📄 Diverse and Few-Step Audio Captioning via Flow Matching
#音频字幕生成 #流匹配 #音频生成 #高效生成 #可控生成
✅ 6.5/10 | 前50% | #音频字幕生成 | #流匹配 | #音频生成 #高效生成
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:未说明(论文仅列出作者姓名,未明确标注第一作者)
- 通讯作者:未说明
- 作者列表:Naoaki Fujita(Panasonic Holdings Corporation, Osaka, Japan)、Hiroki Nakamura(Panasonic Holdings Corporation, Osaka, Japan)、Kosuke Itakura(Panasonic Holdings Corporation, Osaka, Japan)
💡 毒舌点评
亮点:首次将流匹配(Flow Matching)引入自动音频字幕生成,实验证明其在大幅减少采样步数(最高25倍)的同时,能保持甚至超越扩散基线的准确性和多样性,效率提升显著。 短板:研究局限于替换生成过程的“最后一公里”,模型架构(BART解码器、BEATs编码器)直接沿用前人工作;更关键的是,论文未开源代码与模型,且未提供训练硬件与时间,严重削弱了其实用价值和可复现性。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用的是公开数据集Clotho和AudioCaps,但论文未说明其具体获取或预处理方式。
- Demo:未提及。
- 复现材料:提供了算法伪代码(Algorithm 1, 2)和主要训练超参数(优化器、学习率、batch size等)。但缺失模型架构细节(如层数、维度)、硬件信息、完整配置文件。
- 论文中引用的开源项目:使用了预训练的 BEATs [22] 音频编码器和 BART [12] 语言解码器。评估工具使用了 aac-metrics 库。
- 总结:论文中未提及开源计划。
📌 核心摘要
- 要解决的问题:现有的基于扩散模型的多样化音频字幕生成方法,因需要数百步迭代去噪而导致推理计算成本高、速度慢,难以满足实时或大规模处理需求。减少步数则会显著损害生成质量。
- 方法核心:提出首个基于流匹配的音频字幕生成框架(FAC),直接预测从噪声到字幕表示的确定性、线性传输路径,从而用少量采样步数完成生成。
- 与已有方法相比新在哪里:完全用流匹配替代了扩散过程。与基于迭代去噪的扩散模型不同,流匹配学习的是近乎直线的概率路径,使得生成过程更高效、稳定。
- 主要实验结果:在Clotho和AudioCaps数据集上,FAC在30步甚至10步采样下的准确性和多样性指标,与扩散基线(250步)相当或更优。例如,在Clotho上,10步FAC的SPIDEr(0.257)优于250步基线(0.247)。推理时间从每样本2.28秒(250步)降至0.19秒(10步),提速约12倍。通过调节训练时的噪声尺度σ,可以在不增加推理成本的情况下控制生成多样性。
- 实际意义:为高效、可控的多样化音频字幕生成提供了新方案,降低了流式或实时应用中的延迟和计算开销。
- 主要局限性:未开源代码和模型;未报告训练硬件与时间;作为首个应用,流匹配在音频字幕任务上的潜力和边界有待进一步探索;实验主要聚焦于生成过程,未改进音频编码器和语言解码器本身。
🏗️ 模型架构
FAC的整体架构遵循DAC-RLD流水线,如图1所示。其核心是用一个流匹配模块替代了原有的扩散去噪模块。
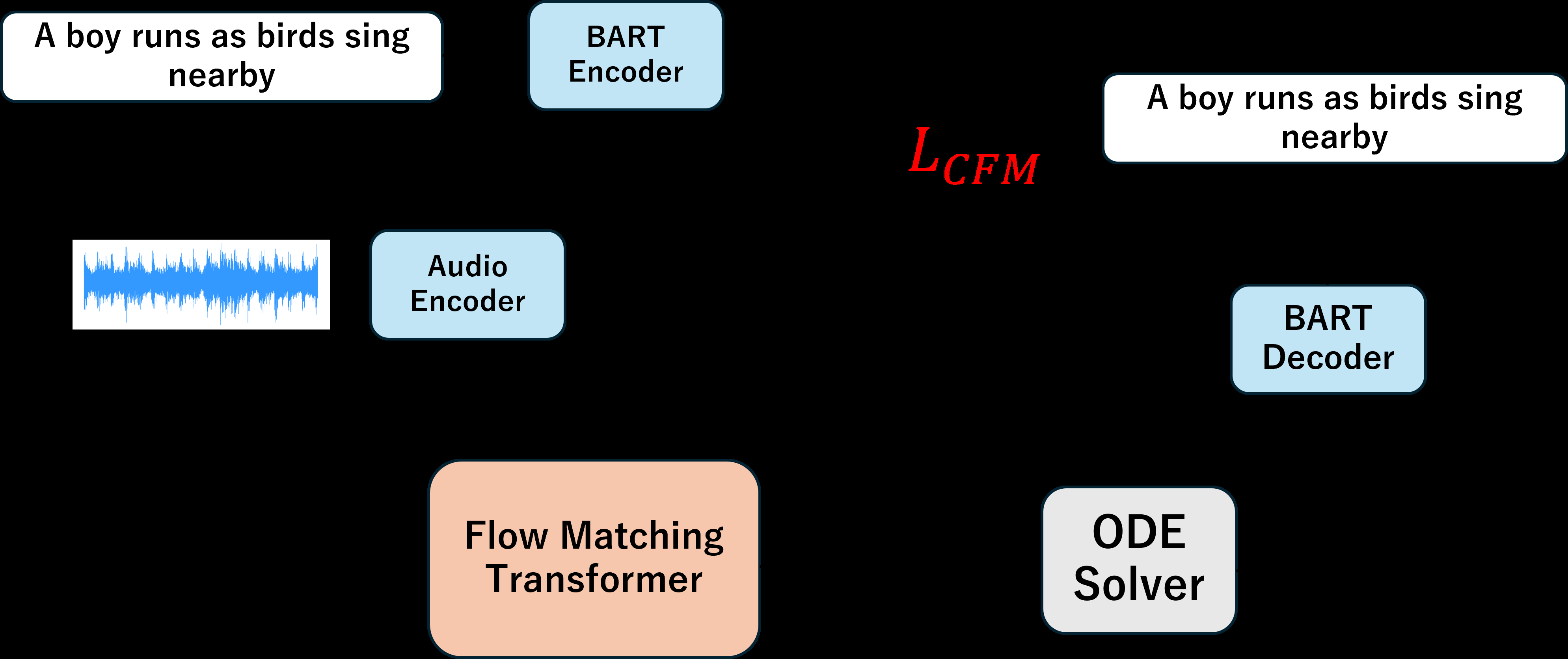
完整流程:
- 音频编码:输入的音频片段首先通过一个预训练的音频编码器(BEATs)转换为声学特征表示
a。 - 初始噪声采样:从先验高斯分布
p0中采样一个潜在表示x0。 - 流匹配迭代:在
K个离散时间步上,从t=0到t=1进行迭代更新。每一步,当前潜在表示xt、上一步的预测x1(用于自条件)、当前时间步t和音频特征a被输入到流匹配模块vθ。该模块直接预测目标字幕表示x1。然后,利用公式xt+Δt = xt + Δt · (x1_hat - xt) / (1 - t)(即欧拉法)更新潜在表示。 - 解码生成:最终得到的潜在表示
x1被送入预训练的BART解码器,解码为自然语言字幕。
主要组件与交互:
- 流匹配模块:核心是一个神经网络(论文未具体说明,推测为Transformer),接收
xt、x1_hat、t和音频条件a,预测目标分布。其训练目标是最小化预测x1与真实字幕编码x1之间的L1损失。 - 自条件机制:在训练和推理中,将上一步的预测
x1_hat反馈回模型,有助于稳定生成过程,这是借鉴自DAC-RLD的设计。 - BART解码器:负责将连续的潜在表示映射到离散的词汇空间,生成流畅的文本。
关键设计选择及动机:
- 选择高斯概率路径(公式1)和直接预测目标x1(公式4)而非速度场,是基于前人研究(Stark et al. [11])表明这能带来更好性能。
- 沿用DAC-RLD的架构,旨在公平比较流匹配与扩散过程本身在效率上的差异。
💡 核心创新点
- 首次将流匹配应用于自动音频字幕生成:填补了该领域生成范式的空白,为平衡多样性、准确性和效率提供了新思路。
- 通过学习线性传输路径实现极少步采样:流匹配模型学习从噪声到数据的确定性、近乎直线的轨迹,使得在极少步数(如10步)内生成高质量字幕成为可能,而扩散模型需数百步。
- 通过调节概率路径参数实现无额外成本的可控多样性:通��调整训练时高斯路径的噪声尺度
σ,可以在推理时不增加任何计算开销的情况下,控制生成字幕的多样性水平,这比扩散模型中常用的引导机制更高效。 - 在多个数据集和步数上验证了效率-质量 Pareto 优势:实验全面展示了FAC在从250步到10步的广泛范围内,其准确性、多样性和效率指标均优于或持平于扩散基线。
🔬 细节详述
- 训练数据:在 Clotho [21] 和 AudioCaps [20] 两个标准AAC数据集上分别独立训练和评估。论文未说明具体预处理与数据增强方法。
- 损失函数:采用条件流匹配损失(CFM Loss),定义为预测的字幕表示
vθ(x,t)与真实字幕编码x1之间的 L1范数(L_CFM = ||vθ(x,t) - x1||1)。 - 训练策略:
- 优化器:AdamW,超参数 β1=0.9, β2=0.999,权重衰减0.01。
- 学习率:1×10⁻⁴,预热2000步,后采用余弦退火调度器。
- 训练轮数:100个epoch。
- 指数移动平均(EMA):衰减率 0.9999。
- 批大小:AudioCaps为 60,Clotho为 20。
- 关键超参数:
- 流匹配中的噪声尺度
σ:消融实验(图3)表明其影响多样性,最佳点在σ=1.0左右。 - 训练时,时间步
t从U(0,1)采样。 - 自条件训练中,通过随机开关(
s > 0.5)决定是否使用上一步预测。
- 流匹配中的噪声尺度
- 训练硬件:论文中未提及。
- 推理细节:
- 解码策略:核采样(nucleus sampling,top-p=0.95, beam size=1,重复惩罚1.2)。
- 评估解码:使用最小贝叶斯风险解码(候选集大小50)以降低随机性。
- 采样步数:实验测试了250、30、10步。
- 正则化技巧:使用了指数移动平均(EMA)和自条件机制。
📊 实验结果
主要对比基准为基于扩散的DAC-RLD模型(基线)。
准确性对比(表1关键数据)
| 步数 | 方法 | Clotho SPIDEr (↑) | AudioCaps SPIDEr (↑) |
|---|---|---|---|
| 250 | 基线 | 0.247 ± 0.004 | 0.460 ± 0.009 |
| 250 | FAC | 0.263 ± 0.008 | 0.460 ± 0.001 |
| 10 | 基线 | 0.253 ± 0.004 | 0.443 ± 0.006 |
| 10 | FAC | 0.257 ± 0.004 | 0.455 ± 0.006 |
结论:FAC在极少步数下(10步)准确度仍优于或接近基线在250步下的水平。
多样性对比(表2关键数据)
| 步数 | 方法 | Clotho Vocab (↑) | Clotho mB4 (↓) |
|---|---|---|---|
| 250 | 基线 | 2374 ± 76.7 | 0.120 ± 0.006 |
| 10 | 基线 | 3543 ± 57.7 | 0.096 ± 0.006 |
| 250 | FAC | 2256 ± 197 | 0.200 ± 0.020 |
| 10 | FAC | 2453 ± 50.7 | 0.188 ± 0.004 |
结论:基线在步数减少时多样性失控(词汇量暴增,mB4骤降),而FAC的多样性指标非常稳定。
与SOTA方法对比(Clotho数据集,表4关键数据)
| 方法 | BLEU4 | SPIDEr | Vocab | div-1 | div-2 |
|---|---|---|---|---|---|
| DAC-RLD (250步) w/o guidance | 0.146 | 0.254 | 2241 | 0.588 | 0.797 |
| FAC (30步) | 0.154 | 0.264 | 2257 | 0.507 | 0.726 |
| FAC (10步) | 0.152 | 0.257 | 2453 | 0.506 | 0.725 |
| 人类 | 0.321 | 0.558 | 3516 | 0.561 | 0.724 |
结论:FAC(10/30步)在准确性上与DAC-RLD基线相当,在多样性指标(div-1, div-2)上更接近人类水平,且mB4显著优于基线,表明其生成的多样性更合理、不过度重复。
推理效率(表3)
| 方法 | 步数 | 时间 [秒/样本] |
|---|---|---|
| 基线 | 250 | 2.28 |
| FAC | 10 | 0.19 |
结论:推理速度提升约12倍(论文摘要提及25倍是基于采样步数减少25倍,而实际墙钟时间受每步计算量影响)。
消融实验:噪声尺度σ的影响(图3)
结论:增大σ(训练噪声)会使生成多样性降低(mB4↑, BLEU4↑),中等σ(≈1.0)时SPIDEr(准确性与多样性综合指标)达到最优。这证明了通过σ控制多样性的有效性。
⚖️ 评分理由
- 学术质量:5.5/7:创新点清晰,将流匹配引入AAC并完成了原理验证和对比实验,技术实现正确。但属于对现有生成框架(DAC-RLD)的“替换升级”,非架构层面的根本性创新。实验对比充分,但缺少对训练开销的报告。
- 选题价值:1.5/2:解决了AAC领域一个实际的痛点(生成效率),具有明确的应用价值。但AAC任务本身相对垂直,受众有限。
- 开源与复现加成:-0.5/1:论文未提供代码、模型权重、预训练检查点或详细的数据集处理说明。虽然给出了伪代码和超参数,但不足以让他人轻松复现全部结果,这是一项重大缺陷。