📄 ECHO: Frequency-Aware Hierarchical Encoding for Variable-Length Signals
#音频大模型 #音频分类 #自监督学习 #工业应用 #开源工具
🔥 9.5/10 | 前10% | #音频分类 | #自监督学习 | #音频大模型 #工业应用
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Yucong Zhang(武汉大学计算机学院;苏州昆山杜克大学多模态智能系统苏州市重点实验室)
- 通讯作者:Juan Liu(武汉大学人工智能学院), Ming Li(武汉大学人工智能学院;苏州昆山杜克大学)
- 作者列表:Yucong Zhang(武汉大学计算机学院;苏州昆山杜克大学多模态智能系统苏州市重点实验室), Juan Liu†(武汉大学人工智能学院), Ming Li†(武汉大学人工智能学院;苏州昆山杜克大学)。†表示共同通讯作者。
💡 毒舌点评
亮点: 该论文成功地将频率感知和滑动窗口两大思想结合,构建了一个能优雅处理现实世界工业信号(采样率可变、长度可变)的通用基础模型,并通过一个前所未有的全面基准(SIREN)证明了其优越性,做到了“设计解决实际问题”和“实验证明设计有效”的闭环。 短板: 论文的实验全部基于离线、干净的学术数据集,对于工业界最关心的实时流式推理性能、计算资源消耗以及在嘈杂、非理想工况下的鲁棒性缺乏深入探讨,这使得其“工业应用”的宣称在现阶段更偏向于技术展示而非经过实战检验的方案。
🔗 开源详情
- 代码:提供了完整的代码仓库链接:https://github.com/yucongzh/ECHO。
- 模型权重:论文未明确提及是否公开了预训练模型权重,但提供了代码仓库,权重很可能在其中或后续发布。
- 数据集:公开了SIREN评估基准工具包:https://github.com/yucongzh/SIREN,并说明包含了多个数据集,获取方式应在该仓库中说明。
- Demo:论文中未提及在线演示。
- 复现材料:提供了详尽的训练细节(学习率、batch size、优化器、步数、硬件、调度策略等),足以支持复现。训练细节见论文第5.1节。
- 论文中引用的开源项目:论文引用了其对比的多个基础模型(BEATs, CED, EAT, Dasheng, FISHER)的开源实现或论文。此外,SIREN基准中使用的数据集(如DCASE, MAFAULDA, CWRU, IIEE, IICA)均为公开数据集。
📌 核心摘要
- 问题:现有的音频/信号基础模型大多基于视觉Transformer,依赖固定尺寸的频谱图输入和固定的预设采样率。处理可变长度信号需要截断/插值,破坏时序连续性;处理不同采样率信号需要重采样,导致信息损失。这限制了它们在通用机器信号监测(涵盖声学、振动等多模态、多采样率数据)中的应用。
- 方法核心:提出ECHO模型,其核心是“频率感知层级编码”。首先,将频谱图沿频率轴均匀分割为多个子带,并为每个子带计算基于其中心频率的相对位置编码,以适配任意采样率。其次,在每个子带上应用滑动窗口提取重叠的时间补丁,以处理任意长度的输入,无需填充或裁剪。最后,将每个子带的序列送入独立的ViT编码器,再将所有子带的分类令牌拼接成最终的层级化嵌入。
- 新意:与已有的频率分割模型(如FISHER)相比,ECHO创新性地引入了频率位置编码,使模型能显式地感知子带在全频谱中的相对位置,而非独立处理。与传统的固定补丁模型(如BEATs, EAT)相比,滑动补丁设计能更好地保留时序连续性,适应可变长度输入。ECHO旨在统一支持可变长度和可变采样率信号。
- 实验结果:在论文提出的统一评估基准SIREN上,ECHO(Small版)取得了77.65%的整体平均分,超过了最强基线FISHER(76.86%)和Dasheng(76.04%)。在故障分类任务平均准确率达到93.19%,位居第一;在DCASE异常检测任务平均得分62.11%,也达到最佳。相比FISHER,ECHO在所有DCASE年份和大部分故障分类数据集上均有提升。
| 模型 | 规模 | 参数量 | SIREN总均分 | DCASE任务均分 | 故障分类任务均分 |
|---|---|---|---|---|---|
| ECHO | Small | 22M | 77.65 | 62.11 | 93.19 |
| FISHER | Small | 22M | 76.86 | 61.00 | 92.73 |
| Dasheng | Base | 86M | 76.04 | 59.95 | 92.12 |
| EAT | Base | 86M | 74.23 | 60.84 | 87.62 |
| BEATs | Base | 90M | 71.86 | 61.86 | 81.86 |
- 实际意义:ECHO为工业设备的状态监测提供了一个强大的通用前端特征提取器。其处理可变采样率和长度的能力,使其能无缝集成来自不同传感器、不同工况的数据,无需预处理重采样或裁剪,简化了部署流程。开源代码和SIREN基准为社区提供了公平比较和推进该领域研究的平台。
- 主要局限:模型虽在学术数据集上表现优异,但缺乏在真实工业场景(高噪声、数据不平衡、极端故障模式)下的验证。论文未探讨模型的推理效率(如延迟、吞吐量),这对实时监测至关重要。此外,滑动窗口带来的计算量增加及其优化策略未做深入分析。
🏗️ 模型架构
ECHO的整体架构如图1所示,是一个端到端的处理流程,包含四个核心组件:
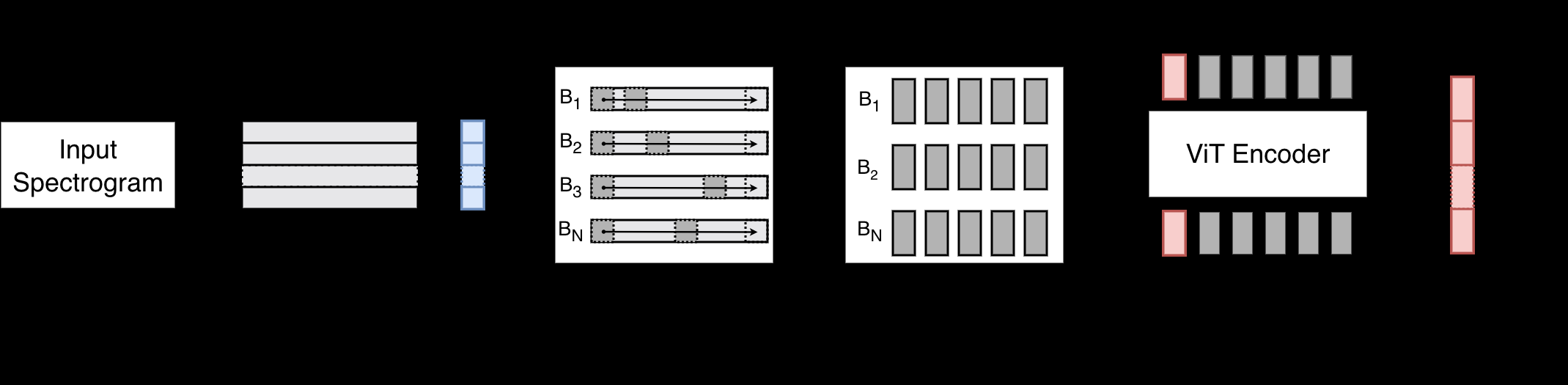
- 频谱图提取 (Spectrogram Extraction):输入是任意采样率(fs)的原始波形。使用短时傅里叶变换(STFT)将其转换为幅度谱图。关键设计是窗长(twin)和跳长(thop)以秒为单位定义,因此对于相同持续时间的信号,无论采样率如何,生成的时频帧数是固定的。
- 频率感知子带分割与位置编码 (Frequency-Aware Sub-band Splitting with PE):将STFT得到的频谱图 S 在频率轴上均匀分割成 N 个无重叠的子带(N与采样率fs成正比)。对于第k个子带,其中心频率 fc 和归一化位置 p 被计算出来,并用于生成一个固定的正弦位置编码 PE(p, j)。这个设计是本文的核心创新之一:它确保来自不同采样率、但处于相对频率位置相同的子带,拥有相同的位置编码,从而使模型能处理任意采样率输入。
- 时序滑动补丁提取 (Temporal Sliding Patch Extraction):对每个子带单独进行时序分割。使用一个长度为L(等于子带宽度)的滑动窗口,以50%的重叠率沿时间轴滑动,提取出一系列“补丁”。这个过程通过一个二维卷积高效实现,最终将每个子带表示为一个补丁序列,形状为 (N_patches, D),其中D是嵌入维度。滑动窗口设计保证了处理任意长度信号的能力,且不破坏时序信息。
- 层级编码 (Hierarchical Encoding):每个子带的补丁序列前面会添加一个可学习的[CLS]令牌,然后独立送入一个ViT骨干网络。ViT的输出中,[CLS]令牌的最终表示概括了该子带的信息。模型的最终嵌入是将所有子带的[CLS]令牌拼接起来得到的。这种“子带级-整体级”的层级结构,使模型既能捕捉每个频率子带内的局部时序依赖,又能通过频率分割来区分不同的频率范围。
数据流:原始波形 -> STFT频谱图 -> N个子带(每个带PE) -> 每个子带生成补丁序列 -> 每个子带序列通过ViT得到子带[CLS]嵌入 -> 拼接所有子带[CLS]嵌入 -> 最终的层级化信号表示向量 z。
💡 核心创新点
- 频率感知的位置编码:与传统ViT使用固定的空间位置编码不同,ECHO为频谱子带设计了基于相对频率位置的PE。这使得模型能够“理解”每个子带在全频谱中的位置,从而统一建模不同采样率下的信号,解决了基础模型无法处理任意采样率输入的瓶颈。
- 滑动窗口补丁设计:摒弃了传统的固定网格分割(如ViT的16x16 patch),采用在时间轴上重叠滑动的窗口。这一设计允许模型处理任意长度的输入信号(从短片段到长序列),无需填充或裁剪,保持了时序的连续性和完整性,也天然支持流式处理场景。
- 统一的可变信号表示框架:ECHO的架构从设计上同时解决了采样率可变和长度可变两个现实世界中的核心问题。这使其成为一个真正通用的机器信号前端,能直接处理来自不同传感器、不同配置的原始数据。
- 提出并开源SIREN基准:论文贡献了一个标准化的评估工具包SIREN,集成了DCASE历年挑战和多个公开的工业信号数据集(声音、振动),并定义了统一的评估协议。这填补了领域内缺乏公平、全面比较基础模型在通用信号诊断任务上性能的空白。
🔬 细节详述
- 训练数据:使用大规模音频数据集进行预训练,具体包括:AudioSet (AS2M), MTG-Jamendo (MTG), Freesound (FS)的子集(源自WavCaps)。论文未详细说明每个数据集的具体使用比例或预处理细节。
- 损失函数:采用自监督的教师-学生框架,损失函数包含两个部分:(1) 全局对齐:学生模型[CLS]令牌的输出与教师模型对应层输出的时间平均值对齐;(2) 帧级对齐:在掩码位置上,学生模型的输出与教师模型的输出进行对齐。具体损失函数公式未在提供的文本中给出。
- 训练策略:
- 优化器:未明确提及,但使用了余弦学习率调度器和线性warm-up。
- 学习率:基础学习率为1e-4,随有效batch size缩放。最小学习率为1e-5。
- Warm-up:线性warm-up持续40,000步,总训练步数为400,000步。
- Batch Size:全局batch size为256。
- 权重衰减:0.05。
- 关键超参数:
- 模型规模:提供了Small (22M) 和 Tiny (5.5M) 两个版本。骨干为ViT。
- STFT参数:窗长25 ms,窗移10 ms。
- 子带宽度:固定为32(频率bins)。
- 教师-学生EMA动量α:未说明具体数值。
- 训练硬件:使用4块NVIDIA GeForce RTX 3090 GPU。
- 推理细节:推理时处理完整频谱图,将K个子带的[CLS]令牌拼接成向量 z 用于下游任务。下游任务采用k-NN(k=5)进行评分或分类。
- 正则化:未明确提及除了权重衰减外的其他正则化技巧。
📊 实验结果
论文在SIREN基准上进行了全面评估,主要对比了5种预训练基础模型。关键结果如上表所示。
- 故障分类任务细分结果(准确率%):
数据集 BEATs CED (Base) EAT (Base) Dasheng (Base) FISHER (Small) ECHO (Small) IIEE (44.1k) 65.81 80.21 78.97 99.36 97.48 99.85 IICA (48k) 91.55 86.08 89.01 90.88 94.20 93.67 CWRU (12k) 88.57 81.90 85.71 88.57 86.67 90.48 MAFAULDA (50k) 63.66 66.48 84.52 81.96 85.29 82.42 平均 81.86 82.88 87.62 92.12 92.73 93.19
结论:ECHO在多个跨采样率的故障分类数据集上均表现出色,平均准确率最高。其优势在CWRU等振动数据集上尤为明显。
- DCASE任务(异常检测)得分(AUC & pAUC调和平均%):
年份 BEATs EAT (Base) Dasheng (Base) FISHER (Small) ECHO (Small) 2020 61.31 57.79 57.27 59.51 60.20 2021 58.97 58.57 57.87 59.79 59.96 2022 62.89 59.69 60.70 61.83 63.71 2023 55.89 57.12 57.71 55.66 57.86 2024 57.84 59.75 57.01 58.68 58.70 2025 61.86 60.84 59.95 61.00 62.11 均值 61.86 60.84 59.95 61.00 62.11
结论:在DCASE挑战系列上,ECHO同样取得了最高的平均分,尤其在2022和2023年份上有显著提升。
- 消融实验(论文中未提供明确的消融实验表格):论文在讨论中通过对比不同模型变体间接说明了设计选择的有效性,例如:对比Dasheng(滑动补丁)与EAT(传统补丁)显示滑动补丁的优势;对比ECHO与FISHER显示频率位置编码的增益。
⚖️ 评分理由
- 学术质量:6.5/7 - 论文创新点清晰(频率PE、滑动窗口),技术方案合理且完整,实验在提出的高标准基准上全面展开,数据充分,结果具有说服力。创新性虽非范式革命,但在解决实际工程痛点上做出了系统且有效的改进。扣分点在于缺乏效率分析和真实场景验证。
- 选题价值:1.8/2 - 选题针对工业监测这一重要且基础的问题,具有很高的实用价值。提出通用模型和统一基准对推动领域发展有直接贡献,与音频/信号处理研究者高度相关。
- 开源与复现加成:1.0/1 - 论文开源了模型代码、SIREN基准,并详细公开了训练超参数和细节,复现友好度极高,显著提升了工作的影响力和可信度。