📄 EMORL-TTS: Reinforcement Learning for Fine-Grained Emotion Control in LLM-based TTS
#语音合成 #强化学习 #语音情感识别 #大语言模型
🔥 8.5/10 | 前25% | #语音合成 | #强化学习 | #语音情感识别 #大语言模型
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Haoxun Li(杭州高等研究院、中国科学院大学)
- 通讯作者:Taihao Li(杭州高等研究院、中国科学院大学)
- 作者列表:Haoxun Li(杭州高等研究院、中国科学院大学)、Yu Liu(未说明具体机构)、Yuqing Sun(未说明具体机构)、Hanlei Shi(未说明具体机构)、Leyuan Qu(未说明具体机构)、Taihao Li(杭州高等研究院、中国科学院大学)
💡 毒舌点评
亮点:本文创新性地将强化学习(GRPO)引入LLM-TTS,为解决其“离散Token难以表达连续情感”的痛点提供了优雅的框架,并首次实现了同时控制VAD全局强度和局部词强调,实验数据全面且显著优于基线。 短板:论文声称是“本地PDF”,但缺乏对代码和模型权重公开的明确承诺,严重阻碍了社区的复现与跟进;另外,对“惊讶”等少数情感的强调控制效果较弱,表明模型的泛化能力仍有提升空间。
🔗 开源详情
- 代码:论文中未提及代码链接。仅提供了一个Demo页面(https://wd-233.github.io/EMORL-TTS_DEMO/)。
- 模型权重:未提及是否公开模型权重。
- 数据集:使用的ESD和Expresso是公开数据集,但GRPO阶段构建的1000句带强调标注的文本语料未公开。
- Demo:提供了在线合成演示页面。
- 复现材料:论文详细描述了两阶段训练流程、损失函数、奖励设计公式和主要超参数,这为复现提供了较好的理论指导。但缺乏训练脚本、具体配置文件和模型检查点。
- 论文中引用的开源项目/工具:依赖的基座模型 Spark-TTS,情感识别模型 Emotion2vec,强制对齐工具 NeMo Forced Aligner,以及VAD预测器均为开源或已有工作。
📌 核心摘要
- 问题:基于大语言模型的语音合成系统虽能实现高质量零样本合成,但由于其依赖离散语音Token,难以实现对情感的细粒度控制(如连续强度、重点词强调)。
- 方法核心:提出EMORL-TTS框架,通过监督微调(SFT)与强化学习(GRPO)相结合的方式,统一建模全局情感强度(在VAD空间)与局部语音强调(通过音高和能量特征)。强化学习阶段使用三个任务特定奖励:情感分类准确性、全局VAD强度匹配度和局部强调清晰度。
- 创新点:a) 首次将VAD空间的全局情感强度控制引入LLM-TTS;b) 设计了基于韵律特征的局部强调控制机制;c) 构建了融合全局与局部控制的统一框架。
- 实验结果:实验表明,EMORL-TTS在情感准确性(目标与感知准确率均达0.88以上)、强度区分度(平均识别率0.71)和强调清晰度(平均准确率0.75)上均显著优于CosyVoice2、Emosphere++等强基线,同时MOS(4.94)和NISQA(4.11)分数与之相当,证明控制能力提升未牺牲合成质量。具体关键数据如下表所示:
表1:情感准确性客观评估(Emotion2vec准确率)
| 模型 | 平均 | 中性 | 生气 | 开心 | 悲伤 | 惊讶 |
|---|---|---|---|---|---|---|
| CosyVoice2 | 0.63 | 0.99 | 0.56 | 0.70 | 0.48 | 0.44 |
| EMORL-TTS w/o GRPO | 0.81 | 0.91 | 0.78 | 0.86 | 0.75 | 0.76 |
| Emosphere++ | 0.85 | 0.97 | 0.93 | 0.78 | 0.80 | 0.77 |
| EMORL-TTS | 0.88 | 0.99 | 0.93 | 0.91 | 0.78 | 0.81 |
表3:情感强度区分度主观评估(正确选择更强样本的比例)
| 情感 | 模型 | 弱<中 | 中<强 | 弱<强 |
|---|---|---|---|---|
| 生气 | Relative Attribute | 0.54 | 0.54 | 0.68 |
| Emosphere++ | 0.74 | 0.78 | 0.78 | |
| EMORL-TTS | 0.56 | 0.82 | 0.82 | |
| 平均 | Relative Attribute | 0.50 | 0.52 | 0.58 |
| Emosphere++ | 0.56 | 0.47 | 0.50 | |
| EMORL-TTS | 0.71 | 0.65 | 0.72 |
表5:语音质量评估
| 模型 | MOS (↑) | NISQA (↑) |
|---|---|---|
| Spark-TTS | 4.96 | 4.15 |
| CosyVoice2 | 4.96 | 4.14 |
| EMORL-TTS | 4.94 | 4.11 |
- 实际意义:该工作将LLM-TTS的可控性从类别推向了连续强度和局部韵律层面,为生成更自然、更具表现力的语音合成(如个性化对话、有声内容创作)奠定了技术基础。
- 主要局限性:a) 未开源代码与模型权重,可复现性存疑;b) 对部分情感(如惊讶)的强调控制效果有待提升;c) 强化学习训练依赖人工标注的强调文本,可能限制其在无标注场景的应用。
🏗️ 模型架构
EMORL-TTS的架构如图1所示,它建立在Spark-TTS基座上,主要包含文本/情感/强度标记器、大语言模型(LLM)和BiCodec解码器三个核心组件。
完整输入输出流程:
- 输入:文本序列
x、情感类别c(如“angry”)、离散化的全局强度级别r(“weak/medium/strong”)、以及可选的局部强调掩码m(标记哪些词需要被强调)。 - 序列化:情感类别和强度被转换为特殊的“控制Token”,与文本Token一起输入LLM。
- 自回归生成:LLM根据这些控制Token和文本Token,自回归地生成一串离散的语音Token序列
z。 - 解码:冻结的BiCodec解码器将语音Token序列转换为最终的波形
ŷ。
主要组件与功能:
- 标记器(Tokenizer):负责将输入文本、情感类别和强度级别转换为LLM能理解的离散Token。
- 大语言模型(LLM):整个系统的核心。它接受序列化的输入(文本+控制Token),并学习在给定控制条件下,输出最可能的语音Token序列。在后训练阶段,只有LLM的参数被更新。
- BiCodec解码器:一个预训练且被冻结的声码器,负责将离散的语音Token解码为连续的声波。它被选择是因为能同时编码全局声学特征和语义信息。
关键设计选择与动机:
- 冻结BiCodec:为了充分利用其强大的表达能力,并专注于提升LLM的可控性,避免在后训练中破坏其声学重建质量。
- 两阶段后训练(SFT + GRPO):
- SFT阶段:目的是让模型初步学会根据情感和强度Token生成对应情感的语音,为后续强化学习提供一个合理的起点。
- GRPO阶段:目的是利用强化学习,通过设计精细的奖励函数,让模型“隐式学习”如何在离散Token空间中实现连续的、细粒度的情感与强调控制,弥补SFT的不足。
 图1清晰展示了流程:文本、情感、强度Token输入LLM,生成语音Token,再由BiCodec解码。右侧显示了三个奖励信号(情感分类、全局强度、局部强调)如何通过GRPO优化LLM策略。
图1清晰展示了流程:文本、情感、强度Token输入LLM,生成语音Token,再由BiCodec解码。右侧显示了三个奖励信号(情感分类、全局强度、局部强调)如何通过GRPO优化LLM策略。
💡 核心创新点
首次在LLM-TTS中实现基于VAD的全局情感强度连续控制:
- 局限:此前LLM-TTS的情绪控制多限于离散类别标签,无法表达“多高兴”或“有些生气”这类连续强度。
- 如何起作用:方法将VAD(效价-唤醒度-支配度)空间的连续强度值离散化为“弱/中/强”三个Token,通过SFT训练模型接收该输入。在强化学习阶段,设计“全局强度奖励”,计算生成语音的VAD值到中性点的距离,并通过硬匹配+软高斯奖励的组合,引导模型生成与目标强度匹配的语音。
- 收益:使LLM-TTS具备了在VAD空间调节情感强度的能力,显著提升了情感表达的层次感。
设计基于韵律特征的局部强调控制机制:
- 局限:强调是情感表达的关键,但如何在离散Token生成中控制强调位置是个难题。
- 如何起作用:允许用户指定需要强调的词。系统通过强制对齐获得词边界,并提取这些词的基频(Pitch)和能量(Energy)特征。在强化学习阶段,设计“局部强调奖励”,通过硬匹配(强调词的特征是否为整句最高)和软匹配(强调词的特征相对整句均值的偏离程度)来鼓励模型在指定位置生成更突出的韵律。
- 收益:实现了词级别的强调可控性,增强了语音的局部表现力和情感聚焦。
构建统一的全局-局部细粒度控制框架:
- 局限:先前工作要么只做全局情感分类,要么只做局部韵律控制,缺乏统一。
- 如何起作用:将VAD强度控制(全局)和强调控制(局部)的输入与奖励机制整合到同一个SFT+GRPO训练框架中。模型同时接收全局强度Token和局部强调标记,并接受三个奖励信号的联合优化。
- 收益:模型能同时理解和执行多层次、多维度的情感控制指令,实现更精细、更自然的合成。
🔬 细节详述
- 训练数据:
- SFT阶段:使用两个英文情感语音数据集:1) ESD:10位说话人,5种情感(愤怒、快乐、悲伤、惊讶、中性),每人每情感约350句,总计约1.2小时/说话人。2) Expresso:选取其中情感标注子集,包含4717句(快乐、悲伤、默认/中性),部分样本带有强调标注。
- GRPO阶段:构建了一个仅文本的语料库,包含从互联网收集的1000句英文句子。关键:为每句话随机选择3个词进行强调标注,以模拟多样的强调模式。这些带标注的文本用于生成候选语音并计算奖励。
- 损失函数:
- SFT阶段:使用标准的Token级交叉熵损失,最小化模型预测Token序列与真实Token序列的差异。
- GRPO阶段:优化目标为最大化预期奖励。具体采用GRPO(Group Relative Policy Optimization)目标,如公式(3)所示。它包含两部分:a) 与基线策略(SFT策略)相比的优势项(由组内相对奖励计算);b) KL散度惩罚项,防止当前策略πθ偏离SFT策略pSFT太远,以保持生成质量。
- 训练策略:
- SFT:训练50个epoch,批大小16,学习率0.0002。
- GRPO:学习率1.0e-6,非常小以保证稳定。生成候选数K=16(每个提示生成16个候选语音),KL锚点权重β=0.1。
- 关键超参数:
- 强化学习中的生成候选数K=16。
- KL散度权重β=0.1。
- 强调奖励计算中,使用20ms窗口提取F0和STFT能量。
- 训练硬件:所有实验在8块NVIDIA RTX 4090 GPU上进行。论文未说明具体训练时长。
- 推理细节:论文未详细说明推理时的解码策略(如温度、beam search参数),推测与Spark-TTS基线类似。
- 正则化或稳定训练技巧:在GRPO目标中明确使用了KL散度约束,作为主要稳定训练的技巧,防止强化学习过程导致生成质量崩溃。
📊 实验结果
主要评估任务与指标:
- 情感准确性(EAT-EMO):客观(Emotion2vec分类准确率)和主观(人类感知识别率)。结果见表1(客观)和表2(主观)。EMORL-TTS在两项指标上均取得最高平均分(0.88和0.89),显著优于所有基线。
- 情感强度区分度(EIT):主观成对比较,判断弱、中、强哪一对更强。结果见表3。EMORL-TTS在“中<强”和“弱<强”的平均识别率上大幅领先(0.65 vs 次优0.52;0.72 vs 次优0.58)。
- 强调准确性(EAT):主观判断强调词位置是否正确。结果见表4。EMORL-TTS平均准确率0.75,与EME-TTS(0.73)相当,但显著高于CosyVoice2(0.35)。在“生气”情感上达到0.92的高准确率。
- 语音质量与自然度:客观(NISQA评分)和主观(MOS)。结果见表5。EMORL-TTS的MOS(4.94)和NISQA(4.11)与Spark-TTS、CosyVoice2等强基线几乎持平,证明强化学习未损害质量。
- 词性对强调效果的影响(POSET):新探索的实验。通过让听众对不同词性(副词、形容词、动词、名词等)被强调的语音进行情感强度排序,得出聚合分数。结果见图2。
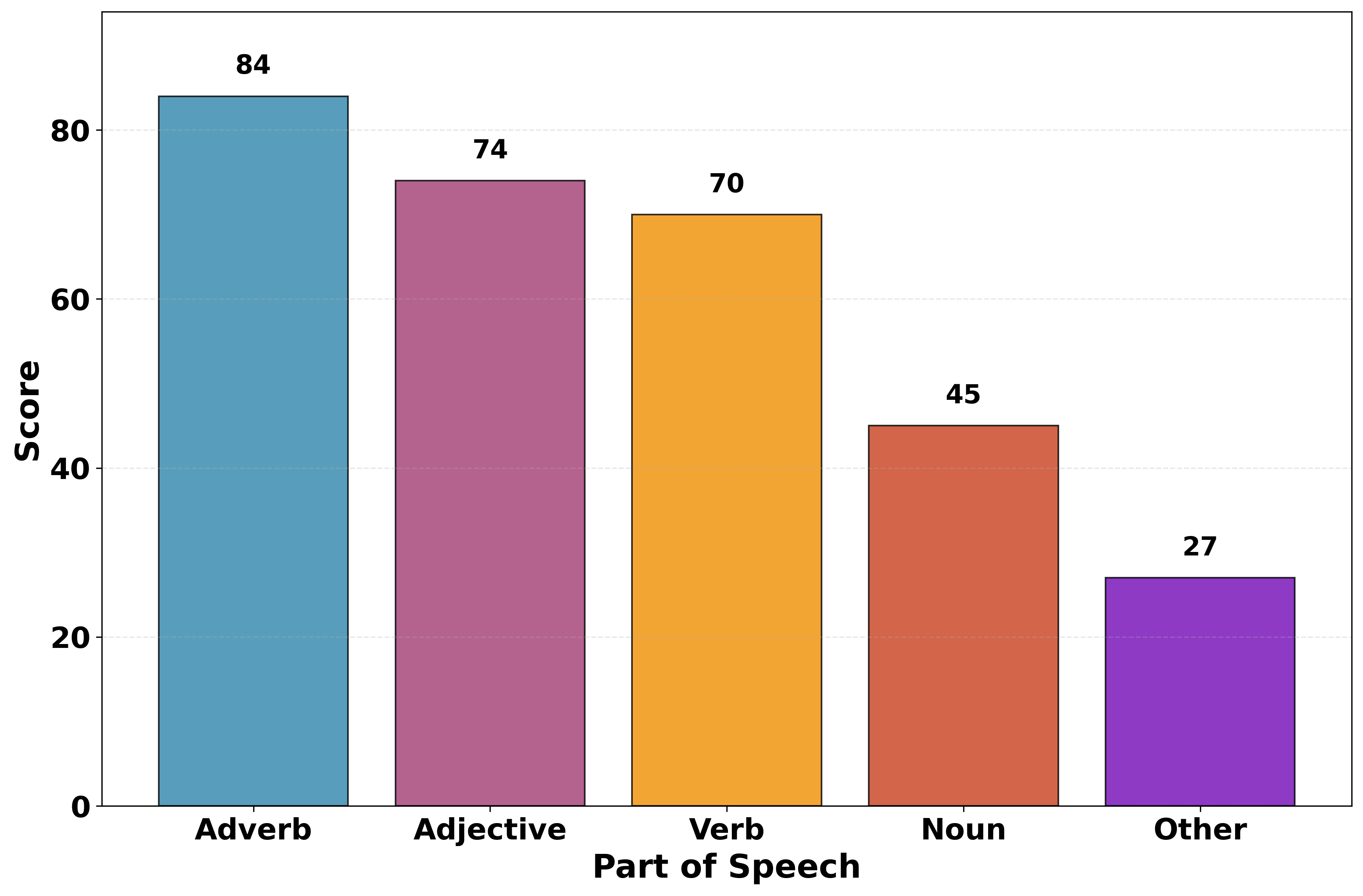 图2的关键结论:强调副词(Adverbs)产生的感知情感强��最强,其次是形容词(Adjectives),其他词类(动词、名词等)的效果相对较弱。这为通过强调特定词性来精细调节情感提供了实证依据。
图2的关键结论:强调副词(Adverbs)产生的感知情感强��最强,其次是形容词(Adjectives),其他词类(动词、名词等)的效果相对较弱。这为通过强调特定词性来精细调节情感提供了实证依据。
与最强基线的差距:
- 在情感准确性(主观)上,EMORL-TTS比最强基线Emosphere++高5个百分点(0.89 vs 0.84)。
- 在情感强度区分度(平均“弱<强”)上,EMORL-TTS比相对属性方法高14个百分点(0.72 vs 0.58),比Emosphere++高22个百分点(0.72 vs 0.50)。
- 在强调准确性上,与专门的EME-TTS接近,但EMORL-TTS同时具备了额外的情感强度控制能力。
关键消融实验:
- EMORL-TTS w/o GRPO:即仅进行SFT。与完整模型对比,所有控制指标(准确性、强度、强调)均有显著下降(例如情感主观准确率从0.89降至0.76),证明了强化学习阶段的必要性。
⚖️ 评分理由
- 学术质量:6.5/7。论文创新点清晰,解决了LLM-TTS中的一个关键痛点。技术方案(SFT+GRPO,复合奖励)设计合理且有充分实验验证。实验对比了多个最新基线,评估维度全面(客观/主观,质量/控制)。主要扣分点在于对BiCodec等前置技术的细节复述较少,且复现门槛因信息不完整而较高。
- 选题价值:1.8/2。情感控制的细粒度化是TTS领域的热点和难点,与LLM-TTS的结合具有前沿性和重要应用价值(如提升人机交互的情感自然度)。对语音合成、情感计算领域的研究者价值很高。
- 开源与复现加成:0.3/1。论文提供了可访问的Demo页面(是重要加分),但明确缺乏代码仓库和模型权重的公开信息。训练数据(特别是GRPO阶段的标注文本)和具体超参数虽有提及,但完整复现仍需大量工程努力,故加成有限。