📄 Differentiable Pulsetable Synthesis for Wind Instrument Modeling
#音乐生成 #信号处理 #可微分DSP #轻量模型 #风琴乐器
✅ 7.5/10 | 前25% | #音乐生成 | #可微分DSP | #信号处理 #轻量模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Simon Schwär(International Audio Laboratories Erlangen, Germany)
- 通讯作者:未说明
- 作者列表:Simon Schwär(International Audio Laboratories Erlangen, Germany)、Christian Dittmar(Fraunhofer Institute for Integrated Circuits IIS, Erlangen, Germany)、Stefan Balke(International Audio Laboratories Erlangen, Germany)、Meinard Müller(International Audio Laboratories Erlangen, Germany)
💡 毒舌点评
亮点:论文巧妙地将与风琴乐器物理发声机制高度吻合的脉冲表(Pulsetable)合成方法引入可微分框架,不仅免去了繁琐的手工脉冲提取,还通过仅60k参数的轻量模型和几分钟录音实现了高效训练,物理可解释性强。 短板:实验主要依赖客观的谐波幅度差异指标,缺少正式的主观听感评估(如MOS测试),说服力略显不足;模型的泛化能力(如对复杂演奏技巧的建模)和更广泛乐器类型的适用性尚未得到充分验证。
🔗 开源详情
- 代码:论文中提及将在补充网站发布代码(链接见上),但当前未提供具体仓库地址。
- 模型权重:论文中提及将发布模型,未说明是否包含预训练权重。
- 数据集:使用公开的ChoraleBricks数据集[16],论文中引用了其来源。
- Demo:论文中提及将提供音频示例。
- 复现材料:论文提供了模型架构的关键参数(如L, M, 网络大小)、训练策略(epochs, 损失函数)和数据划分信息,并指出详细信息在补充网站。这为复现提供了较好基础。
- 论文中引用的开源项目:引用了DDSP [3], ChoraleBricks数据集[16], PESTO基频估计器[23], 以及一些早期的脉冲/波表合成研究。
📌 核心摘要
本文针对传统脉冲表(Pulsetable)合成方法需要大量人工调参和脉冲提取的痛点,提出了一种可微分的脉冲表合成器。该方法直接通过梯度下降优化脉冲原型波形,并与一个轻量神经网络联合训练,根据目标音高和力度选择脉冲。基于此,作者构建了一个风琴乐器合成框架,其核心创新在于将基于物理激励机制(如簧片、铜管乐器的周期性脉冲激励)的合成模型与端到端学习相结合,仅使用约6万个参数和目标乐器几分钟的录音即可无监督训练。主要实验(如表1所示)表明,在同一音域内,脉冲表、波表和加法合成方法性能相近;但在跨音域(不同声部)泛化时,脉冲表方法在铜管乐器(小号、上低音号)上显著优于其他方法。该框架提供了音高、力度等可解释控制参数,并支持音色迁移。其主要局限性在于:对于音色随音高变化显著的乐器(如单簧管),固定频谱包络的脉冲表方法效果不佳;模型未建模音符起振等瞬态噪声成分。
关键实验结果表格(表1:谐波幅度平均差异,单位dB)
| 乐器 | 合成方式 | 脉冲数M | 同一音域(SV) | 不同音域(DV) |
|---|---|---|---|---|
| 小号(tp) | Pulsetable | 2 | 2.84 | 4.90 |
| 4 | 2.67 | 4.96 | ||
| 16 | 2.57 | 4.96 | ||
| Wavetable | 2 | 2.80 | 5.22 | |
| 4 | 2.71 | 5.39 | ||
| 16 | 2.66 | 5.62 | ||
| Add | - | 2.80 | 6.50 | |
| 上低音号(bar) | Pulsetable | 2 | 3.78 | 3.67 |
| 4 | 3.80 | 3.88 | ||
| 16 | 3.89 | 3.61 | ||
| Wavetable | 2 | 3.81 | 5.24 | |
| 4 | 4.14 | 4.35 | ||
| 16 | 3.78 | 5.18 | ||
| 单簧管(cl) | Pulsetable | 2 | 5.85 | 9.41 |
| 4 | 5.81 | 9.82 | ||
| 16 | 5.84 | 10.23 | ||
| Wavetable | 2 | 5.46 | 3.80 | |
| 4 | 5.65 | 3.54 | ||
| 16 | 5.44 | 5.73 | ||
| 双簧管(ob) | Pulsetable | 2 | 3.65 | - |
| 4 | 3.55 | - | ||
| 16 | 3.58 | - | ||
| Wavetable | 2 | 3.86 | - | |
| 4 | 3.69 | - | ||
| 16 | 3.09 | - |
🏗️ 模型架构
本文提出的风琴乐器合成框架(见图2)是一个自编码器结构,由以下可训练组件构成,数据流从输入音频x开始:
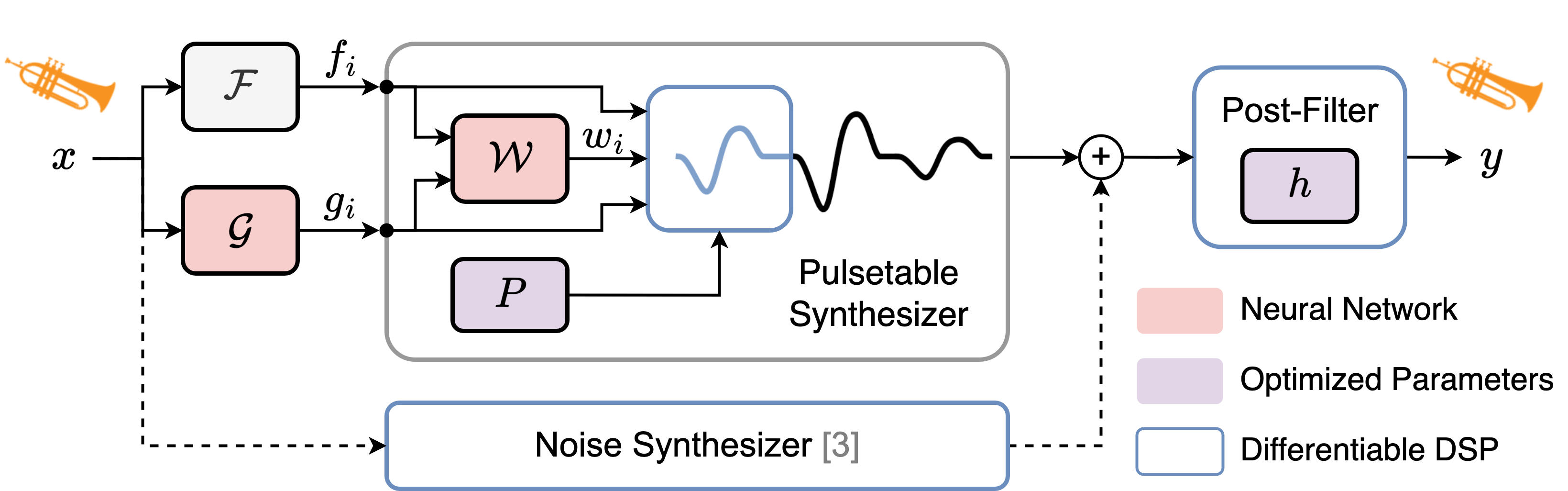
- F0估计器 F:提供每帧基频 fi。为避免DDSP中频率参数训练不稳定的问题,该组件不与其他部分联合训练,可使用现成模型或直接使用标注。
- 增益估计器 G:一个包含约15,000参数的循环神经网络(RNN)。它根据输入信号x预测时变增益控制参数 gi ∈ [0, 1],作为脉冲表合成的响度包络。
- 可微分脉冲表合成器:核心组件。
- 脉冲表 P:一个可训练的矩阵 P ∈ R^{M×L},包含M个长度为L的脉冲原型。
- 选择网络 W:一个轻量神经网络,输入 fi 和 gi,输出一个权重向量 wi ∈ [0, 1]^M,用于从P中选择当前帧的脉冲。为解决离散选择不可微问题,使用温度缩放的softmax进行松弛,并引入熵最大化正则化以避免码本坍缩。
- 合成过程:将选中的脉冲按周期 T=1/fi 重复,并乘以增益gi,生成谐波信号。对于非整数周期,使用线性插值。
- 噪声合成器:一个包含约40,000参数的RNN,用于估计每帧的噪声幅度,并通过滤波产生非谐波成分(如呼吸声、起振噪声)。
- FIR后置滤波器 h:一个长度为4096样本的有限冲激响应滤波器,其系数在时间域直接优化(L1正则化以促进稀疏),用于建模乐器辐射、房间声学等不随脉冲变化的时不变频谱特征。
- 最终输出:将谐波信号与噪声信号相加,再通过FIR滤波器,得到最终的合成信号 y。整个框架通过最小化输入x与输出y之间的多尺度谱损失(MSS)进行端到端训练。
设计选择动机:将控制参数(fi, gi)与音色表征(P, W)解耦,使得模型具有可解释性和灵活性,便于音色迁移和从符号数据控制生成。使用轻量RNN和短脉冲长度(L=64)旨在实现高效训练和推理。
💡 核心创新点
- 可微分脉冲表合成:首次将脉冲表(Pulsetable)合成方法完全可微分化,并嵌入到端到端学习框架中。这解决了传统方法需要从消声室录音中手动提取脉冲的繁琐过程,允许模型从普通录音中直接学习最优脉冲波形。
- 基于物理激励机制的设计:采用脉冲表而非波表作为谐波生成核心,因为脉冲表的“固定波形、变周期”机制更贴近某些风琴乐器(如小号、双簧管)的物理发声原理(周期性产生固定宽度的激励脉冲)。实验表明,这带来了更好的跨音域泛化能力。
- 轻量级风琴乐器合成框架:设计了一个总参数量约6万的紧凑模型(脉冲表参数 + W网络 + G网络 + 噪声网络 + FIR滤波器),仅需几分钟录音即可训练。它提供音高、力度等直观控制参数,实现了效率与可控性的平衡。
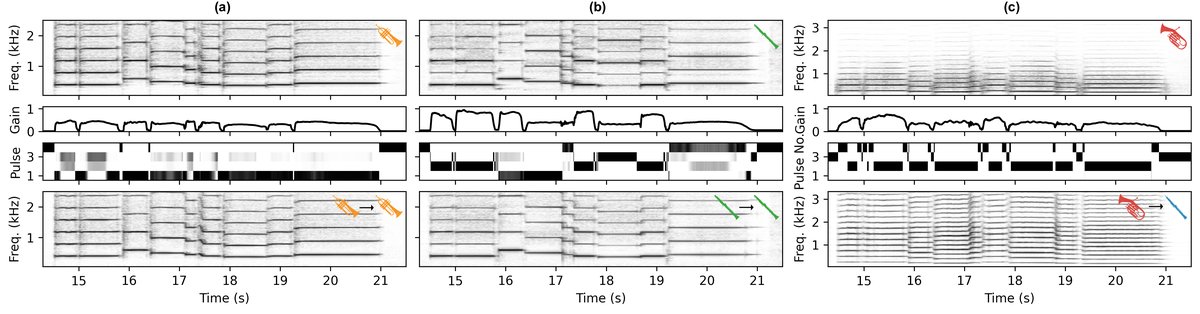
- 解耦的可解释控制与音色迁移:通过将音高(fi)、力度(gi)与音色(由P, W, h决定)解耦,该框架天然支持音色迁移。只需替换目标乐器的P, W, h,即可将一种乐器的演奏风格(由fi, gi序列驱动)转化为另一种乐器的音色(如图3c所示)。
🔬 细节详述
- 训练数据:使用ChoraleBricks数据集[16]。训练时,为每种乐器(小号、上低音号、双簧管、单簧管)选取8个众赞曲的单声部录音,总计约4分18秒。评估分为同声部(SV)和不同声部(DV)两种条件,以测试模型泛化。
- 损失函数:多尺度谱损失(Multi-Scale Spectral Loss, MSS)[24],使用对数幅度谱并限制为正值。窗口大小为[4096, 2048, 1024, 512, 64]。大窗口增强了频率选择性,引导噪声合成器专注于非谐波成分。
- 训练策略:所有模型训练40个epoch。选择网络W中的softmax温度在前几个epoch逐渐降低,以鼓励从软选择过渡到更稀疏的选择。损失函数未提及具体权重。
- 关键超参数:采样率 fs=48kHz;帧率:128样本/帧(约2.67ms);脉冲长度 L=64样本;脉冲数量 M ∈ {2, 4, 16};FIR滤波器长度 4096样本;噪声估计网络参数约40,000;增益估计网络参数约15,000。
- 训练硬件:论文中未说明。
- 推理细节:控制参数fi, gi, wi在帧率上计算,然后线性插值到采样率以生成平滑波形。
- 正则化/稳定训练技巧:1)对选择网络W使用熵最大化正则化,防止码本坍缩;2)对FIR滤波器系数h使用L1正则化,鼓励稀疏表示;3)对F0估计器F进行分离,避免训练不稳定。
📊 实验结果
- 主要评估指标:前五个谐波的帧级幅度平均差异(dB)。该指标与感知音色差异相关[25]。
- 与基线对比:
- 同一音域内(SV):三种合成方法(脉冲表、波表、加法)性能差异很小(<1 dB)。脉冲表方法在M=16时对大多数乐器表现略优。单簧管合成差异整体较大(5-6 dB),可能因模型无法捕获独立于fi/gi的音色变化。
- 跨音域泛化(DV):这是关键发现。对于铜管乐器(小号、上低音号),脉冲表方法(如M=4时小号DV差异4.96 dB)显著优于波表方法(5.39 dB)和加法方法(6.50 dB)。相反,单簧管是例外,其音色(偶次谐波抑制)随音高变化大,因此波表方法(3.54 dB)远优于脉冲表(9.82 dB)。
- 消融研究:脉冲数量M的影响。在SV条件下,增大M(从2到16)带来轻微改善;在DV条件下,M的影响因乐器而异,但总体趋势不明显,表明少量脉冲即可捕捉核心音色特征。
- 音色迁移展示:如图3c所示,将上低音号的控制信号(fi, gi)与双簧管训练的模型(P, W, h)结合,生成了具有双簧管特征(如2kHz附近的共振峰间隙)但音高超出双簧管自然音域的声音,证明了框架的控制灵活性。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了清晰的技术贡献(可微分脉冲表),解决了具体问题(免人工调参),实验设计合理并包含了有意义的对比(脉冲表 vs. 波表)和分析(跨音域泛化)。技术路线正确,细节阐述清楚。扣分点在于实验评估主要依赖客观指标,缺乏主观听感验证;与更广泛的SOTA神经声码器(如基于WaveNet、HiFi-GAN或扩散模型的合成方法)在生成质量上缺乏直接对比,说服力有限。
- 选题价值:1.5/2:选题将物理建模的洞察与现代可微分学习相结合,为高效、可控的乐器合成提供了新范式,具有学术价值和应用潜力(如音乐制作、虚拟乐器)。但领域相对垂直(风琴乐器合成),相较于通用语音合成或音乐生成,其潜在影响力和读者相关性范围较窄。
- 开源与复现加成:0.3/1:论文承诺在补充网站发布代码、模型和音频示例(https://audiolabs-erlangen.de/resources/MIR/2026-ICASSP-DiffPulse),这大大提升了可复现性。但当前文本中未提供直接链接,也未提及训练脚本、配置文件和预训练权重的具体细节,因此加成有限。