📄 DOMA: Leveraging Diffusion Language Models with Adaptive Prior for Intent Classification and Slot Filling
#语音对话系统 #意图识别 #槽填充 #扩散模型 #鲁棒性
🔥 8.5/10 | 前25% | #语音对话系统 | #扩散模型 | #意图识别 #槽填充
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Siqi Yang(电子科技大学)
- 通讯作者:Fan Zhou(电子科技大学;智能数字媒体技术四川省重点实验室;喀什电子与信息产业研究院)
- 作者列表:Siqi Yang(电子科技大学),Yue Lei(电子科技大学),Wenxin Tai(电子科技大学),Jin Wu(电子科技大学),Jia Chen(电子科技大学),Ting Zhong(电子科技大学),Fan Zhou*(电子科技大学;智能数字媒体技术四川省重点实验室;喀什电子与信息产业研究院)
💡 毒舌点评
这篇论文巧妙地将扩散语言模型(DLM)的并行生成能力用于纠正ASR转录错误,并通过一个轻量级的自适应先验模块来解决DLM可能“改对为错”的痛点,想法很实用。不过,整个框架的性能瓶颈和复杂度高度依赖于所使用的DLM(如LLaDA),自适应先验模块本身也可能引入新的错误(例如错误地掩码了本应保留的token),论文对此的边界讨论不足。
🔗 开源详情
- 代码:论文提供了代码仓库链接:https://github.com/ICDM-UESTC/DOMA。
- 模型权重:论文未提及DOMA中的自适应先验(AP)模块权重是否开源。所使用的DLM(LLaDA-8B-Instruct)为第三方开源模型。
- 数据集:论文使用的是公开的基准数据集(SLURP, ATIS, SNIPS),未提及对数据集的修改或私有部分。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了关键的超参数设置(假设数N=5, 门控阈值p=0.5, 生成长度64, 扩散步数32)、优化器学习率(1e-5)、训练轮数(10 epochs)以及骨干模型(RoBERTa-base),但未提供更详细的训练配置(如batch size)、检查点、完整训练日志或附录中的额外设置。
- 论文中引用的开源项目:论文明确提到使用了开源的LLaDA模型([14] Nie et al., ICLR 2025 Workshop),以及作为下游骨干的RoBERTa [20]。ASR使用了Whisper Large-v3。
📌 核心摘要
本文针对自动语音识别(ASR)错误会传播并损害下游口语理解(SLU)任务(如意图分类和槽填充)性能的问题,提出了一个模型无关的框架DOMA。DOMA的核心是使用扩散语言模型(DLM)对ASR转录文本进行细化,并引入了一个自适应先验(AP)机制来引导DLM的生成过程。具体来说,DOMA首先使用DLM生成多个候选细化假设,然后利用一个轻量级的、可训练的AP模块(包含自注意力和门控机制)来识别并保留原始ASR转录中可能正确的token,从而构建一个部分掩码的初始序列,而非从完全掩码开始生成。这有助于减少DLM的过度纠正,同时减少所需的扩散步数,提升推理效率。在SLURP、ATIS和SNIPS三个基准数据集上的实验表明,DOMA在多种基线模型(如RoBERTa, SpokenCSE)上一致提升了ICSF性能,相对提升最高达3.2%(例如,DOMA+SpokenCSE在SLURP上的IC准确率从85.51%提升至88.26%)。同时,与自回归LLM细化方法相比,DOMA将推理延迟降低了34.8%(RTF从0.66降至0.43)。该框架的意义在于为提升SLU系统对ASR错误的鲁棒性提供了一种高效、通用的后处理方案。主要局限性在于其效果依赖于强大的预训练DLM(如LLaDA-8B),且AP模块的训练需要额外数据和计算资源。
关键实验结果表:
| 模型 | 训练集 | 数据集 | SLURP (WER=17.12%) | ATIS (WER=10.31%) | SNIPS (WER=7.69%) |
|---|---|---|---|---|---|
| Accuracy (↑) / SLU-F1 (↑) | Accuracy (↑) / SLU-F1 (↑) | Accuracy (↑) / SLU-F1 (↑) | |||
| RoBERTa [20] | Oracle | 82.78 / 72.19 | 95.87 / 87.18 | 96.99 / 95.31 | |
| DOMA+RoBERTa [20] | Oracle | 84.77 / 74.23 | 97.40 / 88.56 | 97.72 / 97.19 | |
| SpokenCSE [6] | Oracle+ASR | 85.51 / 74.39 | 97.58 / 90.02 | 98.17 / 97.80 | |
| DOMA+SpokenCSE [6] | Oracle+ASR | 88.26 / 76.82 | 98.15 / 90.65 | 98.61 / 98.11 |
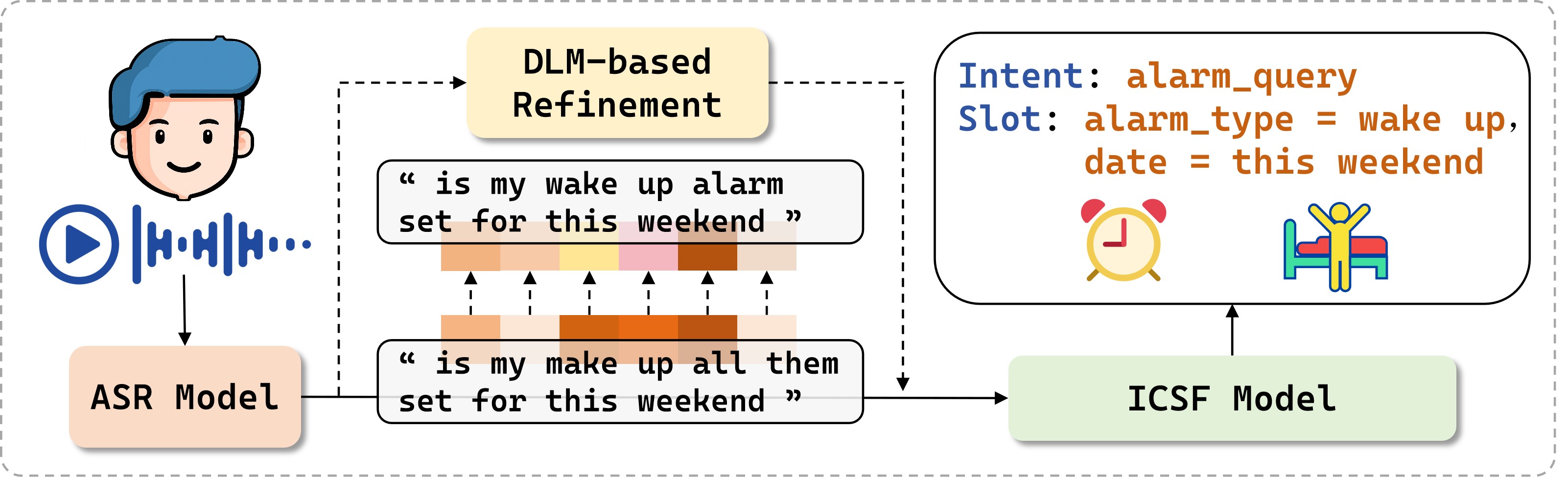 图1展示了DOMA嵌入整个ICSF工作流的示意图。DOMA位于ASR输出和ICSF模型之间,负责文本精细化。
图1展示了DOMA嵌入整个ICSF工作流的示意图。DOMA位于ASR输出和ICSF模型之间,负责文本精细化。
🏗️ 模型架构
DOMA的完整架构和工作流程如图2所示,可分为两个主要部分:ASR精细化(Refinement)模块和下游ICSF模型。
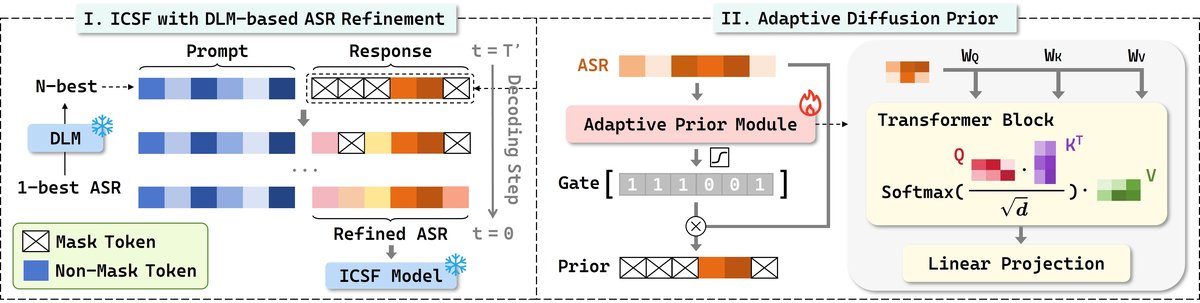 整体流程:
整体流程:
- 输入:接收来自ASR系统的1-best转录文本
z。 - N-best假设生成(第一阶段):将
z和特定提示y1输入DLM(LLaDA),生成N个候选假设[zj]_{j=0}^{N}。 - ASR精细化(第二阶段):将第一阶段生成的假设列表和原始转录
z整合进提示y2。此时,DLM的自适应先验(AP)模块介入。- AP模块:接收ASR转录
z的嵌入E,通过一个Transformer块进行上下文建模,然后通过一个带sigmoid激活的线性层生成门控向量g。g中的每个元素是一个二值指示符,决定对应位置的token是否被保留(g=1)或被掩码(g=0)。初始序列x(T')由掩码位置(g=0)填充[M],保留位置(g=1)填充原始ASR tokenz构成。 - DLM反向过程:DLM从
x(T')开始进行迭代去噪。在每个步骤t,模型预测所有位置的token,高置信度的预测结果被固定(unmasked),低置信度的保持掩码或重新掩码,直至所有位置确定,得到精细化的文本x(0)。
- AP模块:接收ASR转录
- ICSF推理:将精细化的文本
x(0)输入到预训练的ICSF模型(如RoBERTa+分类头)中,得到意图分类和槽填充的预测结果。
关键组件与设计动机:
- DLM(LLaDA):作为核心精细化���擎。相比自回归模型,其并行解码特性可显著提升推理速度。两阶段精细化(先生成N-best,再融合精细化)旨在模拟多步推理,利用多个候选信息提升修正质量。
- 自适应先验(AP)模块:这是一个轻量级的、可学习的门控网络。其动机是解决标准DLM从全掩码序列开始生成时容易产生的过度纠正问题(如图3所示)。AP通过学习“哪些token可能是正确的”,在生成初期就提供一个高质量的起点,引导DLM仅修正错误部分,从而提升修正的保真度并减少所需扩散步数。
💡 核心创新点
- 模型无关的ICSF鲁棒性增强框架(DOMA):将ASR精细化作为一个独立的、可插拔的预处理模块,使下游ICSF模型无需针对特定ASR系统或错误模式进行训练,提升了框架的通用性和可扩展性。
- 采用扩散语言模型(DLM)进行ASR精细化:首次将DLM(如LLaDA)引入ICSF的ASR后处理任务。利用其非自回归、并行生成的特性,克服了自回归LLM细化速度慢的瓶颈,在保证修正效果的同时大幅降低推理延迟。
- 自适应先验(AP)机制:提出了一个新颖的AP模块,通过一个可学习的门控向量动态选择并保留ASR转录中可能正确的token,为DLM的反向过程提供一个部分掩码的、信息丰富的初始序列。该机制缓解了DLM和LLM常见的过度纠正问题,并通过减少需要生成的token数量进一步加速了推理。
🔬 细节详述
- 训练数据:
- 下游ICSF模型:在SLURP, ATIS, SNIPS数据集的oracle(干净文本)和/或ASR转录文本上训练。
- 自适应先验(AP)模块:在开发集上训练,优化目标是使精细化后的ASR输出与oracle文本对齐。使用负对数似然损失。
- 损失函数:AP模块使用负对数似然损失。论文未说明具体公式。
- 训练策略:
- ICSF模型:论文未说明其训练策略(如学习率、轮数),仅说明使用RoBERTa-base作为骨干。
- AP模块:训练最多10个epoch,在开发集上通过网格搜索选择超参数。学习率为1e-5。使用NVIDIA RTX 4090 GPU。
- 关键超参数:
- DLM:使用LLaDA-8B-Instruct,无进一步训练。
- 生成长度:64。
- 扩散步数(T):32。
- N-best假设数量(N):5。
- AP模块门控阈值(p):0.5。
- 训练硬件:论文明确提及所有实验在NVIDIA RTX 4090 GPU上进行,但未说明训练AP模块的具体时长。
- 推理细节:
- 解码策略:DLM采用其标准的迭代去噪解码过程。两阶段精细化,第一阶段生成5个假设,第二阶段生成精细化文本。
- 效率指标:使用实时因子(RTF) 衡量,定义为ASR精细化运行时间与音频时长之比。
- 正则化/稳定训练技巧:AP模块使用了残差连接和sigmoid激活生成二值门控向量。
📊 实验结果
主要Benchmark结果: 论文在三个标准SLU数据集上进行了评估,结果见下方表格。DOMA在所有基线模型和数据集上都带来了性能提升。
| 模型 | 训练集 | SLURP (WER=17.12%) | ATIS (WER=10.31%) | SNIPS (WER=7.69%) |
|---|---|---|---|---|
| Accuracy / SLU-F1 | Accuracy / SLU-F1 | Accuracy / SLU-F1 | ||
| RoBERTa [20] | Oracle | 82.78 / 72.19 | 95.87 / 87.18 | 96.99 / 95.31 |
| DOMA+RoBERTa [20] | Oracle | 84.77 (+1.99) / 74.23 (+2.04) | 97.40 (+1.53) / 88.56 (+1.38) | 97.72 (+0.73) / 97.19 (+1.88) |
| RoBERTa [20] | ASR | 84.08 / 73.91 | 97.12 / 88.30 | 97.59 / 97.18 |
| DOMA+RoBERTa [20] | ASR | 86.65 (+2.57) / 76.46 (+2.55) | 97.60 (+0.48) / 88.80 (+0.50) | 98.15 (+0.56) / 97.77 (+0.59) |
| SpokenCSE [6] | Oracle+ASR | 85.51 / 74.39 | 97.58 / 90.02 | 98.17 / 97.80 |
| DOMA+SpokenCSE [6] | Oracle+ASR | 88.26 (+2.75) / 76.82 (+2.43) | 98.15 (+0.57) / 90.65 (+0.63) | 98.61 (+0.44) / 98.11 (+0.31) |
 图3的案例研究显示,无AP的精细化会将“meeting”误改为“team”,导致ICSF预测出错误的槽值“event name = canada team”。而DOMA利用AP保留了“meeting”,实现了更准确的修正和ICSF预测。
图3的案例研究显示,无AP的精细化会将“meeting”误改为“team”,导致ICSF预测出错误的槽值“event name = canada team”。而DOMA利用AP保留了“meeting”,实现了更准确的修正和ICSF预测。
消融实验(Ablation Study): 如下表所示,在RoBERTa骨干上验证了ASR精细化和AP模块的有效性。AP模块的加入显著降低了WER并提升了SLU-F1。
| 设置 | SLURP (WER) | ATIS (WER) | SNIPS (WER) |
|---|---|---|---|
| raw | 72.19 (17.12%) | 87.18 (10.31%) | 95.31 (7.69%) |
| Refinement w/o AP | 72.57 (16.97%) | 88.17 (9.86%) | 96.74 (6.97%) |
| Refinement w/ AP | 74.23 (15.84%) | 88.56 (9.18%) | 97.19 (6.59%) |
与LLM细化方法的对比: 论文对比了标准DLM (LLaDA) 和两种自回归LLM (Qwen2.5, LLaMA3.1)。结果(表3)表明:
- LLaMA3.1因过度纠正导致WER上升(从17.12%到17.42%)和性能下降。
- DOMA不仅性能最佳(SLU-F1 74.23%),而且推理速度(RTF 0.43)远快于所有AR模型(RTF > 1.0)和标准LLaDA(RTF 0.66)。
| 设置 | RTF ↓ | WER ↓ | Accuracy ↑ | SLU-F1 ↑ |
|---|---|---|---|---|
| raw | - | 17.12 | 82.78 | 72.19 |
| Qwen2.5 [26] | 1.02 | 16.82 | 83.54 | 72.95 |
| LLaMA3.1 [27] | 1.15 | 17.42 | 82.55 | 71.62 |
| LLaDA [14] | 0.66 | 16.97 | 83.05 | 72.57 |
| DOMA | 0.43 | 15.84 | 84.77 | 74.23 |
跨ASR系统泛化性: 如图4所示,在未见过的ASR系统(WSL, Con-FS, Con-SSL+FT)生成的转录上评估,DOMA能有效提升ICSF性能,证明了其泛化能力。
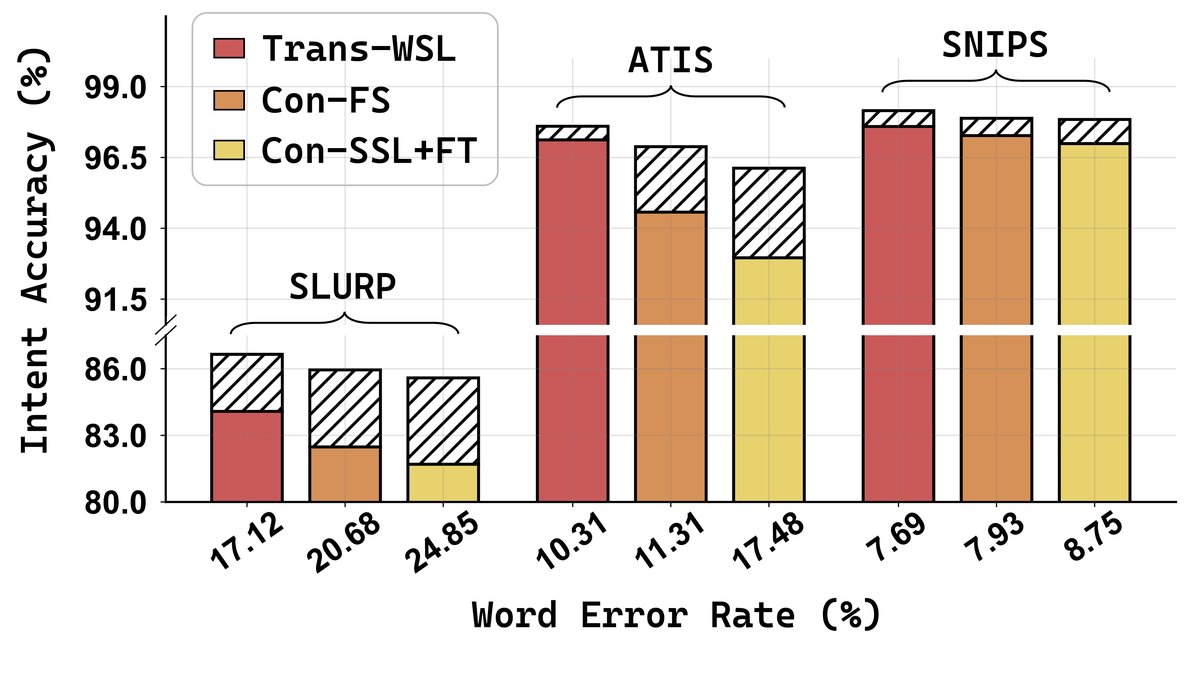 图4显示,在不同WER(从低到高)的ASR系统输出上,应用DOMA后(蓝线)的ICSF性能(SLU-F1)均显著高于使用原始转录(红线)。
图4显示,在不同WER(从低到高)的ASR系统输出上,应用DOMA后(蓝线)的ICSF性能(SLU-F1)均显著高于使用原始转录(红线)。
⚖️ 评分理由
- 学术质量:6.5/7:论文提出了一个完整且有逻辑的解决方案,将前沿的DLM应用于经典SLU鲁棒性问题,并通过AP机制解决了DLM应用中的关键痛点(过度纠正)。实验设计全面,包括主实验、消融实验、不同模型对比、跨系统泛化验证,数据详实,结论可靠。主要扣分点在于核心生成模型DLM并非本工作原创,且对AP模块的失败案例分析不足。
- 选题价值:1.5/2:解决ASR错误传播对SLU的影响是语音交互系统实用化中一个持续且重要的挑战。该工作提出了一种新的、高效的解决范式,对提升智能助手等应用的可靠性有直接价值,与语音研究者和工程师高度相关。
- 开源与复现加成:0.5/1:论文明确提供了代码仓库链接(https://github.com/ICDM-UESTC/DOMA),并详述了关键的超参数(N, p, T)和模型选择(LLaDA-8B-Instruct),这为复现提供了核心信息。减分项在于未提及AP模块的权重文件是否开源,也未提供更详细的训练日志或硬件消耗(如训练时长),使得完全复现仍需额外工作。