📄 E2E-AEC: Implementing An End-To-End Neural Network Learning Approach for Acoustic Echo Cancellation
#语音增强 #端到端 #迁移学习 #声学回声消除 #多任务学习
✅ 7.5/10 | 前25% | #语音增强 | #端到端 | #迁移学习 #声学回声消除
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Yiheng Jiang(阿里巴巴通义实验室)
- 通讯作者:未说明
- 作者列表:Yiheng Jiang(阿里巴巴通义实验室)、Biao Tian(阿里巴巴通义实验室)、Haoxu Wang(阿里巴巴通义实验室)、Shengkui Zhao(阿里巴巴通义实验室)、Bin Ma(阿里巴巴通义实验室)、Daren Chen(阿里巴巴通义实验室)、Xiangang Li(阿里巴巴通义实验室)
💡 毒舌点评
本文最大亮点在于用扎实的消融实验证明了从传统LAEC模型迁移知识到纯神经网络E2E-AEC的可行性,为简化AEC系统流水线提供了有力证据。但短板也很明显:模型本身(1.2M参数的GRU网络)创新有限,更像是多个成熟技巧(渐进学习、注意力对齐、VAD掩码)的工程化组合,且论文未提供任何代码或模型,对于追求可复现的读者而言,其技术细节的透明度打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:训练数据来自公开数据集(DNS Challenge, AEC Challenge),但论文未提供处理后的专用数据集。
- Demo:未提及在线演示。
- 复现材料:给出了模型结构(RNN块设计、层数、维度)、输入特征规格(STFT帧长/移)、损失函数组成和权重、以及部分超参数(模型总参数1.2M)。但未提供完整的训练脚本、优化器设置、学习率策略、数据增强细节等关键复现信息。
- 引用的开源项目:提及使用了gpuRIR [25]生成房间脉冲响应,WebRTC-VAD生成VAD标签。
- 总体开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:传统声学回声消除(AEC)依赖线性自适应滤波器和时延估计,在非线性、时变回声路径下性能下降;现有混合系统复杂,而纯端到端方法在大时延场景下性能不佳。
- 方法核心:提出E2E-AEC,一个完全基于神经网络的端到端AEC模型。其核心创新在于:采用渐进式学习分阶段消除回声与噪声;通过知识迁移,用预训练的混合系统模型初始化网络,以继承其先验知识;设计带监督损失的注意力机制实现精确的信号时间对齐;并引入语音活动检测预测与掩码策略在推理时进一步抑制远端回声。
- 与已有方法相比:新在完全摆脱了传统信号处理流水线(TDE/LAEC),并通过上述策略的组合,解决了端到端模型在时间对齐和初始回声抑制上的难题,使其性能超越或媲美复杂的混合系统及已有的端到端方法(如DeepVQE)。
- 主要实验结果:在AEC Challenge 2023/2022盲测集上,完整模型(Exp 6)取得最优成绩。关键数据见表1:
方法 (AEC Challenge 2023) MOSavg ERLE (dB) DeepVQE (E2E, SOTA) 4.40 65.7 E2E-AEC (本文, Exp 6) 4.51 78.69 - 消融实验(表2)证明了“注意力+损失函数”对时间对齐的有效性。
- 表3显示从第五层提取VAD预测并掩码效果最佳。
- 实际意义:展示了端到端方法在AEC任务上达到甚至超越工业级混合系统的潜力,有望简化部署并提升全双工通话质量。
- 主要局限性:VAD掩码导致的超高ERLE(78.69dB)可能过度抑制,在真实复杂场景(如持续双讲、非平稳噪声)下的泛化能力和鲁棒性有待更全面评估。论文未公开模型与代码。
🏗️ 模型架构
模型整体为基于时频掩蔽的端到端神经网络,输入为带混响、回声和噪声的麦克风信号的STFT特征,输出为纯净近端语音的STFT频谱估计(中间阶段为回声抑制后的语音+噪声频谱)。
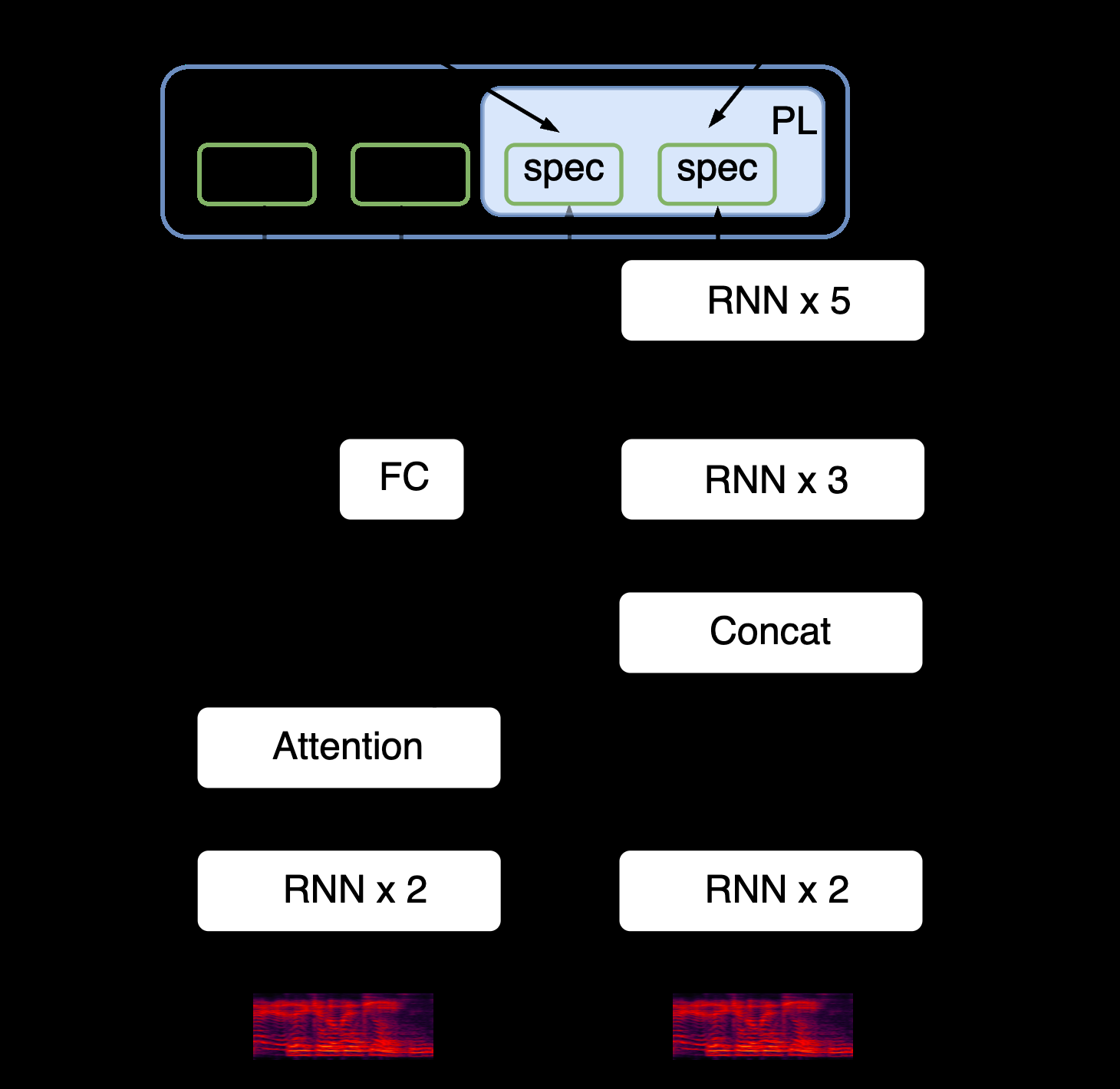
架构主要组件与数据流(结合图1):
- 输入:麦克风信号
mic(包含近端语音x、回声r*hr、噪声v)和远端参考信号ref(包含回声源r)的STFT特征。 - 参考信号编码:
ref经RNN块(2层GRU,采用TF-GridNet设计)编码。 - 时间对齐模块:
- 对编码后的参考特征在时间轴上
unfold操作,扩展为多延迟表示Ru。 - 与麦克风特征
Y进行点积计算相关性Dp,再经卷积层和Softmax生成注意力权重A(T×H矩阵,H为最大允许延迟)。 - 用
A对Ru加权求和,得到对齐后的参考特征~R。 - 监督:
A的期望延迟De与GCC-PHAT算法计算的目标延迟之间计算MSE或交叉熵损失。
- 对编码后的参考特征在时间轴上
- 特征融合与处理:对齐参考特征
~R与麦克风特征Y拼接,送入8个RNN块进行深度处理。 - 渐进式学习(PL)输出:
- 第一阶段(中间层,如第5层):输出复卷积掩码,应用于麦克风频谱,目标是得到无回声但含噪声的语音。
- 第二阶段(最终层):输出复卷积掩码,应用于麦克风频谱,目标是得到纯净无回声的语音。
- VAD预测与掩码:从第一阶段的中间层(第5层)提取特征,经全连接层预测近端语音VAD概率。在推理阶段,当预测无语音时,对最终输出频谱施加掩码(衰减),以强力抑制回声。
- 输出:最终阶段估计的纯净语音频谱,经逆STFT得到时域信号。
关键设计选择:采用单向GRU以支持流式推理;使用复卷积掩码而非相位谱估计;通过多阶段目标分解学习难度。
💡 核心创新点
- 端到端替代传统流水线:完全摒弃了TDE和LAEC模块,通过神经网络隐式学习时间对齐和回声消除,简化了系统架构,是核心范式创新。
- 监督式时间对齐注意力:在注意力机制上引入显式的延迟预测损失(MSE/CE),将无监督对齐转化为有监督学习,显著提升了对齐精度和模型性能(见表2)。
- 基于知识迁移的初始化:使用预训练的混合系统(含LAEC)模型参数来初始化E2E模型,有效迁移了传统方法在回声抑制和对齐上的先验知识,大幅提升了E2E模型的初始性能和最终上限(见表1,Exp 2到Exp 3)。
- 渐进式学习与VAD掩码的协同:将PL的目标从SNR递增改为信号成分递进(先去回声,再去噪),并配合推理时的VAD掩码,在远端单讲场景下实现了极高的回声抑制率(ERLE 78.69dB)。
🔬 细节详述
- 训练数据:
- 清洁语音:DNS Challenge数据集 [24]。
- 噪声:DNS Challenge数据集 [24]。
- 房间脉冲响应:使用gpuRIR [25] 生成。
- 回声数据:来自AEC Challenge 2023 [26] 训练集的远端单讲片段。
- 所有音频从48kHz下采样至24kHz进行处理,评估时再上采样回48kHz。
- 数据规模:未说明具体片段数量或时长。
- 损失函数:
- 总体损失 (公式5):
L = λ1Lspec1 + λ2Lspec2 + λ3Ldelay + λ4Lvad。λ1=λ2=λ4=1,λ3=100(MSE)或1(CE)。 - 频谱损失 (
Lspec1,Lspec2):调制损失(权重0.1)与SNR损失(权重0.9)的加权和。Lspec1针对第一阶段目标(无回声语音+噪声),Lspec2针对第二阶段目标(纯净语音)。 - 延迟损失 (
Ldelay):估计延迟De与GCC-PHAT目标延迟之间的MSE或交叉熵损失。 - VAD损失 (
Lvad):预测VAD概率与WebRTC-VAD生成的ground truth之间的二元交叉熵损失(BCE)。
- 总体损失 (公式5):
- 训练策略:未说明学习率、优化器(如Adam)、warmup、batch size、训练步数/轮数、调度策略。也未说明PL的训练顺序(是否分阶段训练或联合训练)。
- 关键超参数:
- 模型参数量:1.2M。
- 输入帧长:20ms,帧移:10ms。
- RNN块:基于TF-GridNet设计,每块2层单向GRU,隐藏维度64。unfold操作的核大小为4,步长为1。
- 网络深度:特征编码后8个RNN块。
- 最大允许延迟
H:未说明具体值,但由unfold操作和延迟范围决定。 - VAD掩码阈值和衰减因子:未说明。
- 训练硬件:未说明。
- 推理细节:
- 支持流式推理(单向GRU)。
- VAD掩码操作:在推理时,对预测的VAD概率进行平滑,当“非语音”概率超过预设阈值时,对当前帧输出频谱施加衰减。
- 最终输出经逆STFT得到48kHz时域波形。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
主要Benchmark:AEC Challenge 2023 & 2022 盲测集。 评估指标:
- AECMOS:分为EMOS(回声烦扰度,越高越好)和DMOS(其他失真,越高越好)。
MOSavg为所有AECMOS子分数的平均。 - ERLE (dB):回声返回损耗增强,越高表示回声抑制越强。 主要对比与结果: 表1展示了各优化策略的累积效果及与SOTA方法的对比。
| 方法 | 数据集 | DT EMOS | DT DMOS | FarST ERLE (dB) | NearST EMOS | NearST DMOS | MOSavg |
|---|---|---|---|---|---|---|---|
| DeepVQE (E2E, [9]) | AEC Challenge 2023 | 4.62 | 4.02 | 65.7 | 4.61 | 4.36 | 4.40 |
| Align-ULCNet (Hybrid, [28]) | AEC Challenge 2023 | 4.60 | 3.80 | - | 4.77 | 4.28 | 4.36 |
| E2E-AEC Base (Exp 1) | AEC Challenge 2023 | 4.41 | 3.85 | 46.59 | 4.68 | 4.29 | 4.31 |
| +PL (Exp 2) | AEC Challenge 2023 | 4.48 | 3.96 | 46.39 | 4.68 | 4.41 | 4.38 |
| +PL+Trans (Exp 3) | AEC Challenge 2023 | 4.56 | 4.07 | 49.04 | 4.70 | 4.44 | 4.44 |
| +PL+Trans+Align (Exp 4) | AEC Challenge 2023 | 4.62 | 4.17 | 50.63 | 4.69 | 4.45 | 4.48 |
| +PL+Trans+Align+Vad (Exp 5) | AEC Challenge 2023 | 4.64 | 4.20 | 52.04 | 4.69 | 4.45 | 4.50 |
| E2E-AEC Full (Exp 6) | AEC Challenge 2023 | 4.65 | 4.18 | 78.69 | 4.77 | 4.42 | 4.51 |
关键结论:从Exp1到Exp6,MOSavg从4.31持续提升至4.51,超越DeepVQE。知识迁移(Trans)和VAD掩码(VadMask)贡献最大。
时间对齐消融实验(表2,基于Exp 3/4条件):
| 方法 | MOSavg |
|---|---|
| No Align | 4.44 |
| Attention (仅注意力) | 4.44 |
| MSE (仅损失函数) | 4.46 |
| Attention+CE | 4.48 |
| Attention+MSE | 4.48 |
| 结论:注意力与损失函数结合(Attention+MSE/CE)效果最佳,显著优于无对齐基线。 |
VAD层选择消融实验(表3,基于Exp 6):
| VAD预测层 | MOSavg | ERLE (dB) |
|---|---|---|
| layer 3 | 4.48 | 70.15 |
| layer 5 | 4.51 | 78.69 |
| layer 8 | 4.49 | 74.86 |
| layer 10 | 4.48 | 66.06 |
| 结论:从第5层提取VAD进行掩码,ERLE和MOSavg均达到最优。 |
时间延迟估计可视化(图2):
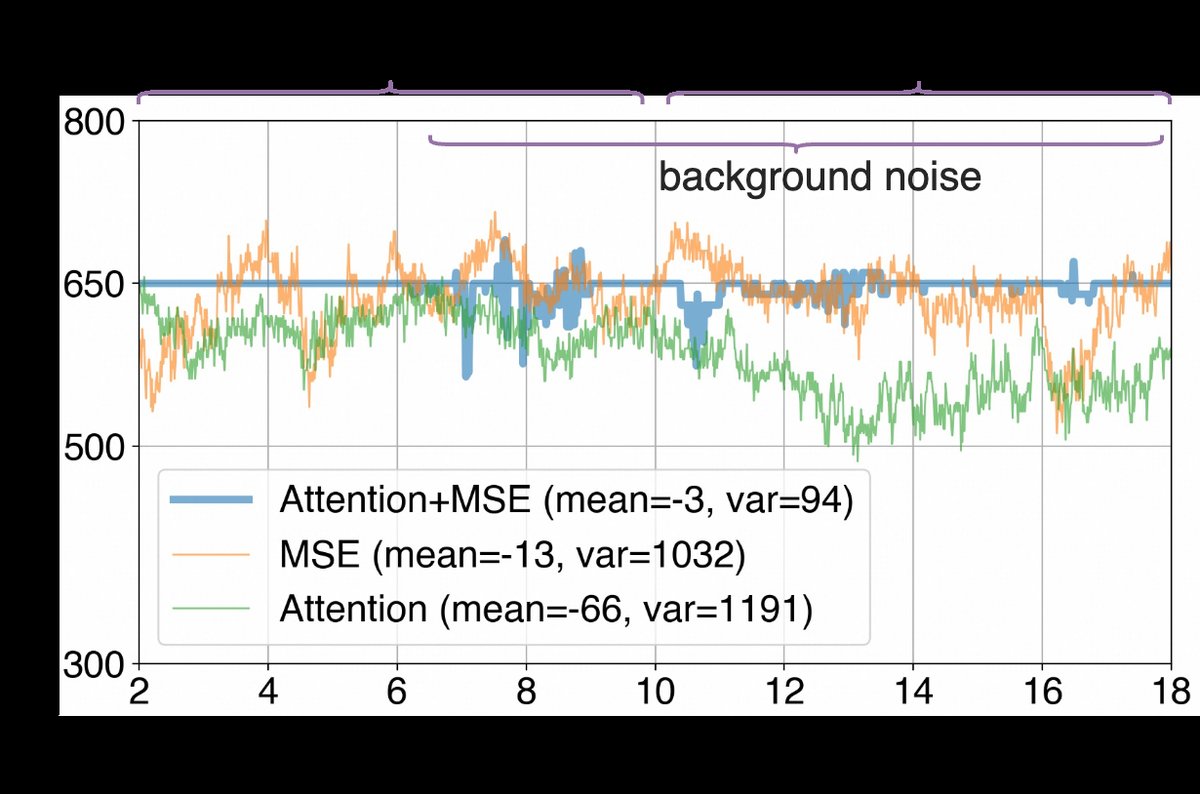 图示:显示了650ms真实延迟下,不同方法的延迟估计曲线。
图示:显示了650ms真实延迟下,不同方法的延迟估计曲线。Attention+MSE(红线)最接近真实值(灰色虚线),平均误差仅-3ms,方差94ms,在声学场景变化(如6s引��噪声,10s转为双讲)时能快速收敛。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性:提出了一个完整、有效的端到端AEC解决方案,创新在于集成与优化,而非提出革命性的新模块。
- 技术正确性:方法设计合理,各模块作用明确,实验结果与方法贡献一致。
- 实验充分性:在标准竞赛数据集上进行了全面的主实验和消融实验,数据详实。但缺少对极端或复杂声学条件的测试。
- 证据可信度:基于公开挑战,指标标准。但Exp6的超高ERLE(78.69dB)可能引起对其泛化能力的疑虑。
- 选题价值:1.5/2
- 前沿性:处于AEC技术从混合系统向纯神经网络系统过渡的研究前沿。
- 应用空间:直接服务于实时音视频通信,应用场景明确且广泛。
- 开源与复现加成:0.0/1
- 代码/模型:论文未提及提供代码或预训练模型。
- 训练细节:仅给出部分超参数和模型大小,缺乏关键训练配置(优化器、学习率等),复现难度较高。