📄 Efficient Audio-Visual Inference Via Token Clustering And Modality Fusion
#音频问答 #音视频 #多模态模型 #预训练 #模型评估
✅ 7.5/10 | 前25% | #音频问答 | #音频大模型 #多模态模型 | #音视频 #多模态模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Chenjie Pan(华南师范大学)
- 通讯作者:Chenyou Fan(华南师范大学)
- 作者列表:Chenjie Pan(华南师范大学)、Yi Zhu(华南师范大学)、Songkai Ning(华南师范大学)、Xiangyang Liu(华南师范大学)、Weiping Zheng(华南师范大学)、Chenyou Fan(华南师范大学)
💡 毒舌点评
亮点:论文精准地抓住了当前音视频LLM中音频模态token冗余这一关键痛点,提出的无参动态聚类压缩策略(ATCC)在大幅削减token数量(96%)和计算量(54%)的同时,性能不降反升,这证明其压缩确实保留了有效信息,而非简单丢弃。 短板:创新性更多体现在“组合”与“针对特定场景的优化”上,其核心的聚类算法和双向交叉注意力融合均为成熟技术的直接应用;此外,论文声称的性能提升幅度(0.6%-3.7%)相对有限,且绝对数值并未显著超越表中列出的所有最强基线(如PAVE在Music-AVQA上仍略高)。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开训练好的模型权重。
- 数据集:论文中使用了多个公开数据集(Music-AVQA, VGGSound, AVSD等),但未提供额外的数据处理或获取方式。
- Demo:未提供在线演示。
- 复现材料:论文提供了详细的模型架构描述、训练超参数(学习率、批次大小)、硬件环境(4x RTX 3090)以及算法伪代码(算法1),这些是重要的复现信息。但未提供完整的配置文件、检查点或更细致的训练日志。
- 论文中引用的开源项目:明确提到了作为基础架构的VideoLLaMA2,并引用了其使用的组件:视觉编码器SigLIP [22], 音频编码器BEATs [23], 以及语言模型Qwen2-7B [24]。也引用了LoRA [14]等训练技术。
📌 核心摘要
- 解决的问题:多模态大语言模型在处理音视频问答任务时,因音频和视觉token数量庞大导致计算和内存开销高,且现有的融合方法往往忽略了音频token的冗余问题,影响了效率和跨模态对齐效果。
- 方法核心:提出高效音视频推理框架(EAVI),包含两个核心组件:(1) 音频token聚类压缩(ATCC),通过动态阈值聚类在保留时序结构的前提下压缩音频token;(2) 双向模态融合模块,通过交叉注意力让压缩后的音频特征与视觉特征相互增强。
- 与已有方法的新颖之处:不同于以往工作主要压缩视觉token或进行简单拼接,EAVI首次专门针对音频模态设计了一种无需额外训练参数的动态聚类压缩方法,并引入了双向的跨模态注意力机制,使融合更加充分。
- 主要实验结果:在三个AVQA基准数据集上,EAVI相比强基线VideoLLaMA2,准确率提升了0.6%-3.7%。效率方面,音频token数量平均减少96%,总token减少66%,导致FLOPs降低54%,KV缓存使用减少65%,推理延迟降低15%。
- 主要对比结果:
模型 Music-AVQA VGGSound AVSD CREMA (2025) 75.6 67 - VideoLLaMA2 (2024) 80.9 71.4 57.2 PAVE (2025) 82.3 - 42.5 EAVI (Ours) 81.5 (+0.6) 75.1 (+3.7) 58.7 (+1.5) - 效率对比:
模型 Tokens (Audio / Total) FLOPs (T) Latency (S) KV cache (MB) VideoLLaMA2 1496 / 2172 40.3 1.13 120 EAVI (Ours) 66 / 742 15.4 0.96 42
- 主要对比结果:
- 实际意义:为在资源受限的设备上部署实时、高效的音视频问答模型提供了可行的技术路径,通过压缩减少了对计算和内存资源的需求。
- 主要局限性:聚类压缩可能导致细微语义信息的丢失;模型的最终性能仍强依赖于底层预训练的视觉和音频编码器;在对话理解(AVSD)等任务上的提升幅度相对较小。
🏗️ 模型架构
EAVI框架的整体架构如图2(左)所示。它建立在类似VideoLLaMA2的架构之上,主要改进了音频处理和跨模态融合部分。
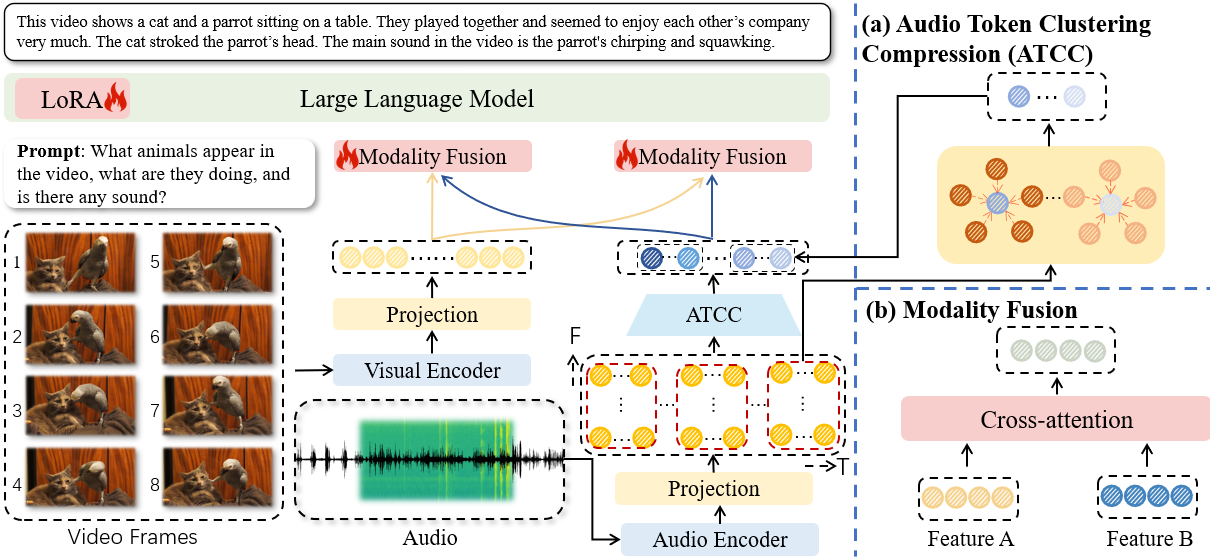
完整流程如下:
- 多模态编码:
- 视频流:从视频中均匀采样N帧,通过预训练的视觉编码器(SigLIP)提取视觉特征 $F_v \in \mathbb{R}^{L \times D}$。
- 音频流:将对齐的音频波形转换为频谱图,通过预训练的音频编码器(BEATs)提取音频特征 $F_a \in \mathbb{R}^{T \times F \times D}$。随后,通过模态特定的投影块将特征映射到文本嵌入空间。
- 音频Token聚类压缩(ATCC):这是第一个核心创新。如图2(a)所示,ATCC模块处理音频特征 $F_a$。它首先将音频特征沿时间维度分割成不重叠的块。在每个块内,使用基于阈值的动态聚类算法(算法1)将相似的token聚合,生成数量更少、但代表块内主要信息的聚类中心(即压缩后的音频token)。聚类阈值 $\lambda$ 由块内token对距离分布的指定分位数(默认中位数)确定,实现了动态压缩。
- 双向模态融合:如图2(b)所示,这是第二个核心创新。该模块接收压缩后的音频特征 $\tilde{F}_a$ 和视觉特征 $F_v$。它进行双向的交叉注意力:
- $\tilde{F}_v = CA(F_v, \tilde{F}_a)$:视觉特征关注音频特征。
- $\tilde{F}_a = CA(\tilde{F}_a, F_v)$:压缩后的音频特征关注视觉特征。 这使得两种模态能够双向地从对方学习互补信息。
- 答案生成:将融合后的视觉特征 $\tilde{F}_v$、音频特征 $\tilde{F}_a$ 以及文本问题嵌入 $Q$ 拼接起来,输入到大型语言模型(Qwen2-7B,使用LoRA进行微调)中,以自回归方式生成答案。
关键设计选择:
- 音频压缩优先:与多数工作压缩视觉token不同,该工作聚焦于音频token冗余,认为其在AVQA中被低估。
- 动态聚类:ATCC无需固定压缩率,能根据输入数据的相似性动态调整压缩后的token数量,更具适应性。
- 无参压缩:聚类过程本身不引入可学习参数,减少了额外开销。
- 双向融合:相比单向或简单拼接的融合,双向注意力能建立更深入的跨模态关联。
💡 核心创新点
基于聚类的音频Token压缩模块(ATCC):
- 是什么:一个针对音频特征的、无参数的动态压缩方法,通过在时间分块内进行阈值聚类来聚合相似token。
- 之前局限:现有压缩方法多针对视觉模态,或使用固定压缩比,或需要额外训练来选择重要token,难以平衡压缩率与信息保留。
- 如何起作用:利用音频信号在短时间内的连续性/相似性,将冗余token合并,同时保留时间块结构。阈值基于数据分布自适应确定。
- 收益:在VGGSound上将音频token从1496个压缩至平均66个(减少96%),大幅降低了后续注意力计算的复杂度,且性能提升。
双向跨模态融合模块:
- 是什么:一个使用双向交叉注意力的模块,让视觉和压缩后的音频特征相互查询、相互增强。
- 之前局限:早期工作(如Emotion-LLaMA)仅简单拼接token;后期工作(如MACAW-LLM)改进了对齐但忽略了输入冗余,融合不够深入。
- 如何起作用:通过双向注意力,视觉特征可以定位到音频中的关键事件,音频特征也能被视觉上下文所增强,形成更丰富的联合表示。
- 收益:消融实验显示,移除融合模块在VGGSound上导致2.2%的准确率下降,证明了其对提升跨模态理解的重要性。
高效且性能提升的音视频推理框架:
- 是什么:将ATCC和双向融合模块集成到一个端到端的框架中,用于音视频问答。
- 之前局限:现有高效模型(如VideoLLaMA2)在减少计算开销时,可能因压缩不当或融合不充分而损失性能。
- 如何起作用:通过先压缩再高效融合的流水线,实现了计算效率和表示质量的协同优化。
- 收益:在三个基准数据集上,EAVI相比基线VideoLLaMA2,在准确率提升0.6%-3.7%的同时,FLOPs降低54%,KV cache使用降低65%。
🔬 细节详述
- 训练数据:使用了五个数据集的训练集进行联合训练,包括Music-AVQA, VGGSound, AVSD, AVInstruct和AVQA。总规模为658.03K个问答对,其中632.32K用于训练,25.71K用于验证。
- 损失函数:采用标准的自回归交叉熵损失(公式3),优化模型在给定多模态上下文和历史答案下预测下一个答案token的概率。
- 训练策略:
- 更新策略:仅更新新增的双向融合模块(两个注意力层,约102.8M参数)和语言模型骨干网络中的LoRA适配参数(约330M参数)。视觉编码器、音频编码器和语言模型主体权重冻结。
- 优化器与学习率:未明确说明优化器类型,学习率设置为
2e-5。 - 批次大小与硬件:批次大小为64,在4块NVIDIA RTX 3090 GPU上进行训练。
- 训练轮数/步数:未说明。
- 关键超参数:
- 聚类阈值分位数
q:默认0.5,实验对比了0.3到0.7的范围。 - 模型骨架:视觉编码器为SigLIP,音频编码器为BEATs,语言模型为Qwen2-7B。
- 融合模块参数:102.8M。
- LoRA参数:330M。
- 聚类阈值分位数
- 训练硬件:4块 NVIDIA RTX 3090 GPU。训练总时长未说明。
- 推理细节:论文未具体说明解码策略(如温度、beam size)。
- 正则化或稳定训练技巧:未明确说明。使用了LoRA进行参数高效微调,这本身有助于稳定大模型的微调过程。
📊 实验结果
主要Benchmark对比: 论文在三个主流的音频-视觉问答基准数据集上进行了评估:Music-AVQA, VGGSound, 和 AVSD。主要结果已汇总在上方“核心摘要”的表格中。EAVI在所有三个基准上都超越了基线模型VideoLLaMA2,并在VGGSound上取得了显著提升(+3.7%)。与表中其他SOTA模型(如CREMA, PAVE)相比,EAVI表现具有竞争力。
消融实验: 论文进行了详细的组件消融实验,以验证每个模块的贡献,结果如下表所示:
| 模型变体 | Music-AVQA | VGGSound | AVSD |
|---|---|---|---|
| EAVI (完整) | 81.5 | 75.1 | 58.7 |
| w/o Fusion (去除融合) | 81.0 (-0.5) | 72.9 (-2.2) | 57.4 (-1.3) |
| w/o ATCC (去除压缩) | 80.5 (-1.0) | 74.8 (-0.3) | 57.9 (-0.8) |
| w/o LoRA (无微调) | 80.9 (-0.6) | 71.4 (-3.7) | 57.2 (-1.5) |
关键发现:去除融合模块(w/o Fusion)在VGGSound上导致最大性能下降(-2.2%),表明该数据集(声音事件识别为主)高度依赖音频-视觉的交互。去除压缩模块(w/o ATCC)在Music-AVQA上下降更明显(-1.0%),作者分析这是因为该数据集场景(如音乐演奏)内容稳定,冗余信息会导致融合模块产生均匀注意力,难以建立判别性关联。
聚类阈值分析:
论文分析了聚类阈值分位数 q 对性能的影响(表3),发现 q=0.5(中位数)通常能取得最好的性能与效率平衡。
效率分析: 效率对比结果已在“核心摘要”表格中列出。EAVI通过ATCC将音频token压缩至平均66个,使得总token数减少66%,进而带来FLOPs减少54%,KV缓存使用减少65%,以及15%的延迟降低。
案例研究:
图3展示了一个案例,说明双向融合模块如何工作。
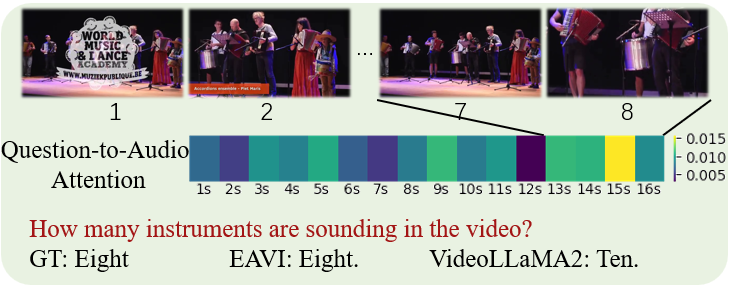 对于问题“有多少音乐家?”,模型的注意力(question-to-audio)聚焦于13-16秒的音频片段。通过回溯融合模块,发现该音频片段主要关注了对应时间段的视频帧(包含8位演奏者)。EAVI成功将这4秒的音频特征与对应的视频帧融合,从而关注到正确的视觉信息并回答“Eight”。而基线模型VideoLLaMA2则过度关注第一帧,错误地预测了“Ten”。这直观地展示了双向融合在定位关键时序信息上的有效性。
对于问题“有多少音乐家?”,模型的注意力(question-to-audio)聚焦于13-16秒的音频片段。通过回溯融合模块,发现该音频片段主要关注了对应时间段的视频帧(包含8位演奏者)。EAVI成功将这4秒的音频特征与对应的视频帧融合,从而关注到正确的视觉信息并回答“Eight”。而基线模型VideoLLaMA2则过度关注第一帧,错误地预测了“Ten”。这直观地展示了双向融合在定位关键时序信息上的有效性。
⚖️ 评分理由
- 学术质量 (6.0/7):论文在解决具体技术问题(音频token冗余)上思路清晰,ATCC和双向融合模块设计合理且有效。实验设计全面,包含了基准对比、消融分析、阈值敏感性分析和效率分析,提供了充分的证据支持其结论。主要扣分点在于,其核心算法(��类、交叉注意力)并非原创,创新更多体现在组合与应用上;另外,部分实验对比(如与PAVE在Music-AVQA上)并未取得绝对领先。
- 选题价值 (1.5/2):选题直指多模态大模型落地的高墙——效率问题,具有很强的现实意义。在音频模态压缩方面进行专门探索,填补了该领域的一部分空白,对音视频理解、实时交互等应用有直接价值。扣分点在于,该问题属于模型优化范畴,其普适性和影响力可能不如提出全新任务或基础架构的工作。
- 开源与复现加成 (0/1):论文提供了丰富的训练设置细节(模型架构、部分超参数、硬件),这为复现提供了基础。然而,它没有提供代码、预训练权重或任何可直接使用的资源,也未承诺未来开源,因此无法给予加分。