📄 EEND-SAA: Enrollment-Less Main Speaker Voice Activity Detection Using Self-Attention Attractors
#语音活动检测 #端到端 #说话人分离 #流式处理
✅ 7.5/10 | 前25% | #语音活动检测 | #端到端 | #说话人分离 #流式处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文按顺序列出 Wen-Yung Wu, Pei-Chin Hsieh, Tai-Shih Chi,但未明确标注)
- 通讯作者:未说明(论文中未提供邮箱或标注通讯作者)
- 作者列表:Wen-Yung Wu(台湾阳明交通大学电气与计算机工程系),Pei-Chin Hsieh(台湾阳明交通大学电气与计算机工程系),Tai-Shih Chi(台湾阳明交通大学电气与计算机工程系)
💡 毒舌点评
亮点在于明确提出了“无注册主说话人VAD”这个在实际场景中更可行的任务定义,并通过设计双吸引子机制巧妙地将其融入端到端框架,实现了对背景说话人的抑制。短板在于,该工作的创新主要是对现有EEND架构的“改造”和“特化”,而非提出全新的、更强大的主说话人检测范式,且缺乏开源的模型权重和完整代码,限制了社区的快速跟进与验证。
🔗 开源详情
- 代码:论文中提供了一个数据生成脚本的GitHub仓库链接:https://github.com/UaenaSone-William/EEND-VAD。但论文中未明确说明是否提供模型推理或训练的完整代码。
- 模型权重:论文中未提及公开任何预训练模型权重。
- 数据集:训练数据使用公开的LibriSpeech、MUSAN语料库以及RIR模拟生成。合成脚本已提供(见上)。
- Demo:论文中未提及提供在线演示。
- 复现材料:论文详细给出了模型架构参数、训练超参数(学习率、batch size、epoch等)和数据生成方案,为复现提供了文本基础。但缺乏硬件环境、训练时长等关键信息。
- 论文中引用的开源项目:EEND [16], SA-EEND [18], EEND-EDA [20], MUSAN [21]。
- 整体开源情况:论文提供了部分复现线索(数据脚本和参数),但未承诺提供核心模型代码和权重,属于有限开源。
📌 核心摘要
- 问题:传统VAD仅检测有无语音,目标说话人VAD(TS-VAD)虽能检测特定说话人但依赖预先注册语音,这在会议、客服等开放场景中不实用。论文旨在解决“无注册主说话人VAD(MS-VAD)”问题,即在未知说话人和存在背景干扰的场景下,仅凭语音的连续性和音量等线索,实时识别出主要说话人的活动。
- 方法核心:提出EEND-SAA框架。该框架在SA-EEND(基于Transformer的端到端神经说话人日志化)基础上进行扩展,核心创新是引入双自注意力吸引子(Dual Self-Attention Attractors)模块。该模块将Transformer的注意力头分为两组,分别专注于生成主说话人和背景说话人的吸引子表征,通过比较这些吸引子与帧级嵌入来输出说话人活动概率。同时,通过因果掩码和键值缓存实现流式处理。
- 新意:相较于TS-VAD,本方法无需注册语音;相较于SA-EEND等说话人日志化方法,本方法直接输出“主说话人”标签而非所有说话人标签,且通过双吸引子设计增强了主/背景说话人的区分度,并具备了实时处理能力。
- 主要实验结果:在合成的多说话人LibriSpeech混合数据集上,EEND-SAA(双吸引子)将主说话人DER(DERmain)从SA-EEND基线的6.63%降至3.61%,主说话人F1(F1main)从0.9667提升至0.9818。关键对比结果如表3所示:
| 模型 | DER (%) | DERmain (%) | F1main |
|---|---|---|---|
| SA-EEND [18] (w/ main speaker labels) | N/A | 6.63 | 0.9667 |
| EEND-SAA (dual) | 7.46 | 3.61 | 0.9818 |
- 实际意义:为会议记录、实时转录、智能助手等需要区分主要发言人的应用场景,提供了一种无需预先登记、可实时运行的语音活动检测解决方案。
- 主要局限性:模型性能高度依赖于主说话人相对于背景说话人的“连续性”和“音量”优势(如实验部分所示),在主说话人语音断续或背景音量较大时性能会下降;合成数据与真实复杂场景可能存在差距;未提供开源模型权重和完整代码。
🏗️ 模型架构
EEND-SAA的整体架构如图1所示,是一个端到端的流式处理框架。
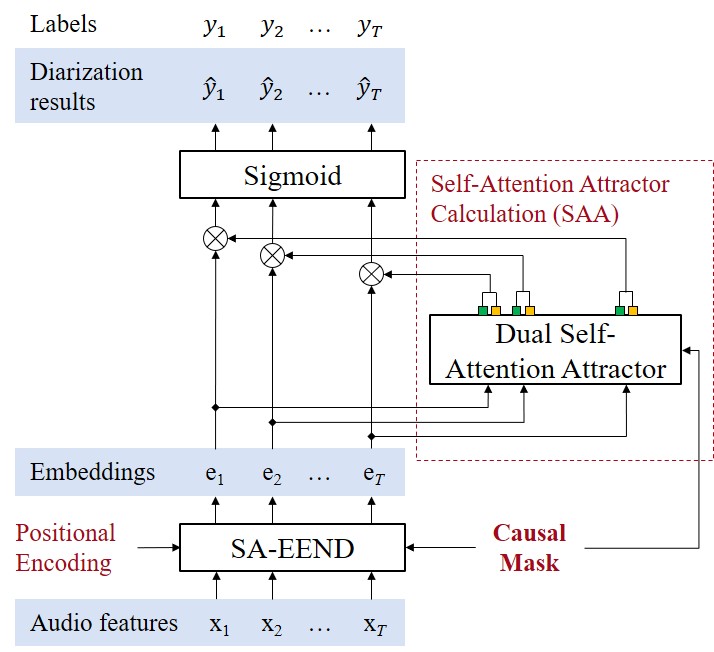
模型主要由三个模块串联组成:
- EEND编码器:输入为对数梅尔频谱图。经过子采样和帧拼接后,送入一个四层Transformer编码器。与原始SA-EEND不同,本模型加入了正弦位置编码,这为模型提供了时序位置信息,对于捕捉主说话人语音的“连续性”这一关键特征至关重要。编码器输出一个大小为
T x D的说话人感知嵌入序列。 - 自注意力吸引子(SAA)模块:这是本论文的核心创新模块。它接收编码器的输出嵌入。SAA模块内部使用一个自注意力层(在双吸引子版本中,注意力头数为8,被分成两组)。通过时间维度平均,分别生成两个吸引子向量:一个主说话人吸引子
A_main,一个背景说话人吸引子A_others。这两个吸引子可以理解为对“主说话人典型嵌入”和“背景说话人典型嵌入”的动态表征。 - 帧级说话人活动输出模块:将编码器输出的嵌入序列
E与SAA模块生成的吸引子A(A是一个2 x D的矩阵)进行点积,再通过sigmoid激活函数,得到一个T x 2的概率矩阵Ŷ。每一行对应一个时间帧,两个值分别表示该帧属于主说话人和背景说话人的概率。
数据流与交互:输入谱图 -> 编码器(生成帧级嵌入) -> SAA模块(生成双吸引子) -> 逐帧与吸引子计算相似度 -> 输出主/背景说话人活动概率。
关键设计选择与动机:
- 双吸引子设计:动机是强制模型在表示学习阶段就区分开主说话人和背景说话人,通过对比学习提升区分度。
- 位置编码:动机是为主说话人的“连续性”这一先验知识提供显式的时序位置线索。
- 因果掩码与KV缓存(流式部分):在推理时,对Transformer和SAA模块应用因果掩码,确保预测仅依赖当前和历史帧。SAA模块改为逐帧生成吸引子并与当前帧比较,而非时间平均。配合键值缓存,实现低延迟的流式推理。
💡 核心创新点
- 无注册的主说话人VAD任务定义与建模:明确提出了一个更贴合实际需求的子任务(MS-VAD),并给出了一个完整的、端到端的解决方案,摆脱了对注册语音的依赖。
- 双自注意力吸引子机制:创新性地将EEND-EDA中的吸引子概念与Transformer的自注意力机制结合,并设计双吸引子结构,使其能够同时学习并区分“主说话人”和“背景说话人”的表征,从而直接输出主说话人标签,而非所有说话人标签。
- 适应流式处理的因果架构与训练策略:通过应用因果掩码和设计“因果感知标签”(即在训练时模拟主说话人晚出现的情况,并临时标注),使模型能够适应实时处理的需求,同时解决了背景说话人先于主说话人出现时的标签分配难题。
🔬 细节详述
- 训练数据:使用LibriSpeech(train-clean-360)的921个说话人,合成100k个15秒的训练样本。每个样本由2-4个说话人混合,随机指定一个为主说话人。背景说话人遵循预设的语音/静音比例配置(M0,B1-B4)。背景音量进行随机缩放([0.1, 0.4], [0.2, 0.8], 1.0)。并加入MUSAN噪声和随机房间脉冲响应(RIR)增强鲁棒性。验证和测试集各1k样本,来自dev-clean和test-clean。
- 损失函数:加权二元交叉熵损失
L_BCE = L_main + α * L_others。L_main和L_others分别是主说话人和背景说话人的BCE损失。α是控制二者贡献的权重因子。论文中未明确给出α的具体值。 - 训练策略:训练100个epoch,批大小64。使用Adam优化器和Noam学习率调度器。学习率公式为
lr = d_model^{-0.5} min(step_num^{-0.5}, step_num warmup_steps^{-1.5}),其中d_model=256,warmup_steps=100k。 - 关键超参数:
- 输入特征:25ms窗长,10ms帧移,23维梅尔滤波器组,下采样每3帧,拼接前后各3帧。
- EEND编码器:4层Transformer,4个注意力头,嵌入维度256,前馈网络维度2048,dropout率0.1。
- SAA模块(单吸引子):1层自注意力,4个头。双吸引子版本:1层自注意力,8个头(分两组)。
- 训练硬件:论文中未提及。
- 推理细节:采用因果掩码进行流式推理。SAA模块改为逐帧更新吸引子,并使用键值缓存加速计算。
- 正则化或稳定训练技巧:使用了Noam学习率调度(warmup)以稳定训练;使用了dropout(0.1);在数据生成中加入了多种增强(音量、噪声、混响)。
📊 实验结果
主要实验在合成的多说话人LibriSpeech数据集上进行。
- 模型架构对比(表3): 在统一的背景配置(B2,音量0.2-0.8,2-4说话人)下,对比了不同模型变体。
| 模型 | DER (%) | DERmain (%) | F1main |
|---|---|---|---|
| SA-EEND [18] (w/ 2–4 speakers labels) | 25.84 | 11.44 | 0.9412 |
| SA-EEND [18] (w/ main speaker labels) | N/A | 6.63 | 0.9667 |
| EEND-SAA (single) | N/A | 4.21 | 0.9788 |
| EEND-SAA (dual) | 7.46 | 3.61 | 0.9818 |
| 结论:使用主说话人标签训练SA-EEND能大幅降低DERmain。而EEND-SAA(双吸引子)在所有主说话人指标上均取得了最佳性能。 |
- 不同语音活动比例的影响(表4): 测试了在固定背景音量(1.0或0.2-0.8)下,不同背景说话人活跃度(M0-B4)的影响。
| 说话配置 | DER (%) | DERmain (%) | F1main |
|---|---|---|---|
| M0 (持续语音) | 13.52 / 9.12 | 18.53 / 8.38 | 0.9063 / 0.9582 |
| B1 (40%语音) | 8.46 / 8.83 | 5.84 / 3.40 | 0.9707 / 0.9828 |
| B2 (50%语音) | 7.50 / 7.46 | 5.92 / 3.61 | 0.9702 / 0.9818 |
| B3 (62.5%语音) | 6.89 / 7.20 | 7.33 / 3.99 | 0.9634 / 0.9799 |
| B4 (83.3%语音) | 6.49 / 6.17 | 8.42 / 4.35 | 0.9579 / 0.9781 |
| 注:斜杠前为背景音量1.0的结果,斜杠后为背景音量0.2-0.8的结果。 | |||
| 结论:当背景说话人持续说话(M0)且音量大时,主说话人检测最困难。随着背景说话人变得更间歇(B1-B4)或音量变低,F1main显著提升,证明模型能有效利用连续性线索。 |
- 背景音量的影响(表5): 在固定说话模式(M0或B2)下,测试背景音量的影响。
| 音量缩放 | DER (%) | DERmain (%) | F1main |
|---|---|---|---|
| 0.1-0.4 | 10.43 / 8.99 | 5.39 / 2.51 | 0.9729 / 0.9873 |
| 0.2-0.8 | 9.12 / 7.46 | 8.38 / 3.61 | 0.9582 / 0.9818 |
| 1 | 13.52 / 7.50 | 18.53 / 5.92 | 0.9063 / 0.9702 |
| 注:斜杠前为M0配置的结果,斜杠后为B2配置的结果。 | |||
| 结论:降低背景音量能显著提升主说话人检测性能(F1main↑,DERmain↓)。 |
- 因果模型验证(表6): 验证了流式模型在匹配和不匹配数据上的表现。
| 模型 | 因果 | 数据类型 | DER (%) | DERmain (%) | F1main |
|---|---|---|---|---|---|
| Dual SAA | No | No | 7.46 | 3.61 | 0.9818 |
| Dual SAA w/ causal | No | No | 11.34 | 10.39 | 0.9512 |
| Dual SAA w/ causal | Yes | Yes | 8.17 | 3.28 | 0.9835 |
| 结论:在非因果数据上使用因果模型会导致性能严重下降。采用专门设计的因果标签训练因果模型后,性能甚至略优于非因果模型,证明了流式方案的可行性。 |
- 位置编码消融(表7):
模型 DER (%) DERmain (%) F1 EEND-SAA w/ pos 7.46 3.61 0.9818 EEND-SAA w/o pos 10.51 7.45 0.9626 结论:位置编码对模型性能至关重要,移除后DER和DERmain大幅上升,F1下降。
⚖️ 评分理由
- 学术质量:6.0/7 - 论文创新性地定义了实用的子任务(MS-VAD),并提出了针对性的模型架构(双SAA)。技术路线正确,实验设计较充分,包含了与多种基线的对比、不同条件的鲁棒性分析以及关键组件的消融研究,证据可信。扣分点在于,核心贡献是对EEND架构的改造和特化,而非提出全新的技术原理。
- 选题价值:1.5/2 - 解决了无注册主说话人检测这一实际痛点,对会议、人机交互等应用有直接价值。问题定义清晰,具有前沿性和应用潜力。但对于非语音专业听众,其影响力可能不如ASR、TTS等通用任务广泛。
- 开源与复现加成��0.0/1 - 论文仅提供了一个数据生成脚本的GitHub链接(https://github.com/UaenaSone-William/EEND-VAD)。核心的模型代码、训练好的权重、详细的训练配置(如GPU型号、训练时间)均未公开。这严重限制了其他研究者快速复现和在其基础上进行改进的可能性,因此复现加分为0。