📄 DisContSE: Single-Step Diffusion Speech Enhancement based on Joint Discrete and Continuous Embeddings
#语音增强 #扩散模型 #音频大模型 #自回归模型 #预训练
🔥 8.5/10 | 前10% | #语音增强 | #扩散模型 | #音频大模型 #自回归模型
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yihui Fu(德国布伦瑞克工业大学通信技术研究所)
- 通讯作者:未说明
- 作者列表:Yihui Fu(德国布伦瑞克工业大学通信技术研究所)、Tim Fingscheidt(德国布伦瑞克工业大学通信技术研究所)
💡 毒舌点评
这篇论文的亮点在于它巧妙地将离散token的保真度与连续嵌入的phonetic精度结合起来,并且通过“量化误差掩码初始化”这一小巧思,成功地将扩散过程的反向步骤压缩到一步,实现了性能与效率的双赢。不过,论文通篇没有提及代码和模型开源的具体计划,对于想要立刻复现或应用其技术的同行来说,这无疑是一个不小的障碍。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:论文使用的是公开的URGENT 2024挑战赛数据集,但未提供直接的下载链接或获取方式说明。
- Demo:未提及。
- 复现材料:提供了非常详细的训练细节(见“详细分析”部分),包括数据处理、网络参数、损失函数、训练配置等,有利于复现。但未提供具体的配置文件、启动脚本或检查点。
- 论文中引用的开源项目:引用了以下开源项目作为依赖:
- Descript Audio Codec (DAC): https://github.com/descriptinc/descript-audio-codec
- WavLM: https://huggingface.co/docs/transformers/model_doc/wavlm
- URGENT 2024 Challenge 工具包: https://github.com/urgent-challenge/urgent2024_challenge
- MaskGIT: [13] Chang et al., CVPR 2022.
📌 核心摘要
- 问题:现有基于离散音频编解码器的扩散语音增强方法虽然保真度好,但推理时需要多次迭代,计算复杂度高;且在恢复正确音素(phoneme)方面表现不佳,导致其侵入式指标分数较低。
- 方法核心:本文提出DisContSE,一个混合判别/生成模型。它联合处理离散的音频编解码器token和连续嵌入,分别通过离散增强模块和连续增强模块进行优化,并引入语义增强模块提升音素准确性。其关键创新是提出“量化误差掩码初始化”策略,使得在推理时仅需一步扩散过程即可生成结果。
- 与已有方法相比新在哪里:首次实现了基于音频编解码器的单步扩散语音增强;提出了联合离散与连续表征的统一框架,并明确设计了三个功能互补的增强模块;通过量化误差指导初始化,优化了单步推理的质量。
- 主要实验结果:在URGENT 2024挑战赛数据集上进行评估,DisContSE在PESQ、POLQA、UTMOS等关键指标和主观MOS测试中均排名第一,总体排名(2.36,越低越好)显著优于所有对比的基线扩散模型。消融实验证明了每个模块及单步策略的有效性。关键结果对比如下:
| 方法 | 类型 | PESQ | POLQA | UTMOS | ESTOI | 总体排名 |
|---|---|---|---|---|---|---|
| SGMSE+ [1] | G30 | 2.75 | 2.98 | 2.74 | 0.78 | 6.27 |
| CRP [15] | G1 | 3.10 | 3.01 | 3.04 | 0.81 | 3.36 |
| StoRM [17] | D+G50 | 2.94 | 3.02 | 2.95 | 0.79 | 4.82 |
| Universe++ [18] | D+G8 | 3.09 | 3.23 | 3.04 | 0.80 | 4.18 |
| DisContSE (prop.) | D+G1 | 3.14 | 3.25 | 3.13 | 0.80 | 2.36 |
- 实际意义:该工作为语音增强领域提供了一种高效且高质量的解决方案,单步推理特性使其更适合部署在实时或资源受限的应用场景中。
- 主要局限性:论文未明确开源代码和模型权重,限制了即时复现;尽管提出了单步扩散,但模型本身结构相对复杂,结合了多个预训练模型(DAC, WavLM)和独立的增强模块,总参数量较大。
🏗️ 模型架构
DisContSE是一个由三个主要模块和一个共享的离散扩散解码器构成的混合架构。
 图1 (a) 整体架构与训练策略:清晰地展示了训练时的数据流和损失计算。干净语音x(n)经DAC编码为离散token (Xtok) 和连续嵌入。训练时,随机掩码生成器(MaskGIT)根据时间步t对Xtok生成掩码Mt,得到部分掩码的token Xt。离散增强模块对Xt进行处理。同时,连续增强模块和语义增强模块分别对带噪语音y(n)的DAC连续编码和WavLM特征进行增强,生成Econt和Esem。这两部分信息与离散增强模块的输出相加,作为条件输入到掩码语言模型(Masked LM)。掩码语言模型预测被掩盖位置的干净token,通过交叉熵损失Jdis_CE进行优化。此外,连续增强模块输出预测的连续嵌入,语义增强模块输出预测的语义特征,分别通过MAE损失Jcont_MA和Jsem_MA进行优化。最后,自判别器(self-critic)利用二元交叉熵损失Jcritic_BCE来优化模型判断token真伪的能力。
图1 (a) 整体架构与训练策略:清晰地展示了训练时的数据流和损失计算。干净语音x(n)经DAC编码为离散token (Xtok) 和连续嵌入。训练时,随机掩码生成器(MaskGIT)根据时间步t对Xtok生成掩码Mt,得到部分掩码的token Xt。离散增强模块对Xt进行处理。同时,连续增强模块和语义增强模块分别对带噪语音y(n)的DAC连续编码和WavLM特征进行增强,生成Econt和Esem。这两部分信息与离散增强模块的输出相加,作为条件输入到掩码语言模型(Masked LM)。掩码语言模型预测被掩盖位置的干净token,通过交叉熵损失Jdis_CE进行优化。此外,连续增强模块输出预测的连续嵌入,语义增强模块输出预测的语义特征,分别通过MAE损失Jcont_MA和Jsem_MA进行优化。最后,自判别器(self-critic)利用二元交叉熵损失Jcritic_BCE来优化模型判断token真伪的能力。
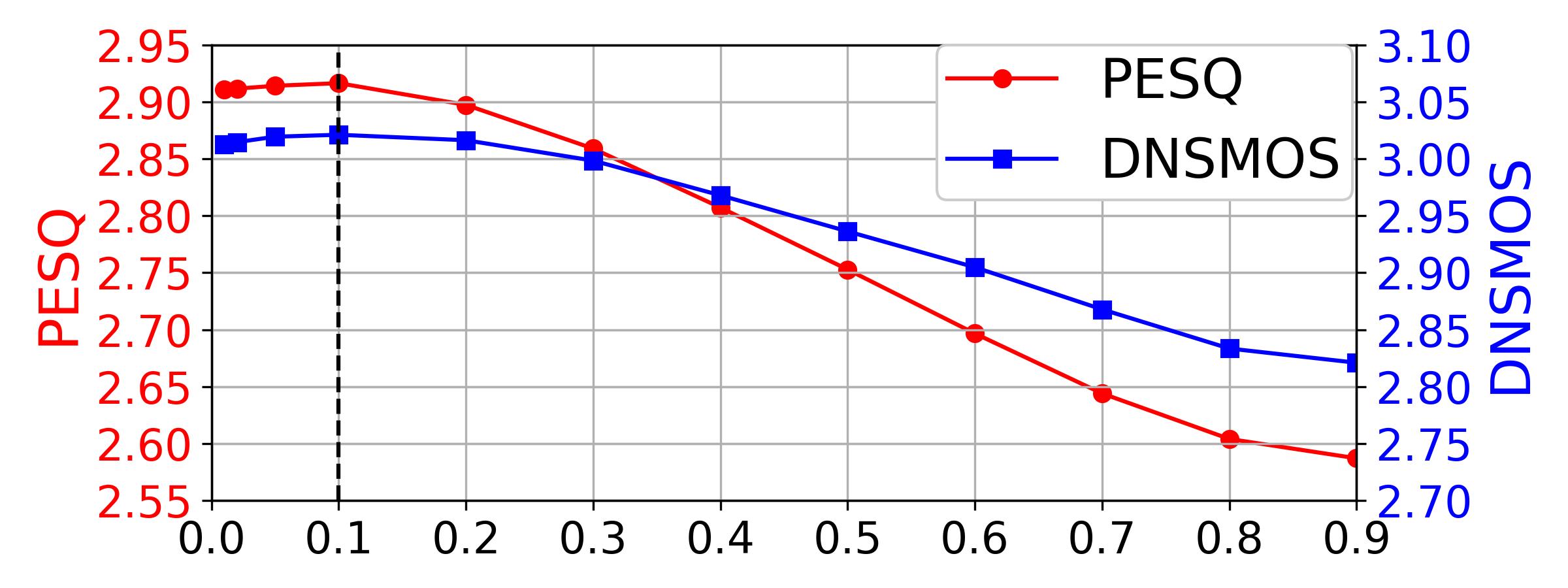 图2 推理过程:推理的核心是单步扩散。首先,根据选择的初始时间步T(论文最优为0.1)生成初始掩码MT。论文提出了两种生成MT的策略,其中核心的“量化误差掩码初始化”(左侧虚线箭头)利用连续增强模块输出与DAC量化之间的误差矩阵Δquant,在误差最大的位置设置掩码。初始掩码Mt与离散增强模块输出的干净token估计X0合并,得到初始状态XT,连同Econt+Esem一起输入离散增强模块。在单步(N=1)情况下,模型直接输出最终预测X0,送入DAC解码器得到增强语音x̂(n)。如果执行多步,则会在中间步骤根据模型输出的置信度重新进行掩码(如红色框内流程)。
图2 推理过程:推理的核心是单步扩散。首先,根据选择的初始时间步T(论文最优为0.1)生成初始掩码MT。论文提出了两种生成MT的策略,其中核心的“量化误差掩码初始化”(左侧虚线箭头)利用连续增强模块输出与DAC量化之间的误差矩阵Δquant,在误差最大的位置设置掩码。初始掩码Mt与离散增强模块输出的干净token估计X0合并,得到初始状态XT,连同Econt+Esem一起输入离散增强模块。在单步(N=1)情况下,模型直接输出最终预测X0,送入DAC解码器得到增强语音x̂(n)。如果执行多步,则会在中间步骤根据模型输出的置信度重新进行掩码(如红色框内流程)。
主要组件详解:
- 离散增强模块:处理离散token。包含C组并行的嵌入层(维度H),将D大小的码本条目映射为H维嵌入,求和后得到Edis。嵌入层与连续增强模块共享权重。其输出与Econt、Esem相加后,送入一个8层Transformer块(维度H=512,4头)的掩码语言模型进行处理。
- 连续增强模块:处理由DAC编码器输出的连续嵌入(维度D=1024)。包含一个由两个全连接层(FC(H)和FC(D))及中间的8层Transformer块组成的连续语言模型。它预测增强后的连续嵌入Xcont,并计算其与干净语音连续嵌入的MAE损失。该模块的输出不仅用于生成Econt作为离散模块的条件,其预测的Xcont还通过DAC tokenizer(图中虚线箭头)转化为离散token,用于量化误差的计算。
- 语义增强模块:处理由WavLM编码器(冻结)提取的语义特征(维度S=1024)。结构类似于连续增强模块,包含两个全连接层(FC(H)和FC(S))和4层Transformer块。它预测增强后的语义特征,并计算MAE损失。其输出经FC(H)层投影为Esem。
- 自判别器(Self-Critic):复用离散增强模块的参数,但将最后的分类层FC(C×D)改为FC(C),将softmax改为sigmoid,输出预测掩码Mt的估计。使用二元交叉熵损失进行训练,使模型能判别token是来自干净语音还是当前模型的生成结果。
💡 核心创新点
- 联合离散与连续嵌入的扩散增强框架:是什么:提出一个同时利用离散编解码token(高保真度)和连续嵌入(良好phonetic精度)的统一语音增强模型。之前局限:以往方法要么只处理离散token(如MaskSR),要么只处理连续表征,未能充分发挥二者互补的优势。如何起作用:通过离散模块增强token保真度,连续模块提供更可靠的特征引导和初始估计,语义模块进一步纠正音素,三者协同。收益:在PESQ等波形质量和UTMOS等自然度指标上取得领先,同时保持了较低的hallucination(由ESTOI和LPS证明)。
- 语义增强模块:是什么:引入一个基于WavLM特征的监督增强模块,专注于提升phonetic准确性。之前局限:先前基于离散token的方法在侵入式指标(反映语音正确性)上表现不佳,表明其可能恢复错误的音素。如何起作用:利用预训练WavLM强大的语义表征能力,通过监督学习直接优化语义特征。收益:消融实验(表2,行1 vs 6)显示,移除该模块会导致WAcc(字准确率)和总体排名下降,证明其对提升下游任务性能和音素准确性有贡献。
- 量化误差掩码初始化策略与单步扩散:是什么:提出一种新的推理初始化方法,利用连续模块输出与DAC量化之间的误差来生成初始掩码,使得仅需一步扩散即可生成高质量结果。之前局限:传统扩散语音增强(如SGMSE+)需要数十到上百步迭代,推理速度慢。如何起作用:在推理开始时(T=0.1),模型已有一个相对可靠的连续增强输出。通过量化误差找出该输出与离散token最不匹配(即不确定性最高)的位置,优先对这些位置进行掩码和预测,使得单步预测能聚焦于最需要修正的部分。收益:实现了单步(D+G1)扩散增强,在性能上超越了需要多步(如G8, G30, G50)的基线模型,推理效率极高。
🔬 细节详述
- 训练数据:URGENT 2024 Speech Enhancement Challenge数据集。训练集Dtrain约634.5小时,验证集Dval约32.7小时。包含三种失真:加噪(无混响)、加噪(有混响)、加噪+削波。SNR范围[-5, 20] dB。语句活动电平范围[-36, -16] dB。采样率16 kHz。排除了CommonVoice 11.0英语部分。测试集Dtest包含661个波形(排除了带宽限制波形)。
- 损失函数:总损失J = Jdis_CE + Jcritic_BCE + Jcont_MA + Jsem_MA。其中:
- Jdis_CE:在被掩码位置计算的预测token与干净token间的交叉熵损失。
- Jcritic_BCE:自判别器预测的掩码与真实掩码间的二元交叉熵损失。
- Jcont_MA:增强后的连续嵌入与干净语音连续嵌入间的MAE损失。
- Jsem_MA:增强后的语义特征与干净语音语义特征间的MAE损失。
- 训练策略:使用AdamW优化器。学习率0.00025,配备4000步的学习率预热。批量大小48。总训练步数300K步。训练硬件为4个NVIDIA H100 GPU,耗时约3.5天。在训练期间,DAC编码器、DAC tokenizer和WavLM编码器的参数保持冻结。
- 关键超参数:
- 模型可训练参数量:81.4M。冻结的DAC参数:74.2M,WavLM参数:158.3M。
- 转换器维度H:512,注意力头数:4。
- 离散增强与连续增强中的掩码/连续LM:各8层转换器。
- 语义LM:4层转换器。
- DAC参数:码本大小D=1024,码书数量C=12。
- WavLM:使用第6层输出,维度S=1024。
- 推理关键参数:初始时间步T=0.1(单步扩散)。
- 训练硬件:4个NVIDIA H100 GPU。
- 推理细节:采用单步反向过程(N=1)。使用论文提出的“量化误差掩码初始化”策略生成初始掩码MT。初始掩码大小由sin(πT/2)·L·C决定,其中T=0.1。将初始状态输入离散增强模块,一次前向计算得到最终预测token X0,送入DAC解码器生成波形。
- 正则化/稳定训练技巧:论文未明确提及使用额外的Dropout或权重衰减等标准正则化技巧。训练稳定性部分依赖于预训练模型(DAC, WavLM)的冻结。
📊 实验结果
主要性能对比(Table 1:在Dtest测试集上与基线方法的比较):
| 方法 | 类型 | PESQ | POLQA | DNSMOS | NISQA | UTMOS | ESTOI | LPS | SBScore | SpkSim | WAcc(%) | MOS | 总体排名↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noisy | - | 1.88 | 2.17 | 1.91 | 1.66 | 1.87 | 0.67 | 0.72 | 0.71 | 0.76 | 79.91 | 2.17 | 8.36 |
| DisContSE (prop.) | D+G1 | 3.14 | 3.25 | 3.19 | 3.85 | 3.13 | 0.80 | 0.82 | 0.84 | 0.60 | 75.50 | 3.75 | 2.36 |
| Continuous Enh only | D | 3.12 | 3.24 | 3.15 | 3.76 | 3.10 | 0.80 | 0.82 | 0.84 | 0.59 | 74.71 | 3.68 | 3.55 |
| CRP [15] | G1 | 3.10 | 3.01 | 3.08 | 3.89 | 3.04 | 0.81 | 0.84 | 0.82 | 0.71 | 78.90 | 3.71 | 3.36 |
| StoRM [17] | D+G50 | 2.94 | 3.02 | 3.15 | 4.02 | 2.95 | 0.79 | 0.79 | 0.80 | 0.77 | 72.76 | 3.67 | 4.82 |
| Universe++ [18] | D+G8 | 3.09 | 3.23 | 3.14 | 4.03 | 3.04 | 0.80 | 0.79 | 0.81 | 0.60 | 73.06 | 3.73 | 4.18 |
| SB [3] | G30 | 2.57 | 2.86 | 3.21 | 3.61 | 3.07 | 0.79 | 0.80 | 0.82 | 0.57 | 75.39 | 3.73 | 4.82 |
注:加粗为最佳,下划线为次佳。总体排名基于各指标平均排名计算。
- 关键发现:DisContSE在PESQ、POLQA、UTMOS和主观MOS上取得了最佳分数,在LPS和WAcc上取得了次佳分数,总体排名第一(2.36)。它平衡了波形质量(侵入式指标)和自然度/可懂度(非侵入式及下游指标)。作为对比,CRP在ESTOI、LPS和WAcc(可懂度相关)上表现最佳,总体排名第二。仅使用连续增强模块的版本(D)性能稍逊,证明了联合离散与连续增强的必要性。
消融研究(Table 2:在Dval验证集上的消融实验):
| 编号 | 方法描述 | T | 类型 | PESQ | POLQA | UTMOS | WAcc(%) | 总体排名↓ |
|---|---|---|---|---|---|---|---|---|
| 1 | 量化误差掩码初始化(提议) | 0.1 | D+G1 | 2.92 | 2.97 | 3.08 | 81.84 | - |
| 2 | 随机掩码初始化 | 0.1 | D+G1 | 2.90 | 2.95 | 3.06 | 82.18 | - |
| 3 | 完全掩码初始化(1步) | 1.0 | D+G1 | 2.60 | 2.54 | 2.82 | 81.98 | - |
| 4 | 完全掩码初始化(5步) | 1.0 | D+G5 | 2.74 | 2.74 | 3.03 | 81.76 | - |
| 6 | 移除语义增强模块 | 0.1 | D+G1 | 2.90 | 2.94 | 3.06 | 80.22 | - |
| 7 | 移除连续增强模块 | 1.0 | G1 | 2.51 | 2.46 | 2.76 | 81.74 | - |
| 8 | 仅连续增强(判别式) | - | D | 2.93 | 3.02 | 3.08 | 81.40 | - |
| 9 | 移除自判别器 | 0.1 | D+G1 | 2.89 | 2.95 | 3.07 | 80.96 | - |
- 关键消融结论:
- 初始化策略有效:比较1、2、3行,提出的量化误差掩码初始化(1)在PESQ和POLQA上优于随机初始化(2),且两者远优于从完全掩码开始的单步(3)或多步(4、5)扩散。
- 各模块不可或缺:比较1、6、7行,移除语义模块(6)导致WAcc下降;移除连续模块(7)导致性能全面大幅下降;仅用连续模块(8,对应表1最后一行)性能低于完整模型(1)。
- 自判别器有帮助:比较1和9行,移除自判别器(9)会导致PESQ和WAcc略有下降。
⚖️ 评分理由
- 学术质量:6.5/7:论文提出了一个设计精巧、模块清晰的联合框架,核心的“单步扩散”创新点明确且有效,具有很强的工程美感。实验设计严谨,在URGENT 2024这一大规模、多维度评估体系上取得了领先的综合表现,消融实验充分验证了每个设计选择的必要性。技术正确性高,所有结论都有扎实的数据支持。
- 选题价值:1.5/2:语音增强是语音处理的核心任务,而提升生成模型的推理效率是整个领域关注的重点。本文成功地在保持甚至提升性能的前提下,将扩散语音增强的推理效率提升了一个数量级(从多步到单步),这具有显著的学术价值和广阔的应用前景(如实时通信、助听器等)。
- 开源与复现加成:0.5/1:论文提供了非常详细的训练配置(数据、优化器、硬件、步数)、模型结构参数(维度、层数)和损失函数设计,为复现打下了良好基础。主要的扣分点在于未提供代码和预训练模型的公开链接,也未在论文中明确讨论开源计划。