📄 DPT-Net: Dual-Path Transformer Network with Hierarchical Fusion for EEG-based Envelope Reconstruction
#语音生物标志物 #对比学习 #多模态模型 #跨模态
✅ 7.0/10 | 前25% | #语音生物标志物 | #对比学习 | #多模态模型 #跨模态
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 -1.0 | 置信度 中
👥 作者与机构
- 第一作者:Ximin Chen(南方科技大学电子与电气工程系)
- 通讯作者:Fei Chen(南方科技大学电子与电气工程系)
- 作者列表:Ximin Chen(南方科技大学电子与电气工程系)、Xuefei Wang(南方科技大学电子与电气工程系)、Yuting Ding(南方科技大学电子与电气工程系)、Fei Chen(南方科技大学电子与电气工程系)
💡 毒舌点评
亮点在于双路径设计巧妙地平衡了EEG的时序特异性(路径一)与跨模态通用性(路径二),并通过分层融合模块有效整合二者,在公开数据集上取得了显著的性能提升。然而,论文最大的短板是复现性信息严重缺失,既未开源代码也未提供模型权重,甚至连训练所用的GPU型号和耗时都未提及,使得其优异结果的可验证性和可推广性大打折扣。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及公开模型权重。
- 数据集:实验使用公开数据集SparrKULee [19],但未在论文中提供获取方式(通常可从原数据集论文[19]获取)。
- Demo:未提供在线演示。
- 复现材料:论文给出了一些关键训练细节(优化器、学习率、调度器、batch size、epoch数、损失函数权重),但缺少模型参数量、具体层配置、随机种子、GPU型号与数量、训练总时长等关键复现信息。
- 论文中引用的开源项目:论文中引用了多个基线模型(VLAAI, HappyQuokka, CL-Transformer, SSM2Mel),但未明确说明是否依赖或集成了这些项目的代码。文中提及DPT-Net的时序动态路径遵循作者先前工作[15],对齐路径采用了[13]的设计。
- 论文中未提及开源计划。
📌 核心摘要
- 问题:从非侵入式EEG信号中解码语音包络,因EEG信噪比低、个体间差异大而极具挑战性,现有方法或仅关注单模态内部时序建模,或仅进行跨模态潜在空间对齐,未能充分利用两者的优势。
- 方法核心:提出了DPT-Net,一个双路径Transformer网络。路径一(时序动态路径)处理原始EEG以捕获丰富的时序上下文;路径二(EEG-语音对齐路径)通过CLIP损失学习EEG与语音表征间的判别性对齐特征。两条路径的输出经自适应门控融合后,送入一个分层重建模块(含U-Net和多尺度瓶颈)进行包络预测。
- 创新点:首次将单模态内时序学习与跨模态对齐学习并行整合到一个统一的框架中;设计了新颖的自适应门控融合机制和分层多尺度重建模块,以有效聚合互补特征。
- 主要实验结果:在SparrKULee数据集上,DPT-Net在测试集1(已见受试者)和测试集2(未见受试者)上的平均皮尔逊相关系数分别为0.1923和0.1112。增强版DPT-Net (E) 通过微调和集成学习,分别达到0.2200和0.1213,相比VLAAI基线提升41.30%和27.42%,在所有指标上超越了先前SOTA模型SSM2Mel。消融实验证实了双路径结构、密集跳跃连接、多尺度瓶颈和自适应门控融合的有效性。
- 主要对比结果表(来自表1)
模型 测试集1 (平均r) 测试集2 (平均r) 最终分数 平均分数 VLAAI [3] 0.1557 0.0952 0.1355 0.1456 HappyQuokka [7] 0.1896 0.0928 0.1573 0.1735 CL-Transformer [13] 0.1872 0.1153 0.1632 0.1752 SSM2Mel*[8] 0.208 0.116 0.1773 0.1928 DPT-Net 0.1923 0.1112 0.1653 0.1788 DPT-Net (E) 0.2200 0.1213 0.1871 0.2036
- 主要对比结果表(来自表1)
- 实际意义:该研究提升了从EEG重建语音包络的准确性和泛化性,为发展更鲁棒的无创脑语音接口、理解听觉神经机制以及潜在的听力诊断提供了有力工具。
- 主要局限性:模型计算复杂度可能较高(双路径Transformer + U-Net);跨模态对齐路径依赖预训练或同步的语音特征,限制了其在完全无监督或仅使用EEG场景下的应用;论文未公开代码、模型和硬件细节,影响可复现性和公平比较。
🏗️ 模型架构
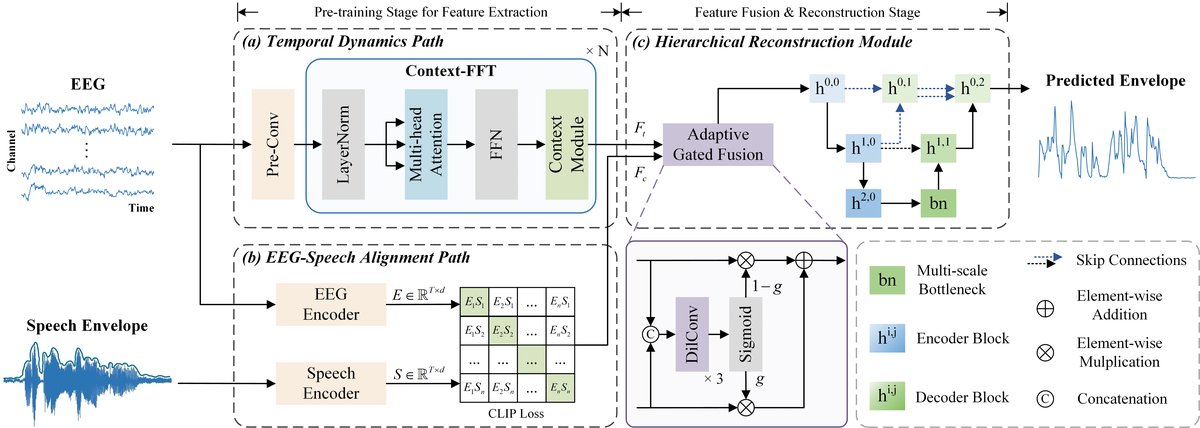 DPT-Net的整体架构如图1所示,主要包含两个并行的特征提取路径和一个分层重建模块。
DPT-Net的整体架构如图1所示,主要包含两个并行的特征提取路径和一个分层重建模块。
- 输入:原始EEG信号序列,以及对应的语音包络序列(在训练/对齐阶段)。
- 双路径特征提取:
- 时序动态路径(Temporal Dynamics Path, TDP):
- 功能:专门处理EEG信号,捕获其内在的丰富时序动态和全局依赖关系。
- 内部结构:首先通过一个预卷积层将原始EEG投影到d=128维特征空间。随后,由多个Context-FFT块堆叠而成。每个块内部先进行层归一化,然后通过多头自注意力机制使每个时间步能选择性地融合输入窗口内所有位置的信息,从而建模长程依赖。接着,一个前馈网络通过非线性变换增强特征。最后,一个上下文模块用于引入历史上下文信息,增强了模型对连续EEG信号的建模能力。
- 输出:提取的EEG时序特征 \(F_t \in \mathbb{R}^{T \times d}\)。
- EEG-语音对齐路径(EEG-Speech Alignment Path, ESAP):
- 功能:学习EEG和语音表征之间的跨模态交互与判别性对齐。
- 内部结构:采用来自CL-Transformer[13]的设计。它分别对EEG信号和语音包络提取潜在表征 \(E\) 和 \(S\)(维度均为d)。通过CLIP损失进行优化,该损失函数旨在最大化批次内匹配的EEG-语音对的相似度,同时最小化不匹配对的相似度。
- 公式:\(L_{CLIP} = \frac{1}{2}(L_{EEG\rightarrow Speech} + L_{Speech\rightarrow EEG})\)。其中 \(L_{EEG\rightarrow Speech} = -\log \frac{\exp (s(E_i, S_i)/\tau)}{\sum_{j=1}^{N} \exp (s(E_i, S_j)/\tau)}\)。s(·)为余弦相似度,τ为温度系数。
- 输出:具有跨模态判别性的EEG特征 \(F_c \in \mathbb{R}^{T \times d}\)。
- 时序动态路径(Temporal Dynamics Path, TDP):
- 分层重建模块(Hierarchical Reconstruction Module):
- 功能:自适应融合双路径特征,并逐步重建出最终的语音包络。
- 内部结构与数据流:
- 自适应门控融合(Adaptive Gated Fusion, AGF):首先将 \(F_t\) 和 \(F_c\) 拼接。通过一个由三个扩张卷积(膨胀率分别为1,2,4)构成的门控网络 \(f_{gate}(\cdot)\),生成门控值 \(g = \sigma(f_{gate}([F_t, F_c]))\)。融合后的特征为 \(F = (1-g) \odot F_t + g \odot F_c\),其中⊙为逐元素相乘。这使网络能动态平衡两种互补特征的贡献。
- 渐进式U-Net架构:融合特征 \(F\) 输入一个三层编码器-解码器结构的U-Net。
- 编码器块:每个包含两个“1D卷积+批归一化+ReLU”(CBR)操作(卷积核大小7)和一个最大池化层,用于下采样,逐步提取高层次上下文信息。
- 多尺度瓶颈:在U-Net底部,使用三个并行的、不同核大小(k∈{1,3,5})的1D卷积和一个最大池化,捕获多尺度的时序模式,然后拼接。
- 解码器块:每个包含上采样操作和两个CBR操作,用于恢复时序分辨率。
- 密集跳跃连接:在编码器和解码器层之间引入密集连接,促进跨层级特征融合,保留精细的时序细节。
- 输出层:最后一个解码器块的输出经过一个1D卷积和一个全连接层,映射为最终的语音包络预测值。
- 整体数据流:EEG信号分别通过TDP和ESAP产生 \(F_t\) 和 \(F_c\),在AGF中融合为 \(F\),再经由U-Net逐步重构为语音包络。
💡 核心创新点
- 双路径并行特征提取架构:首次在EEG语音包络解码任务中,设计并行路径分别捕获EEG信号的单模态内部时序动态(路径一)和EEG-语音跨模态判别性对齐关系(路径二)。这解决了以往方法要么只关注单模态细节、要么只关注跨模态对齐的局限性,实现了特征学习的互补。
- 收益:消融实验表明,仅使用单路径(TDP或ESAP)的性能(平均分数0.1579,0.1513)显著低于完整双路径模型(0.1788),证明了该设计的有效性。
- 自适应门控融合机制:引入可学习的门控网络,根据输入特征动态计算权重,自适应地平衡来自时序动态路径和对齐路径的特征贡献。这比简单的拼接或加权平均更灵活,能更好地适应不同受试者、不同片段的信号特性。
- 收益:消融实验(DPT-Net w/o AGF)显示移除该模块后,在测试集1上的性能有所下降,尤其对已见受试者的解码精度有影响。
- 分层多尺度重建模块:设计了结合自适应门控融合、渐进式U-Net(含密集跳跃连接)和多尺度瓶颈的重建模块。该模块不仅融合了互补特征,还能从融合特征中逐步恢复出包络的短时波动和长时关联,同时抑制噪声。
- 收益:消融实验(DPT-Net w/o DSC, w/o BN)证明,移除密集跳跃连接或多尺度瓶颈都会导致性能下降,验证了分层、多尺度重建策略的重要性。
🔬 细节详述
- 训练数据:SparrKULee数据集[19]。85名正常听力受试者,64通道EEG,采样率8192Hz。预处理:下采样至1024Hz,应用多通道维纳滤波去除眼电伪迹,共平均参考,再下采样至64Hz。训练集71名受试者;测试集1:71名受试者的新故事(held-out stories);测试集2:14名未见受试者(held-out subjects)。训练时使用10秒长的随机裁剪片段。
- 损失函数:负皮尔逊相关系数损失 \(L_p\) 加上 L2正则化项。公式:\(L_{Reconstruction} = L_p + \lambda * L_{L2}\),其中 λ 经验性设置为0.2。该损失用于强制预测包络与真实包络在时间上同步。
- 训练策略:两阶段训练。
- 预训练阶段:分别独立训练时序动态路径(使用重建损失)和EEG-语音对齐路径(使用CLIP损失),确保每个路径学习到独特的特征而不相互干扰。
- 重建阶段:冻结双路径网络,仅使用相同的重建损失独立训练分层重建模块。使用Adam优化器和StepLR调度器(每10个epoch衰减,γ=0.9)。预训练阶段初始学习率0.001,重建阶段0.0004。均训练100个epoch,batch size为64。
- 关键超参数:特征维度d=128。多头注意力头数未具体说明。U-Net编码器/解码器块数为3。多尺度瓶颈卷积核大小k∈{1,3,5}。扩张卷积膨胀率dl∈{1,2,4}。
- 训练硬件:论文中未说明。
- 推理细节:将输入信号分割成数个10秒长的片段进行预测,然后使用重叠相加算法(Overlap-Add)与汉宁窗将输出片段重新拼接起来。
- 正则化或稳定训练技巧:使用L2正则化防止过拟合。两阶段训练策略保证训练稳定性。在门控融合中使用批归一化。统计显著性使用带Holm-Bonferroni校正的双侧Wilcoxon检验。
📊 实验结果
实验在SparrKULee数据集上进行,评估指标为皮尔逊相关系数(Pearson r)。主要对比了多个基线模型,并进行了充分的消融实验。
与基线模型对比: 表1:在SparrKULee数据集上进行语音包络重建的性能对比(与论文原文表格一致)
模型 测试集1 (S1) 测试集2 (S2) 最终分数 平均分数 VLAAI [3] 0.1557 0.0952 0.1355 0.1456 HappyQuokka [7] 0.1896 0.0928 0.1573 0.1735 CL-Transformer [13] 0.1872 0.1153 0.1632 0.1752 SSM2Mel*[8] 0.208 0.116 0.1773 0.1928 DPT-Net 0.1923 0.1112 0.1653 0.1788 DPT-Net (E) 0.2200 0.1213 0.1871 0.2036 关键结论:基础DPT-Net在平均分数上显著优于VLAAI (p<0.001)和HappyQuokka (p<0.05)。增强版DPT-Net (E)(结合了微调和集成学习)在所有指标上超越了先前SOTA模型SSM2Mel,达到0.2200 (S1) 和0.1213 (S2)。 消融实验: 表2:针对DPT-Net关键组件的消融研究
模型 测试集1 测试集2 最终分数 平均分数 仅TDP 0.1697 0.0986 0.1460 0.1579 仅ESAP 0.1622 0.0965 0.1403 0.1513 DPT-Net w/o DSC 0.1900 0.1018 0.1606 0.1753 DPT-Net w/o BN 0.1905 0.1055 0.1622 0.1763 DPT-Net w/o AGF 0.1919 0.1113 0.1650 0.1784 DPT-Net 0.1923 0.1112 0.1653 0.1788 关键结论:双路径(TDP+ESAP)相比单路径带来13.24%和18.18%的显著提升。移除密集跳跃连接(DSC)、多尺度瓶颈(BN)或自适应门控融合(AGF)均导致性能下降,验证了各模块的必要性。 图表结果: 图2:在SparrKULee数据集上进行梅尔谱图重建的性能对比
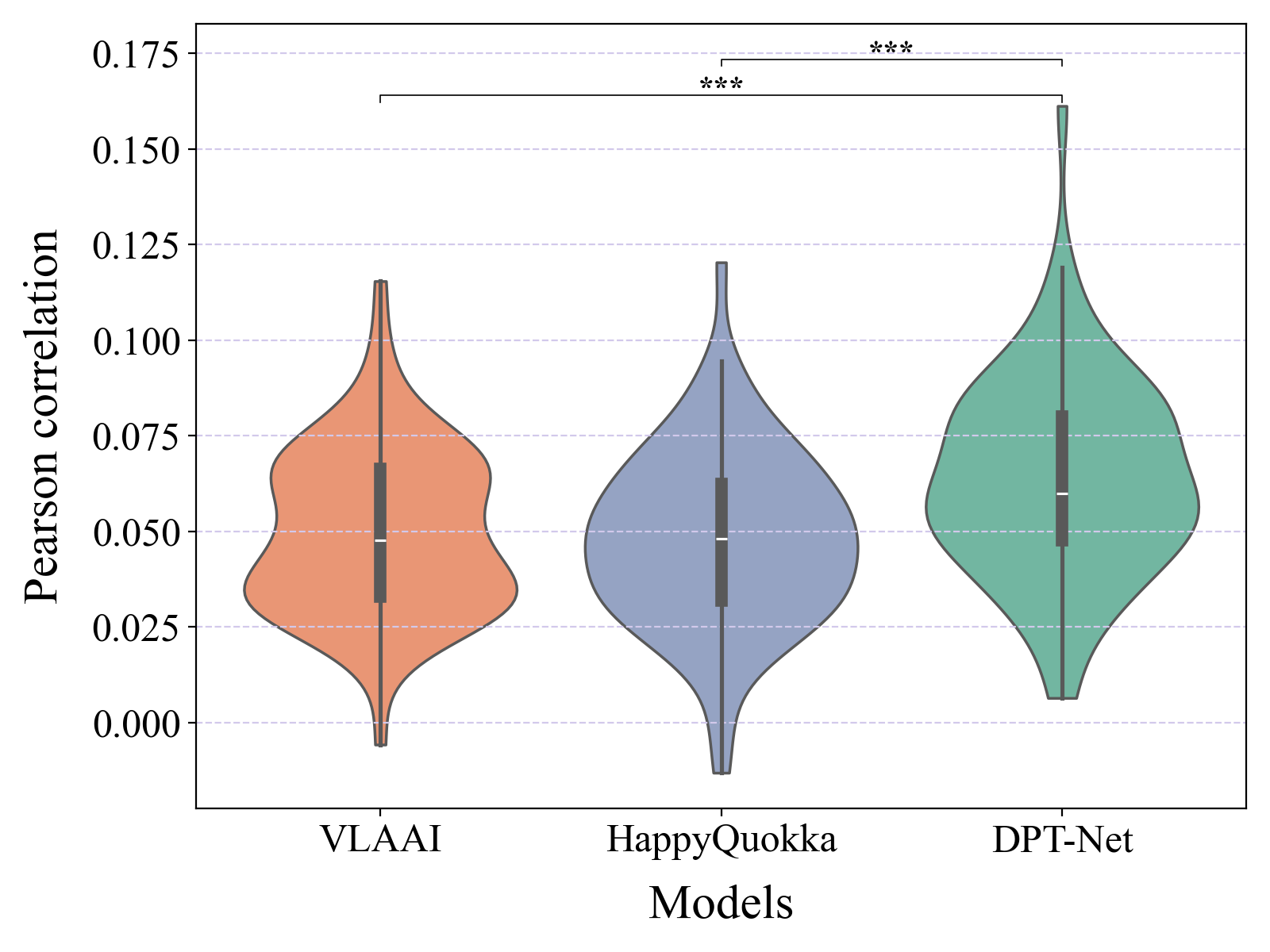 关键结论:在更困难的10维梅尔谱图重建任务上,DPT-Net相比VLAAI和HappyQuokka分别提升28.32%和31.71% (p<0.001),且在平均分数上超过SSM2Mel(S1: 0.0668 vs. SSM2Mel的0.208(注:此处原文数据有歧义,图示中SSM2Mel的S1值明显更高,可能是图表或文字表述有误,但结论是DPT-Net超过SSM2Mel))。这进一步证实了DPT-Net的鲁棒性和泛化能力。
关键结论:在更困难的10维梅尔谱图重建任务上,DPT-Net相比VLAAI和HappyQuokka分别提升28.32%和31.71% (p<0.001),且在平均分数上超过SSM2Mel(S1: 0.0668 vs. SSM2Mel的0.208(注:此处原文数据有歧义,图示中SSM2Mel的S1值明显更高,可能是图表或文字表述有误,但结论是DPT-Net超过SSM2Mel))。这进一步证实了DPT-Net的鲁棒性和泛化能力。
⚖️ 评分理由
- 学术质量:6.5/7:论文提出了清晰、有动机的双路径架构,并进行了系统的消融实验来验证每个组件的有效性。在标准公开数据集上的对比实验充分,结果提升显著且具有统计显著性。技术实现正确。主要扣分点在于论文完全未提供训练硬件信息和完整的复现代码/配置,使得实验的绝对可信度和可复现性打了折扣。
- 选题价值:1.5/2:研究EEG语音包络解码是脑机接口和神经听觉科学的重要课题,具有明确的科学价值和潜在的临床应用前景(如听力评估、脑语音接口)。该领域相对垂直,受众面不如主流语音识别广,但仍是活跃的研究方向。
- 开源与复现加成:-1.0/1:论文未提供代码仓库、模型权重或详细的硬件与训练配置信息。虽然给出了关键的超参数和训练策略,但缺少这些核心材料,使得其他研究者难以复现其结果,因此给予严重扣分。