📄 Domain Partitioning Meets Parameter-Efficient Fine-Tuning: A Novel Method for Improved Language-Queried Audio Source Separation
#音频分离 #参数高效微调 #领域适应 #预训练
✅ 7.5/10 | 前50% | #音频分离 | #参数高效微调 | #领域适应 #预训练
学术质量 7.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yinkai Zhang(新疆大学计算机科学与技术学院 / 丝绸之路多语言认知计算联合国际实验室 / 新疆多语言信息技术重点实验室)
- 通讯作者:Kai Wang, Hao Huang(新疆大学计算机科学与技术学院 / 丝绸之路多语言认知计算联合国际实验室 / 新疆多语言信息技术重点实验室)
- 作者列表:Yinkai Zhang(新疆大学计算机科学与技术学院等),Dingbang Zhang(新疆大学计算机科学与技术学院等),Tao Wang(新疆大学计算机科学与技术学院等),Diana Rakhimova(哈萨克斯坦阿勒法拉比国立大学信息系统系),Kai Wang(新疆大学计算机科学与技术学院等),Hao Huang(新疆大学计算机科学与技术学院等)。
💡 毒舌点评
亮点:论文巧妙地将LLM领域的“领域划分+PEFT微调”范式迁移到音频分离任务,思路清晰且实验效果扎实,在多个数据集上稳定超越强基线AudioSep。短板:创新更多是框架层面的组合,作为核心组件的ReConv-Adapter是在Conv-Adapter基础上“加宽”而非原创性设计,其参数效率与性能增益的权衡有待更深入探讨。
🔗 开源详情
- 代码:提供开源代码仓库链接:https://github.com/butterflykite/DP-LASS。
- 模型权重:论文中未明确提及是否公开预训练模型或微调后的模型权重。
- 数据集:基于公开数据集AudioSet进行训练,未提供独立的自建数据集。评估使用公开的AudioCaps, Clotho等基准测试集。
- Demo:论文中未提及在线演示(Demo)。
- 复现材料:论文提供了较为充分的复现信息,包括:训练数据构建方式(单类音频,混合采样)、关键超参数(学习率、batch size、训练步数)、硬件配置(RTX 3090 GPU)以及消融实验设置。
- 引用的开源项目:论文依赖并引用了AudioSep的官方实现和预训练模型(https://github.com/Audio-AGI/AudioSep),以及HuggingFace PEFT库(用于DoRA/LoRA的实现)。
📌 核心摘要
- 问题:语言查询音频源分离(LASS)任务面临一个关键挑战:不同声音类别之间特征分布差异巨大,使得单一模型难以有效建模所有类别。
- 方法核心:提出一种结合领域划分(Domain Partitioning) 与参数高效微调(PEFT) 的新方法。首先,使用K-Means对各类音频的CLAP嵌入进行聚类,将训练数据划分为多个子领域;然后,为每个子领域在预训练AudioSep模型上微调一个独立的PEFT模块(ReConv-Adapter);推理时,由子领域分类器将输入路由到对应的模块。
- 创新点:这是首次将“预训练+领域划分微调”的LLM范式应用于LASS任务,并设计了新的PEFT模块ReConv-Adapter(在卷积层添加并行分支并采用零初始化)。
- 实验结果:在六个基准数据集上,本文方法平均SDRi达到9.76 dB,SI-SDR达到9.06 dB,分别比基线AudioSep提升1.01 dB和1.29 dB。关键实验结果如下:
| 方法 | AudioCaps (SDRi/SI-SDR) | VGGSound (SDRi/SI-SDR) | AudioSet (SDRi/SI-SDR) | Music (SDRi/SI-SDR) | ESC-50 (SDRi/SI-SDR) | Clotho v2 (SDRi/SI-SDR) | 平均 (SDRi/SI-SDR) |
|---|---|---|---|---|---|---|---|
| LASS-Net | 3.36 / -0.78 | 1.26 / -4.43 | 1.32 / -3.66 | 0.38 / -12.24 | 3.41 / -2.35 | 2.21 / -3.38 | 1.99 / -4.47 |
| AudioSep | 8.22 / 7.19 | 9.14 / 9.04 | 7.74 / 6.90 | 10.51 / 9.43 | 10.04 / 8.81 | 6.85 / 5.24 | 8.75 / 7.77 |
| CLAPSep | 9.66 / 8.76 | 5.04 / 4.27 | 6.17 / 4.64 | 7.65 / 5.62 | 11.49 / 10.23 | 5.26 / 2.84 | 7.55 / 6.06 |
| Ours (classifier) | 8.92 / 8.02 | 10.04 / 10.06 | 9.06 / 8.46 | 11.46 / 10.56 | 11.13 / 10.50 | 7.92 / 6.75 | 9.76 / 9.06 |
| Ours (oracle) | 9.20 / 8.47 | 10.31 / 10.36 | 9.31 / 8.70 | 11.71 / 11.18 | 11.74 / 11.21 | 8.05 / 7.10 | 10.05 / 9.50 |
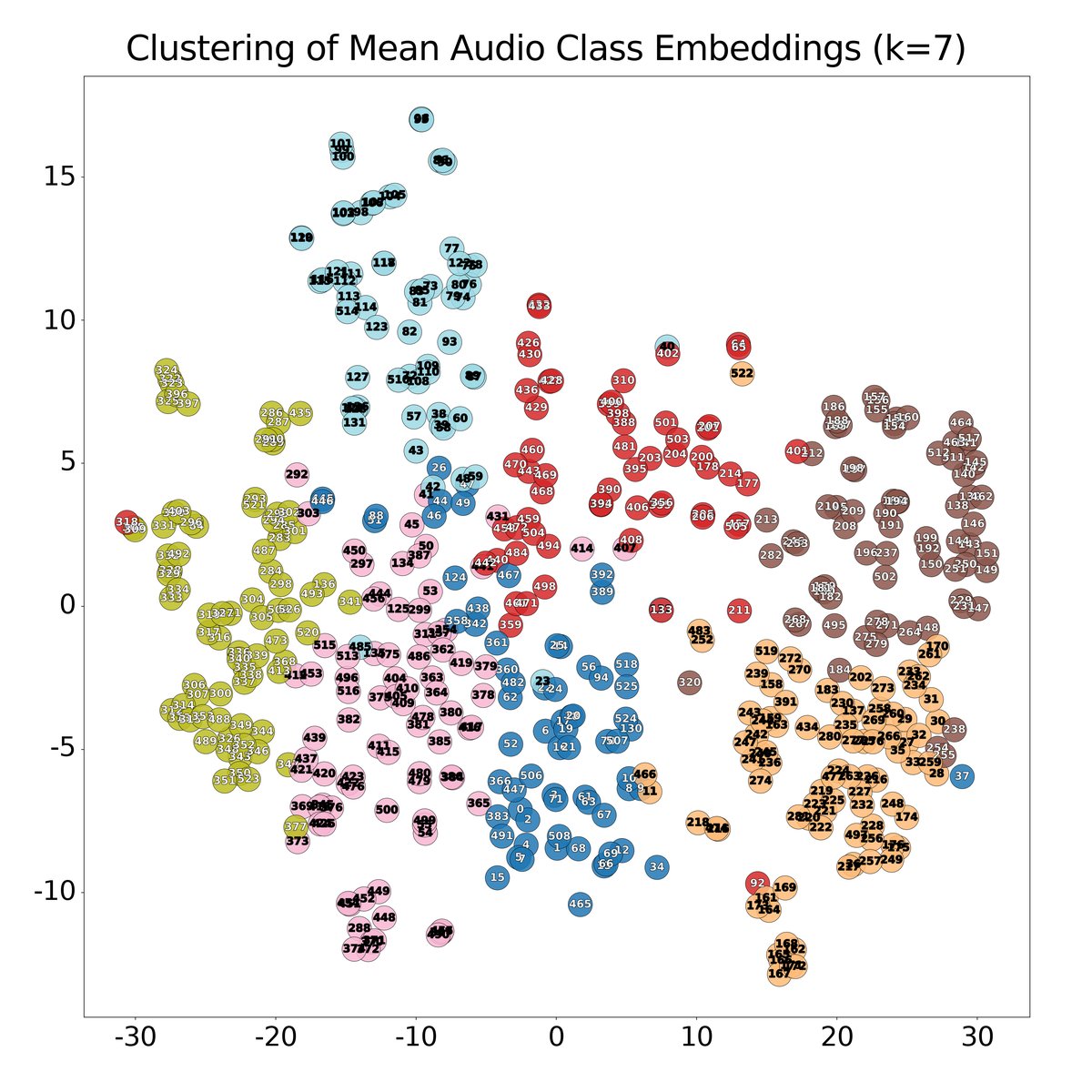
消融研究表明,ReConv-Adapter在参数量(19M)与性能上取得了最佳平衡。子领域划分的有效性通过t-SNE可视化得到验证。
- 实际意义:该方法提供了一种提升通用音频分离模型在特定领域性能的高效范式,具有较好的可扩展性和实用性。
- 主要局限性:1)领域划分依赖于K-Means聚类,子领域数量需手动设定,且划分质量影响最终性能;2)提出的ReConv-Adapter参数量(19M)显著高于DoRA/LoRA(约0.26M),在效率上并非最优选择;3)论文未探讨该方法在更复杂、多目标的现实场景中的泛化能力。
🏗️ 模型架构
本文方法整体架构分为三个连续阶段,旨在将一个通用LASS模型(AudioSep)转化为针对不同声音子领域的“专家集合”。
阶段1:领域划分(Domain Partitioning)
- 输入:完整的AudioSet训练集(仅包含单类别音频)。
- 处理:
- 特征计算:对每个音频类别,使用CLAP的音频编码器计算其所有样本的嵌入均值
e_i。CLAP编码器与基线AudioSep中的文本编码器共享语义空间,保证了嵌入的语义一致性。 - 聚类:使用K-Means算法对所有类别的嵌入向量
{e_i}进行聚类,将其划分为K个子域。每个子域有一个质心c_d。
- 特征计算:对每个音频类别,使用CLAP的音频编码器计算其所有样本的嵌入均值
- 输出:多个数据子域(Subdomain),每个子域包含一组语义或声学特征相似的音频类别。
阶段2:微调(Fine-tuning)
- 输入:预训练的AudioSep模型(QueryNet + SeparationNet)和各子域数据。
- 处理:
- 冻结基座:冻结预训练AudioSep模型的所有参数。
- 插入PEFT模块:为每个子域,在AudioSep的SeparationNet(ResUNet)的每个ResUNet块中,并行插入一个可训练的PEFT模块,即ReConv-Adapter。
- ReConv-Adapter结构(见图2):在原始ResUNet块(包含BN、LeakyReLU、Conv层和FiLM层)的每个卷积层(Conv1, Conv2)旁边,并联一个结构相同的新卷积层分支。这个新分支的所有权重初始化为零(采用ControlNet的零卷积策略),确保训练初期不会扰动原始模型的输出。
- 输出:每个子域对应一组独特的、可训练的ReConv-Adapter模块参数(约19M参数/子域)。基座模型参数保持不变。
阶段3:推理(Inference)
- 输入:待分离的混合音频
m和文本查询c。 - 处理:
- 子领域分类器:该分类器同时接收混合音频和文本。它首先用CLAP的音频和文本编码器分别提取嵌入,拼接成特征向量。然后,该向量依次通过1D卷积、8头注意力层和2层Transformer编码器,最终通过全连接层输出7个分数,对应7个子域(PEFT模块)。
- 路由选择:选择分数最高的子域所对应的ReConv-Adapter模块集。
- 分离:将混合音频和文本查询输入AudioSep模型,但此时在SeparationNet中激活的是路由到的特定ReConv-Adapter模块。最终输出分离后的音频
ˆx。
- 输出:根据文本查询分离出的目标音频源。
关键设计动机:通过领域划分减小子域内的特征分布差异,使每个子域的微调更高效、更专注;通过PEFT(ReConv-Adapter)以较小的参数增量实现领域适应,避免全量微调的高成本和灾难性遗忘;通过子域分类器实现自动化的推理路由。
💡 核心创新点
“领域划分+PEFT”的LASS新范式:
- 是什么:首次将大语言模型中“预训练大模型 + 领域划分 + 参数高效微调”的成功范式,应用于语言查询音频分离任务。
- 之前局限:现有LASS方法(如AudioSep)试图用单一模型处理所有声音类别,但不同类别特征分布差异大,模型容量和优化难度高。
- 如何起作用:通过聚类划分数据子域,将“建模所有类别”这一复杂任务分解为多个“建模相似类别”的子任务。每个子任务通过微调一个轻量级PEFT模块来适配,降低了学习难度。
- 收益:实验表明,该范式在AudioSep基线上取得了平均1.01 dB SDRi和1.29 dB SI-SDR的稳定提升,且具有良好的泛化性。
针对卷积架构的ReConv-Adapter设计:
- 是什么:一种为卷积神经网络(如ResUNet)设计的PEFT模块,在原始卷积层旁添加并行的可学习卷积分支,并采用零初始化。
- 之前局限:原始Conv-Adapter采用瓶颈结构,实验中发现性能提升有限;DoRA、LoRA等主流PEFT方法主要为Transformer设计,直接应用于卷积时需权重矩阵化,可能非最优。
- 如何起作用:直接并行复制卷积层,增加了模型在特定领域的表达能力。零初始化确保训练初期行为与基座模型一致,稳定训练。
- 收益:消融实验显示,在同等数据规模下(AudioSet-Small),ReConv-Adapter(SDRi 8.93)优于Conv-Adapter(8.81)、LoRA(8.66)和DoRA(8.67),证明了其有效性。
高效的子领域分类器:
- 是什么:一个专门训练的小型网络,用于在推理时根据输入音频和文本,预测应使用的子领域(PEFT模块)。
- 之前局限:若没有分类器,推理时需要遍历所有PEFT模块进行尝试,或人工指定,不切实际。
- 如何起作用:结合CLAP的多模态嵌入和轻量级的CNN-Transformer结构,快速、准确地完成路由决策。
- 收益:表1显示,使用分类器的推理结果(9.76 dB)与理论最优的“oracle”选择(10.05 dB)差距很小,证明了该分类器的有效性。
🔬 细节详述
- 训练数据:
- 来源与预处理:基于AudioSet。仅使用单类别音频进行领域划分和微调训练,以提高领域划分准确性和降低计算成本。
- 规模:构建了两个版本:
- AudioSet-Small:11,747个样本,来自平衡训练子集,每类至少10个样本(不足的通过剪切补充)。
- AudioSet-Large:803,171个样本,来自非平衡训练子集,同样保证每类至少10个样本。
- 数据增强:训练时,随机从两个不同类别的音频片段中各取一段(时长2秒)混合,生成训练样本。
- 损失函数:
- 使用L1损失,计算预测波形与目标波形之间的差异。
- 训练策略:
- 微调:学习率
4e-4,优化器未明确说明(可能沿用AudioSep默认设置)。AudioSet-Small训练:单卡RTX 3090,batch size 20,共88,200步。AudioSet-Large训练:4卡RTX 3090,全局batch size 80,共753,000步。 - 子领域分类器训练:使用AudioSet的非平衡子集。损失函数为7类交叉熵损失。训练:4卡RTX 3090,全局batch size 1000,共489,000步。优化器:AdamW,学习率
1e-3。
- 微调:学习率
- 关键超参数:
- 子领域数量
K=7,与AudioSet的七个顶级类别对齐。 - ReConv-Adapter每个模块参数量:19.0M。
- 分类器架构:1D Conv(kernel size 3) -> 8-Head Attention -> 2层 Transformer Encoder -> FC。
- 子领域数量
- 训练硬件:NVIDIA RTX 3090 GPU(1卡或4卡)。
- 推理细节:未说明解码策略、温度等,因为该方法是直接的波形估计,不涉及自回归生成。
- 正则化技巧:
- 零卷积(Zero Convolution):ReConv-Adapter初始化权重为零,是稳定训练的关键技巧。
- 冻结预训练模型:整个微调过程中,AudioSep的基座参数保持冻结。
📊 实验结果
- 主要Benchmark与结果:在AudioSep论文使用的同一套六个测试集(AudioCaps, VGGSound, AudioSet, MUSIC, ESC-50, Clotho v2)上进行评估。核心指标为SDRi和SI-SDR。
- 与主要方法对比(表1):本文方法(使用分类器)在所有测试集上均超越LASS-Net和AudioSep基线,在除AudioCaps和ESC-50外的四个测试集上超越CLAPSep。平均SDRi和SI-SDR分别达到9.76 dB和9.06 dB,相比AudioSep基线(8.75/7.77)提升显著。
- Oracle上限:当可以理想选择最佳PEFT模块时(Ours (oracle)),平均指标进一步提升至10.05/9.50,展示了该框架的潜力上限。
- 消融实验(PEFT方法对比,表2):在AudioSet-Small数据集上,使用oracle机制对比不同PEFT方法。
- 所有PEFT方法(DoRA, LoRA, Conv-Adapter, ReConv-Adapter)均能显著提升AudioSep的性能。
- 参数量与性能呈正相关:DoRA/LoRA(~0.26M) < Conv-Adapter(5.0M) < ReConv-Adapter(19.0M)。
- ReConv-Adapter在所有测试集上均取得最优分离结果,验证了其有效性。
- 领域划分分析(图3):使用t-SNE可视化CLAP嵌入的聚类结果。图中显示,大部分相同颜色的点(同一子域)形成清晰的簇,不同簇之间有明确边界,直观验证了基于CLAP嵌入进行K-Means聚类的有效性。同时观察到声学特征相似的类别(如各类人声)倾向于聚在一起,与语义分类不完全一致。
⚖️ 评分理由
- 学术质量(5.5/7):论文工作扎实,技术路线完整且有实验验证。创新性在于将LLM训练范式迁移到音频分离领域,并针对卷积网络设计了ReConv-Adapter。但创新更多是框架层面的组合,核心模块ReConv-Adapter的原创性有限。实验设计合理,对比了多种方法和策略,结果可信。
- 选题价值(1.5/2):LASS是当前音频AI的热点和难点,具有明确的应用场景和学术价值。论文针对该任务的核心挑战(特征分布差异)提出方案,有较强的实际意义和影响力。
- 开源与复现加成(0.5/1):论文提供了GitHub代码仓库链接,极大方便了复现。文中给出了详细的训练超参数、数据构建和硬件信息,复现基础好。���未明确提及是否开源预训练模型权重(尤其是微调后的PEFT模块),这可能增加复现完整性能的难度。