📄 Do Speech LLMs Learn Crossmodal Embedding Spaces?
#语音大模型 #模型评估 #跨模态 #音频检索
✅ 6.5/10 | 前50% | #音频检索 | #模型评估 | #语音大模型 #跨模态
学术质量 5.5/7 | 选题价值 0.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Carlos Escolano(TALP Research Center, Universitat Politècnica de Catalunya)
- 通讯作者:未说明
- 作者列表:Carlos Escolano(TALP Research Center, Universitat Politècnica de Catalunya)、Gerard Sant(University of Zurich)、José A.R. Fonollosa(TALP Research Center, Universitat Politècnica de Catalunya)
💡 毒舌点评
本文最大的亮点是提供了一个系统且可量化的框架来“解剖”语音大模型的黑箱内部,明确指出了当前主流架构在“让模型听懂语义”与“保留说话人特征”之间难以兼得的根本困境,为后续研究提供了清晰的“病历本”。短板在于,作为一篇诊断性工作,它揭示了问题却几乎没开药方,且仅对比了几个特定模型,结论的普适性有待更广泛模型的验证。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文评估了四个模型(SONAR, Spire, Qwen2-Audio, Phi4-Multimodal),但这些模型本身是已发表的工作,论文未提供其权重获取方式。
- 数据集:所使用的评估数据集(FLEURS, Spoken SQuAD, SD-QA)均为公开数据集,论文中提及。
- Demo:未提及。
- 复现材料:论文给出了模型的基本架构参数和评估指标的定义,但未提供完整的训练细节、配置文件或附录。复现需要依赖原模型论文中的信息。
- 论文中引用的开源项目:引用了HuBERT, Whisper, TOWER等模型,但未明确说明是否提供了本次评估使用的具体版本。
- 总体而言,论文中未提及针对本分析工作的开源计划。
📌 核心摘要
- 要解决的问题:语音大模型(Speech LLMs)需要将语音信号映射到LLM的文本嵌入空间,但这一映射过程的性质(是否形成良好的跨模态嵌入空间)和代价(是否会丢失副语言信息)尚未被系统研究。
- 方法核心:提出一套评估指标(各向同性分数IsoScore、Hubness的Robin Hood分数、关系相似性RS),并结合跨模态检索、性别分类、口音分类等探针任务,对不同架构的语音大模型(保留连续语音编码器表示 vs. 从头学习离散语音单元)进行系统分析。
- 与已有方法相比新在哪里:首次从嵌入空间几何属性(各向同性、Hubness、同构性)的角度,定量对比了纯编码器模型(SONAR)与多种解码器架构的语音大模型(Spire, Qwen2-Audio, Phi4-Multimodal)。明确揭示了现有语音大模型在跨模态对齐质量上仍逊于专门的多模态编码器,并发现了两种主流设计范式(连续表示 vs. 离散表示)在语义对齐和副语言信息保留方面存在的根本性权衡。
- 主要实验结果:
- 跨模态映射属性:在FLEURS数据集上,所有语音大模型的IsoScore均低于0.05,远低于SONAR的0.0425;RH分数(越低越好)均高于0.35,差于SONAR的0.25;RS分数(越高越好)均低于0.55,远低于SONAR的0.94。
- 检索性能:在FLEURS(精确句对)和Spoken SQuAD(主题匹配)数据集上,语音大模型的Top-1检索准确率(FLEURS @1)在16-18%之间,与SONAR(19.19%)接近,但Spire稍弱(11.54%)。
- 副语言信息保留与权衡:使用连续编码器的模型(Phi4, Qwen2)在浅层能很好地区分性别(准确率~85%)和口音,但随着层深增加,性能显著下降(见图1)。而使用离散单元的Spire则能稳定保留性别信息(全层>82%),但在SD-QA数据集的口音分类上,对某些口音(如IND-S, NGA)的准确率下降近20%,显示鲁棒性不足(见表2)。
- 关键数据表格:
模型 IsoScore ↑ RH ↓ RS ↑ FLEURS @1 ↑ Spoken SQUAD @1 ↑ SONAR 0.0425 0.25 0.94 54.25% 19.19% Phi4-Multimodal 0.0004 0.35 0.53 54.04% 16.37% Qwen2-Audio 0.0002 0.41 0.55 53.55% 18.35% Spire 0.0001 0.43 0.16 50.17% 11.54%
- 实际意义:为语音大模型的设计提供了重要启示:1)当前基于LLM的架构在跨模态嵌入空间质量上仍有很大提升空间,可能需要更复杂的非线性映射。2)模型设计者必须在“保持语义对齐强度”与“保留丰富的副语言信息/对多样口音的鲁棒性”之间做出明确权衡。
- 主要局限性:研究局限于对4个特定模型的分析,结论的普适性需要在更多模型上验证;所提出的评估框架本身可能需要更多验证;论文主要进行诊断分析,未提出具体的改进模型或算法来解决所发现的权衡问题。
🏗️ 模型架构
本文是一篇分析性论文,核心是评估而非提出新模型。因此,模型架构部分主要描述所评估的四个模型��
- SONAR:作为基线,是一个编码器-only模型,将文本和语音联合编码到共享向量空间。包含24个注意力层,隐藏维度1024,参数量约1B。
- Spire:改造自TOWER架构。语音经HuBERT处理成连续表示后,通过k-means聚类为5000个离散单元。这些单元作为新词元加入LLM词表,模型直接学习处理音频词元。包含32个注意力层,隐藏维度4092,参数量约7B。
- Qwen2-Audio:扩展自Qwen2 LLM。使用Whisper编码器提取语音连续表示,通过线性投影层映射到LLM嵌入空间。包含32个注意力层,隐藏维度4096,参数量约7B。
- Phi-4 Multimodal:架构类似Qwen2-Audio(音频编码器+线性投影),但使用LoRA适配器进行微调,而非全参数微调LLM。包含32个注意力层,隐藏维度3072,参数量约4.5B。
数据流对比:Spire是端到端地在LLM内部学习离散语音表示,属于“内部学习”范式。而Qwen2-Audio和Phi-4是先用一个预训练的连续编码器(Whisper/其他)提取特征,再通过投影层“输入”到LLM,属于“外部投影”范式。这种架构差异是本文分析的核心变量。
💡 核心创新点
- 系统性评估框架的提出:引入了基于嵌入空间几何属性(IsoScore, RH, RS)和多任务探针(检索、性别、口音)的完整评估体系。这超越了单纯比较下游任务性能,深入到了模型内部表示的特性分析,为评估语音-文本多模态模型提供了新的视角和工具。
- 揭示两种主流架构范式的根本性权衡:首次通过实验证据明确指出,采用连续语音编码器投影的模型(如Qwen2-Audio)在跨模态对齐度量上表现更好,但会随着层深增加而“遗忘”副语言信息;而从头学习离散语音单元的模型(如Spire)能稳定保留副语言信息,但跨模态对齐度弱且对罕见口音鲁棒性差。
- 量化当前语音大模型与专用多模态编码器的差距:用明确的数字(如IsoScore相差两个数量级)证明,尽管参数量巨大,当前解码器架构的语音大模型在形成结构良好(各向同性、低Hubness、同构)的跨模态嵌入空间方面,仍显著落后于专门设计的编码器模型(SONAR)。
🔬 细节详述
- 训练数据:论文未详细说明所评估模型(Spire, Qwen2-Audio, Phi4-Multimodal, SONAR)的训练数据,仅说明用于评估的数据集(FLEURS, Spoken SQuAD, SD-QA)的细节。
- 损失函数:未说明。论文聚焦于模型分析,而非训练过程。
- 训练策略:未说明。
- 关键超参数:论文提供了模型的层数和隐藏维度(见上文架构部分)。Spire的离散语音单元数(词表扩展大小)为5000。
- 训练硬件:未说明。
- 推理细节:论文未详细说明解码策略。评估跨模态检索和探针任务时,主要使用余弦相似度进行最近邻搜索。
- 评估方法:使用IsoScore(基于PCA和协方差矩阵)量化各向同性;使用Robin Hood分数量化Hubness;使用固定子集(n=100)的成对余弦距离的皮尔逊相关系数量化关系相似性(RS);使用k近邻检索准确率评估跨模态对齐;使用线性SVM分类器评估性别和口音信息的保留情况。
📊 实验结果
- 主要基准与结果:核心结果已在“核心摘要”的表格中完整列出。关键发现是所有语音大模型在嵌入空间质量指标上均劣于SONAR。
- 与最强基线/SOTA的差距:在嵌入空间质量指标上,所有语音大模型与SONAR存在巨大差距(如RS:0.16-0.55 vs. 0.94)。在检索准确率上,性能接近(FLEURS @1:50-54% vs. 54.25%),但这可能因为检索任务本身已接近天花板,而嵌入空间质量指标更能反映内部结构的缺陷。
- 关键消融实验:论文的“消融”体现在对不同模型架构(连续表示 vs. 离散表示)的对比分析上,这构成了全文的核心发现(见02节)。
- 不同条件下的细分结果:
- 口音鲁棒性:表2显示,使用连续表示的模型对各类口音的检索准确率均很高且稳定(>98%)。而Spire对某些口音(如IND-S: 83.2%, NGA: 82.6%)的准确率显著低于对其他口音(如USA: 99.2%),表明离散化表示对语音变体的鲁棒性较差。
- 层间变化:图1展示了模型各层在检索准确率、性别分类和口音分类上的变化。核心结论是:连续表示模型的副语言分类准确率随层深下降(对齐改善),而Spire则保持稳定(对齐较差)。
实验结果图表:
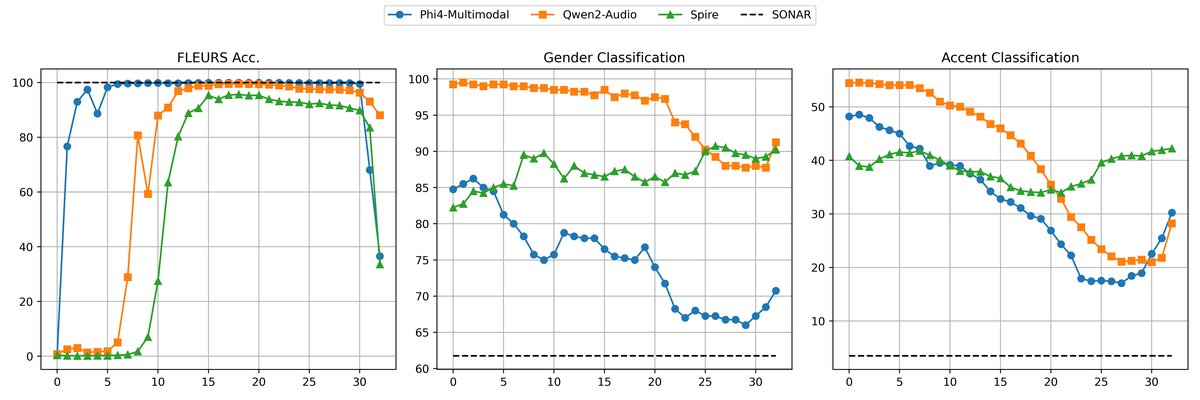 图1关键结论:(左) 所有模型的跨模态检索准确率在中间层(如第22层)达到峰值,后续层下降。(中) Phi4和Qwen2的性别分类准确率随层深显著下降,而Spire保持高位稳定。(右) 类似的,Phi4和Qwen2的口音分类准确率随层深下降,Spire相对稳定但有波动。这直观展示了语义对齐与副语言信息保留之间的权衡。
图1关键结论:(左) 所有模型的跨模态检索准确率在中间层(如第22层)达到峰值,后续层下降。(中) Phi4和Qwen2的性别分类准确率随层深显著下降,而Spire保持高位稳定。(右) 类似的,Phi4和Qwen2的口音分类准确率随层深下降,Spire相对稳定但有波动。这直观展示了语义对齐与副语言信息保留之间的权衡。
⚖️ 评分理由
- 学术质量:5.5/7:创新在于提出并应用了一套系统的分析框架,揭示了重要的设计权衡。实验设计严谨,对比了多个模型、数据集和指标,证据链完整。技术路线正确。主要扣分点在于作为分析性工作,未能提出解决方案,且对比模型数量有限。
- 选题价值:0.5/2:选题非常前沿,直接针对语音大模型的核心瓶颈问题——模态对齐。研究成果能为架构设计者提供明确的设计指引和警示。但因其高度理论分析的性质,对广大工程实践者的直接效用略低。
- 开源与复现加成:0.5/1:论文详细列出了评估所用的模型名称、数据集和方法,为研究者提供了明确的复现路径。但未提供任何代码或模型权重,完全复现其分析需要重新获取所有模型并实现评估脚本,有一定门槛。