📄 Dissecting Performance Degradation in Audio Source Separation under Sampling Frequency Mismatch
#音乐源分离 #信号处理 #鲁棒性 #数据增强
✅ 7.5/10 | 前25% | #音乐源分离 | #信号处理 | #鲁棒性 #数据增强
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Kanami Imamura (东京大学,日本产业技术综合研究所(AIST))
- 通讯作者:未说明
- 作者列表:Kanami Imamura (东京大学,AIST)、Tomohiko Nakamura (AIST)、Kohei Yatabe (东京农工大学)、Hiroshi Saruwatari (东京大学)
💡 毒舌点评
亮点:论文以一种非常“工程化”且易于复现的方式(仅在重采样核中添加高斯噪声)解决了DNN模型对采样率变化的敏感性问题,并验证了其在多个主流模型上的普适性,实用价值很高。短板:理论深度有限,对“为什么添加噪声就能恢复性能”的解释停留在“提供高频成分存在性”的层面,未能更深入地揭示DNN模型内部为何对这种统计特性(而非精确频谱内容)如此敏感。
🔗 开源详情
- 代码:论文明确提供了噪声核重采样的代码仓库链接:https://github.com/kuielab/sdx23/。同时,基线模型(如BSRNN)的实现引用了另一个开源仓库:https://github.com/amanteur/BandSplitRNN-PyTorch。
- 模型权重:未提及公开训练好的噪声核重采样网络权重。对于对比中使用的其他预训练模型(如MDX23C),论文未说明是否提供权重。
- 数据集:实验使用了公开的MUSDB18-HQ数据集,论文中给出了数据集引用。
- Demo:未提及。
- 复现材料:论文详细描述了实验设置(数据集划分、重采样参数、网络结构、训练超参数等),并提供了参考代码链接,具备较好的复现基础。
- 论文中引用的开源项目:TorchAudio(用于实现常规重采样), BandSplitRNN-PyTorch(BSRNN实现), Music-Source-Separation-Training(多个预训练模型)。
📌 核心摘要
- 问题:基于DNN的音频源分离模型通常在单一采样频率下训练。当处理不同采样率的输入时,常用重采样到训练采样率的方法,但这会导致性能下降,尤其是当输入采样率低于训练采样率时。
- 方法:作者提出两个假设:(i) 上采样导致的高频成分缺失是性能下降的原因;(ii) 高频成分的存在性比其具体频谱内容更重要。为此,他们提出并对比了三种替代重采样方法:后重采样噪声添加(直接在信号上加噪)、噪声核重采样(在插值核上加噪)、可训练核重采样(用DNN参数化插值核)。
- 创新:与传统重采样方法相比,本工作系统性地分析了性能下降的原因,并提出了一种极其简单却有效的“噪声核重采样”方法。其核心创新在于发现并验证了为重采样信号补充与输入信号相关的高频成分(而非不相关的噪声) 即可有效缓解性能下降。
- 实验结果:在MUSDB18-HQ数据集上进行音乐源分离实验。基线模型BSRNN在8kHz输入(训练于44.1kHz)下,人声SDR从6.58dB降至3.47dB。使用噪声核重采样后,SDR恢复至6.05dB。在包括Conv-TasNet, BSRNN, Mel-RoFormer在内的多个模型上,噪声核重采样均能缓解常规重采样带来的性能下降(见表1)。可训练核重采样效果类似,而后重采样噪声添加则效果不佳甚至恶化。
- 实际意义:提供了一种简单、通用且有效的工程解决方案,只需在现有重采样步骤的核函数中添加微小噪声,即可提升DNN音频模型对采样率变化的鲁棒性,便于实际部署。
- 局限性:研究主要局限于音乐源分离任务,结论在语音增强等其他音频任务上的普适性有待验证。对于可训练核重采样,其训练增加了额外开销。论文未能从根本上提出一种与采样率无关的DNN架构。
🏗️ 模型架构
本文并未提出一个新的分离模型架构,而是专注于研究重采样这一预处理/后处理步骤对现有分离模型性能的影响。其核心架构是DNN音频源分离的通用流水线(如图1(a)所示):
- 输入:采样率为F’s的音频信号。
- 重采样到训练SF:将输入信号从F’s重采样至模型训练采样率Fs。这是本文研究的关键环节。
- DNN处理:将重采样后的信号输入到预训练好的、固定参数的源分离模型(如BSRNN)中,得到分离结果。
- 重采样回原SF:将分离后的信号从Fs重采样回F’s。
- 输出:采样率为F’s的分离后音频信号。
本文的贡献在于改进了第2和第4步中的“重采样”过程,提出了三种替代方案(图1(b-d)):
- 后重采样噪声添加:在完成常规重采样后,直接对整个信号添加高斯噪声。
- 噪声核重采样:在计算插值时,对窗口化Sinc插值核k(win-sinc)添加高斯噪声,得到k(noisy),从而生成包含高频成分的重采样信号。
- 可训练核重采样:用一个小型MLP(k(tr))来参数化插值核,该MLP在固定分离模型的情况下,通过联合损失函数进行端到端训练。
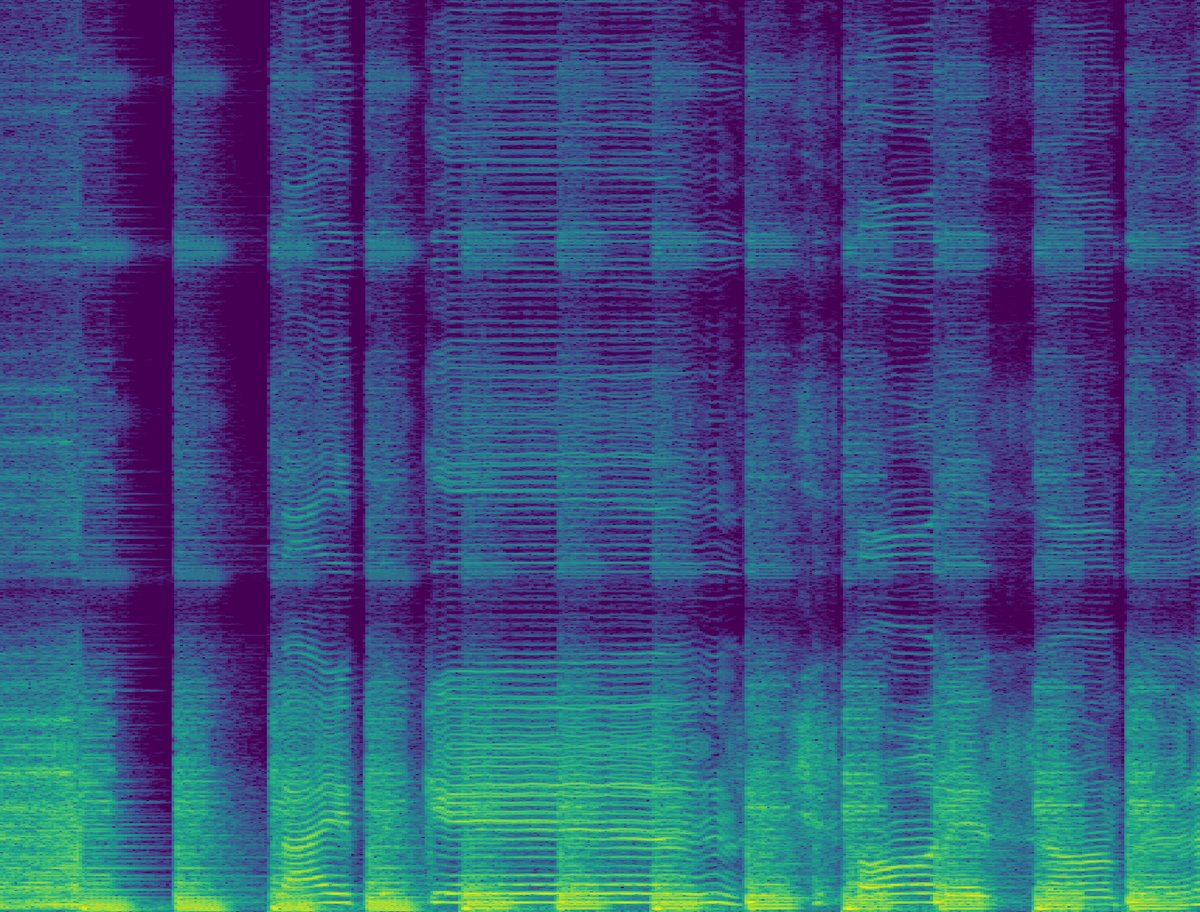 图1:重采样处理流水线及各方法核函数示意图。(a)为处理非训练SF的通用流程;(b)(c)(d)分别为本文提出的三种改进重采样方法。
图1:重采样处理流水线及各方法核函数示意图。(a)为处理非训练SF的通用流程;(b)(c)(d)分别为本文提出的三种改进重采样方法。
💡 核心创新点
- 系统性假设与验证:首次明确提出了关于重采样导致性能下降的两个关键假设——高频成分缺失假说和存在性重于内容假说,并通过精心设计的对比实验提供了实证支持。
- 提出“噪声核重采样”:这是一种极其简单却高效的方法。通过在插值核中加入微弱高斯噪声,使得重采样后的信号频谱在高频段(原Nyquist频率以上)产生与低频成分相关的“影子”成分,而非无意义的随机噪声。这验证了第二个假设。
- 方法的普适性验证:在7个不同的、公开的音乐源分离模型(从Conv-TasNet到MDX23C)上进行了测试,证明“噪声核重采样”普遍��效,且不会损害原本不存在性能下降的模型的性能,强调了其实用性。
- 对比分析的有效性:通过对比“后重采样噪声添加”(失败)与“噪声核重采样”(成功),有力地论证了高频成分与输入信号的相关性是关键,而非简单的能量注入。
🔬 细节详述
- 训练数据:MUSDB18-HQ数据集,150首立体声音乐轨道,包含人声、贝斯、鼓、其他四类音源。使用官方划分:86首训练,14首验证,50首测试。训练/验证时使用原始44.1kHz采样率。测试时额外使用8, 11.025, 16, 22.05, 32kHz的重采样版本。
- 损失函数:对于可训练核重采样,损失函数L定义为分离损失和重采样正则化损失之和:
L = ||ŝ - s||_2^2 + ||y(tr) - y(win-sinc)||_2^2。第一项衡量分离源ŝ与真实源s的L2距离,第二项约束可训练核生成的重采样信号y(tr)接近常规核重采样信号y(win-sinc)。 - 训练策略:
- 可训练核重采样:使用三层MLP(隐藏层32单元,带LayerNorm和ReLU),Adam优化器,初始学习率1e-3,每2个epoch衰减为0.98,梯度裁剪(最大范数5),早停(耐心10个epoch),最多训练100个epoch,批大小4。仅训练核网络,分离模型保持冻结。
- 基线模型训练:对于BSRNN等模型,论文描述遵循其公开代码配置。训练了4个不同随机种子的模型并报告平均结果。
- 关键超参数:
- 常规重采样核:窗口化Sinc函数,Kaiser窗,窗长L=48,α≈4.1(torchaudio默认值)。
- 噪声核重采样:噪声方差σ²=1.0×10⁻⁶,每个输入信号重新采样噪声。
- 后重采样噪声添加:SNR设定为20dB。
- 训练硬件:未说明。
- 推理细节:未说明。
- 正则化或稳定训练技巧:可训练核重采样中,损失函数第二项起到正则化作用,防止核函数偏离过大。
📊 实验结果
主要实验:不同重采样方法在BSRNN模型上的对比(图2)
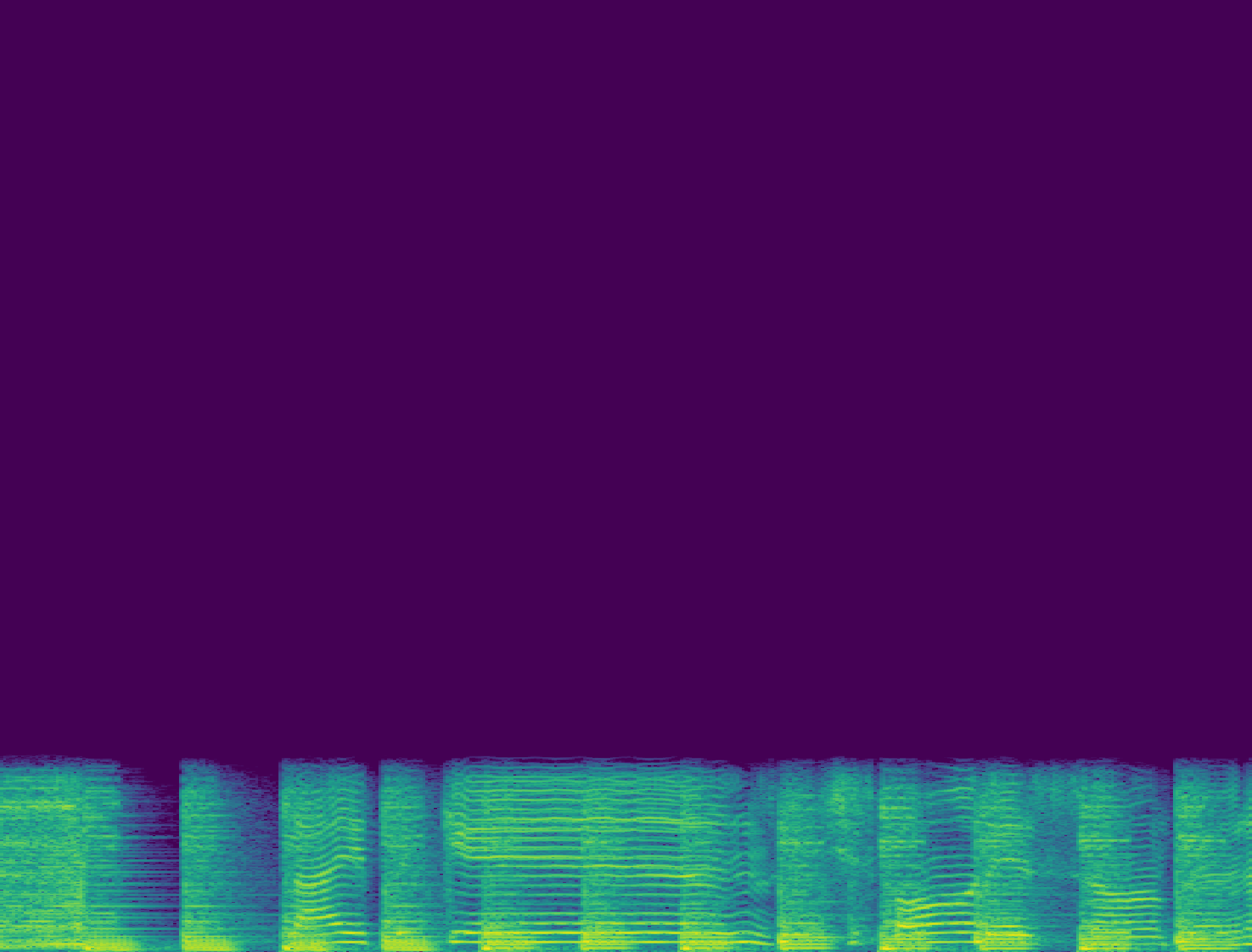 图2:常规重采样、后重采样噪声添加、噪声核重采样、可训练核重采样在BSRNN模型上的SDR(单位:dB)对比。横轴为测试数据采样率(kHz),纵轴为SDR。
图2:常规重采样、后重采样噪声添加、噪声核重采样、可训练核重采样在BSRNN模型上的SDR(单位:dB)对比。横轴为测试数据采样率(kHz),纵轴为SDR。
- 关键结论:对于人声(vocals),常规重采样将SDR从训练采样率(44.1kHz)下的约6.5dB,在8kHz输入时降至约3.5dB。噪声核和可训练核重采样能将SDR恢复至6.0dB以上。后重采样噪声添加效果最差。对于贝斯(bass)、鼓(drums)、其他(other),趋势类似但降幅较小。
核心实验:噪声核重采样对多种模型的普适性(表1)
| 模型 | 44.1kHz (训练SF) | 8kHz 常规重采样 | 8kHz 噪声核重采样 |
|---|---|---|---|
| vocals | |||
| Conv-TasNet | 5.95 | 0.91 ↓ | 5.06 ↑ |
| BSRNN | 6.58 | 3.47 ↓ | 6.05 ↑ |
| Mel-RoFormer | 9.67 | 8.42 ↓ | 9.00 ↑ |
| HT-Demucs | 8.85 | 7.98 ↓ | 8.03 ↑ |
| BS-RoFormer | 10.83 | 10.59 ↓ | 10.51 |
| MDX23C | 9.17 | 9.28 | 9.26 |
| SCNet | 9.46 | 9.33 | 9.32 |
| bass | |||
| Conv-TasNet | 5.31 | 3.74 ↓ | 5.20 ↑ |
| BSRNN | 6.11 | 5.96 ↓ | 6.27 ↑ |
| Mel-RoFormer | 7.01 | 6.18 ↓ | 7.24 ↑ |
| HT-Demucs | 10.03 | 9.93 | 9.95 |
| BS-RoFormer | 9.47 | 9.30 | 9.41 |
| MDX23C | 6.64 | 6.25 | 6.44 |
| SCNet | 9.43 | 9.50 | 9.49 |
| drums | |||
| Conv-TasNet | 5.64 | 3.18 ↓ | 5.20 ↑ |
| BSRNN | 6.62 | 6.25 ↓ | 6.41 ↑ |
| Mel-RoFormer | 8.58 | 4.96 ↓ | 6.93 ↑ |
| HT-Demucs | 9.94 | 8.90 ↓ | 9.04 ↑ |
| BS-RoFormer | 11.56 | 10.79 | 10.65 |
| MDX23C | 7.66 | 6.80 | 7.03 |
| SCNet | 10.21 | 10.07 | 10.09 |
| other | |||
| Conv-TasNet | 3.81 | 1.00 ↓ | 3.42 ↑ |
| BSRNN | 4.35 | 3.53 ↓ | 4.06 ↑ |
| Mel-RoFormer | 6.67 | 5.62 ↓ | 6.13 ↑ |
| HT-Demucs | 6.65 | 5.74 ↓ | 5.95 ↑ |
| BS-RoFormer | 7.81 | 7.22 ↓ | 7.37 ↑ |
| MDX23C | 6.16 | 5.63 | 5.63 |
| SCNet | 7.07 | 6.87 | 6.87 |
关键结论:对于在常规重采样下性能显著下降的模型(如Conv-TasNet, BSRNN, Mel-RoFormer, HT-Demucs),噪声核重采样(粗体数字)普遍能提升性能(↑)。对于本身鲁棒的模型(BS-RoFormer, MDX23C, SCNet),噪声核重采样影响不大,不会损害性能。
核函数分析与频谱示例(图3, 图4)
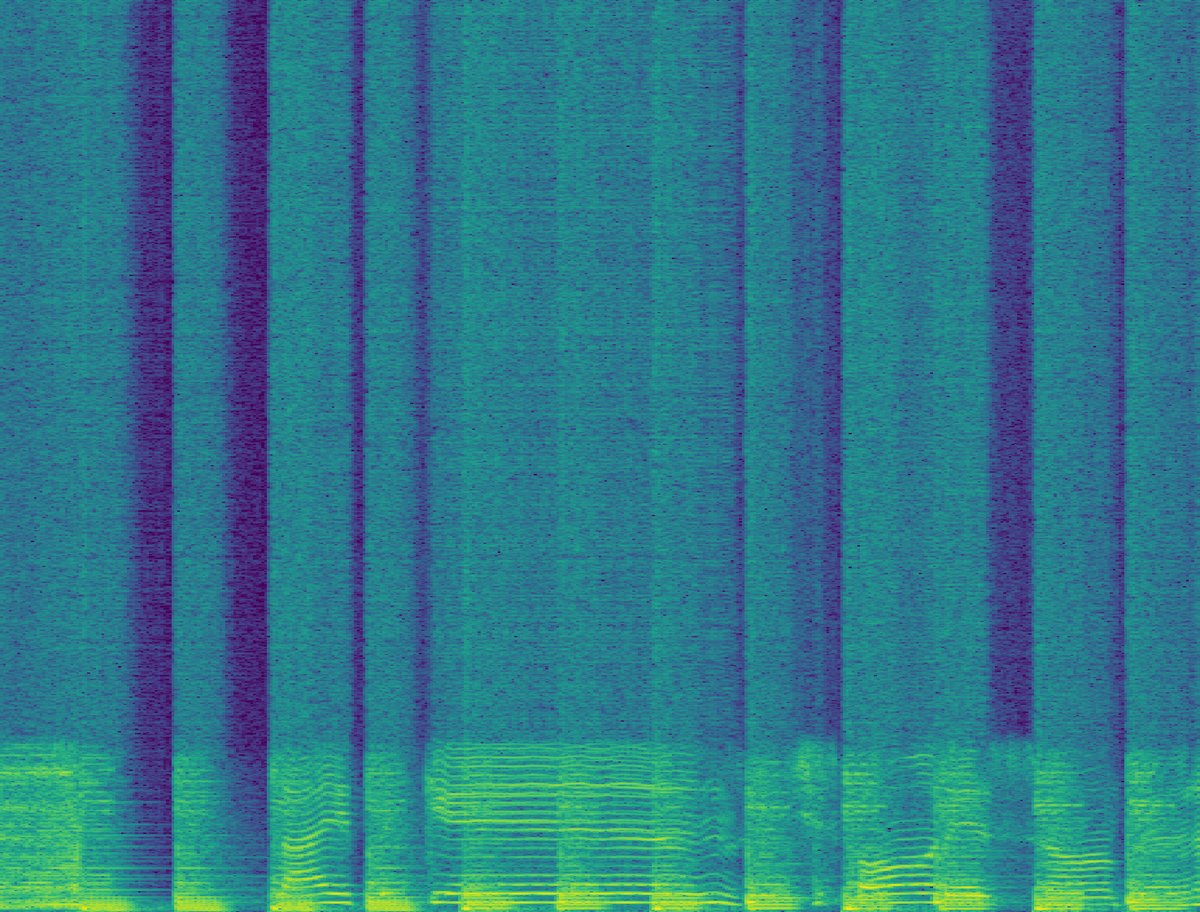 图3:8kHz到44.1kHz重采样时,常规核、噪声核和可训练核的波形及频率响应对比。红色虚线为输入Nyquist频率(4kHz),灰色虚线为训练Nyquist频率(22.05kHz)。噪声核和可训练核在4kHz以上有显著能量。
图3:8kHz到44.1kHz重采样时,常规核、噪声核和可训练核的波形及频率响应对比。红色虚线为输入Nyquist频率(4kHz),灰色虚线为训练Nyquist频率(22.05kHz)。噪声核和可训练核在4kHz以上有显著能量。
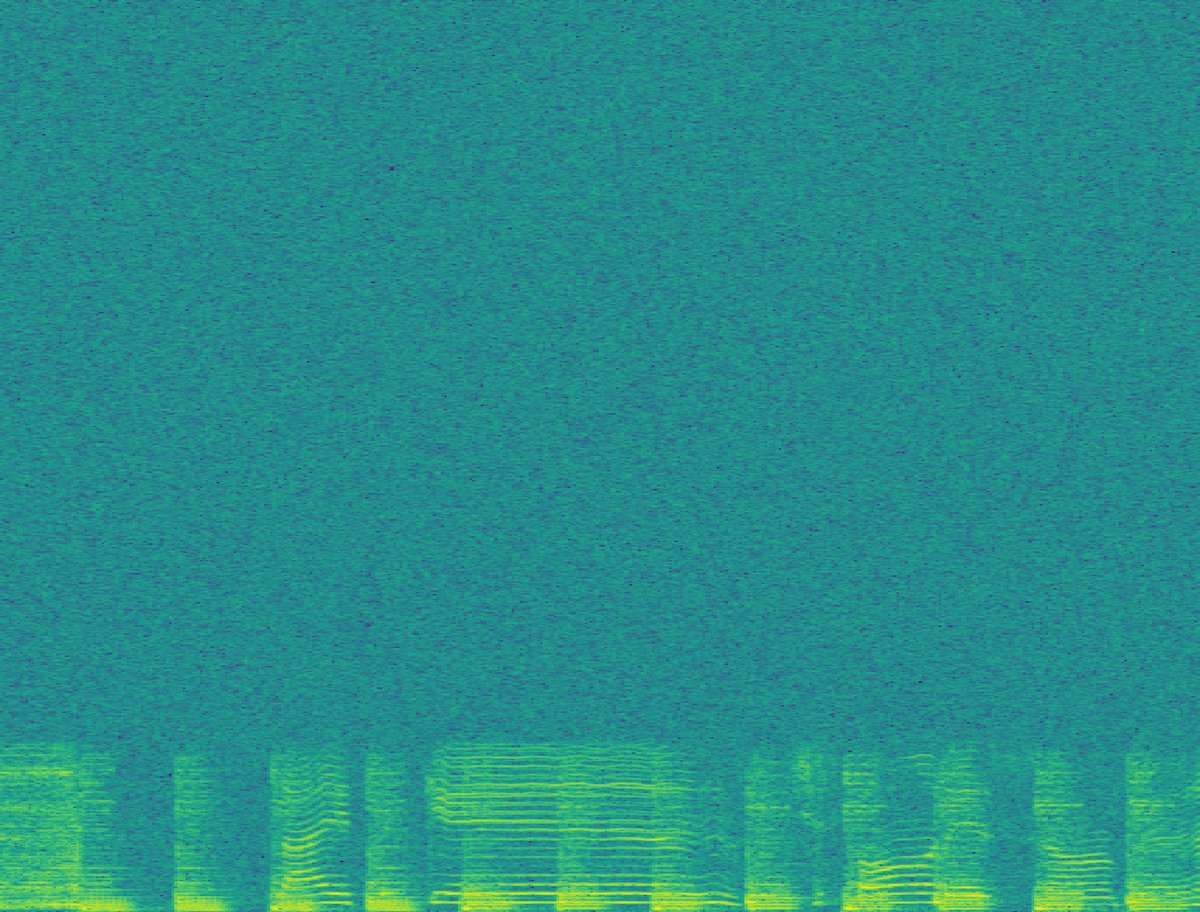 图4:不同方法重采样后的频谱图。(a)常规重采样在4kHz以上为暗区;(b)后重采样噪声添加产生无意义的宽频噪声;(c)噪声核重采样产生与低频相关的条纹状高频成分;(d)可训练核重采样产生混叠结构。
图4:不同方法重采样后的频谱图。(a)常规重采样在4kHz以上为暗区;(b)后重采样噪声添加产生无意义的宽频噪声;(c)噪声核重采样产生与低频相关的条纹状高频成分;(d)可训练核重采样产生混叠结构。
关键结论:图3证实噪声核在4kHz以上引入了更多能量。图4直观显示,噪声核添加的高频成分与低频信号相关,这支持了假设二;而后重采样噪声添加的噪声与信号无关,导致性能下降。
⚖️ 评分理由
- 学术质量:6.5/7:论文问题明确,假设合理,实验设计严谨且充分,通过多种对比方法和模型验证了核心论点,结论有说服力。主要不足在于“噪声核”方法的创新性更多体现在实践发现和系统分析上,理论深度有限。
- 选题价值:1.0/2:解决了音频AI模型部署中的一个具体而普遍的工程痛点,提供了即时可用的解决方案,对相关领域的工程师和研究者有直接参考价值。但话题相对专项,不属于开辟新方向的突破性研究。
- 开源与复现加成:0.5/1:明确提供了核心方法(噪声核重采样)的代码仓库,并注明了所用基线模型的代码来源,复现门槛较低。扣分点在于未提供所有实验的完整复现脚本,且可训练核的部分训练细节(如超参搜索过程)可更详细。