📄 Dynamic Spectrogram Analysis with Local-Aware Graph Networks for Audio Anti-Spoofing
#音频深度伪造检测 #图神经网络 #自监督学习 #动态卷积
🔥 8.5/10 | 前10% | #音频深度伪造检测 | #图神经网络 | #自监督学习 #动态卷积
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yingdong Li(中山大学计算机学院)
- 通讯作者:Kun Zeng(中山大学计算机学院, zengkun2@mail.sysu.edu.cn)
- 作者列表:Yingdong Li(中山大学计算机学院)、Chengxin Chen(中国移动互联网公司,中国移动通信集团公司)、Dong Chen(中山大学计算机学院)、Nanli Zeng(中国移动互联网公司,中国移动通信集团公司)、Kun Zeng(中山大学计算机学院)
💡 毒舌点评
亮点在于将动态卷积与物理视角的多视图频谱分析相结合,并为强大的AASIST图网络框架增加了巧妙的局部信息聚合机制(LVM和SRM),技术融合顺畅且针对性强。短板是双分支前端(SSL + 频谱)不可避免地带来了计算开销,论文未对模型效率(如参数量、推理速度)进行分析或讨论,这在实际部署中可能是一个考量点。
🔗 开源详情
- 代码:论文中提供了代码仓库链接:
https://github.com/lydsera/LocalSpoofDetect。 - 模型权重:论文中未提及是否公开模型权重。
- 数据集:使用的是公开数据集(ASVspoof 2019 LA, CFSD),论文未提及自行发布新数据集。
- Demo:论文中未提及提供在线演示。
- 复现材料:论文中提供了详尽的实现细节(见3.2节),包括音频采样率、频谱图参数、SSL模型处理方式、训练优化器、学习率、批大小、损失函数、数据增强方法(RawBoost)以及训练硬件(A100 GPU),为复现提供了充分信息。
- 引用的开源项目:
- wav2vec 2.0 (XLS-R模型)
- RawNet2
- AASIST (原始架构)
- RawBoost (数据增强方法)
📌 核心摘要
- 问题:针对日益多样的语音深度伪造技术,现有音频反欺骗方法在模型复杂度和鲁棒性之间难以取得平衡,且固定的特征提取方式难以自适应地捕获不同尺度的伪造痕迹。
- 方法核心:提出一个双分支前端与增强图网络后端相结合的模型。前端包含自监督(SSL)分支和新设计的频谱分析分支。频谱分支采用“对称性引导内核选择(SKS)”块,通过物理视角(时间/频谱对称性)分析生成上下文图,动态加权不同尺度的卷积核。后端在AASIST框架上新增了“局部变化主节点(LVM)”和“稀疏残差主节点(SRM)”,以建模精细的局部伪造模式。
- 创新点:(i) 利用频谱对称性指导动态卷积,自适应捕获多尺度伪造伪影;(ii) 采用残差式快捷连接简化前端特征融合,无需复杂融合模块;(iii) 增强图神经网络后端,引入LVM和SRM节点以聚合局部判别信息。
- 实验结果:在ASVspoof 2019 LA和中文伪造语音数据集(CFSD)上取得了当前最优性能,EER分别为0.08%和0.10%,min t-DCF为0.0024。消融实验证实了每个提出组件的有效性。
- 实际意义:该模型能有效、鲁棒地检测合成与伪造语音,可增强语音生物识别等系统的安全性,对抵御日益逼真的语音伪造攻击具有重要价值。
- 主要局限性:未分析模型的计算效率(参数量、FLOPs、推理延迟),可能限制其在资源受限场景的应用;双分支架构对SSL预训练模型的依赖性较强。
🏗️ 模型架构
模型整体架构为双分支前端 + 增强图网络后端,具体流程如下:
- 输入:原始音频波形。
- 前端双分支:
- 波形分支(SSL Branch):采用预训练的wav2vec 2.0 XLS-R模型提取帧级特征,经过线性投影降维至128维,再通过后处理模块和RawNet2编码器生成特征。该分支旨在利用自监督学习的强大泛化表征。
- 频谱分支(Spectrogram Branch):这是本文核心创新之一。输入为128维的梅尔频谱图。首先构建三个视图:原始视图(X1)、时间翻转视图(X2)和频谱翻转视图(X3)。一个共享的2D卷积特征提取器分别处理这三个视图,得到f1, f2, f3。接着计算时间不一致图(dt=|f1-f2|)和频谱不一致图(df=|f1-f3|),将五张特征图拼接成5通道的“上下文图C”。该图通过一个轻量级通道注意力模块生成自适应的卷积核权重α。然后,在原始特征图f1上应用三个不同尺度(3x3,5x5,7x7)的卷积核,其输出用α进行加权求和,得到SKS块的输出Y。该分支堆叠两个SKS块以进行层级特征提取。最后,通过一个位置编码器(利用自注意力机制)生成位置嵌入(PosT和PosS)。
- 前端特征整合:频谱分支的位置嵌入(PosT和PosS)通过残差式快捷连接(Residual-style shortcut) 直接与波形分支自注意力模块的输出相加,从而生成统一的表示,馈入后端。这一设计免除了独立的特征融合模块。
- 后端增强图网络(基于AASIST):
- 统一的表示被送入AASIST的时域图和频域图模块。
- 核心创新在于多尺度异质堆叠图注意力层(M-HS-GAL)。在原有的“全局主节点”基础上,引入了两种新的局部主节点:
- 局部变化主节点(LVM):通过计算每个节点的“变化率(VR)”(即节点特征与其他节点特征的注意力加权L2距离),选择变化率最高的τ比例节点组成“变化区域(Region V)”。LVM节点通过注意力机制聚合该区域节点的信息。
- 稀疏残差主节点(SRM):计算每个节点相对于所在域均值的残差向量,并基于残差的幅度、方差和稀疏度计算异���分数(AS)。选择异常分数最高的节点组成“残差区域(Region R)”。SRM节点同样通过注意力机制聚合这些节点的残差信息。
- 输出:在读出阶段,聚合来自五个来源的信息:全局主节点、LVM节点、SRM节点、以及时域/频域节点的平均池化和最大池化表示。最终通过分类器输出真伪判断。
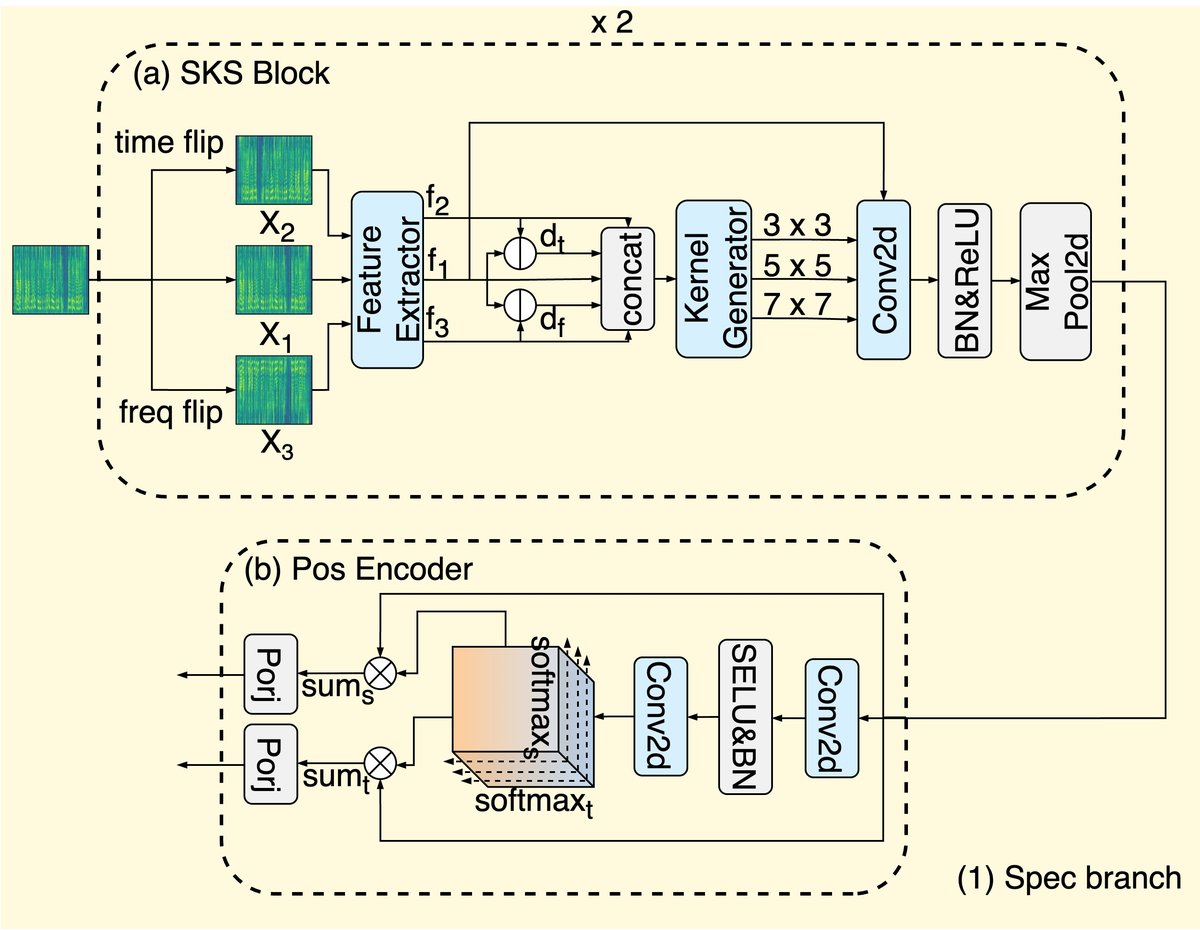 图2:提出的模型架构概览。展示了双分支前端(频谱分支包含SKS块,波形分支使用wav2vec 2.0)通过残差式快捷连接整合,并馈入增强的AASIST图网络后端。后端中的M-HS-GAL层包含了新增的局部主节点(LVM和SRM)。
图2:提出的模型架构概览。展示了双分支前端(频谱分支包含SKS块,波形分支使用wav2vec 2.0)通过残差式快捷连接整合,并馈入增强的AASIST图网络后端。后端中的M-HS-GAL层包含了新增的局部主节点(LVM和SRM)。
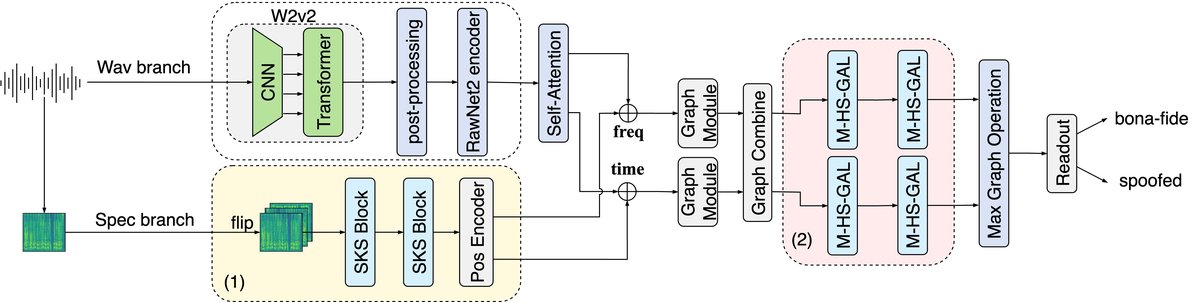 图3:频谱分支的详细架构。输入梅尔频谱被构建为三个视图,经共享卷积提取后生成上下文图C。C通过轻量级注意力模块生成权重,用于动态加权不同尺度的卷积。最后通过位置编码器生成嵌入。
图3:频谱分支的详细架构。输入梅尔频谱被构建为三个视图,经共享卷积提取后生成上下文图C。C通过轻量级注意力模块生成权重,用于动态加权不同尺度的卷积。最后通过位置编码器生成嵌入。
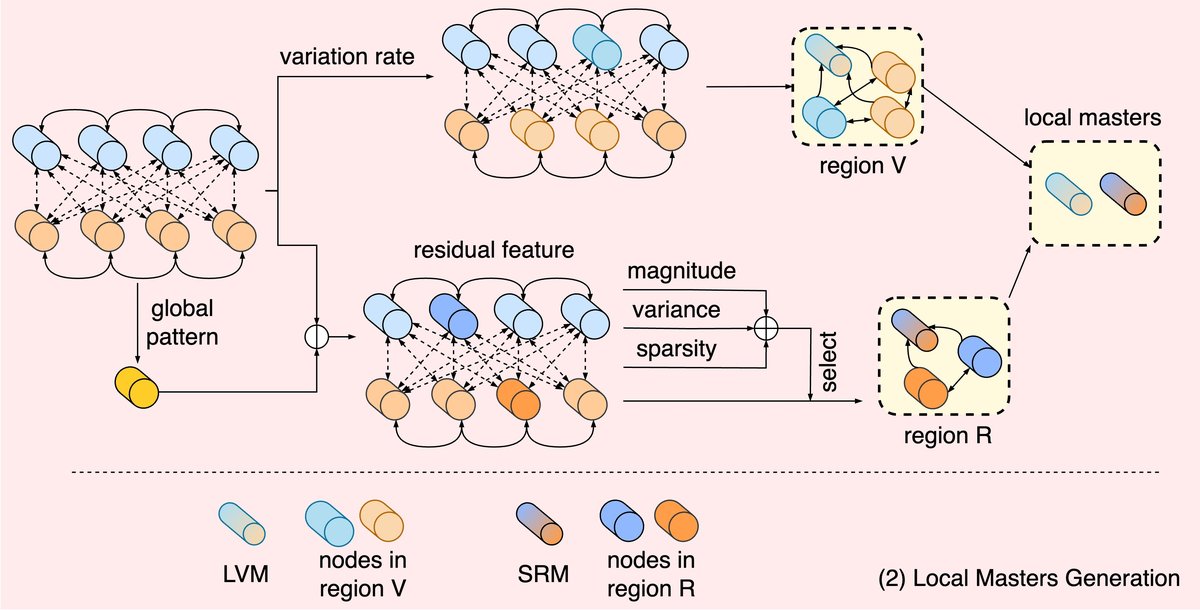 图4:M-HS-GAL模块中局部主节点的生成过程。LVM从基于变化统计划分的时间/频率图中选择节点;SRM则基于残差的幅度、方差和稀疏度选择节点。
图4:M-HS-GAL模块中局部主节点的生成过程。LVM从基于变化统计划分的时间/频率图中选择节点;SRM则基于残差的幅度、方差和稀疏度选择节点。
💡 核心创新点
对称性引导的内核选择(SKS)块:
- 是什么:一种用于频谱图的动态卷积模块。它利用物理视角(时间翻转、频谱翻转)生成“上下文图”,以此为指导,自适应地加权不同尺度(3,5,7)的卷积核。
- 之前局限:标准固定大小卷积核难以同时有效捕获多种尺度的伪造伪影(如图1所示)。
- 如何起作用:通过对称性分析突出异常模式(不一致性图),为通道注意力模块提供丰富上下文,使其能根据输入频谱内容动态分配不同尺度卷积核的权重。
- 收益:使模型能更灵活、自适应地提取多尺度判别特征,提升对多样化伪造攻击的鲁棒性。消融实验证明其有效性。
残差式快捷连接的前端整合策略:
- 是什么:将频谱分支的位置嵌入直接通过残差加法与波形分支的特征相加,然后送入后端。
- 之前局限:多特征融合通常需要设计复杂的融合模块(如跨注意力、拼接+投影),增加了模型复杂度和训练难度。
- 如何起作用:利用残差连接实现简单、直接的特征互补融合,假设两个分支的特征在表示空间上可加。
- 收益:大幅简化了模型架构,消除了专用融合模块,同时保持了优异性能。消融实验(表2)显示,仅此简化整合(0.12% EER)已优于需要复杂融合的WaveSpect等方法。
增强AASIST框架的局部主节点(LVM和SRM):
- 是什么:在AASIST的异构图中引入两个新的节点类型,分别建模高变化区域和稀疏残差区域。
- 之前局限:原AASIST仅依赖一个“全局主节点”聚合信息,可能忽略关键的局部伪造模式。
- 如何起作用:LVM关注特征变化剧烈的节点,SRM关注残差向量异常(大、不规则、稀疏)的节点。它们分别通过注意力机制聚合所选区域的细粒度信息。
- 收益:使后端分类器能直接访问前端提取的、最具判别性的局部特征,增强检测灵敏度。消融实验(表2)表明,两者结合能带来显著性能提升。
🔬 细节详述
- 训练数据:
- ASVspoof 2019 LA(英文,包含多种攻击类型)。
- 中国伪造语音数据集(CFSD,大规模中文数据集)。
- 预处理:重采样至16kHz,切分为5秒片段(80,000样本)。
- 数据增强:在原始波形上应用RawBoost数据增强技术。
- 类别权重:由于类别不平衡,使用加权交叉熵损失,真实/伪造样本权重为0.1/0.9。
- 损失函数:加权交叉熵损失(Weighted Cross-Entropy Loss)。
- 训练策略:
- 优化器:Adam,学习率 1×10⁻⁶,权重衰减 1×10⁻⁴。
- 训练轮数:100 epochs。
- 批大小(Batch Size):14。
- 无warmup、调度策略等信息,论文中未说明。
- 关键超参数:
- SSL分支:wav2vec 2.0 XLS-R,帧级输出1024维,投影至128维。
- 频谱分支:128维梅尔频谱图,1024点FFT,256样本跳跃长度。
- SKS块:并行卷积核大小为3×3,5×5,7×7。
- 后端局部主节点选择比例τ:论文未明确给出具体值,只提到“top ⌈τN⌉ nodes”。
- SRM异常分数权重 wm, wv, ws:论文未明确给出具体值,只提到是“tunable hyperparameters”。
- 稀疏度计算阈值 λ = 0.1。
- 训练硬件:单块 NVIDIA A100 GPU。
- 推理细节:论文中未说明解码策略、温度、beam size等信息。评估时使用在开发集上取得最佳EER的模型检查点。
- 正则化/稳定训练技巧:除加权损失处理类别不平衡外,论文中未提及其他技巧。
📊 实验结果
论文在两个主要数据集上与多项SOTA工作进行了对比,结果如下:
表1:在ASVspoof 2019 LA, 2021 LA 和 CFSD评估集上的性能对比(越低越好)
| 系统 | 19LA min t-DCF↓ | 19LA EER↓ | 21LA EER↓ | CFSD EER↓ |
|---|---|---|---|---|
| RawNet2 [9] | 0.0330 | 1.12% | — | 0.99% |
| RawGAT-ST [25] | 0.0335 | 1.06% | — | 0.74% |
| AASIST [20] | 0.0275 | 0.83% | 20.35% | 0.91% |
| S2pecNet[26] | 0.0240 | 0.77% | — | — |
| w2v2+AASIST [11] | 0.0064 | 0.20% | 0.82% | 0.79% |
| w2v2+AASIST2 [13] | — | 0.15% | 1.61% | — |
| WaveSpect [15] | 0.0048 | 0.15% | — | 0.14% |
| w2v2+STCA+LMDC [18] | 0.0028 | 0.09% | 0.78% | — |
| Ours | 0.0024 | 0.08% | 0.72% | 0.10% |
关键结论:本文提出的模型在ASVspoof 2019 LA和CFSD两个数据集上均达到了最优性能(EER 0.08% 和 0.10%),且优势明显。
消融实验(ASVspoof 2019 LA数据集)
| 系统配置 | min t-DCF↓ | EER↓ |
|---|---|---|
| 基线(w2v2+AASIST)[11] | 0.0064 | 0.20% |
| 前端消融 | ||
| + 频谱分支(复制X1) | 0.0040 | 0.12% |
| + 频谱分支(多视图)(a) | 0.0029 | 0.11% |
| 后端消融 | ||
| + LVM | 0.0057 | 0.18% |
| + SRM | 0.0054 | 0.18% |
| + LVM + SRM (b) | 0.0044 | 0.14% |
| 完整模型 (a+b) | 0.0024 | 0.08% |
关键结论:
- 前端有效:即使是简单的频谱分支(复制通道)也能显著提升性能(0.20% -> 0.12%)。引入多视图分析后性能进一步提升。
- 后端有效:LVM和SRM单独使用时带来适度提升,二者结合带来更大幅度提升(0.20% -> 0.14%)。
- 协同效应:完整模型整合前端(a)和后端(b)创新后,达到最佳性能(0.08%),证明了前后端设计的互补性。
⚖️ 评分理由
- 学术质量:6.5/7
- 创新性:提出了SKS块和图网络局部主节点两个有洞察力的创新点,技术设计新颖且针对性强。
- 技术正确性:架构逻辑清晰,公式推导明确,模块间数据流合理。
- 实验充分性:在两个不同语言、不同攻击类型的权威基准上测试,并提供了详尽的消融研究,充分验证了各组件的有效性。
- 证据可信度:报告的SOTA数字(EER 0.08%)具有显著竞争力,消融实验中的数字变化一致且合理,支撑了论文的主张。
- 选题价值:1.5/2
- 前沿性:音频深度伪造检测是当前语音安全领域的热点和难点。
- 潜在影响:研究成果可直接应用于增强语音生物识别系统、电话银行等场景的安全性。
- 实际应用空间:明确,市场需求迫切。
- 读者相关性:对从事语音安全、反欺骗、音频分析的读者有高参考价值。
- 开源与复现加成:0.5/1
- 代码:论文明确提供了GitHub代码仓库链接(
https://github.com/lydsera/LocalSpoofDetect)。 - 复现材料:提供了非常详细的训练超参数(学习率、batch size、优化器、损失权重等)、数据预处理和增强方法(RawBoost),复现指导性强。
- 模型权重与数据集:未提及公开预训练权重或数据集(但使用的是公开基准)。
- Demo:未提及。
- 代码:论文明确提供了GitHub代码仓库链接(