取方式。虽然详细描述了训练配置(硬件、优化器、超参数),但由于模型架构细节(如Inception块具体配置)未完全公开,且缺乏预训练模型,完全复现论文结果的难度很高。因此给予负分加成。