📄 Does the Pre-Training of an Embedding Influence its Encoding of Age?
#语音生物标志物 #说话人识别 #预训练 #模型比较
✅ 7.0/10 | 前50% | #语音生物标志物 | #预训练 | #说话人识别 #模型比较
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Carole Millot(Inria Paris)
- 通讯作者:未说明
- 作者列表:Carole Millot(Inria Paris)、Clara Ponchard(Inria Paris)、Jean-François Bonastre(AMIAD, 邮箱域名(polytechnique.edu)提示可能与巴黎综合理工学院相关,但论文中机构仅写为AMIAD)、Cédric Gendrot(LPP, Sorbonne Nouvelle, CNRS)
💡 毒舌点评
亮点在于将心理物理学中的感知实验范式引入语音年龄检测模型的评估,为人机对齐提供了新颖的视角。短板是下游年龄检测模型过于简单(一个三层MLP),且对不同嵌入的分析更多停留在性能比较层面,缺乏对其内部年龄信息编码机制的更深层探究。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及提供训练好的年龄检测模型或使用的嵌入提取器的特定权重。所使用的嵌入提取器(WeSpeaker, MMS LID, wavLM, BA-LR)本身是已发表的开源项目。
- 数据集:使用的是VoxCeleb2语料库,这是一个公开数据集。论文中提及了带有年龄标注的增强版本,但未说明如何获取该特定版本。
- Demo:未提及。
- 复现材料:论文给出了下游MLP的详细超参数(学习率、批大小、优化器)和训练流程,但未提供配置文件或检查点。
- 论文中引用的开源项目:WeSpeaker toolkit, PraatSauce, PsyToolKit, lmerTest package (R语言)。
📌 核心摘要
这篇论文研究了语音自监督学习(SSL)嵌入提取器的预训练策略如何影响其对说话人年龄信息的编码。为解决两个问题:1. 如何用人类感知验证自动年龄检测系统的性能;2. 不同预训练目标的嵌入是否在年龄检测上表现不同,作者进行了两项工作。首先,他们建立了一个基于WeSpeaker嵌入和简单MLP的年龄检测系统,并在VoxCeleb2-age数据集上实现了6.8年的平均绝对误差(MAE)。然后,他们设计了一个感知实验,让人类听者判断语音对中说话人的年龄差异。实验发现,人类准确度与系统MAE显著相关,即系统判断困难的语音对,人类也更难判断。其次,他们比较了四个不同嵌入提取器(WeSpeaker、MMS LID、wavLM base+、BA-LR)在相同年龄检测任务上的性能。结果显示,为说话人识别设计的WeSpeaker表现最佳(MAE 6.8),而为语言识别优化的MMS LID表现最差(MAE 9.1)。这支持了他们的假设:预训练目标(如追求说话人独立性的语言识别)会削弱嵌入中的年龄相关信息。主要局限性包括:仅在一个数据集和下游任务上验证,且未深入探究嵌入内部的年龄编码机制。
🏗️ 模型架构
本文的核心架构包含两部分:1. 用于生成语音嵌入的预训练SSL模型(提取器);2. 用于年龄预测的下游回归模型(检测系统)。
- 嵌入提取器:论文未提出新的提取器,而是使用四个现有的、预训练好的模型作为“黑盒”特征提取器。对于每个输入语音段,提取器输出一个固定维度的向量表示(嵌入)。
- 下游年龄检测系统:这是一个三层的多层感知机(MLP)。输入是上述嵌入向量,输出是预测的年龄(回归任务)。激活函数为ReLU,损失函数为均方误差(MSE),优化器为Adam。这是一个非常简单的、非端到端的系统,旨在隔离和评估嵌入本身的质量。
💡 核心创新点
- 感知验证范式:提出并实践了一种通过人类感知实验来评估自动语音年龄检测系统的方法。通过构建人类表现与系统误差(MAE)之间的统计学关联,为系统评估提供了人类视角的合理性验证,而不仅仅依赖于基准测试分数。
- 预训练目标影响的实证分析:系统性地比较了四种具有不同预训练目标(说话人识别、语言识别、通用语音处理、可解释说话人识别)的嵌入提取器在年龄检测任务上的表现。实验证据支持了“训练目标决定了嵌入中编码何种信息”的假设。
- 可解释嵌入的探索:将一种旨在提供可解释性的二进制说话人嵌入(BA-LR)引入年龄检测任务,考察在追求可解释性的同时是否会损失年龄等声学信息。
🔬 细节详述
- 训练数据:使用VoxCeleb2语料库,并采用其中的年龄标注版本。数据集被随机划分为训练集和测试集,确保说话人无重叠。训练集包含3316名说话人,测试集包含535名说话人。论文中特别说明,保留了同一说话人跨年的多条录音,以确保系统学习的是年龄变化而非说话人身份。
- 损失函数:下游年龄检测模型使用均方误差(Mean Squared Error) 作为损失函数,这是一个标准的回归损失。
- 训练策略:对于下游MLP,使用Adam优化器,学习率为1e-3,批大小为32。训练最多100个epoch,并根据验证集性能选择最优检查点。验证集占训练数据的10%。
- 关键超参数:下游模型为“三层MLP”。嵌入提取器的输出维度由其自身设计决定(例如,MMS LID使用48维,BA-LR使用约200位二进制),论文中未修改这些维度。
- 训练硬件:论文提到使用了来自GENCI-IDRIS的HPC资源(Grant 2025-AD011014982R1),但未具体说明GPU型号、数量或训练时长。
- 推理细节:未说明。下游模型直接输出回归的年龄值。
- 正则化或稳定训练技巧:未明确提及,仅提到MLP使用ReLU激活。
📊 实验结果
论文主要报告了两项实验的结果:参考系统性能和多嵌入比较。
- 参考年龄检测系统性能(基于WeSpeaker嵌入)
| 子集 | MAE.mean | MAE.std |
|---|---|---|
| 验证集 | 2.6 | 2.4 |
| 测试集 | 6.8 | 4.2 |
图表引用:
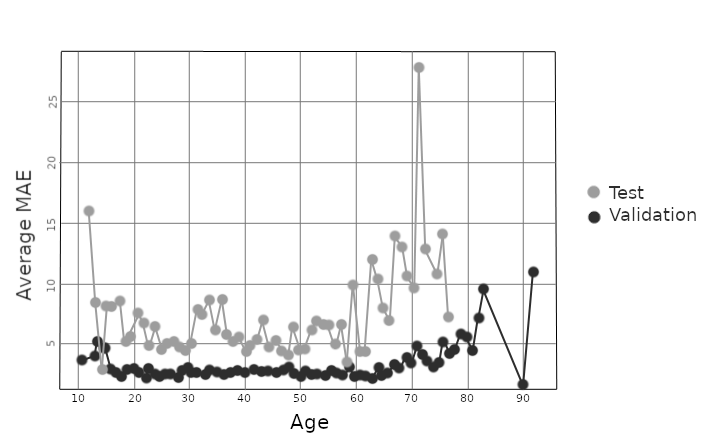 图1描述:展示了训练集和测试集中不同年龄的说话人语音条数分布。可见年轻(<20岁)和年老(>70岁)的说话人样本较少,这解释了系统在这些年龄段误差较大的原因。
图1描述:展示了训练集和测试集中不同年龄的说话人语音条数分布。可见年轻(<20岁)和年老(>70岁)的说话人样本较少,这解释了系统在这些年龄段误差较大的原因。
- 关键结论:测试集MAE为6.8年。误差分析显示,模型对年轻和年长说话人误差较大,与数据分布不均一致。对于同一说话人跨年录音,模型能做出区分(年龄变化与无变化的说话人MAE接近),表明系统确实在学习年龄特征而非仅记忆说话人身份。
- 不同嵌入提取器对年龄检测性能的影响
| 嵌入提取器 | 测试集MAE.mean | 测试集MAE.std |
|---|---|---|
| WeSpeaker (参考) | 6.8 | 4.2 |
| MMS LID | 9.1 | 5.4 |
| wavLM base+ | 7.3 | 5.3 |
| BA-LR | 8.7 | 6.1 |
- 关键结论:为说话人识别训练的WeSpeaker表现最好(MAE最低)。为语言识别优化的MMS LID表现最差,支持了其训练目标(说话人独立性)会压制年龄信息的假设。通用语音模型wavLM表现居中。追求可解释性的BA-LR表现不佳,表明其在设计上可能牺牲了部分声学判别力。
- 感知实验结果
- 关键结论(来自混合效应模型,见表3):参与者的判断准确率与三个固定效应显著相关:系统MAE(p < 0.001)、信噪比SNR(p < 0.05)和语音对的年龄差(p < 0.001)。系统MAE越高(模型判断越不准的语音对),人类准确率越低;SNR越低(噪音越大),人类准确率越低;年龄差越大(10岁间隔 vs. 3岁间隔),人类准确率越高。这验证了“人机表现一致性”的假设。
⚖️ 评分理由
- 学术质量:6.5/7:论文结构完整,假设清晰,实验设计巧妙(尤其是感知实验部分)且执行到位。统计分析严谨。主要扣分点在于核心模型过于简单,限制了结论的深度;对嵌入的比较是功能性的,缺乏对其内部表示的探查。
- 选题价值:2/0:选题切合语音处理中嵌入学习和可解释性的前沿方向,年龄检测本身具有应用价值。研究预训练目标对特定属性(年龄)编码的影响,对社区有明确启示。
- 开源与复现加成:0.5/1:论文提供了足够详细的实验设置(数据集划分、模型参数、评估指标),使他人能够基于公开的嵌入提取器和数据集复现核心结论。但未开源自身的代码或处理后的数据,增加了复现的初始门槛。