📄 Differentiable Grouped Feedback Delay Networks for Learning Direction and Position-Dependent Late Reverberation
#空间音频 #可微分渲染 #深度学习 #信号处理 #实时处理
✅ 7.5/10 | 前25% | #空间音频 | #可微分渲染 | #深度学习 #信号处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Orchisama Das(Kings College London, Dept. of Engineering, United Kingdom)
- 通讯作者:未说明(论文未明确指定)
- 作者列表:
- Orchisama Das(Kings College London, Dept. of Engineering, United Kingdom)
- Sebastian J. Schlecht(Friedrich-Alexander Universit¨at Erlangen-N¨urnberg, Multimedia Comms. and Signal Process., Germany)
- Gloria Dal Santo(Aalto University, Acoustics Lab, Dept. of Info. and Comms. Engineering., Finland)
- Zoran Cvetkovi´c(Kings College London, Dept. of Engineering, United Kingdom)
💡 毒舌点评
亮点在于巧妙地将传统可变声场渲染模型(FDN)与神经网络结合,在保持结构先验的同时实现了端到端学习和高效的多位置渲染,计算复杂度优势明显。短板则是其精度略逊于最强基线(NAF),且在房间过渡区域误差有可见增加,表明其建模复杂空间动态的能力仍有提升空间。
🔗 开源详情
- 代码:是。论文末尾提供了GitHub仓库链接:https://github.com/orchidas/DiffGFDN。
- 模型权重:论文中未提及公开已训练的模型权重。
- 数据集:论文中引用了一个相关的模拟数据集[29](https://zenodo.org/records/13338346),但未明确说明本研究使用的数据集是否完全相同或如何获取。听觉示例链接指向一个网站。
- Demo:论文提供了一个包含听觉示例的网站链接:https://ccrma.stanford.edu/~orchi/FDN/GFDN/DiffGFDN/ICASSP26/。
- 复现材料:论文详细描述了模型架构、损失函数、��练超参数(层数、神经元数、学习率、批大小、轮数)和关键设置(位置编码参数),为复现提供了充分信息。
- 论文中引用的开源项目:依赖了PyFar库中的滤波器组设计工具(链接:https://pyfar.readthedocs.io/stable/modules/pyfar.dsp.filter.html)。
- 总结:论文提供了代码和听觉示例,在复现细节上描述较充分,但未明确承诺公开数据集和预训练模型。
📌 核心摘要
- 问题:在扩展现实(XR)中,实现六自由度(6-DoF)音频渲染需要动态建模房间混响。在耦合空间中,晚期混响的衰减特性随听者位置和方向变化而呈现多斜率、各向异性的特点。
- 方法核心:提出一种扩展的可微分群组反馈延迟网络(DiffGFDN)。该架构在八度带内运行,每个组包含与球谐阶数相关的延迟线。通过多层感知器(MLP)从听者位置预测球谐域的接收器增益,以编码方向依赖性。
- 创新点:与之前仅建模全向晚期混响的DiffGFDN不同,新方法直接从空间房间脉冲响应中学习各向异性的晚期尾音,并将其推广到任意位置;与传统卷积方法相比,渲染多个位置时无需重复存储和处理长脉冲响应,只需更新增益。
- 主要实验结果:在模拟的三耦合房间数据集上,该方法与DNN插值器和神经声场(NAF)方法对比。其双耳EDC平均误差略高于NAF(在0.6米网格间距下约高1.5 dB,在0.9米下约高0.9 dB),但其计算复杂度显著低于基于卷积的方法,为实现更快的6-DoF渲染提供了可能。 论文中的关键结果表(表1)如下:
| 方法 | 网格间距 (m) | 耳朵 | 头朝向误差 (dB) 0° | 90° | 180° | 270° |
|---|---|---|---|---|---|---|
| DiffGFDN | 0.9 | 左 | 3.0 | 3.0 | 3.3 | 3.1 |
| 右 | 3.0 | 3.2 | 3.1 | 3.0 | ||
| 0.6 | 左 | 2.8 | 2.9 | 3.1 | 2.8 | |
| 右 | 2.7 | 2.9 | 2.9 | 2.7 | ||
| CS amplitude interpolator | 0.9 | 左 | 2.5 | 2.6 | 2.7 | 2.5 |
| 右 | 2.5 | 2.6 | 2.6 | 2.5 | ||
| 0.6 | 左 | 1.6 | 1.6 | 2.0 | 1.6 | |
| 右 | 2.0 | 2.1 | 2.3 | 2.0 | ||
| NAF | 0.9 | 左 | 2.3 | 2.2 | 2.2 | 2.2 |
| 右 | 2.5 | 2.4 | 2.3 | 2.4 | ||
| 0.6 | 左 | 1.6 | 1.3 | 1.3 | 1.5 | |
| 右 | 1.5 | 1.3 | 1.4 | 1.4 |
- 实际意义:为XR等应用提供了一种计算高效的、能动态渲染方向和位置相关晚期混响的渲染器。
- 主要局限性:目前仅在模拟数据上评估,未进行主观听音测试;其预测的EDC误差在绝对数值上仍高于NAF;在房间交界区域的建模误差较大。
🏗️ 模型架构
该模型架构旨在学习并渲染方向和位置依赖的晚期混响。整体分为训练和推理两个流程。
- 整体架构(单个八度频带内) 如图1(pdf-image-page2-idx0)所示,核心是一个由G个群组构成的DiffGFDN。每个群组k包含 N’ = (N_sh + 1)^2 条延迟线(N_sh为最大球谐阶数)。每个群组使用固定的延迟长度和基于公共衰减时间T60k计算的吸收增益。可学习参数包括群组内的反馈矩阵 A_k 和输入/输出增益 b_k, c_k。位置依赖的源增益 g_in,k 和接收器增益 g_out,k 通过MLP从傅里叶编码的空间坐标预测得到,并在球谐域中表示。传递函数为各群组贡献的总和(公式2)。
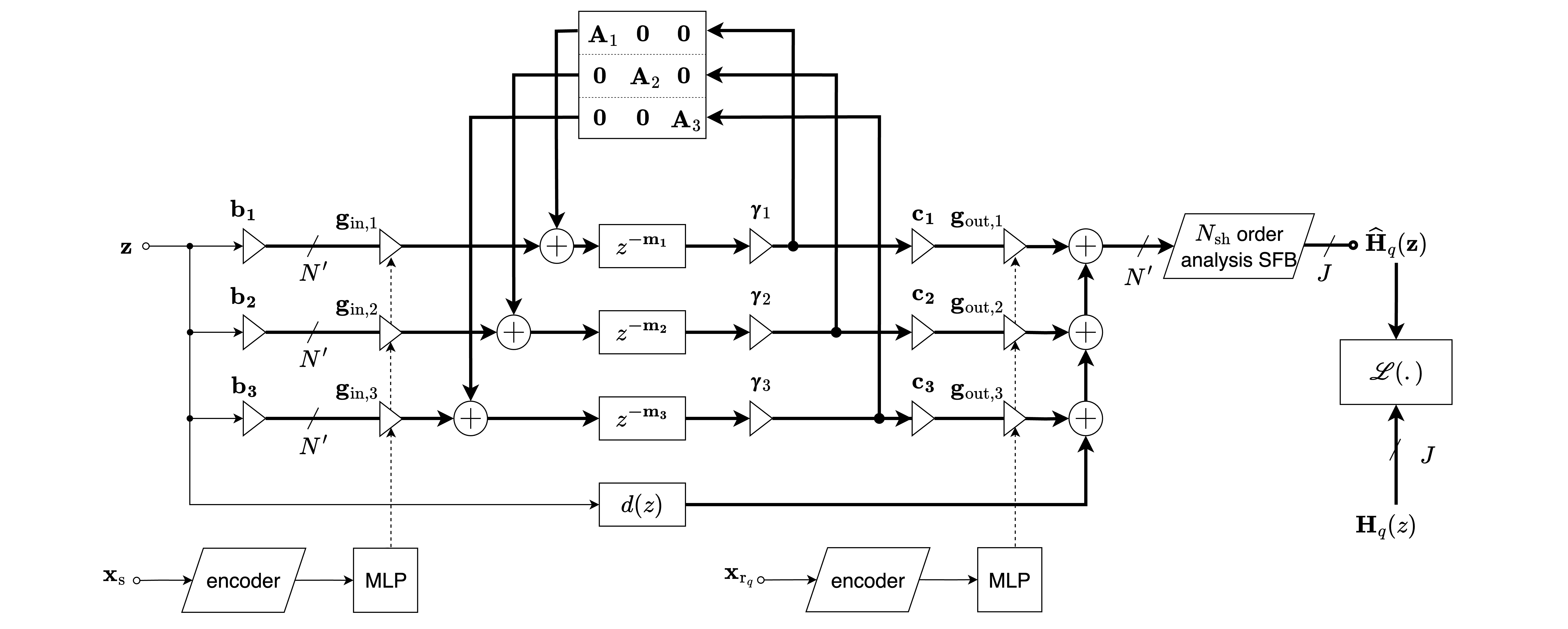 图1: 提出的单个频带DiffGFDN架构。粗线代表多通道信号。H_q(z) 和 \hat{H}_q(z) 分别是第q个接收位置 x_rq 处的参考和预测方向依赖传递函数。x_s 表示源位置。
图1: 提出的单个频带DiffGFDN架构。粗线代表多通道信号。H_q(z) 和 \hat{H}_q(z) 分别是第q个接收位置 x_rq 处的参考和预测方向依赖传递函数。x_s 表示源位置。
- 训练流程 如图2(a)(pdf-image-page3-idx1)所示: a. 输入:测量的空间房间传递函数(SRTFs),以Ambisonics格式编码。 b. 子带分解:通过线性相位FIR滤波器组将SRTFs分解为B个八度子带。 c. 方向转换:每个子带的SRTFs通过球面分析滤波器组(SFB)转换为J个方向的房间传递函数(DRTFs),方向采样自球面t-design网格(公式3)。 d. 预测与损失计算:DiffGFDN预测子带SRTFs,同样经过SFB转换为DRTFs。计算预测与参考DRTFs之间的方向性能量衰减曲线(DEDC)损失、频谱损失和稀疏损失(公式5, 6, 7),并反向传播更新所有可学习参数。
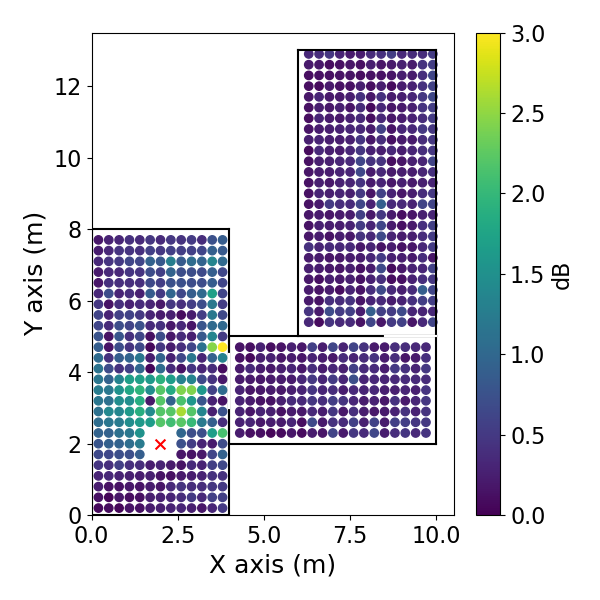 图2: (a) 训练流程。参考SRTFs先经过重建的全八度滤波器组。然后,参考子带SRTFs和DiffGFDN预测的子带SRTFs被波束成形为DRTFs并送入损失函数计算器L。(b) 推理流程。干声信号先经过滤波器组,每个子带由训练好的子带DiffGFDN处理。DiffGFDN的输出被波束成形为扇区,然后求和并编码用于扬声器/双耳播放。
图2: (a) 训练流程。参考SRTFs先经过重建的全八度滤波器组。然后,参考子带SRTFs和DiffGFDN预测的子带SRTFs被波束成形为DRTFs并送入损失函数计算器L。(b) 推理流程。干声信号先经过滤波器组,每个子带由训练好的子带DiffGFDN处理。DiffGFDN的输出被波束成形为扇区,然后求和并编码用于扬声器/双耳播放。
- 推理流程 如图2(b)(pdf-image-page3-idx1)右侧所示: a. 输入:单声道干声信号。 b. 子带分解:通过与训练相同的滤波器组分解为B个子带。 c. DiffGFDN处理:每个子带信号通过在新听者位置预测了接收器增益的DiffGFDN,输出多通道球谐域信号。 d. 方向转换与合成:输出通过SFB转换为J个方向信号,然后将所有子带在时域合成全带输出,最后可进行Ambisonics编码、扬声器渲染或双耳渲染。
关键设计选择与动机:
- 八度子带处理:匹配音频工程习惯,且允许针对不同频带独立建模衰减特性。
- 球谐域方向编码:利用球谐函数的完备性,通过预测球谐接收器增益来参数化方向依赖性,避免了直接为每个方向存储独立滤波器。
- 位置编码:采用傅里叶特征映射,将3D坐标编码为高维向量,便于MLP学习复杂的空间变化函数。
- 延迟线与FDN结构:继承了FDN高效渲染长混响尾音的能力,且其群组结构对应“公共斜率”模型,提供了物理可解释性。
💡 核心创新点
- 将DiffGFDN扩展至方向依赖性建模:首次在可微分FDN框架中引入球谐域的接收器增益,使原本建模全向混响的架构能够学习各向异性的晚期混响场,这是对基础模型的功能性扩展。
- 直接从空间RIR中学习方向依赖的晚期尾音:区别于需要分别渲染方向和空间的传统混合方法,该模型可直接从SRTFs数据中端到端学习晚期混响的方向特性,有望提升一致性。
- 支持高效多位置渲染:核心FDN结构(延迟线、反馈矩阵)是位置无关的,为不同位置仅需预测并更新接收器增益,极大降低了为多听众或多6-DoF位置实时渲染时的计算和存储开销,相比卷积方法优势明显。
- 子带并行处理与复合损失设计:将问题分解到多个八度频带独立解决,并设计了同时关注频谱包络(频谱损失)、稀疏性(稀疏损失)和时域能量衰减曲线(DEDC损失)的复合损失函数,以全面约束学习。
🔬 细节详述
- 训练数据:未提供数据集名称,但描述为使用Treble引擎生成的模拟数据集[29]。包含三间耦合房间的二阶Ambisonics SRIRs,源固定,838个接收位置在0.3米网格上(平面1.5米高)。代码库链接提到一个Zenodo数据集[29]。
- 损失函数:包含三部分(公式7):
- 方向性EDC损失(L_DEDC):在子带内计算,衡量预测与参考DRIR的能量衰减曲线在时间上的差异,并应用了随机时间掩码(Bernoulli p=0.5)以减少过拟合。
- 频谱损失(L_spec):鼓励每个群组的传递函数在频谱上平坦(理想为1),避免频率着色。
- 稀疏损失(L_sparse):鼓励反馈矩阵A_k的元素稀疏(趋近于单位矩阵),这有助于生成更自然的混响。
- 训练策略:在每个八度频带独立训练DiffGFDN。优化器、学习率调度策略未说明。每个子带训练15个epoch,批大小为32,初始学习率为10^-3。MLP使用残差连接、ReLU激活和层归一化。
- 关键超参数:
- 八度子带数 B:6个(中心频率0.25, 0.5, 1, 2, 4, 8 kHz),63Hz和125Hz频带的MLP层数不同。
- 群组数 G:3(对应数据集的公共斜率数量)。
- 最大球谐阶数 N_sh:2(二阶Ambisonics)。
- 每个群组延迟线数 N’:(2+1)^2 = 9。
- MLP结构:0.25-8kHz频带为10层、128神经元;63/125Hz为5层。
- 位置编码:L=20,f_min=1,f_max=32。
- 波束成形方向数 J:12(来自球面t-design网格)。
- 训练硬件:未说明。
- 推理细节:推理时,干声经子带滤波器组、DiffGFDN、SFB波束成形后合成。可输出为Ambisonics、多声道扬声器或双耳信号。论文给出了其计算复杂度公式(公式8),并与均匀分段重叠相加(OLA)卷积的复杂度(公式9)进行了理论对比。
- 正则化或稳定训练技巧:稀疏损失起到了正则化作用;对DEDC损失使用随机时间掩码以防止过拟合;对预测的球谐接收器增益进行能量归一化。
📊 实验结果
主要评估:在模拟的耦合房间数据集上,评估双耳RIR合成的质量,主要指标是平均绝对EDC误差(dB)。比较了提出的DiffGFDN渲染器、基于DNN的CS振幅插值器[16]和神经声场(NAF)[8]方法。
关键对比结果(表1): 见上文“核心摘要”中的Markdown表格。
- 结论:NAF在所有条件下EDC误差最低,但计算成本高。CS插值器次之。本方法(DiffGFDN)的误差略高于NAF(平均约1.5 dB),但显著低于CS插值器在更细网格下的表现,并且在计算效率上具有明显优势(见复杂度分析)。
计算复杂度分析: 论文通过公式(8)和(9)对比了DiffGFDN与OLA卷积的理论计算量(FLOPS):
- DiffGFDN的计算量与RIR长度无关,主要取决于群组数、子带数、方向数和球谐阶数。
- OLA卷积的计算量随RIR长度(T)线性增长。
- 具体示例:对于2秒长的SRIR和N_FFT=512的OLA卷积,DiffGFDN所需FLOPS约为1,884,而OLA卷积约为26,478,相差一个数量级。
方向EDC误差空间分布: 如图3(pdf-image-page3-idx2至pdf-image-page3-idx9)所示。该图展示了1 kHz频带下,两种相反方向(方位角0°和180°)的平均绝对EDC误差在空间位置上的分布,分别对应DiffGFDN(图a-d)和CS插值器(图e-h),以及0.9米和0.6米两种训练网格间距。
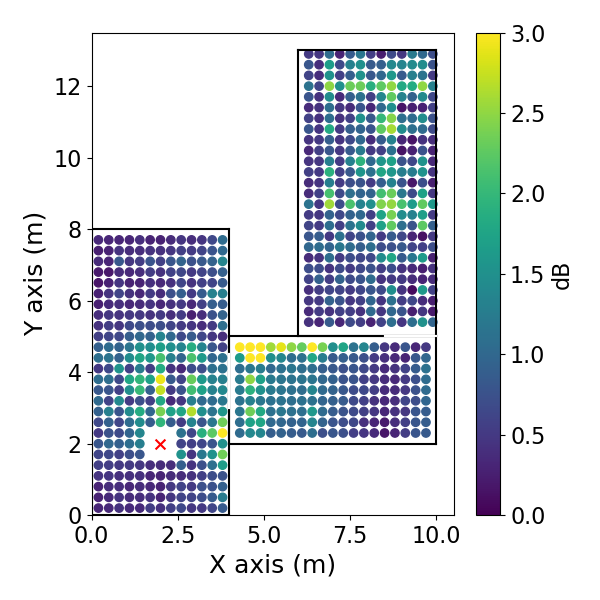
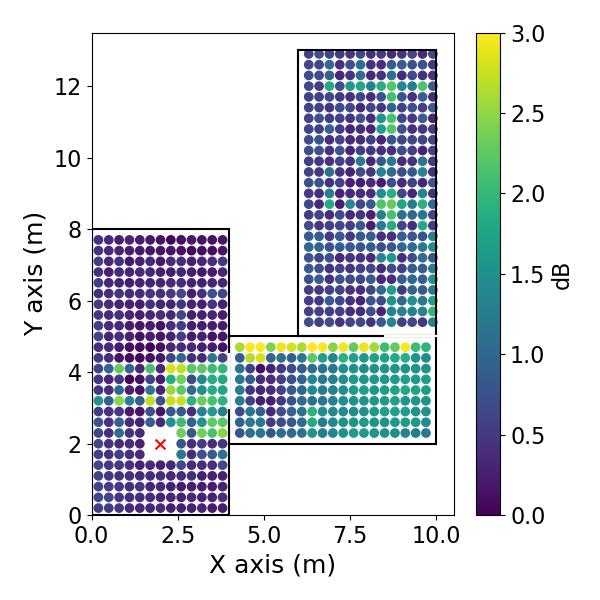
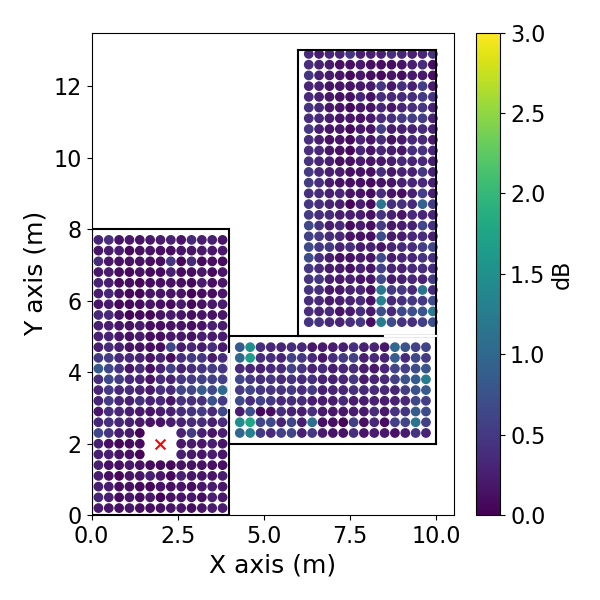
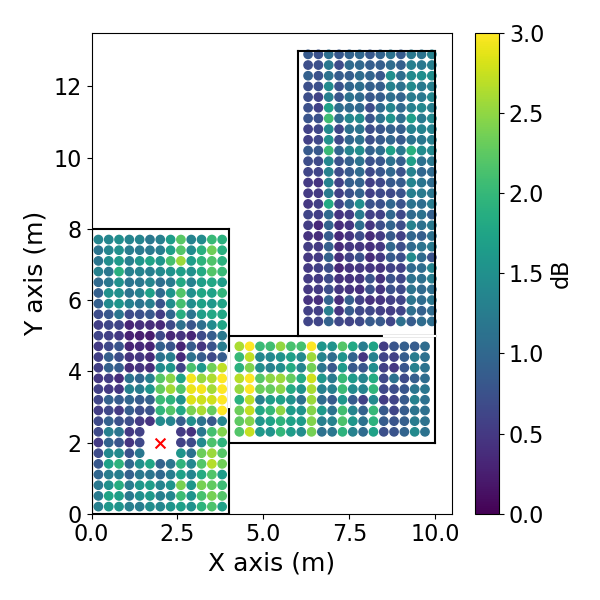 图3: DiffGFDN重建的DEDC误差。(a) 方位角180°,0.9m网格;(b) 180°,0.6m网格;(c) 0°,0.9m网格;(d) 0°,0.6m网格。
图3: DiffGFDN重建的DEDC误差。(a) 方位角180°,0.9m网格;(b) 180°,0.6m网格;(c) 0°,0.9m网格;(d) 0°,0.6m网格。
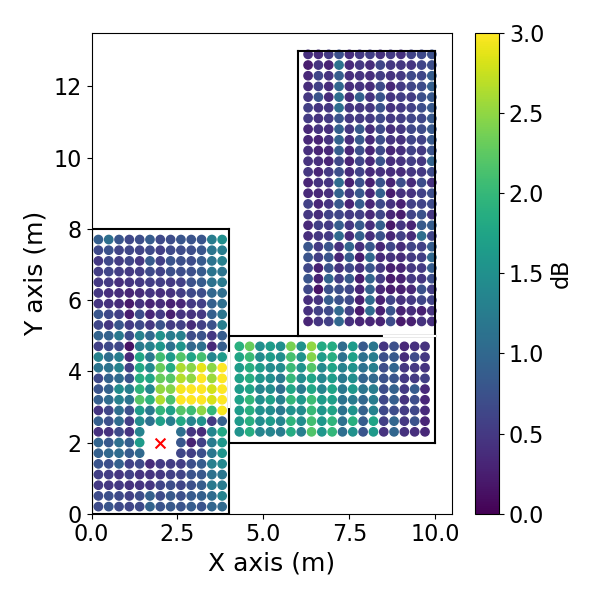
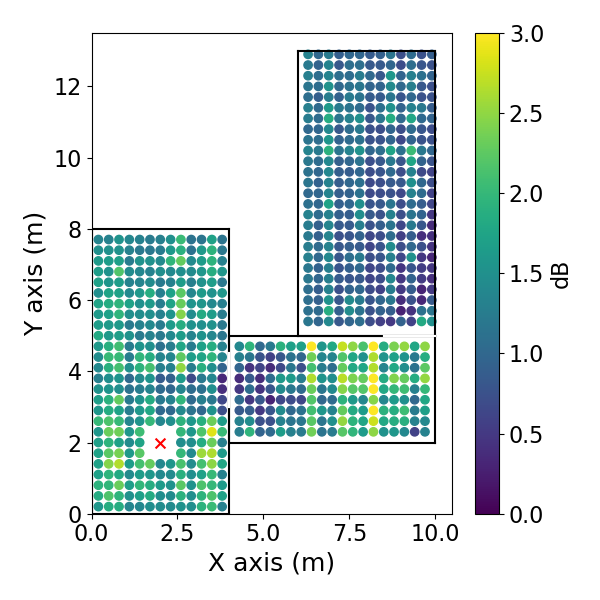
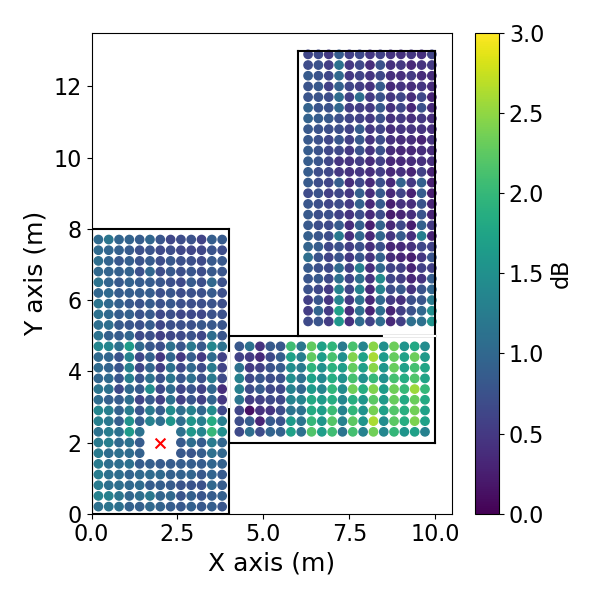
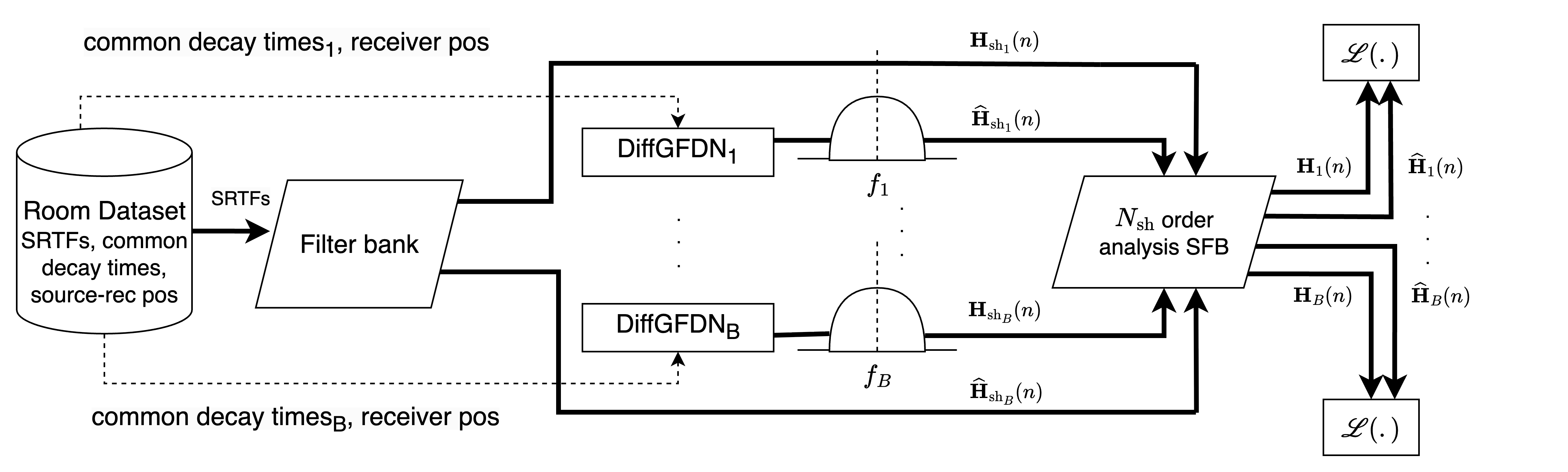 图3: DNN CS插值器的DEDC误差。(e) 方位角180°,0.9m网格;(f) 180°,0.6m网格;(g) 0°,0.9m网格;(h) 0°,0.6m网格。
图3: DNN CS插值器的DEDC误差。(e) 方位角180°,0.9m网格;(f) 180°,0.6m网格;(g) 0°,0.9m网格;(h) 0°,0.6m网格。
- 关键结论:
- 两种方法的误差在房间中心区域相对较低,在房间边界和过渡区域(尤其是两个房间的连接处)误差增大。
- CS插值器在更细的网格(0.6m)上训练时,误差下降更明显(对比图e和f),表明其对采样密度更敏感。
- DiffGFDN的误差分布在不同网格间距下变化相对较小,表现出更好的泛化潜力。
- 在房间的某些区域,误差分布具有方向依赖性(对比图a和c,或e和g)。
⚖️ 评分理由
- 学术质量:6.0/7:创新性地将FDN与神经网络结合用于方向依赖性混响建模,技术路径清晰完整。实验设置了合理的对比基线(NAF代表高精度上限,CS插值器代表同类学习方法),并提供了详细的误差分析和计算复杂度对比。但创新性更多是现有框架(DiffGFDN)的功能性扩展而非范式突破;实验仅基于模拟数据,缺乏真实数据验证和主观听音测试;报告的精度未超越最强基线(NAF)。
- 选题价值:1.5/2:课题直接针对XR/AR音频渲染的核心挑战之一(动态混响),具有明确的应用前景和前沿性。空间音频是重要发展方向,该研究提供了高效渲染的新思路。
- 开源与复现加成:+0.5/1:论文明确提供了代码仓库链接(https://github.com/orchidas/DiffGFDN),这是非常积极的复现信号。但未提及模型权重和训练数据的公开(尽管引用了相关数据集),因此加成有限。