📄 DepthTalk: Few-Shot Talking Head Generation with Depth-Aware 3D Gaussian Field Motion
#说话人生成 #3D高斯溅射 #少样本学习 #音视频
✅ 7.0/10 | 前25% | #说话人生成 | #3D高斯溅射 | #少样本学习 #音视频
学术质量 5.8/7 | 选题价值 1.2/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Shucheng Ji(澳门理工大学应用科学学院)
- 通讯作者:Xiaochen Yuan(澳门理工大学应用科学学院)
- 作者列表:Shucheng Ji(澳门理工大学应用科学学院)、Junqing Huang(澳门理工大学应用科学学院)、Yang Lian(澳门理工大学应用科学学院)、Xiaochen Yuan(澳门理工大学应用科学学院)
💡 毒舌点评
亮点在于其“深度梯度损失”设计很巧妙,通过监督深度图的梯度而非绝对值来防止尺度不一致导致的深度崩塌,这是一个对实际工程问题有深刻洞察的解决方案。短板是其整体框架建立在强大的预训练深度先验模型(Sapiens)之上,这在一定程度上限制了方法的通用性和在无此类先验场景下的可用性,且论文未提供代码,复现门槛较高。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开模型权重。
- 数据集:使用了HDTF和公开数据集,但未说明这些数据集是否在本工作专属发布或如何获取。
- Demo:未提及在线演示。
- 复现材料:提供了训练时长(预训练2小时)、优化器、学习率、损失权重等关键超参数,但缺乏batch size、数据预处理细节等,复现信息不够充分。
- 论文中引用的开源项目:引用了InsTaG([2])、SyncTalk([10])、GeneFace([14])、MimicTalk([15])等开源工作作为基线或技术参考。
- 总体:论文中未提及开源计划。
📌 核心摘要
- 问题:基于3D高斯溅射(3DGS)的说话人生成模型在优化时存在深度歧义,导致在渲染新视角(尤其是大角度偏转)时产生模糊、暗区等视觉伪影。现有方法仅在训练阶段引入深度监督,缺乏重建时的深度感知机制。
- 方法核心:提出DepthTalk框架。其核心是深度感知高斯运动网络(DAGM),采用双管道架构:一个“深度感知管道”整合深度先验、表情和音频特征预测深度相关的高斯场变换;另一个“几何感知管道”专注于利用表情和音频预测面部运动变换。两者通过自适应运动融合(MF) 模块结合。此外,提出了深度梯度损失(DGL),通过Sobel算子计算并比较渲染深度图与先验深度图的梯度幅度来施加监督,避免因绝对尺度差异造成的深度崩塌。
- 新意:将深度感知直接嵌入到高斯场的重建(变换预测)过程中,而非仅用于训练正则化;解耦了深度对齐与面部运动建模;提出基于梯度的深度损失函数。
- 实验:在仅5秒视频的少样本设定下进行实验。定量结果:DepthTalk在图像质量指标(PSNR: 29.8974, LPIPS: 0.0530, SSIM: 0.9226)上优于所有对比方法(包括InsTaG),唇部运动精度(LMD: 3.0836)也达到最佳。消融研究表明,DAGM、MF和DGL三个组件共同作用才能达到最佳性能。定性结果(图3)显示,DepthTalk在生成新视角面部时,光照更真实,伪影更少。
- 意义:在数据受限(少样本)场景下,实现了更高质量、更几何一致的说话人头部视频合成,对数字人、虚拟现实等应用有潜在价值。
- 局限性:依赖外部预训练的深度先验模型(Sapiens);实验数据集(HDTF等)的规模和多样性有限;推理速度(32.66 FPS)虽实时但略低于InsTaG。
🏗️ 模型架构
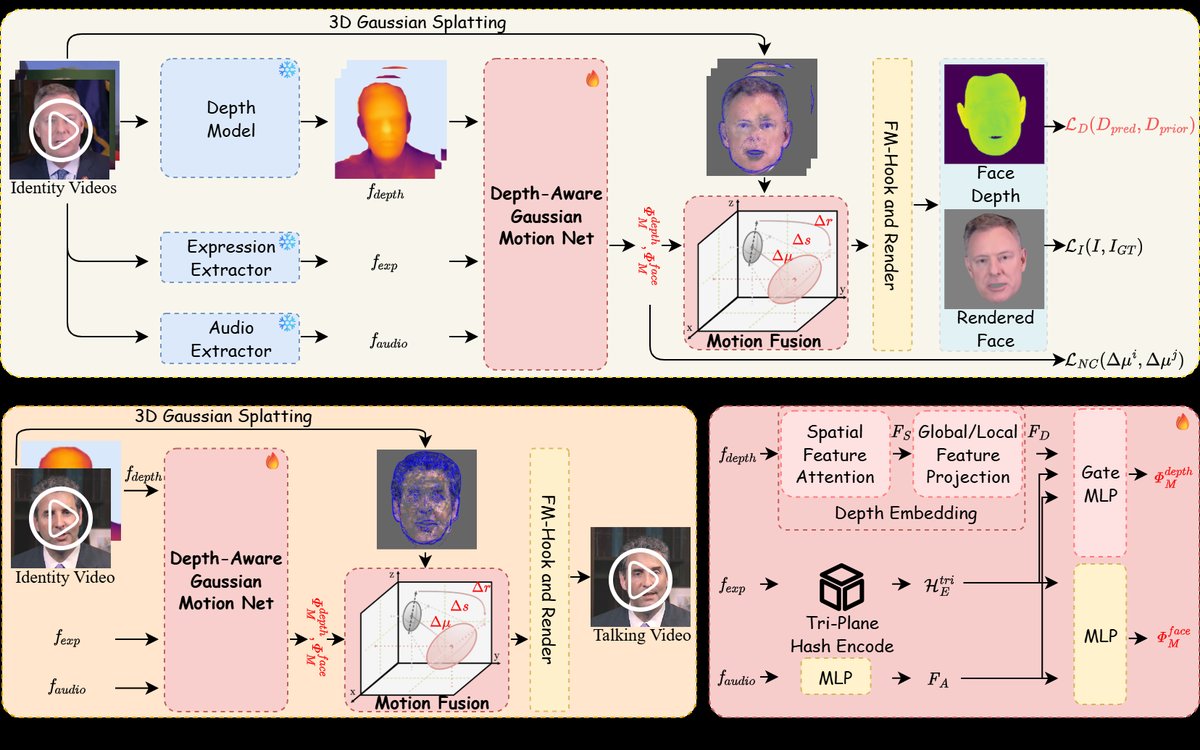 论文的整体架构如图2所示。输入是音频特征、上半脸表情控制信号和头部姿态(相机位姿)。核心流程如下:
论文的整体架构如图2所示。输入是音频特征、上半脸表情控制信号和头部姿态(相机位姿)。核心流程如下:
- 高斯场构建:首先从多身份视频构建一个初始的3D高斯场表示。
- 双管道运动预测(DAGM):
- 深度感知管道:接收三个输入流:深度先验特征(来自Sapiens模型)、表情特征、音频特征。它们通过一个三平面哈希编码器(H) 和MLP网络进行处理,并通过深度嵌入模块(emb) 进行整合。深度嵌入模块先对深度先验进行卷积下采样,再通过空间注意力机制强调关键区域,并分别进行全局(全局平均池化)和局部(自适应平均池化)投影,最后融合得到深度特征FD。最终输出是预测的深度相关高斯场变换 Φdepth_M = {∆µd, ∆sd, ∆rd}。
- 几何感知管道:仅使用表情特征和音频特征,通过相同的哈希编码器和MLP,输出面部运动相关的变换 Φface_M = {∆µf, ∆rf, ∆sf}。
- 自适应运动融合(MF):将两个管道的变换进行融合。对于位置和颜色变换,采用动态加权求和:∆µ = wd*∆µd + ∆µf,∆r = ∆rd + ∆rf,其中wd是可学习的权重。对于缩放因子变换∆s则直接相加(∆sd + ∆sf)。权重wd在预训练阶段保持恒定,在身份微调阶段变为可学习,以平衡深度一致性和几何保真度。
- 渲染与损失:应用融合后的变换更新高斯场,然后渲染得到图像和深度图。使用深度梯度损失(DGL) 监督渲染深度图与先验深度图的梯度一致性,同时使用L1、D-SSIM等损失监督图像质量。
💡 核心创新点
- 深度感知的高斯运动预测(DAGM):之前的工作(如InsTaG)在训练时用深度损失正则化,但推理时高斯场变换不依赖深度信息。DepthTalk将深度先验直接输入运动预测网络,使高斯场的变换在生成时就具备深度感知能力,从而更有效地纠正几何不一致。
- 解耦的双管道设计与自适应融合:认识到深度对齐(全局几何结构)和面部运动(局部表情细节)的需求不同,将两者解耦到不同管道中独立学习,并通过可学习权重wd进行自适应融合,避免了单一管道建模的局限性。
- 深度梯度损失(DGL):针对深度先验图与渲染深度图因尺度不同而无法直接比较的问题,提出通过比较它们的梯度幅度来进行监督。这相当于只监督深度的“相对变化”或“边缘结构”,而非“绝对值”,从而更鲁棒地防止深度崩塌,同时保留几何细节。
🔬 细节详述
- 训练数据:
- 预训练:使用6个来自HDTF数据集的扩展说话视频(4-8分钟,512x512)。
- 测试:使用4个来自公开数据集的视频,确保与训练无身份重叠。每个测试视频拆分为5秒训练片段和12秒未见测试片段。
- 未说明具体数据增强方法。
- 损失函数:
- 深度梯度损失(LD):使用3x3 Sobel算子计算预测深度图和先验深度图的水平、垂直梯度,得到梯度幅度,然后计算两者在每个像素上的L1范数并平均。公式见Eq. 7和8。权重 λD = 2e-3。
- 图像重建损失:包括L1损失(LI, λI=1.0)、1-DSSIM损失(LS, λS=0.2)。
- 负对比损失(LC):仅在预训练阶段使用,用于最大化不同身份高斯特征之间的距离,权重 λC=1.0。公式见Eq. 9。
- 训练策略:
- 两阶段训练:1) 多身份预训练:同时训练DAGM网络,使用所有损失。2) 身份微调:使用预训练模型初始化,针对单个身份进行微调,分为两个子阶段:先使用两个管道的变换构建初始场,再微调阶段仅优化几何感知管道。微调阶段移除了负对比损失。
- 优化器:AdamW。
- 学习率:网格(哈希编码器)学习率为5e-3,神经网络(MLP等)学习率为5e-4。
- 训练步数:预训练120,000次迭代,微调10,000次迭代。
- 未说明 batch size、warmup策略、学习率调度策略。
- 关键超参数:深度先验图尺寸512x512;DAGM中下采样后特征图64x64x256;GroupNorm组大小16;Sobel滤波器3x3;ε=1e-6;可学习权重wp平衡全局/局部深度投影。
- 训练硬件:NVIDIA RTX 4090 GPU,预训练耗时约2小时。
- 推理细节:头部姿态通过BFM(3D Morphable Face Model)估计。采用FM-Hook处理嘴部建模以保证唇形同步。推理帧率32.66 FPS。
- 正则化技巧:负对比损失用于预训练阶段的多身份特征分离。
📊 实验结果
论文在5秒少样本设定下进行了对比实验和消融研究。
表1:与基线方法的定量比较(5秒训练数据)
| 方法 | PSNR↑ | LPIPS↓ | SSIM↑ | LMD↓ | 训练时间↓ | FPS↑ | 实时 |
|---|---|---|---|---|---|---|---|
| GeneFace | 16.7544 | 0.3392 | 0.5060 | 6.2994 | 8小时 | 19.39 | |
| MimicTalk | 16.6801 | 0.3488 | 0.5050 | 6.4199 | 38分钟 | 17.52 | |
| InsTaG | 29.3591 | 0.0566 | 0.9166 | 3.1972 | 4分钟 | 40.62 | ✓ |
| DepthTalk (ours) | 29.8974 | 0.0530 | 0.9226 | 3.0836 | 4分钟 | 32.66 | ✓ |
关键结论:DepthTalk在所有图像质量指标(PSNR, LPIPS, SSIM)和运动精度(LMD)上均优于对比方法,特别是与最强大的基线InsTaG相比,有显著提升。训练时间与InsTaG相当,但推理速度略低。
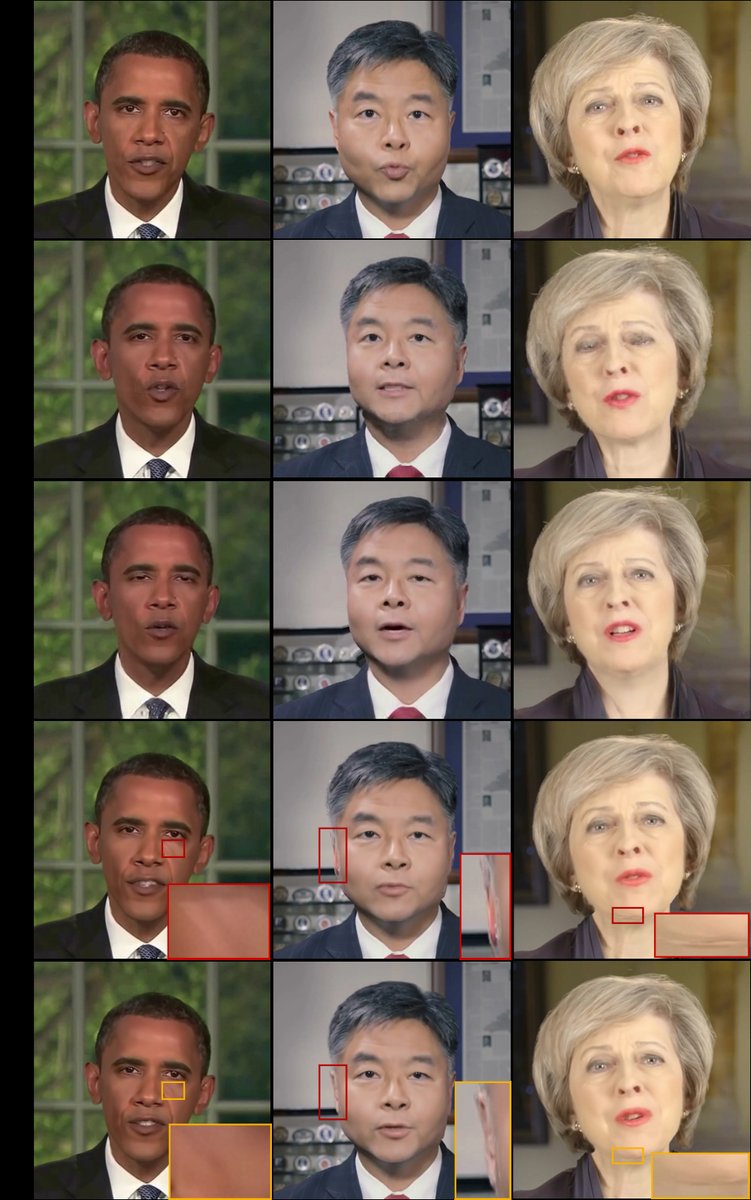 表2:DepthTalk消融研究(5秒训练数据)
表2:DepthTalk消融研究(5秒训练数据)
| DAGM | MF | DGL | PSNR↑ | LPIPS↓ | SSIM↑ |
|---|---|---|---|---|---|
| 29.3591 | 0.0566 | 0.9166 | |||
| ✓ | 29.1821 | 0.0566 | 0.9153 | ||
| ✓ | ✓ | 29.4862 | 0.0534 | 0.9197 | |
| ✓ | ✓ | ✓ | 29.8974 | 0.0530 | 0.9226 |
关键结论:单独加入DAGM(第一行)相比无组件基线(可能为InsTaG)PSNR略有下降,但加入MF和特别是DGL后,各项指标持续提升,证明三个组件的组合是必要且有效的。
定性结果(图3):展示了GeneFace、MimicTalk、InsTaG和DepthTalk在生成新视角头部时的结果。红框标出其他方法存在的光照错误和模糊伪影,黄框标出DepthTalk方法的改进。DepthTalk生成的图像在面部光照一致性、表面细节保留和视角变化时的鲁棒性上表现更好。
⚖️ 评分理由
- 学术质量:5.8/7:论文有明确的动机和创新点(DAGM双管道、DGL),技术方案合理,实验设计完整(包括对比和消融),结果有说服力。扣分在于创新属于现有框架(3DGS说话人生成)下的针对性改进,而非范式变革;且对深度先验模型Sapiens的依赖可能限制其普适性。
- 选题价值:1.2/2:解决少样本说话人生成中的深度模糊问题是一个具体且有价值的点,与虚拟现实、数字人等应用相关。但该任务本身相对细分,影响力受限。
- 开源与复现加成:0.0/1:论文中未提及代码、模型、数据的开源,也未提供足够的超参数和配置细节以确保独立复现,这是一个重大缺陷。