📄 DPO-Regularized Regression for Age Prediction
#说话人识别 #回归模型 #偏好学习 #DPO #多任务学习
✅ 7.5/10 | 前25% | #说话人识别 | #回归模型 | #偏好学习 #DPO
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Mahsa Zamani(卡内基梅隆大学语言技术研究所)
- 通讯作者:Bhiksha Raj(卡内基梅隆大学语言技术研究所)
- 作者列表:Mahsa Zamani(卡内基梅隆大学语言技术研究所)、Rita Singh(卡内基梅隆大学语言技术研究所)、Bhiksha Raj(卡内基梅隆大学语言技术研究所)
💡 毒舌点评
亮点:将偏好优化(DPO)从语言模型对齐巧妙迁移到连续值回归问题,作为序数损失的监督信号,思路新颖且理论上有说服力,为传统MSE回归提供了有价值的补充。短板:实验仅在TIMIT(630人,20-58岁)这一个相对较小且年龄范围受限的数据集上验证,说服力有限;且未开源代码和模型,对于声称的“state-of-the-art”缺乏与同期最先进方法的直接横向对比。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。论文使用了预训练的TitaNet-Large,但未提供针对此任务微调后的模型权重。
- 数据集:使用的是公开的TIMIT数据集,但未在论文中给出具体的获取链接或预处理脚本。
- Demo:未提及。
- 复现材料:论文提供了较为详细的训练配置(如图1、算法1、第4节实验设置),包括超参数(学习率、批量大小、训练轮数、MLP结构、损失权重、桶数、偏好对数量等),但未提供完整的训练脚本、数据划分或检查点。
- 论文中引用的开源项目:明确依赖并使用了TitaNet-Large [27]作为特征提取器。
📌 核心摘要
本文针对说话人年龄估计这一回归任务中,均方误差(MSE)损失无法有效建模年龄序数关系的问题,提出了一种结合MSE与直接偏好优化(DPO)的混合训练方法。方法的核心是将连续年龄目标离散化为分位数桶,并为每个样本构建偏好对(预测更接近真实年龄的桶为“偏好”,更远的为“非偏好”),通过DPO损失鼓励模型学习这种序数偏好。这不同于传统MSE对误差分布的假设,也不同于简单的分类方法。主要实验在TIMIT数据集上进行,结果表明,结合MSE和DPO的回归+DPO(RD)配置,使用12个桶和30个偏好对时,取得了最佳的平均绝对误差(MAE)3.98,优于仅使用MSE的基线(4.05)和纯分类方法,并接近该数据集上报告的最优水平(3.97)。该方法的意义在于首次将DPO应用于非分类的回归任务,为需要利用序数信息的连续值预测问题提供了一种新思路。主要局限性是实验数据集规模较小、年龄范围不包含青少年和老年,且未与更多现代方法进行对比验证。
表1:不同损失配置在TIMIT数据集上的MAE对比(关键结果)
| 损失配置 | MAE | 桶数量 | 偏好对数量 |
|---|---|---|---|
| RO (仅回归/MSE) | 4.0543 | - | - |
| RD (回归+DPO) | 4.0737 | 6 | 6 |
| RD (回归+DPO) | 4.0454 | 8 | 8 |
| RD (回归+DPO) | 3.9801 | 12 | 30 |
| RD (回归+DPO) | 4.0892 | 12 | 40 |
| RCD (回归+分类+DPO) | 4.0326 | 8 | 30 |
🏗️ 模型架构
本文提出的模型架构旨在同时进行连续值回归和离散类别分类(用于DPO监督),并在推理时丢弃分类头。整体流程如下:
- 特征提取器:使用预训练的TitaNet-Large模型作为语音特征提取器,将输入语音信号转换为192维的说话人嵌入向量。
- 共享编码器与双头架构:
- 共享编码器:一个包含两个隐藏层的多层感知机(MLP),将192维TitaNet嵌入投影到128维(第一层,使用0.3的Dropout),再映射到64维(第二层)。这个共享编码器学习适用于下游任务的表征。
- 回归头:从共享编码器的64维输出,通过一个全连接层直接输出一个标量值,即预测的连续年龄。
- 分类头:从共享编码器的64维输出,通过另一个全连接层输出一个长度为N(桶数量)的logits向量(z),对应于N个离散年龄桶的概率分布。
- 训练与推理:
- 训练阶段:前向传播得到连续年龄预测(ŷ)和桶logits(z)。计算MSE损失(L_MSE)用于回归头,以及DPO损失(L_DPO)和可选的交叉熵损失(L_CE)用于分类头。总损失为L_total = L_MSE + λ L_DPO + γ L_CE。反向传播更新共享编码器和两个头的参数。
- 推理阶段:丢弃分类头,仅使用共享编码器和回归头,输出最终的连续年龄预测值。
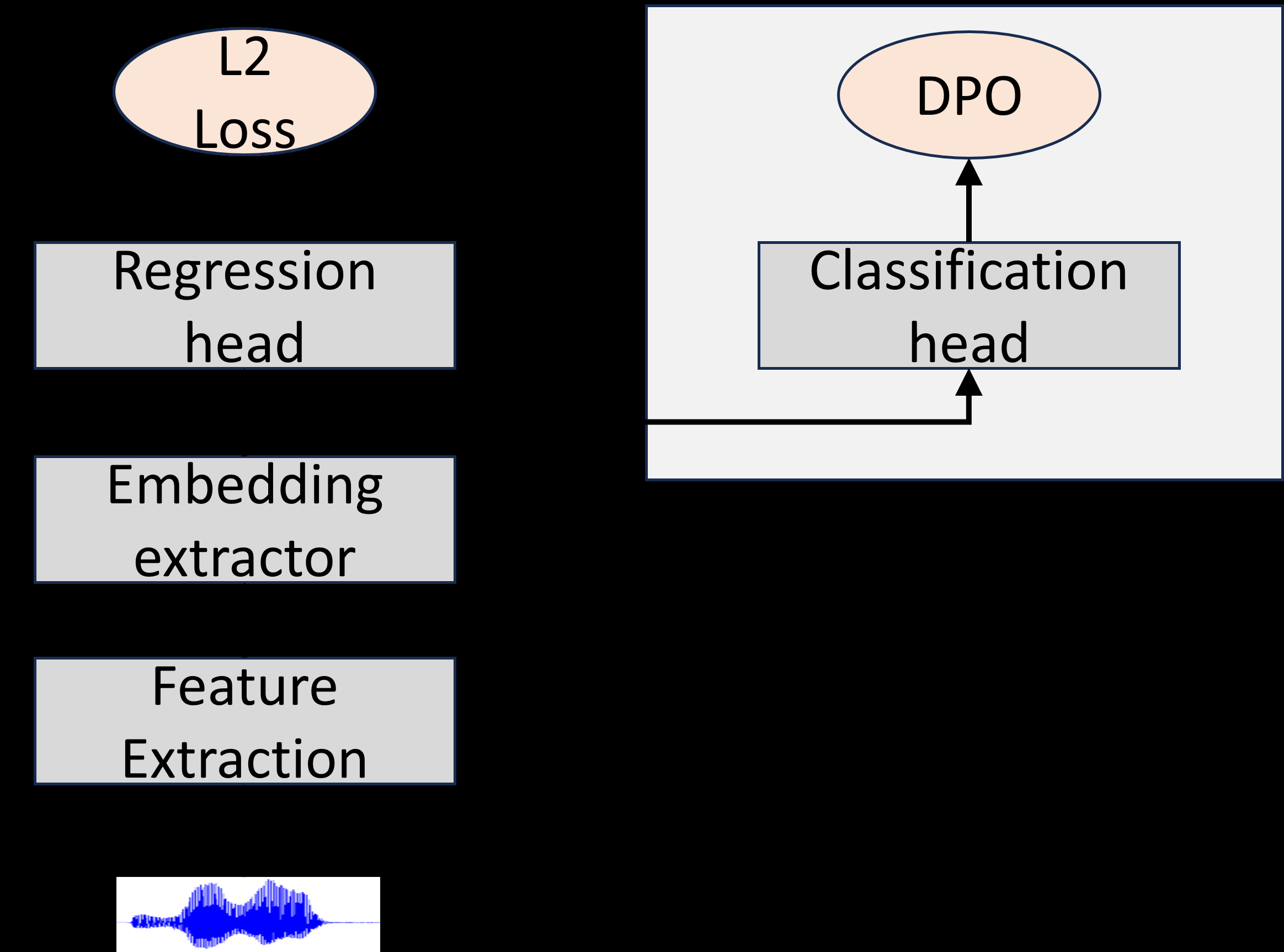 图1清晰地展示了该架构:特征提取器(虚线框内的“regression model”)的输出送入共享MLP,随后分支出回归头(预测年龄)和分类头(预测桶概率)。训练时,MSE损失作用于回归输出,DPO和CE损失作用于分类头的logits。分类头仅在训练时使用。
图1清晰地展示了该架构:特征提取器(虚线框内的“regression model”)的输出送入共享MLP,随后分支出回归头(预测年龄)和分类头(预测桶概率)。训练时,MSE损失作用于回归输出,DPO和CE损失作用于分类头的logits。分类头仅在训练时使用。
 图2展示了基于分位数的年龄范围划分策略。将总年龄范围(a_min, a_max)根据数据分布划分为N个桶,每个桶有一个代表值r(i)。这确保了每个桶在训练数据中有大致相等的样本量,尤其适用于年龄分布不平衡的数据集。
图2展示了基于分位数的年龄范围划分策略。将总年龄范围(a_min, a_max)根据数据分布划分为N个桶,每个桶有一个代表值r(i)。这确保了每个桶在训练数据中有大致相等的样本量,尤其适用于年龄分布不平衡的数据集。
💡 核心创新点
- 首次将DPO应用于连续值回归任务:这是本文最核心的创新。DPO此前主要用于语言模型和生成模型的离散输出(如文本、类别)对齐。作者首次将其扩展到需要预测连续数值的回归问题,通过将连续目标离散化,构建偏好对,让模型学习“哪个预测更接近真实值”的序数关系。
- 提出了DPO正则化的回归训练范式:与标准DPO用于微调不同,本文将DPO损失直接集成到端到端的回归模型训练目标中(公式4),与MSE损失协同工作。这种混合损失设计旨在让模型既学习点的准确性(MSE),又学习序的合理性(DPO)。
- 针对回归任务简化DPO损失:标准DPO公式(公式2)涉及参考模型。作者进行了简化,假设参考分布均匀,并直接基于分类头的logits计算DPO损失(公式3:L_DPO = -log σ(z+ - z−))。这种简化更适用于从头训练回归模型的场景,而非微调。
- 设计了适合回归任务的DPO对采样策略:为了构建有效的训练信号,作者设计了具体的采样方法:排除真实年龄所在的桶,从其余桶中随机选两个,将离真实年龄更近的标记为“偏好”桶,更远的为“非偏好”桶。这确保了DPO对能够提供有意义的序数监督。
🔬 细节详述
- 训练数据:使用TIMIT数据集。包含630位说话人,年龄范围为20-58岁。预处理:未提及具体音频预处理步骤,但使用预训练的TitaNet-Large提取192维嵌入。
- 损失函数:
- MSE损失:L_MSE = ||ŷ - y||²,用于回归头,最小化预测年龄与真实年龄的平方误差。
- DPO损失:L_DPO = 1/P * Σ log(1 + e^(-(z_+ - z_-))),其中P是每个样本的偏好对数量。用于鼓励分类头为“偏好”桶分配更高logits。
- 交叉熵损失(可选):L_CE,用于分类头的标准分类损失。总损失公式为:L_total = L_MSE + λ L_DPO + γ L_CE。
- 训练策略:优化器Adam,学习率0.0001。批量大小64。训练轮数2000。使用验证集MAE选择最佳检查点。
- 关键超参数:
- 年龄桶数量N:实验探索了4、6、8、12、16个桶,最佳为12。
- DPO偏好对数量K:实验探索了6、8、30、40、60,最佳为30。
- DPO损失权重λ:最佳为0.5。
- CE损失权重γ:不使用CE时γ=0;使用时最佳为1.5。
- 分类头输出维度:等于N。
- 回归头结构:两层MLP(192->128->64),隐藏层使用Dropout(0.3)。
- 训练硬件:论文中未提及。
- 推理细节:推理时仅使用回归头输出预测年龄,无需解码策略或温度等参数。
- 正则化/稳定训练技巧:使用Dropout(0.3)防止过拟合。采用分位数分桶确保数据平衡。DPO对采样排除了真实桶,避免信息泄露。
📊 实验结果
主要Benchmark与结果: 在TIMIT数据集上,所有模型使用MAE进行评估。主要结果汇总于表1。
关键对比与消融:
- 基线对比:回归基线(RO,仅MSE)的MAE为4.0543。最佳的回归+DPO(RD)配置(12桶,30对)MAE为3.9801,绝对降低0.0743,相对提升约1.8%。论文声称此结果(3.98)与该数据集此前最优结果(3.97)相当。
- 消融实验:
- 桶数量的影响(RD配置):如表1和图3(a)所示,随着桶数从6增加到12,MAE从4.0737降至3.9801。但桶数增加到16时,MAE回升至4.0791,表明过多的桶导致数据稀疏,性能下降。
- 偏好对数量的影响(RCD配置):如表1和图3(b)所示,在桶数固定为8时,偏好对K从8增加到30,MAE从4.0512改善至4.0326。但论文未显示K=30是否为全局最优(RD配置的最佳K为30)。
- 不同损失配置对比:纯分类(CO)和分类+DPO(CD)的MAE均显著高于回归模型(RO和RD),说明将年龄预测视为纯分类问题并映射到中点值,并非最优策略。回归+分类(RC)配置(如4桶时MAE 4.0806)略逊于RO,表明简单添加分类损失不一定有益。
- 按年龄段分析:论文提供了RO和RD(最佳配置)在各年龄段的详细结果(表2)。
表2:RO与RD(最佳配置)在不同年龄段的详细性能对比
| 年龄段 | RO MAE | RD MAE | 变化 | RO Precision | RD Precision |
|---|---|---|---|---|---|
| 20–30 | 2.899 | 2.861 | -0.038 | 0.746 | 0.735 |
| 30–40 | 4.461 | 4.374 | -0.087 | 0.453 | 0.448 |
| 40–50 | 8.040 | 8.098 | +0.058 | 0.162 | 0.184 |
| 50–60 | 10.815 | 10.281 | -0.534 | 0.818 | 0.909 |
| 总体MAE | 4.0543 | 3.9801 | -0.0743 |
可以看出,DPO在年龄较大、预测难度更高的群体(50-60岁)上带来了最显著的MAE改善(降低0.534)和精确度提升(0.818 -> 0.909),这验证了作者关于DPO在误差方差较大区间更有效的假设。
相关图表:
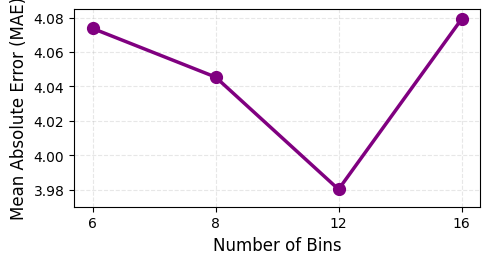 图3(a)展示了RD配置下,MAE随桶数变化的趋势(在12桶时达到最优)。图3(b)展示了RCD配置下,MAE随偏好对数量增加而改善的趋势(至30对)。
图3(a)展示了RD配置下,MAE随桶数变化的趋势(在12桶时达到最优)。图3(b)展示了RCD配置下,MAE随偏好对数量增加而改善的趋势(至30对)。
⚖️ 评分理由
- 学术质量:6.0/7:创新性(强):将DPO从生成模型迁移到回归任务,思路新颖,是论文最大的亮点。技术正确性(强):方法描述清晰,损失函数推导合理,实验设计能够支撑其主张。实验充分性与可信度(中等):实验在标准数据集上进行,包含关键的消融研究(桶数、对数、损失组合),结果可信。但主要短板在于验证的广度与深度不足:仅在一个小规模、年龄范围受限的数据集上验证;未与近年提出的强大说话人表征模型或复杂回归方法(如论文参考文献中[4]提到的Tessellated Linear Model之外的更多方法)进行直接对比;因此,其声称的“state-of-the-art”和“显著改进”的结论需要更多证据支撑。
- 选题价值:1.5/2:前沿性:方法论上的跨领域迁移(偏好学习 -> 回归)具有启发性,是近期机器学习中的一个有趣动向。潜在影响:可能为其他具有序数性质的回归任务提供新思路。实际应用与读者相关性:说话人年龄估计是语音分析中的一个具体应用,对从事说话人分析、人机交互或语音生物标志物研究的读者有价值。但任务本身相对垂直,直接应用影响力有限。
- 开源与复现加成:0.0/1:论文详细公开了所有关键超参数、模型结构和训练策略,可复现性基础良好。但严重缺乏开源资源:未提供代码、预训练的TitaNet或处理后的TIMIT特征。这增加了他人复现的门槛,也使得“更简单模型”(相比[4])的说法无法被快速验证。