📄 Domain-Aware Scheduling for ASR Fine-Tuning
#语音识别 #领域适应 #低资源 #数据选择
✅ 6.5/10 | 前50% | #语音识别 | #领域适应 | #低资源 #数据选择
学术质量 6.2/7 | 选题价值 1.8/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Nikolaos Lagos(Naver Labs Europe, France)
- 通讯作者:未说明
- 作者列表:Nikolaos Lagos(Naver Labs Europe, France), Ioan Calapodescu(Naver Labs Europe, France)
💡 毒舌点评
该论文提出了一个在低资源场景下微调ASR系统的实用策略(按域相似度排序数据并分阶段训练),实验结果一致且增益明确,对实际部署者有吸引力。但其核心贡献是对现有数据选择方法(Lagos et al., 2024)的一个后处理步骤,而非根本性架构或算法创新,且方法效果高度依赖于数据选择步骤的质量。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文中未提及公开的微调后模型权重。
- 数据集:使用了公开的ESB基准数据集,并说明了如何从验证集中抽取种子。数据选择过程依赖于FAISS库进行索引。
- Demo:未提供在线演示。
- 复现材料:论文提供了详细的训练超参数(表3)、数据选择参数(KNN搜索,4分组)、评估协议和模型架构描述,复现信息较为充分。
- 论文中引用的开源项目:Wav2vec 2.0 [1]、Sentence-BERT [10]、FAISS [11]、SpeechBrain [13]。
📌 核心摘要
- 要解决的问题:在真实场景中,用于微调ASR系统的目标域数据往往稀缺。常用的解决方案是从大型开源数据集中选择与目标域相似的域外数据。传统方法在使用这些选中的数据时采用随机顺序,导致训练效果不佳。
- 方法核心:提出“域感知调度”(DAS)。该方法首先利用一个仅1分钟的目标域种子数据,通过KNN搜索对选定的域外数据按与目标域的距离进行排序(从最远到最近)。然后,将训练过程分为多个阶段,按顺序使用距离递增的数据组进行训练,每个阶段都从上一阶段的最优检查点继续。
- 与已有方法相比新在哪里:与传统课程学习按“难度”排序不同,DAS按“域距离”排序。与之前直接使用排序数据的“仅选择”基线相比,DAS引入了基于距离的顺序调度机制。论文声称这是首个在ASR微调中明确利用域相似度进行调度的方法。
- 主要实验结果:在ESB基准的7个英语数据集上,使用100小时训练预算,DAS方法相对于随机选择和“仅选择”基线,平均WER分别降低了4.14个点(17.29%相对降低)和2.52个点(11.32%相对降低)。在不同训练预算(10/50/100小时)下,DAS均表现出稳定改进。具体结果见下表。
| 数据集 | Random WER(↓) | SO WER(↓) | DAS WER(↓) | DAS vs SO WERR(%) (↑) | DAS vs Random WERR(%) (↑) |
|---|---|---|---|---|---|
| LibriSpeech-clean | 6.75±0.35 | 6.59±0.45 | 4.63±0.10 | 29.71 | 31.44 |
| LibriSpeech-other | 14.44±0.58 | 14.31±0.41 | 10.74±0.05 | 24.92 | 25.62 |
| CommonVoice | 37.31±0.43 | 35.55±1.47 | 32.77±0.44 | 7.81 | 12.17 |
| Tedlium | 14.49±2.07 | 11.74±0.62 | 9.34±0.9 | 20.44 | 35.53 |
| Voxpopuli | 19.32±0.23 | 17.37±0.86 | 15.62±0.24 | 10.08 | 19.18 |
| AMI | 39.33±0.96 | 34.60±1.73 | 32.14±0.6 | 7.1 | 18.28 |
| Earnings22 | 38.84±0.72 | 36.76±1.91 | 32.65±1.3 | 11.2 | 15.95 |
| Gigaspeech | 21.13±0.22 | 21.81±0.67 | 20.59±0.74 | 5.58 | 2.82 |
| 平均值 | 23.95±0.77 | 22.34±1.10 | 19.81±0.55 | 11.32 | 17.29 |
- 实际意义:该方法为无法依赖大量领域内数据的从业者(如低资源或隐私受限场景)提供了一种提升ASR微调性能的实用方案,可以作为现有数据选择技术的补充。
- 主要局限性:方法的有效性高度依赖于数据选择步骤(KNN搜索)的质量,这在Gigaspeech数据集上表现明显(该数据集本身多样性高)。论文未探索其他调度顺序(如从近到远)或组内多样性的控制,属于初步研究。
🏗️ 模型架构
论文中并未提出一个全新的端到端神经网络模型,而是提出了一种 “训练调度”(Scheduling)策略,应用于现有ASR模型的微调过程中。其核心流程是一个两阶段框架:
数据选择与排序阶段:
- 输入:一个大型域外(OOD)数据池,以及一个仅1分钟的目标域种子数据。
- 流程: a. 特征提取:使用预训练的自监督模型(wav2vec 2.0 Base 提取音频嵌入,Sentence-BERT 提取文本嵌入),并进行拼接。 b. 域校准:使用一个MLP对拼接后的嵌入进行多任务训练,使其能预测数据的来源ID、风格、类型等高级域标签。训练后的MLP的最后一层隐藏层输出被视为“域校准嵌入”。 c. 距离计算:使用FAISS库,以种子数据的“域校准嵌入”为查询,在OOD数据池的“域校准嵌入”索引中进行KNN搜索(欧氏距离),得到每个OOD样本与种子数据的距离。 d. 去重与排序:计算每个OOD样本与所有种子样本距离的平均值,作为最终排序分数。根据此分数将OOD数据从最远到最近排序。
- 输出:一个按与目标域距离排序的OOD训练数据集。
域感知调度训练阶段:
- 输入:排序后的OOD数据集,预训练的ASR模型(如wav2vec 2.0 large)。
- 流程:
a. 分组:将排序后的数据均匀划分为
m个组(论文中m=4)。组1数据最远,组m数据最近。 b. 分阶段训练:训练过程分为m个连续阶段。阶段i使用组i的数据进行训练。 c. 检查点继承:每个阶段(i > 1)都从前一阶段(i-1)的最优模型检查点开始训练。阶段1从预训练模型开始。 d. 组内随机:每个阶段内部的数据使用标准的随机打乱和mini-batch处理。 - 输出:微调后的ASR模型。
关键设计选择:
- 从远到近排序:动机是让模型先学习更通用、更偏离目标域的知识,然后逐渐聚焦到更相似的数据上,以实现稳定适应。
- 基于平均距离排序:为了处理一个OOD样本可能与多个种子样本匹配的情况,采用平均距离可以获得更稳定的相似度评分。
- 等预算分阶段:确保每个阶段计算量相当,便于与基线方法公平比较。
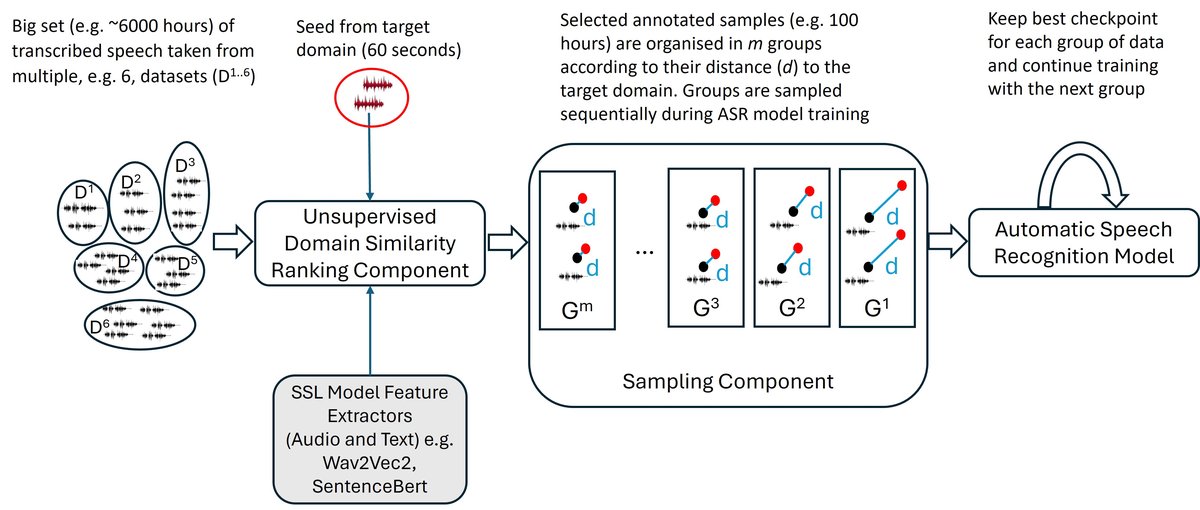 图1 展示了DAS的整体流程:从种子和OOD池开始,经过特征提取、域校准、KNN距离计算和排序,得到排序后的数据;然后按阶段使用这些数据从远到近微调模型。
图1 展示了DAS的整体流程:从种子和OOD池开始,经过特征提取、域校准、KNN距离计算和排序,得到排序后的数据;然后按阶段使用这些数据从远到近微调模型。
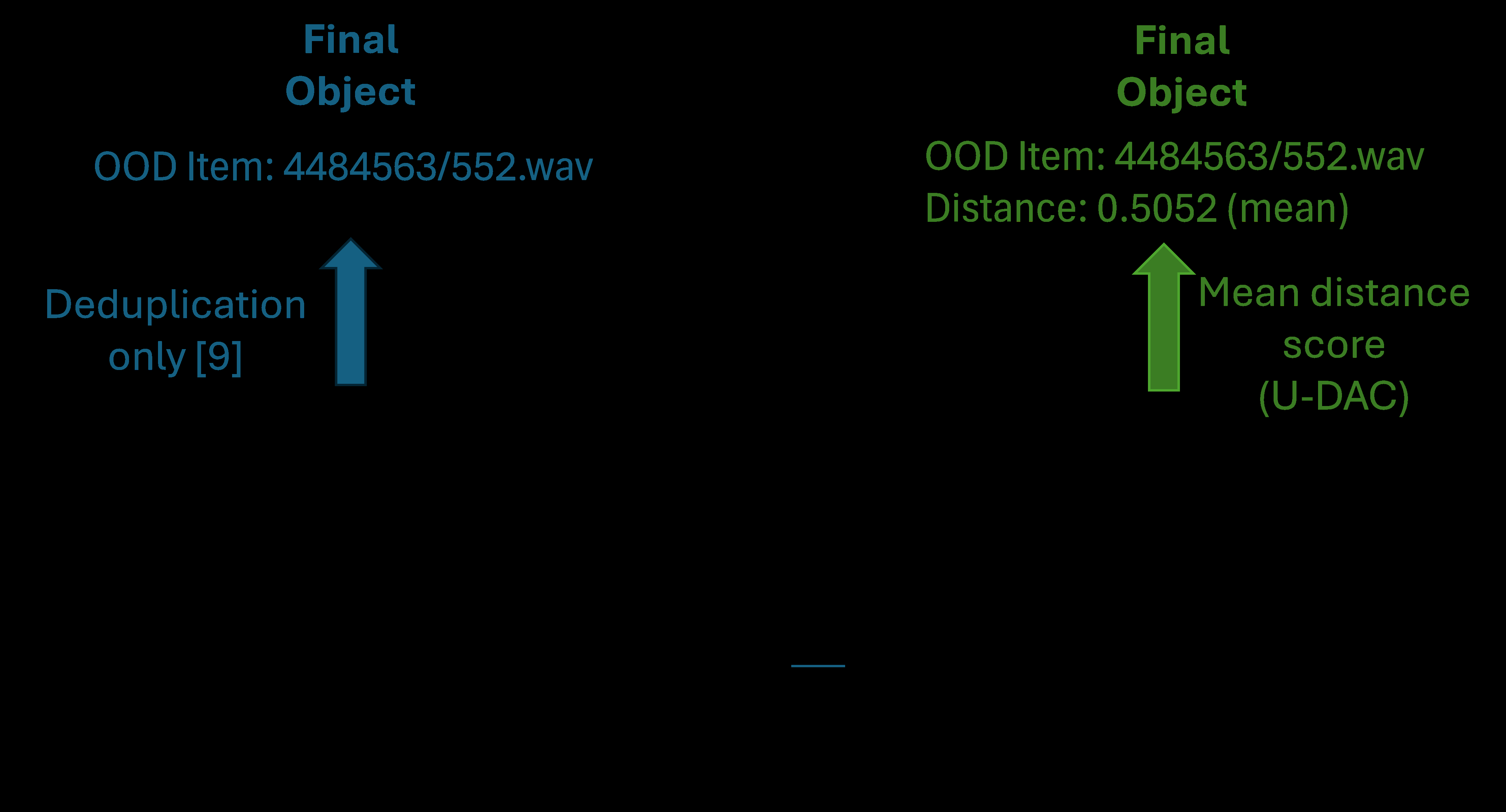 图2 对比了“仅选择”方法(只保留样本ID)和DAS方法(创建包含样本ID和平均距离的复合对象)在数据结构上的区别,后者是实现基于距离排序的关键。
图2 对比了“仅选择”方法(只保留样本ID)和DAS方法(创建包含样本ID和平均距离的复合对象)在数据结构上的区别,后者是实现基于距离排序的关键。
💡 核心创新点
- 基于域距离的训练调度(核心创新):提出了“Domain-Aware Scheduling”(DAS),将课程学习的思想从传统的“按难度排序”转变为“按与目标域的距离排序”,并应用于ASR微调。这是一种简单但有效的训练策略,无需修改模型架构。
- 极低资源的目标域适应:该方法仅需约1分钟的目标域种子数据即可工作,避免了依赖大量目标域数据进行预训练或复杂适应,极大降低了实际应用门槛。
- 与现有数据选择方法的协同:DAS并非取代而是补充了现有的数据选择技术(如Lagos et al., 2024)。它证明了在选择好数据后,仅仅改变训练呈现的顺序(调度),就能带来显著的性能提升。
🔬 细节详述
- 训练数据:
- 数据池:使用ESB基准中的7个英语数据集(LibriSpeech, CommonVoice, TED-LIUM, VoxPopuli, AMI, Earnings-22, GigaSpeech),涵盖有声书、维基百科、TED演讲、议会辩论、会议等多种场景和说话风格(叙事、演讲、自发)。
- 种子数据:从每个数据集的验证集中随机抽取3个1分钟片段作为种子。
- 数据预算:实验设置了10小时、50小时、100小时三种训练预算。主要结果基于100小时。
- 预处理:音频嵌入来自wav2vec 2.0 Base的第9层输出,并进行语句级平均池化。文本嵌入来自Sentence-BERT(all-MiniLM-L6-v2)。数据索引和KNN搜索使用FAISS库。
- 损失函数:ASR模型微调使用CTC(Connectionist Temporal Classification)损失。未使用语言模型。
- 训练策略:
- 模型:在wav2vec 2.0 large (LS960h)模型之上添加一个3层的MLP(每层1024个单元,LeakyReLU激活)。微调时解冻wav2vec 2.0的CNN特征提取器。
- 优化器:wav2vec 2.0部分使用Adam优化器,MLP部分使用Adadelta(学习率0.9,衰减率0.95,epsilon 1.e-8)。
- 学习率调度:使用“new-bob”技术进行学习率退火,参数:改进阈值0.0025,退火因子0.8,耐心0。
- DAS调度:对于100小时预算,数据被分为4个组,每个组约25小时。训练分为4个阶段,每个阶段使用16k次迭代(根据数据集不同,批次大小不同)。总迭代预算与基线相同。
- 批次大小:根据数据集不同在24到36之间(详见表3)。
- 关键超参数:DAS的分组数
m=4。KNN搜索的距离度量为平方欧氏距离。 - 训练硬件:论文中未说明。
- 推理细节:论文未提及特殊的解码策略,推测为标准CTC解码。
- 正则化/稳定训练技巧:论文未提及除上述训练策略外的额外技巧。
📊 实验结果
主要实验在ESB基准的7个数据集上进行,采用“Leave-one-out”评估策略:对于每个目标域数据集,将其从OOD池中移除,使用其验证集的种子来选择OOD数据并训练模型,最后在目标域测试集上评估。对比了三种训练策略:随机选择(Random)、仅选择(SO, 基线[4])和DAS。
主要结果(100小时预算,WER↓):详见上方“核心摘要”中的表格。DAS在所有数据集(除Gigaspeech的一个种子外)上均优于SO和Random基线。平均而言,DAS相比SO将WER降低了2.52个点(11.32%相对减少),相比Random降低了4.14个点(17.29%相对减少)。标准差较小,表明改进稳定。
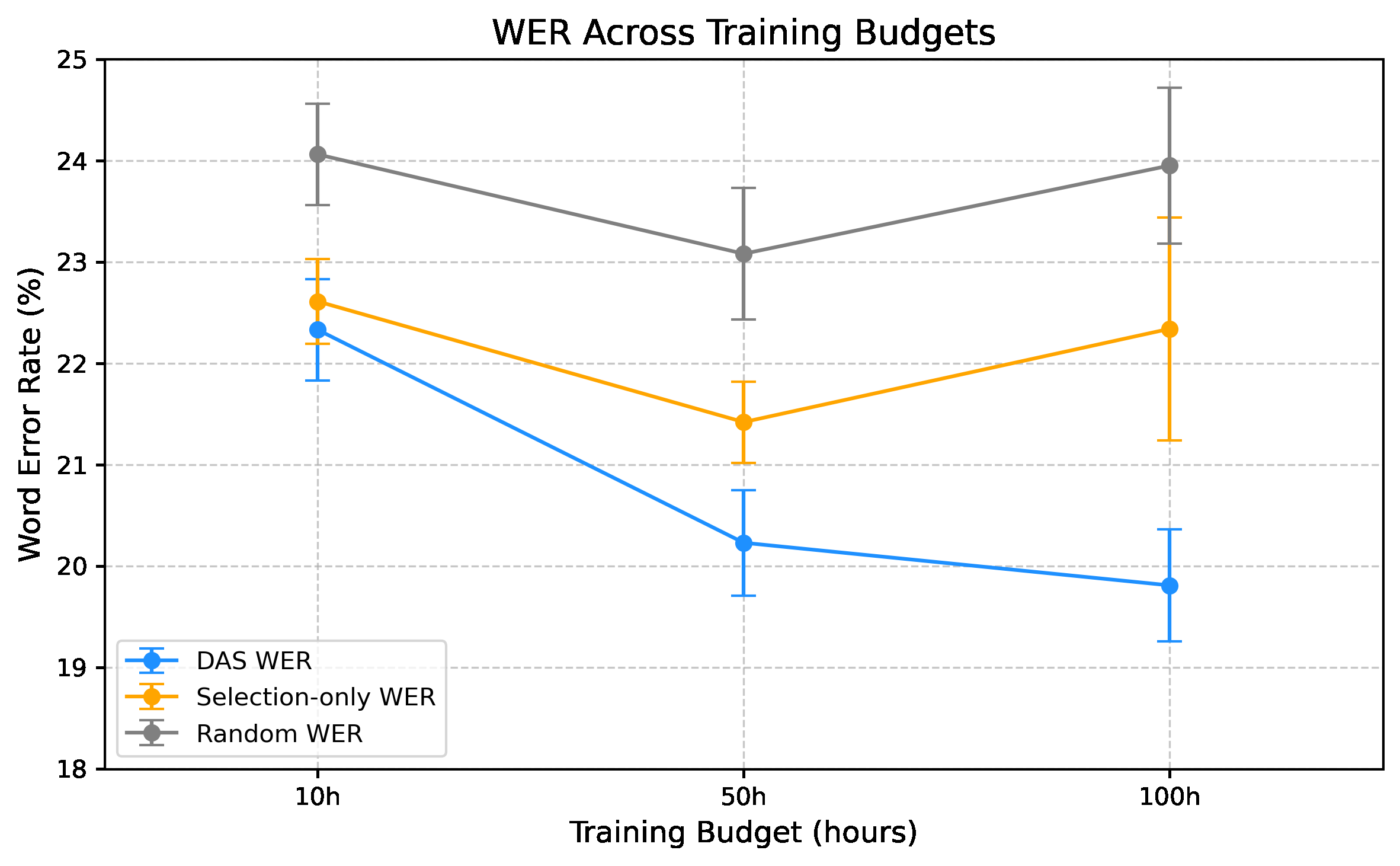 图3 展示了在10小时、50小时、100小时三种预算下,Random、SO和DAS三种方法的WER。关键结论:DAS的性能随着数据预算的增加而稳定提升,并且在所有预算下都优于两个基线,显示出对噪声域外数据的鲁棒性。
图3 展示了在10小时、50小时、100小时三种预算下,Random、SO和DAS三种方法的WER。关键结论:DAS的性能随着数据预算的增加而稳定提升,并且在所有预算下都优于两个基线,显示出对噪声域外数据的鲁棒性。
消融/分析实验:
- 种子鲁棒性:表4的“Improved seeds”列显示,对于绝大多数数据集和种子组合,DAS都优于SO。
- 训练预算影响:图3表明,DAS的性能随着数据增加而稳定提升,而基线方法的性能则有波动。
- 数据选择重复率:表2揭示了数据选择过程中存在的重复匹配问题(平均重复率17.58%),这解释了为何需要计算“平均距离”来获得稳定排序。
⚖️ 评分理由
- 学术质量:6.2/7:论文提出了一个清晰、实用且经过充分验证的方法(DAS)。技术路线正确,实验设计严谨(使用标准基准、多数据集、多随机种子、多预算评估),结果具有统计意义。创新性属于渐进式改进(对已有调度思想的针对性应用),而非范式突破。
- 选题价值:1.8/2:选题针对语音识别中一个普遍存在的实际痛点(低资源微调),提出的方法门槛低(1分钟数据)、效果好、易于实施,对相关领域的研究者和工程师都有较高的实用价值和参考意义。
- 开源与复现加成:0.5/1:论文提供了非常详细的实验设置(数据集、模型配置、超参数、评估协议),使得复现成为可能。但论文中未提及任何代码、模型权重或训练脚本的公开链接,这在一定程度上限制了其可复现性和影响力。加0.5分。