📄 EchoRAG: A Two-Stage Framework for Audio-Text Retrieval and Temporal Grounding
#音频检索 #知识蒸馏 #对比学习
✅ 7.5/10 | 前25% | #音频检索 | #知识蒸馏 | #对比学习
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 中
👥 作者与机构
- 第一作者:Zilin Wang(厦门大学电影系;厦门大学闽台文化遗产数字化保护与智能处理文化和旅游部重点实验室)
- 通讯作者:Liyan Chen(厦门大学电影系;厦门大学闽台文化遗产数字化保护与智能处理文化和旅游部重点实验室)
- 作者列表:Zilin Wang(厦门大学电影系;厦门大学闽台文化遗产数字化保护与智能处理文化和旅游部重点实验室), Zheng Huang(厦门大学电影系;厦门大学闽台文化遗产数字化保护与智能处理文化和旅游部重点实验室), Zibai Ou(厦门大学电影系;厦门大学闽台文化遗产数字化保护与智能处理文化和旅游部重点实验室), Yuchen Yang(厦门大学电影系), Liyan Chen(厦门大学电影系;厦门大学闽台文化遗产数字化保护与智能处理文化和旅游部重点实验室)
💡 毒舌点评
EchoRAG 的亮点在于其工程设计的巧妙,将稳定的全局检索(教师)与精确的细粒度对齐(学生)结合,形成了一个有效的“粗筛-精排”范式。然而,其“创新”更多体现在对现有技术(如ColBERT的后期交互、KL蒸馏)的组合与适配上,在理论深度上稍显不足;峰值平滑正则化虽有效,但其设计(熵+全变差)更像是一个启发式的“补丁”,缺乏更深入的理论分析。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开训练好的EchoRAG模型权重。
- 数据集:实验使用的数据集(SQuAD-Spoken, AudioCaps, VoxPopuli)为公开数据集。论文中未提及是否提供了其处理后的VoxPopuli查询数据。
- Demo:未提及在线演示。
- 复现材料:论文提供了较为详细的实现细节(模型架构、训练三阶段、损失函数、优化器设置、硬件环境),但未提供完整的配置文件、训练脚本或检查点。
- 引用的开源项目:论文依赖预训练模型 CLAP,并引用了 Whisper(用于基线ASR)、 BGE-M3、 Qwen3-Embedding(文本嵌入基线)、 Qwen2-Audio(生成模型)等开源项目或模型。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
问题:现有的音频RAG方法通常将音频压缩为单一的全局嵌入(如CLS token),丢失了细粒度的帧级信息和时间线索,这限制了其在需要精确定位音频片段的任务中的性能。
方法核心:提出了EchoRAG,一个两阶段框架。第一阶段,使用预训练CLAP模型的CLS编码器作为教师,进行快速的全局句级检索。第二阶段,引入一个基于token-frame后期交互(LI)的学生模块,从教师分布进行知识蒸馏,对检索结果进行细粒度重排序并预测支持性音频片段的时间跨度。此外,设计了一个无监督的峰值-平滑正则化,以改善时间定位分布的质量。
新意:与已有方法相比,EchoRAG的新意在于:a) 架构上结合了全局检索的高效性和细粒度交互的精确性;b) 训练上采用了针对多查询-单音频场景的Multi-positive InfoNCE损失来缓解假阴性问题;c) 提出了无需帧级标注的peak-smooth正则化来优化时间定位。
主要实验结果:EchoRAG在音频-文本检索任务(SQuAD-Spoken, AudioCaps)上取得了具有竞争力的性能,R@10和NDCG@10常高于基线。在生成任务(HotpotQA, SLUE-SQA-5)上,EchoRAG在FactScore(忠实度)指标上显著优于基线,表明其检索到的证据更具支持性。具体关键数据见下表:
表1:音频-文本检索结果(摘选)
方法 数据集 R@1 R@5 R@10 NDCG@10 WavRAG SQuAD-Spoken 0.6424 0.8041 0.8979 0.8483 Ours SQuAD-Spoken 0.6535 0.8037 0.9260 0.8341 CLAP AudioCaps 0.6253 0.9375 1.0000 0.8211 Ours AudioCaps 0.6581 0.9475 1.0000 0.8459 表3:生成结果(摘选)
方法 设置 HotpotQA EM HotpotQA FS SLUE-SQA-5 EM TextRAG top-1 0.3350 0.3426 0.5162 WavRAG top-1 0.3138 0.3247 0.5610 EchoRAG top-1 0.3408 0.3426 0.5687 EchoRAG Oracle 0.6301 0.6537 0.6449 实际意义:该框架为基于音频的知识密集型问答和检索提供了一个更精确的解决方案,尤其是在需要定位具体说话片段或声音事件的场景(如法庭取证、会议纪要、媒体检索)中具有应用潜力。
主要局限性:a) 框架的性能部分依赖于CLAP教师模型的质量,且教师模型的微调引入了额外的训练开销。b) 峰值-平滑正则化虽然有效,但属于无监督启发式方法,其超参数(如α)可能需要针对不同任务调整。c) 实验中并未评估对更长音频(如数分钟)或更复杂查询的处理能力。
🏗️ 模型架构
EchoRAG是一个端到端的检索与定位框架,采用两阶段、教师-学生架构。其整体流程如下图所示:
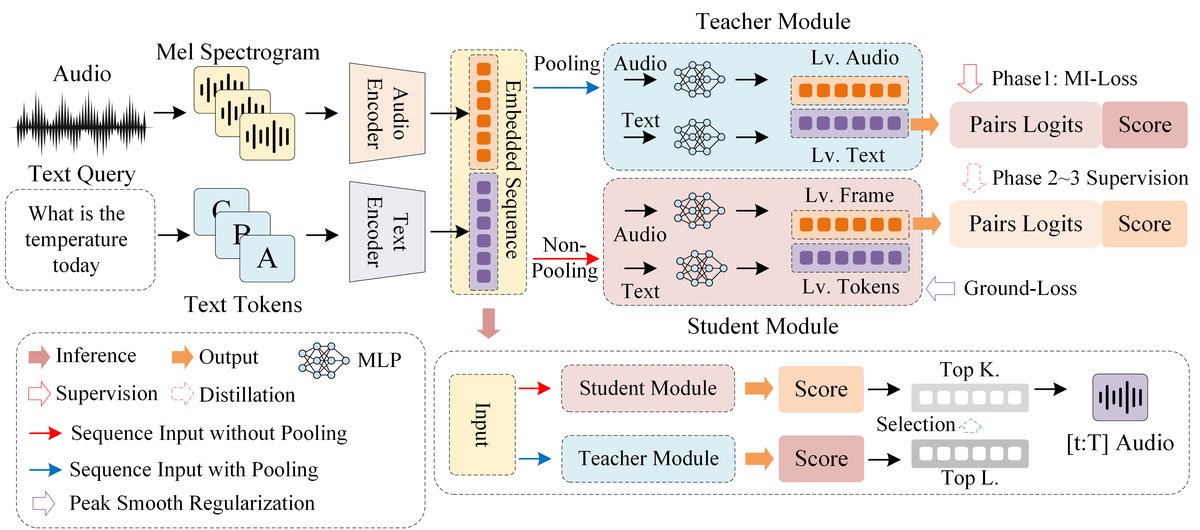 图2: EchoRAG框架概览。上半部分为第一阶段,全局CLS编码器(教师)生成紧凑表示进行快速检索;下半部分为第二阶段,token-frame LI模块(学生)对短名单进行精排和时间预测,并受峰值-平滑正则化约束。
图2: EchoRAG框架概览。上半部分为第一阶段,全局CLS编码器(教师)生成紧凑表示进行快速检索;下半部分为第二阶段,token-frame LI模块(学生)对短名单进行精排和时间预测,并受峰值-平滑正则化约束。
完整输入输出流程:
- 输入:一个文本查询
q和一个包含N个音频片段的语料库A。 - 输出:一个排序后的音频片段列表,以及为每个片段预测的支持性时间区间
[t_start, t_end]。
主要组件:
CLS教师模块:
- 功能:负责第一阶段的快速粗粒度检索。
- 结构:基于预训练的CLAP模型,其文本和音频编码器均保持可训练。在编码器输出之上添加线性投影头,用于获取全局句级嵌入(文本侧为序列的[CLS] token嵌入或平均池化;音频侧为帧级嵌入的池化)。
- 交互:文本查询
q和所有音频a_i通过各自编码器生成全局向量X_q和Y_i,计算点积相似度s_ij,进行检索并输出Top-L候选列表。
LI学生模块:
- 功能:负责第二阶段的细粒度重排序和时间定位。
- 结构:同样基于CLAP编码器,但获取token级文本嵌入
T和帧级音频嵌入A。 - 交互:对于文本查询和Top-L候选音频,计算token×帧的相似度矩阵
S = T A^⊤。通过聚合(训练早期用均值池化,后期用log-sum-exp池化)得到查询-音频对的LI分数。这些分数被优化为模仿教师CLS分支的分布(通过KL散度)。
峰值-平滑正则化器:
- 功能:在训练第三阶段,作用于LI学生模块产生的帧级分数分布
p_t。 - 结构:由两个无监督损失项组成:
- 峰值项(熵损失):
-∑ p_t log p_t,鼓励分布集中在少数帧上。 - 平滑项(全变差损失):
α ∑ |p_{t+1} - p_t|,惩罚相邻帧间的剧烈变化,使定位边界更平滑。
- 峰值项(熵损失):
- 功能:在训练第三阶段,作用于LI学生模块产生的帧级分数分布
数据流与关键设计动机:
- 粗到精:CLS教师快速筛选候选,避免在全部语料上进行昂贵的token-frame交互,保证效率。LI学生对候选进行精修,弥补全局表示的信息损失。
- 知识蒸馏:LI学生从CLS教师学习“什么是正确的相关度”,将稳定的全局对齐知识迁移到细粒度的帧级交互中,提升了LI学生学习的稳定性和准确性。
- 无监督定位优化:峰值-平滑正则化在没有帧级标注的情况下,利用“定位应集中且边界平滑”这一先验知识,引导模型生成更符合实际需求的时间分布。
💡 核心创新点
- 两阶段、教师-学生架构:这是EchoRAG的核心框架创新。它解决了现有方法在效率(全局检索)与精度(细粒度对齐)之间的权衡问题。教师(CLS)提供稳定全局监督,学生(LI)学习细粒度模式,两者结合实现了性能提升。
- Multi-positive InfoNCE损失:针对音频检索中一个音频可能对应多个有效查询(假阴性)的问题,修改了标准的InfoNCE损失。在计算音频到文本的对比损失时,将同一个音频对应的所有查询都视为正样本,从而在有限数据下更充分地利用数据,减少监督噪声。
- 峰值-平滑帧级正则化:提出了一种无需帧级人工标注的弱监督方法来改善时间定位。通过同时鼓励分布的“集中性”和“局部平滑性”,模型能够生成更尖锐、更稳定的定位热力图,即使在没有精确边界标签的情况下也能有效。
🔬 细节详述
- 训练数据:
- 使用了三个数据集:SQuAD-Spoken(将SQuAD文本与合成语音配对)、AudioCaps(音频及其人类描述)、VoxPopuli(多语种议会录音及其转录,使用其英文子集并通过LLM生成多样化查询)。
- 训练/测试划分:使用SQuAD-Spoken和AudioCaps的测试集进行检索和定位评估;剩余数据(包括VoxPopuli)用于模型训练。
- 损失函数:
LInfoNCE:双向(文本到音频,音频到文本)平均的Multi-positive InfoNCE损失,用于训练CLS教师。LKD:KL散度损失,用于将教师CLS分支的全局logits分布蒸馏到学生LI分支的聚合logits上。Lground:峰值-平滑正则化损失,由熵损失和全变差损失组成,权重为α。- 总损失:
L = LInfoNCE + λ_KD L_KD + λ_ground L_ground。
- 训练策略:
- 三阶段训练:
- 阶段1(0-20%步数):仅优化CLS教师,使用
LInfoNCE。 - 阶段2(20-60%):引入LI学生,联合优化教师(
LInfoNCE)和学生(LKD)。 - 阶段3(60-100%):在LI学生上应用
Lground正则化。
- 阶段1(0-20%步数):仅优化CLS教师,使用
- 优化器:Adam。
- 学习率:投影头为
1e-4,其余部分为5e-5。 - Batch size:32,梯度累积步数为4(有效batch size 128)。
- 训练轮数:10 epochs。
- 三阶段训练:
- 关键超参数:
- 教师模型:预训练的CLAP。
- LI聚合方式:训练早期使用均值池化(稳定),后期切换为log-sum-exp池化(强调显著匹配)。
- 正则化权重
α和蒸馏权重λ_KD,λ_ground:论文未给出具体数值。
- 训练硬件:NVIDIA RTX 4090 GPU,使用bfloat16精度。
- 推理细节:论文未详细说明推理时的具体解码策略。对于时间定位,模型输出帧级分数
p_t后,可能通过后处理(如阈值或平滑)得到起止点[t_start, t_end]。 - 其他:在训练过程中,通过数据增强每个音频样本配对多个查询,这是使用Multi-positive InfoNCE的动机之一。
📊 实验结果
- 音频-文本检索(表1)
图(论文内表格)展示了在SQuAD-Spoken和AudioCaps上的检索性能。
- 结论:EchoRAG在SQuAD-Spoken上R@10达到0.9260,显著优于WavRAG的0.8979。在AudioCaps上,EchoRAG在几乎所有指标上均为最优,例如NDCG@10为0.8459,高于CLAP的0.8211和WavRAG的0.5252。这证明了其在语音和非语音音频检索场景下的有效性。
- 音频定位(表2)
 图(论文内表格)展示了在音频定位任务上的性能。
图(论文内表格)展示了在音频定位任务上的性能。
- 结论:EchoRAG的精确率(Precision)最高,为37.25%,优于TAG(28.60%)和WSTAG(36.44%)。但召回率(31.07%)和F1值(33.88%)略低于WSTAG(召回率32.98%, F1 34.62%)。这表明EchoRAG的定位边界可能更精确,但可能漏检部分相关片段。
- 生成结果(表3)
图(论文内表格)展示了在问答生成任务上的性能。
- 结论:在Top-1设置下,EchoRAG在HotpotQA的EM和FS上与TextRAG持平或略优,但在SLUE-SQA-5上表现更好。在Oracle设置(使用金标证据)下,EchoRAG的EM和FS均取得最高值(例如HotpotQA EM 0.6301, FS 0.6537),表明当检索完美时,其生成模型能更好地利用证据。整体上,EchoRAG在事实一致性(FactScore) 方面优势明显,这与其细粒度检索能提供更相关证据的假设一致。
- 消融实验(表4)
图(论文内表格)展示了在SQuAD-Spoken上的消融结果。
- 结论:从基线(SP + CLS-Only)开始,单独加入Multi-positive(MP)损失或LI模块都能提升性能。两者结合(MP + CLS→LI)取得最佳结果(R@1 0.6535, NDCG@10 0.8341),验证了两个技术点的互补性:MP处理假阴性,LI实现细粒度对齐。
⚖️ 评分理由
- 学术质量:6.0/7:论文提出了一个设计良好、逻辑清晰的框架,有效地结合了多种技术来解决实际问题。实验设计全面,对比了多类基线,并进行了消融研究,证据较为扎实。主要扣分点在于创新性属于技术组合与适配,而非基础方法的突破;此外,定位任务的结果并非全面领先,说明细粒度正则化方法可能仍有提升空间。
- 选题价值:1.5/2:音频检索与时间定位是多模态AI和语音处理的重要前沿,具有广泛的应用前景。EchoRAG的工作对此方向有明确的推动作用,特别是强调细粒度信息在RAG中的重要性,符合领域发展趋势。
- 开源与复现加成:0.3/1:论文提供了关键的实现细节和超参数,使得核心实验具备可复现性。但缺乏明确的代码和模型发布声明,因此加成有限。0.3分反映了信息完整但未完全开放的现状。