📄 Emotional Dimension Control in Language Model-Based Text-To-Speech: Spanning a Broad Spectrum of Human Emotions
#语音合成 #流匹配 #预训练 #零样本 #语音情感识别
✅ 7.5/10 | 前25% | #语音合成 | #流匹配 | #预训练 #零样本
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.2 | 置信度 中
👥 作者与机构
- 第一作者:Kun Zhou(阿里巴巴集团通义实验室,新加坡)
- 通讯作者:未说明
- 作者列表:Kun Zhou(阿里巴巴集团通义实验室,新加坡)、You Zhang(美国罗切斯特大学)、Dianwen Ng(阿里巴巴集团通义实验室,新加坡)、Shengkui Zhao(阿里巴巴集团通义实验室,新加坡)、Hao Wang(阿里巴巴集团通义实验室,新加坡)、Bin Ma(阿里巴巴集团通义实验室,新加坡)
💡 毒舌点评
亮点在于将经典心理学理论(PAD模型)与前沿的语言模型TTS框架深度结合,实现了从离散情感标签到连续情感空间控制的优雅跳转,为情感语音合成提供了更富表现力的控制范式。短板是实验部分更像一场“理论验证秀”(如图2展示合成语音的声学特征与理论吻合),但在与当前最强系统(如使用大规模情感数据或更强解码方法的模型)的“硬碰硬”对比和系统性消融实验上显得保守和不足,使得其宣称的优势说服力打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:使用了公开的ESD和LibriTTS数据集。情感维度预测器的训练数据(ESD子集)是公开的,TTS训练数据(LibriTTS)也是公开的。
- Demo:提供了在线演示页面:https://demos46.github.io/emotion_pad/
- 复现材料:提供了模型架构描述、关键超参数(如ED预测器的训练设置、TTS模型各组件维度)、数据集规模等信息。但未提供完整的训练脚本、配置文件或预训练检查点。
- 论文中引用的开源项目:引用了CosyVoice、HiFi-GAN、3D-Speaker(用于说话人嵌入)、WavLM、UMAP等开源模型和工具。
📌 核心摘要
- 要解决什么问题:当前的情感语音合成(TTS)系统受限于数据集中的少量离散情感标签(如喜怒哀乐),无法覆盖人类丰富(理论上有约34000种)且微妙的情感光谱,导致生成语音的情感表达有限、不自然。
- 方法核心是什么:本文提出一个基于语言模型的TTS框架,核心是引入情感维度(ED)预测器和连续情感维度控制。ED预测器利用心理学期理论(PAD模型:愉悦度-唤醒度-支配度),将语音数据集中的离散情感标签映射为连续的3维向量。在TTS训练和推理时,将ED向量作为额外条件输入语言模型,从而引导语音合成。
- 与已有方法相比新在哪里:相比传统基于离散标签的监督学习或基于参考语音的风格迁移方法,本文方法无需在TTS训练阶段使用显式情感标签,仅通过连续的ED向量即可在推理时灵活控制生成语音的情感风格,且能探索训练数据中未出现过的情感组合。
- 主要实验结果如何:在零样本情感克隆任务上,本文方法的语音自然度MOS(4.54)优于基线CosyVoice(4.36)。在情感可懂度(E-MOS)主观评估中,本方法在所有测试情感上得分均高于CosyVoice基线。XAB测试表明,系统能较好地区分PAD维度相近的情感对(如愤怒vs焦虑,正确匹配率约84%)。客观上,合成语音的音高和频谱通量统计特征与理论预期相符(如图2所示)。
- 实际意义是什么:该框架使得TTS系统能够更精细、灵活地合成多样化的情感语音,无需依赖大规模标注数据,有望提升对话系统、有声读物、虚拟助手等应用的情感交互自然度和用户体验。
- 主要局限性是什么:1) 情感维度预测器依赖于已有的离散情感标签数据集进行训练,其质量可能受限于原始标签的噪声和偏差;2) 实验评估中,与最先进的情感TTS系统(如CosyVoice的情感扩展版本EmoCtrl-TTS)的直接对比缺失,且缺乏关键模块的消融研究;3) 当前工作主要在英语单语种上进行验证,多语言适应性未探讨。
🏗️ 模型架构
本论文的框架包含两个主要阶段:情感维度(ED)预测器训练和TTS模型训练/推理。
- 情感维度(ED)预测器(图1(a))
- 功能:将任意语音片段映射到一个3维的PAD情感向量。
- 架构与数据流:
- 输入:情感语音片段(例如来自ESD数据集)。
- 特征提取:使用预训练的WavLM模型提取语音特征。
- 维度映射:特征经过一个线性层(输出128维情感特征向量)和一个分类层(用于初步预测情感类别)。
- 锚点引导降维:该预测器的核心创新在于使用锚点引导的维度归约。首先,为ESD数据集中的5种离散情感(中性、生气、高兴、悲伤、惊喜)根据Russell的理论[17]预定义一个3维PAD锚点向量(如表1所示)。训练时,将初始锚点向量加入高斯噪声。然后,利用线性层输出的128维特征向量,通过UMAP算法进行降维,并优化目标,使得降维后的3维ED向量既接近其对应情感类别的锚点,又能在高维特征空间中保持样本间的邻域结构(通过kNN图和交叉熵损失约束)。
- 输出:预测的3维PAD情感向量(Pleasure, Arousal, Dominance)。
- 文本到语音(TTS)模型(图1(b))
- 整体架构:采用自回归语言模型(LM)解码器、流匹配(Flow Matching)模块和HiFi-GAN声码器的三阶段架构。
- 关键输入:
- 输入文本(经过G2P处理)。
- 提示语音(可选,用于提供说话人信息和/或情感参考)。
- 情感维度(ED)向量:这是本框架的关键控制信号。其来源有两种:在“情感克隆”模式下,由ED预测器从提示语音中提取;在“情感控制”模式下,由用户直接指定。
- 说话人嵌入(X-vector):来自预训练的声纹模型。
- 数据流与组件交互:
- 文本编码器处理文本,语音标记器(Speech Tokenizer)处理提示语音(如有)。
- 说话人嵌入和ED向量作为条件,与文本特征拼接。
- 自回归语言模型(LM) 解码器在上述条件下,预测离散的语音标记序列。训练时使用教师强制法,优化交叉熵损失。
- 生成的语音标记序列输入流匹配模块(OT-CFM),转换为梅尔频谱图。
- HiFi-GAN声码器将梅尔频谱图转换为最终的语音波形。
- 关键设计选择:将情感信息从传统的分类标签或参考语音,解耦并参数化为连续的ED向量,直接注入到自回归LM的条件中。这使得模型可以“学习”如何将不同的PAD向量映射到相应的韵律和风格变化上。
💡 核心创新点
- 基于心理学连续维度的情感控制空间:借鉴Russell的PAD情感理论,将离散的情感标签映射到一个低维、连续且可解释的3维空间。这突破了传统TTS系统依赖有限离散标签的限制,为用户提供了细粒度、自由组合情感的可能。
- 无需TTS训练阶段情感标签的框架:通过预训练ED预测器,TTS模型在训练时无需情感标签,仅利用表达性语音数据学习。ED预测器在训练后即被冻结,作为固定模块指导TTS生成。这降低了TTS训练对高质量情感标注数据的依赖。
- 锚点引导的维度归约训练ED预测器:在训练ED预测器时,创新性地使用了心理学研究中定义的、基于大量受试者评定的情感锚点值。这使得学习到的ED空间与人类情感感知理论对齐,而非单纯的数据驱动降维,提升了语义合理性和可控性。
- 统一的情感克隆与控制能力:同一个框架,通过ED向量的不同来源(自动提取或手动指定),无缝支持“情感克隆”(从参考语音复现情感)和“情感控制”(主动设计情感)两种核心应用模式。
🔬 细节详述
- 训练数据:
- ED预测器:使用ESD数据集英文子集训练集,约10小时,包含5种基本情感(中性、生气、高兴、悲伤、惊喜)。
- TTS模型:使用LibriTTS数据集,约600小时英语语音,来自2456位说话人,无情感标签。合并了
train-clean和train-other子集。
- 损失函数:
- ED预测器:优化UMAP降维过程中的交叉熵损失,该损失衡量降维后的ED向量与高维特征空间中kNN图结构的一致性。同时,隐含地通过锚点损失(未明确公式化)将ED向量推向对应类别的锚点。
- TTS模型:自回归语言模型使用标准的交叉熵损失,用于预测下一个语音标记。
- 训练策略:
- ED预测器:WavLM微调100个epoch,batch size 64,学习率0.0001,优化器Adam。UMAP优化参数:最小距离0.1,最近邻数20,学习率0.01。
- TTS模型:具体优化器、学习率调度等细节未在文中说明。
- 关键超参数:
- 语音标记器:基于ESPNet Conformer ASR模型,使用向量量化,码本大小为4096,前6层编码器后进行量化。
- 文本编码器:6层Transformer,8头注意力,512维。
- 语言模型:12层Transformer,8头注意力,512维。
- 流匹配模型:使用最优传输条件流匹配(OT-CFM)。
- 训练硬件:未说明。
- 推理细节:情感克隆时,ED向量从提示语音自动推断;情感控制时,用户可根据表1手动指定PAD值。解码策略未具体说明。
- 正则化或稳定训练技巧:未提及。
📊 实验结果
主要实验设置与指标:
- 评估任务:零样本情感克隆(使用相同说话人的一句话作为提示)。
- 主要基线:CosyVoice [12](在LibriTTS上从头训练),MixedEmotion [25](在情感数据上训练)。
- 主要指标:自然度平均意见分数(MOS),情感可懂度平均意见分数(E-MOS)。
关键结果表格:
表2:零样本情感克隆任务的自然度MOS评估
| 系统 | 自然度 MOS |
|---|---|
| Ground Truth | 4.80 ± 0.08 |
| Proposed (Emotion Cloning) | 4.54 ± 0.18 |
| Baseline CosyVoice [12] | 4.36 ± 0.13 |
图3:零样本情感克隆任务的情感可懂度(E-MOS)评估
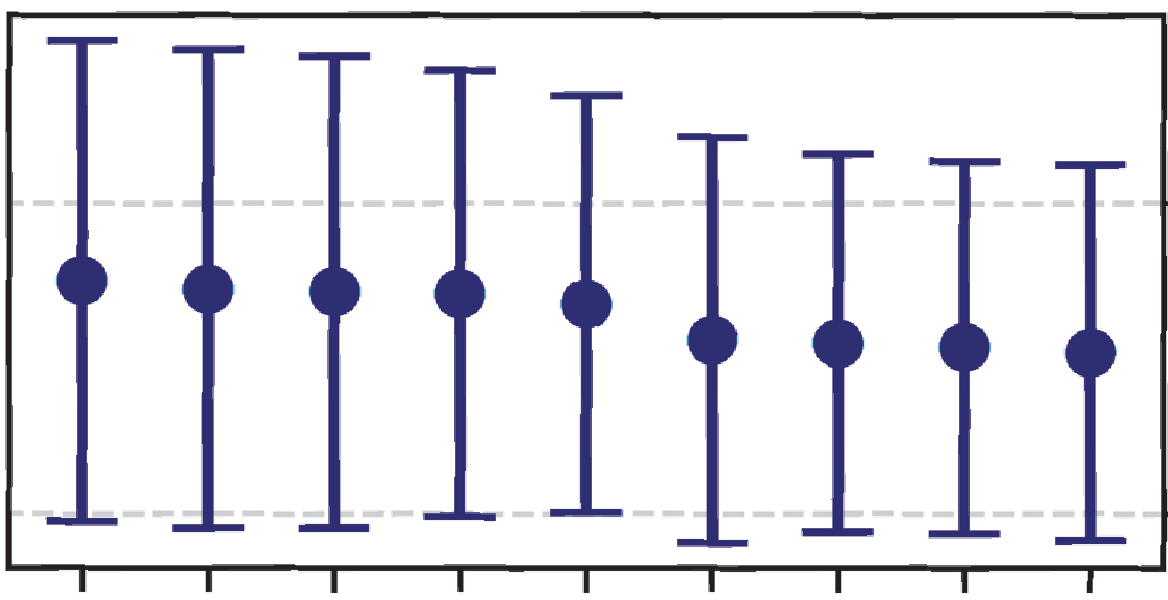 结论:在情感可懂度上,本方法在所有四种情感(生气、高兴、悲伤、惊喜)上的得分均高于CosyVoice基线,但低于在有情感数据上训练的MixedEmotion系统。
结论:在情感可懂度上,本方法在所有四种情感(生气、高兴、悲伤、惊喜)上的得分均高于CosyVoice基线,但低于在有情感数据上训练的MixedEmotion系统。
图2:合成语音的声学特征分析
 结论:兴奋、惊喜、高兴等高唤醒度情绪的音高和频谱通量值较高,悲伤、生气、中性等低唤醒度或抑制性情绪的值较低,与情感心理学理论预期一致。
结论:兴奋、惊喜、高兴等高唤醒度情绪的音高和频谱通量值较高,悲伤、生气、中性等低唤醒度或抑制性情绪的值较低,与情感心理学理论预期一致。
图4:XAB配对测试结果(评估情感可区分性)
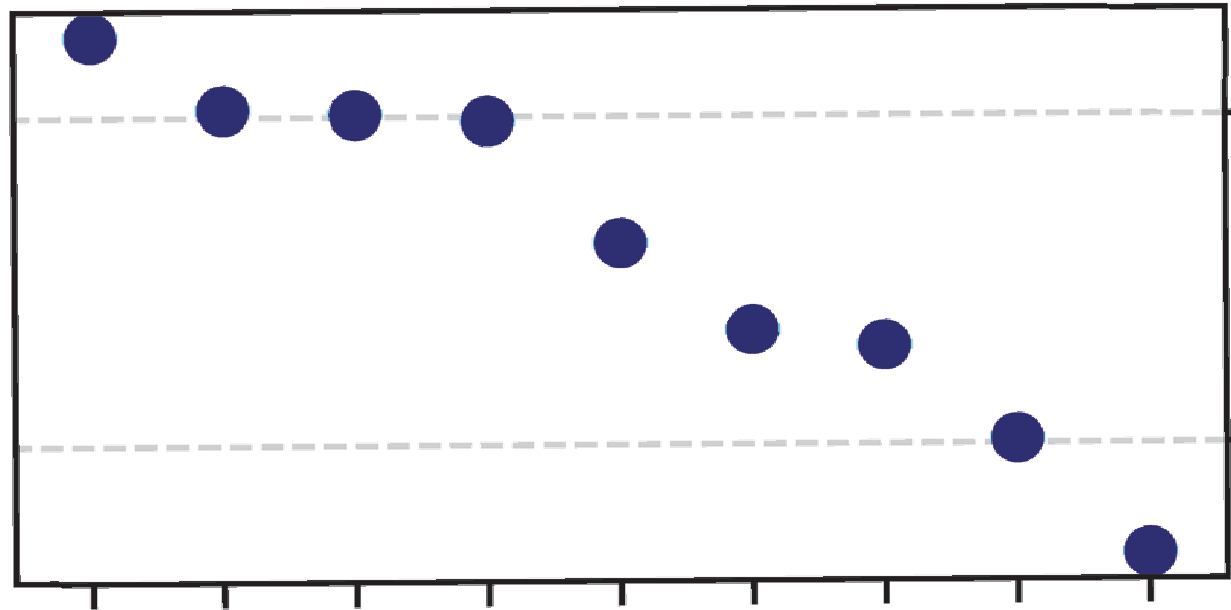 结论:系统能够较好地区分这些情感对,特别是“愤怒 vs 焦虑”对(正确率84%),这与“支配度”是区分它们的关键这一理论相吻合。
结论:系统能够较好地区分这些情感对,特别是“愤怒 vs 焦虑”对(正确率84%),这与“支配度”是区分它们的关键这一理论相吻合。
⚖️ 评分理由
- 学术质量:6.0/7:创新性明确,将心理学理论工程化应用于TTS控制是好的切入点。技术实现路径(ED预测器+LM-TTS)清晰合理。但实验深度不足:1) 与最相关且同样基于LM的强基线(如CosyVoice的情感扩展版本)对比缺失;2) 缺少对ED预测器本身精度、或ED向量连续控制有效性的消融实验(例如,固定其他条件,只改变ED向量观察输出变化);3) 客观评估更多是特性验证,缺乏与基线的直接量化对比。
- 选题价值:1.5/2:情感TTS是语音交互的核心前沿问题,本文提出的连续维度控制方案具有理论合理性和应用潜力,对领域发展有启发价值。
- 开源与复现加成:0.2/1:提供了演示页面和部分实现细节,但核心代码、预训练模型和详细配置未开源,复现门槛较高。