📄 EEG and Eye-Tracking Driven Dynamic Target Speaker Extraction with Spontaneous Attention Switching
#语音分离 #多模态模型 #多任务学习 #生物声学 #数据集
✅ 7.0/10 | 前25% | #语音分离 | #多模态模型 | #多任务学习 #生物声学
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Xuefei Wang(南方科技大学电子与电气工程系)
- 通讯作者:Fei Chen(南方科技大学电子与电气工程系)
- 作者列表:Xuefei Wang(南方科技大学电子与电气工程系)、Ximin Chen(南方科技大学电子与电气工程系)、Yuting Ding(南方科技大学电子与电气工程系)、Yueting Ban(南方科技大学电子与电气工程系)、Siyu Yu(南方科技大学电子与电气工程系)、Yu Tsao(台湾中研院资讯科技创新研究中心)、Fei Chen(南方科技大学电子与电气工程系)
💡 毒舌点评
这篇论文首次将EEG引导的目标说话人提取问题从静态场景拓展到更符合真实情况的动态注意力切换场景,并为此构建了一个完整的多模态框架,这是其最大亮点;然而,实验仅在参与者数量有限(18人)的自建数据集上进行,且代码与模型未完全开源,极大限制了其结论的普适性与可复现性。
🔗 开源详情
- 代码:论文中未提及代码链接。数据集链接(https://github.com/XXuefeii/AASD)中可能包含部分代码,但论文正文未说明。
- 模型权重:未提及。
- 数据集:是。提供了专门的数据集仓库链接(https://github.com/XXuefeii/AASD),包含EEG和眼动数据。
- Demo:未提及。
- 复现材料:论文提供了部分训练超参数(Adam优化器,lr=1e-4, batch size=16),但未提供完整的训练脚本、配置文件或检查点。代码和完整复现指南缺失。
- 论文中引用的开源项目:论文中提到了使用预训练的Wav2vec2.0模型[17]和基于Conv-TasNet[16]的架构。
📌 核心摘要
- 要解决什么问题? 论文旨在解决现有EEG引导的目标说话人提取(TSE)方法通常假设听众注意力静态不变,无法处理现实多说话人环境中听众自发在不同说话人之间切换注意力的动态场景。
- 方法核心是什么? 提出了一个多模态动态注意力TSE网络(MDATNet),其核心是:(a) 利用EEG和平均注视坐标(眼动)联合解码注意力是否发生切换;(b) 引入一个动态更新单元,当检测到注意力切换时重置历史信息,否则融合历史语音特征,以保持对同一目标说话人跟踪的连续性。
- 与已有方法相比新在哪里? 与之前仅基于EEG或假设静态注意力的方法(如BASEN, NeuroHeed等)相比,本文方法首次明确建模并处理了“注意力切换”这一动态过程,通过引入眼动先验和动态历史语音记忆机制,实现了更自适应、更符合认知过程的提取。
- 主要实验结果如何? 在自建的EEG自发注意力切换数据集上,MDATNet在所有指标上显著优于基线方法。相比最强的M3ANet,SDR提升了1.77 dB,STOI提升了3.99%。消融实验表明,眼动信息和动态更新单元分别带来了显著的性能提升,二者结合达到最佳效果(SDR 8.79 dB, STOI 88.17%)。
- 实际意义是什么? 该研究推动了脑机接口(BCI)与语音处理的交叉领域发展,为开发未来能更自然理解并跟随用户注意力焦点的助听器、耳机或人机交互系统提供了技术路径。
- 主要局限性是什么? 主要局限性在于实验数据集规模有限(18位被试,18小时数据),且均为特定实验室环境下的受控数据,跨被试泛化能力、在复杂声学场景(如背景噪音、混响)下的鲁棒性尚未得到充分验证。
🏗️ 模型架构
论文提出了一个名为MDATNet(Multimodal and Dynamic Attention Target Net)的端到端神经网络框架,整体架构见图1。
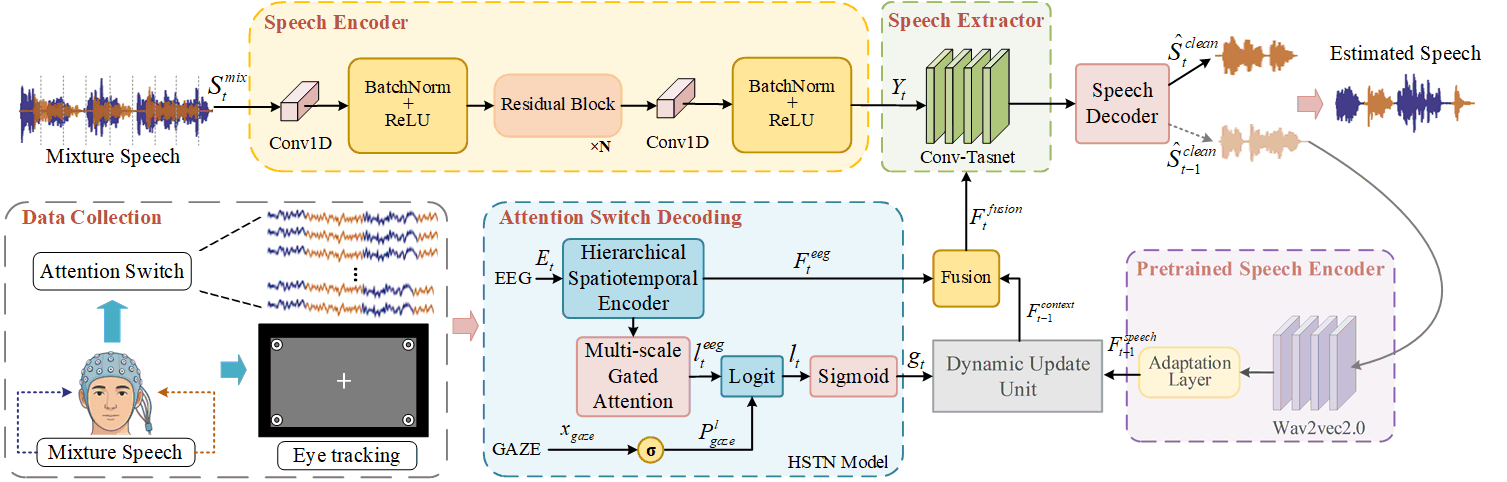
该框架由五个核心模块组成,处理流程如下:
- 语音编码器:输入混合语音信号
Smix_t,通过一个包含残差块和批归一化的1D CNN,将其转换为高维特征表示Y_t。这为后续分离提供了基础。 - 注意力切换解码模块:这是系统的“大脑”。它接收原始EEG信号
Et,通过一个分层时空网络(HSTN) 提取特征F_eeg_t。同时,引入眼动引导:将平均注视坐标Gt转换为一个先验概率p_gaze,并将其作为偏置(bias)加到EEG解码得到的logit上(公式4-5),得到一个注意力门控值gt。gt > 0.5表示检测到注意力发生切换。 - 动态更新单元:这是处理“动态”特性的关键。它根据注意力切换信号
gt决定如何利用历史信息:- 如果
gt > 0.5(发生切换),则清空历史上下文F_context_{t-1}(设为空)。 - 如果
gt <= 0.5(未切换),则使用上一时刻提取的语音经Wav2vec2.0编码得到的特征F_speech_{t-1}作为历史上下文(公式7)。随后,将F_eeg_t与F_context_{t-1}进行多模态融合,得到引导特征F_fusion_t(公式8)。
- 如果
- 语音提取器:基于Conv-TasNet架构,接收编码后的混合语音特征
Y_t和来自注意力模块的引导特征F_fusion_t,通过学习时频掩膜,输出目标语音的表示。 - 语音解码器:将提取器输出的表示解码为时域波形
Ŝclean_t,作为最终输出。该输出还会被送回动态更新单元,用于下一时刻的上下文提取,形成闭环。
关键设计选择与动机:
- 眼动作为EEG的补充:利用眼动坐标为EEG解码提供显式的空间先验,弥补EEG空间分辨率低的缺点。
- 动态记忆重置:模拟人类注意力切换时,对新目标的“重新聚焦”过程,摒弃可能误导的旧目标语音特征。
- 两阶段训练:先预训练编码器(如HSTN和Wav2vec2.0),再端到端联合训练整个框架,确保各模块有效协同。
💡 核心创新点
- 针对动态注意力切换的建模与解码:是什么:首次在EEG引导的TSE任务中,明确提出并建模“自发注意力切换”现象。局限:以往工作多假设听众注意力静态,或仅做注意力存在/不存在的二分类,忽略了切换这一动态过程。如何起作用:通过融合EEG和眼动信号,直接解码一个连续的注意力门控值
gt来指示切换。收益:使系统能够感知听众注意力的实时转移,为动态提取提供准确的触发信号。 - 基于注意力状态的动态历史语音更新机制:是什么:一个根据注意力切换信号动态决定是否保留并利用上一时刻语音特征的模块。局限:先前方法要么完全忽略历史语音信息,要么无差别地使用所有历史信息,这在注意力切换后可能引入干扰。如何起作用:当注意力未切换时,融合历史语音特征(来自Wav2vec2.0)以增强当前目标的时序连续性;当检测到切换时,清空历史信息,避免将旧目标的语音特征用于新目标的提取。收益:在维持稳定跟踪和实现快速自适应切换之间取得了平衡,提升了在动态场景下的鲁棒性。
- 整合EEG、眼动与历史语音的多模态、动态神经引导框架:是什么:一个完整的、端到端的系统,集成了三种模态/信息源来解决动态TSE问题。局限:早期方法要么仅用EEG,要么将EEG与其他模态(如唇动)静态融合,缺乏对动态变化的适应性。如何起作用:将EEG(神经注意力)、眼动(空间线索)和历史语音(声学一致性)在特征层面进行动态融合,共同指导语音分离。收益:实现了更全面、更符合认知过程的注意力状态表征,显著提升了动态场景下的分离性能(SDR 8.79 dB)。
🔬 细节详述
- 训练数据:
- 数据集:论文自建的“EEG-based spontaneous attention switching dataset”。参与者为18名健康中国成年人,年龄18-27岁。
- 来源:语音刺激来自AISHELL语料库(3男3女),在左右声道(+/-90°)同时播放。
- 规模:每位参与者完成60个试次(6个区块,每个区块10个试次,每个试次60秒)。共采集18小时的EEG(64导,500Hz采样)和眼动数据。
- 预处理:EEG经过伪迹去除、降采样至128Hz、0.1-45Hz带通滤波。眼动数据为平均注视坐标。数据已开源:https://github.com/XXuefeii/AASD。
- 数据增强:论文中未提及。
- 损失函数:论文中未明确说明损失函数具体形式。通常此类任务会使用SI-SNR(尺度不变信噪比)损失。
- 训练策略:
- 优化器:Adam优化器。
- 学习率:1e-4。
- Batch Size:16。
- 训练硬件:NVIDIA V100 GPU。
- 训练阶段:采用两阶段训练:第一阶段预训练Wav2vec2.0和HSTN编码器;第二阶段使用多模态自发注意力切换数据联合训练整个框架。
- 其他:未提及warmup、训练轮数/步数、学习率调度策略。
- 关键超参数:
- 模型架构:语音编码器/提取器基于Conv-TasNet。注意力解码使用HSTN。
- 眼动融合参数:公式4中的敏感度参数
κ和公式5中的融合权重α,论文未给出具体数值。 - 其他模型维度(如特征维度D、EEG通道数C等):未说明。
- 推理细节:论文未详细说明推理过程的特殊设置(如流式处理、解码策略等)。从架构看,应是逐块处理。
- 正则化或稳定训练技巧:论文未提及。
📊 实验结果
论文在自建数据集上进行了实验,与多种基线模型进行了比较,并进行了消融研究。
表1:与主流模型的对比(数据集:EEG-based spontaneous attention switching dataset)
| 模型 (方法) | SDR (dB) | SI-SDR (dB) | STOI (%) | ESTOI (%) |
|---|---|---|---|---|
| BASEN [22] | 4.32 | 3.72 | 74.93 | 60.40 |
| NeuroHeed [12] | 5.44 | 4.95 | 79.61 | 65.82 |
| NeuroSpex+ [23] | 6.65 | 6.10 | 82.77 | 69.90 |
| M3ANet [24] | 7.02 | 6.61 | 84.18 | 71.84 |
| MDATNet (ours) | 8.79 | 8.63 | 88.17 | 79.31 |
关键结论:所提出的MDATNet在所有指标上均显著优于现有方法。相比最强的基线M3ANet,在SDR、SI-SDR、STOI和ESTOI上分别取得了1.77 dB、2.02 dB、3.99%和7.47%的绝对提升。
表2:消融实验结果(数据集:EEG-based spontaneous attention switching dataset)
| 模型变体 | STOI (%) | ESTOI (%) |
|---|---|---|
| MDATNet (w/o ET, w/o DU) | 78.46 | 65.34 |
| MDATNet (w/ ET, w/o DU) | 81.25 | 68.92 |
| MDATNet (w/o ET, w/ DU) | 84.27 | 72.81 |
| MDATNet (Full Model) | 88.17 | 79.31 |
关键结论:加入眼动(ET)模块和动态更新(DU)单元均能带来性能提升,且动态更新单元的增益更大。两者结合(完整模型)达到最佳性能,证明了这两个组件的有效性及其互补性。论文指出所有提升均具有统计显著性(p-value < 0.001)。
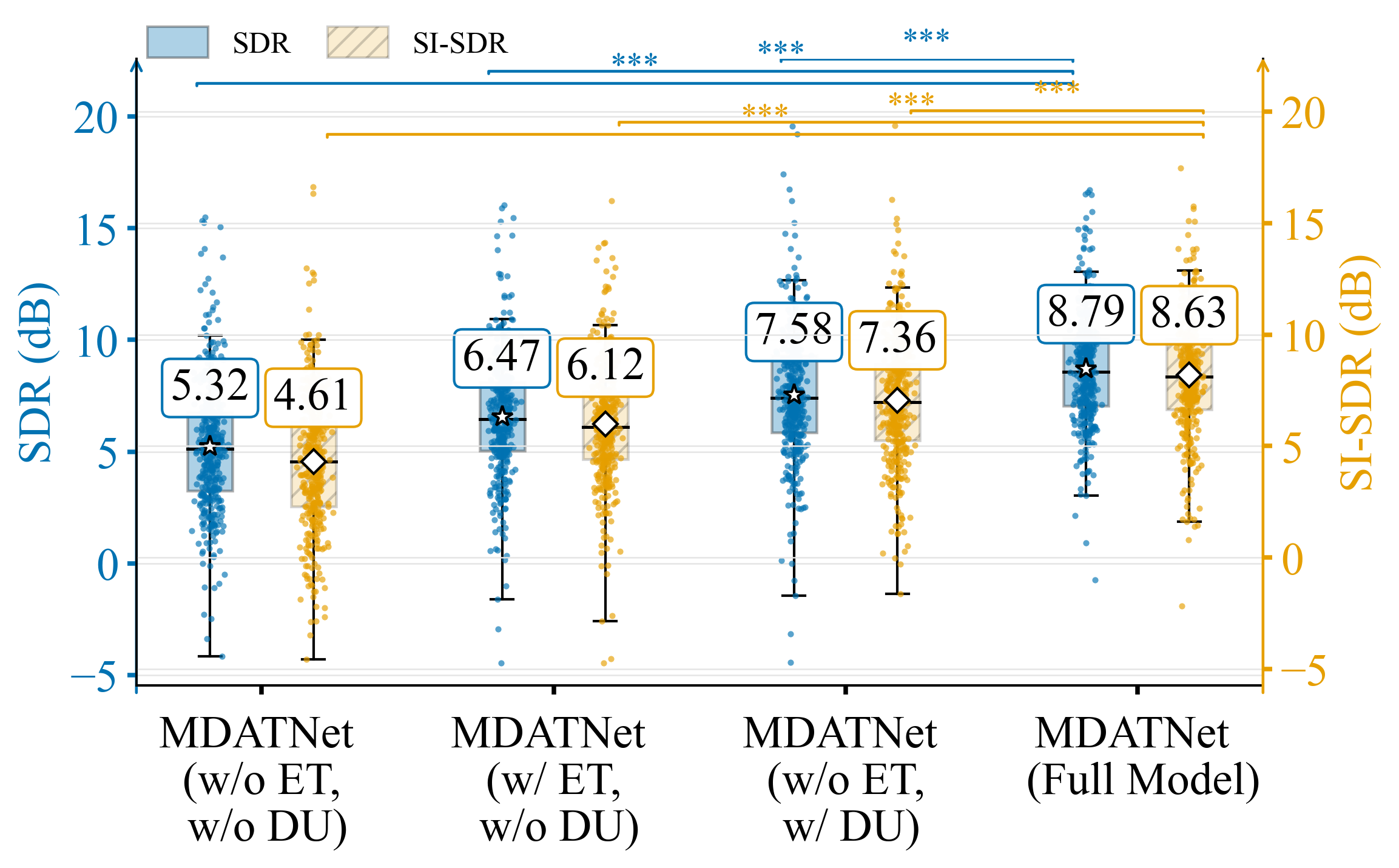 图表结论:此图以柱状图形式直观展示了消融实验在SDR和SI-SDR指标上的结果,与表2的结论一致,显示完整模型性能最佳,且两个模块的贡献均显著。
图表结论:此图以柱状图形式直观展示了消融实验在SDR和SI-SDR指标上的结果,与表2的结论一致,显示完整模型性能最佳,且两个模块的贡献均显著。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性(2.0/2):提出了明确的问题(动态注意力切换)和针对性的解决方案(注意力切换解码+动态历史更新),在脑机接口与语音分离交叉领域有明确的创新点。
- 技术正确性(2.0/2):模型设计逻辑清晰,各模块功能明确,实验对比了合理的基线,并进行了充分的消融研究,技术实现描述完整。
- 实验充分性(1.5/2):实验在自建数据集上进行,对比了多个最新方法,结果显著。但数据集规模较小(18人),且缺乏跨数据集验证,限制了结论的普适性。
- 证据可信度(0.5/1):结果数据详实,消融实验提供了内部证据。但因数据集非公开标准集(虽提供了链接),且缺乏第三方复现,外部验证不足。
- 选题价值:1.5/2
- 前沿性(0.75/1):动态场景下的神经引导TSE是当前的一个前沿方向,该工作填补了该方向的部分空白。
- 潜在影响与应用空间(0.75/1):研究对开发下一代智能助听设备、神经调控耳机有潜在推动作用,但因其依赖EEG和眼动设备,短期实际应用受限于硬件成本和便携性。
- 开源与复现加成:-0.5/1
- 代码与模型:论文未提供代码仓库或模型权重链接。
- 数据集:提供了数据集下载链接(https://github.com/XXuefeii/AASD),这是一个重要加分项。
- 训练细节:提供了部分训练超参数(优化器、学习率、batch size),但缺乏损失函数、完整训练日志、预训练模型细节等关键复现信息。
- 综合来看,开源程度有限,增加了复现难度,因此给予负分。