📄 Deepaq: A Perceptual Audio Quality Metric Based on Foundational Models and Weakly Supervised Learning
#音频质量评估 #弱监督学习 #度量学习 #音频大模型 #LoRA微调
✅ 7.5/10 | 前25% | #音频质量评估 | #弱监督学习 | #度量学习 #音频大模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Guanxin Jiang (International Audio Laboratories Erlangen†, Germany)
- 通讯作者:Andreas Brendel* (Fraunhofer Institute for Integrated Circuits IIS, Erlangen, Germany)
- 作者列表:Guanxin Jiang (International Audio Laboratories Erlangen†, Germany)、Andreas Brendel* (Fraunhofer Institute for Integrated Circuits IIS, Erlangen, Germany)、Pablo M. Delgado (Fraunhofer Institute for Integrated Circuits IIS, Erlangen, Germany)、Jürgen Herre (International Audio Laboratories Erlangen†, Germany; Fraunhofer Institute for Integrated Circuits IIS, Erlangen, Germany) (†注:International Audio Laboratories Erlangen是Friedrich-Alexander University Erlangen-Nürnberg (FAU)与Fraunhofer IIS的联合机构)
💡 毒舌点评
亮点:成功地将大规模音乐基础模型MERT“跨界”应用到质量评估任务,并证明了其在泛化到音源分离等未见过失真上的强大潜力,结果表明确实比ViSQOL、PEAQ等传统指标更接近人类感知。
短板:整个训练完全依赖非公开的内部音乐数据集,复现难度极高;虽然使用了弱监督标签,但核心标签仍来自ViSQOL,本质上是在“蒸馏”一个已有指标的判断,其能否真正超越“老师”在未见场景的极限存疑。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开的MERT微调权重或DeePAQ模型权重。
- 数据集:训练所用的460小时内部音乐数据集未公开。评估使用的测试集(如ODAQ, IgorC96Multiformat等)多为公开数据集。
- Demo:未提及。
- 复现材料:论文详细描述了模型架构(MERT v1, LoRA配置)、训练数据构成与预处理、损失函数公式、关键超参数(学习率、batch size、权重衰减等)。然而,由于核心训练数据闭源,这些信息的价值大打折扣。
- 引用的开源项目:论文引用了 MERT(预训练模型)、FFmpeg(音频编码)、ViSQOL v3(生成替代标签)、PEAQ(基线指标)、wav2vec 2.0(对比基础模型)等开源项目或工具。
📌 核心摘要
- 解决的问题:通用音频(涵盖音乐、语音等)的质量评估缺乏既精确又鲁棒的客观指标,尤其面对编码失真和音源分离失真时,现有方法(如ViSQOL, PEAQ)的表现各有短板。主观评测成本高昂,而基础模型在质量评估任务上的潜力尚未充分挖掘。
- 方法核心:提出DeePAQ,以预训练音乐基础模型MERT为骨干网络。通过弱监督学习方式,利用ViSQOL计算的MOS分数和编码码率作为替代标签构建排序三元组,采用改进的Rank-n-Contrast (RnC)损失函数对模型进行微调,使其学到的嵌入空间能有效反映音频的失真程度。为适应有限数据,采用了LoRA(低秩适配)技术进行高效微调。推理时,计算测试音频与参考音频嵌入的欧氏距离,并通过三次多项式映射得到预测分数。
- 与已有方法的新颖之处:首次将弱监督学习(替代标签)、度量学习(RnC损失) 和LoRA微调这三者相结合,并应用于基于音乐基础模型的通用音频质量评估。相比依赖手工特征或专用神经网络的传统指标(PEAQ等),以及简单微调基础模型的方法,该组合在数据稀缺下更有效、更稳定。
- 主要实验结果:在涵盖音频编码和音源分离的9个独立听测集上进行评估。所提的全参考模型在整体相关性上达到最优,PCC为0.924,SRCC为0.889,优于最强基线2f-model(0.924/0.889附近)和ViSQOL等。尤其在处理训练中未见的音源分离失真时,表现显著优于其他指标。具体结果见下表(关键数据节选):
| 测试集 | 指标 | ViSQOL v3 | 2f-model | HAAQI | 提出的全参考模型 |
|---|---|---|---|---|---|
| IgorC96Multiformat | PCC | 0.939 | 0.931 | 0.899 | 0.954 |
| SRCC | 0.863 | 0.872 | 0.807 | 0.848 | |
| ODAQ-Overall | PCC | 0.701 | 0.863 | 0.572 | 0.916 |
| SRCC | 0.763 | 0.814 | 0.548 | 0.868 | |
| Source Separation Overall | PCC | 0.646 | 0.953 | 0.883 | 0.919 |
| SRCC | 0.808 | 0.881 | 0.656 | 0.787 | |
| Overall (所有测试) | PCC | - | - | - | 0.924 |
| SRCC | - | - | - | 0.889 |
(注:表格整理自论文Table 1,数值已乘以1000还原。)
- 实际意义:提供了一种更接近人类感知、且泛化能力更强的音频质量自动评估工具,有望提升音频编解码器、音源分离算法等的开发与优化效率。
- 主要局限性:模型训练完全依赖非公开的内部数据集,外部研究者无法复现。对音源分离任务的评估显示,其相关性虽高但SRCC有所下降,且完全依赖一个“干净”的参考信号,实际应用中可能受限。
🏗️ 模型架构
DeePAQ的整体架构遵循“嵌入-距离-映射”的范式,具体流程如下:
 (架构图描述:左侧为训练阶段,右侧为推理阶段。训练阶段将音频三元组输入MERT,冻结CNN,微调Transformer(使用LoRA),通过投影头得到嵌入,计算RnC损失。推理阶段分别输入测试音频和参考音频,得到嵌入后计算欧氏距离,再通过映射函数得到主观分数。)
(架构图描述:左侧为训练阶段,右侧为推理阶段。训练阶段将音频三元组输入MERT,冻结CNN,微调Transformer(使用LoRA),通过投影头得到嵌入,计算RnC损失。推理阶段分别输入测试音频和参考音频,得到嵌入后计算欧氏距离,再通过映射函数得到主观分数。)
编码器(MERT Foundation Model):
- 组件:MERT v1 (95M参数)。
- 功能:将输入的原始音频波形(重采样至24kHz)编码为时序特征表示。
- 结构:包含一个卷积(CNN)特征提取器和12层Transformer编码器。论文中特别指出,其训练方式(自监督,结合声学教师和音乐教师)使其能捕获丰富的音乐语义信息。
- 处理:输入为4秒音频片段。经过MERT��,得到一个13×768维的时频特征矩阵。关键设计:对该矩阵在时间维度上进行平均,并展平为一个长度为9,984的一维向量,作为后续投影头的输入。此操作旨在融合时序信息,得到全局表征。
投影头(Projection Head):
- 组件:一个单层全连接神经网络。
- 结构:包含一个ReLU激活函数和一个线性层,将9,984维输入映射到256维的质量嵌入空间(Quality Embedding Space Z)。
- 功能:将MERT的高维通用音频特征,投影到一个专门优化的低维空间,在这个空间中,欧氏距离应能直接反映音频的感知质量差异。
训练策略(微调方式):
- LoRA适配:在Transformer的每个注意力模块的查询(Query)和值(Value)投影层中插入低秩(rank=8, scale factor=16)适配矩阵。训练时,冻结原始MERT的所有参数,仅更新这些新增的LoRA矩阵,参数量仅占总模型的2.93%。这是应对有限训练数据、防止过拟合的关键策略。
- 全量微调(对比实验):论文也测试了直接微调整个Transformer层,在大数据下效果与LoRA接近,但在小数据下易过拟合。
推理流程:
- 将测试音频和参考音频(全参考模式下为同一音频的干净版本)分别通过上述相同的编码器+投影头,得到两个256维嵌入向量
f(x_test)和f(x_ref)。 - 计算两个嵌入之间的欧氏距离
d = ||f(x_test) - f(x_ref)||_2。 - 将距离
d通过一个预训练好的三次多项式映射函数(或MLP)映射为最终的预测主观分数(如MOS)。这个映射函数是在验证集上训练得到的。
- 将测试音频和参考音频(全参考模式下为同一音频的干净版本)分别通过上述相同的编码器+投影头,得到两个256维嵌入向量
💡 核心创新点
- 首次将弱监督度量学习与LoRA微调结合用于音频质量评估:针对高质量标注数据稀缺的核心挑战,创新性地使用ViSQOL MOS分和编码码率作为替代标签(surrogate labels),结合RnC损失进行排序学习。同时,采用LoRA高效微调大型预训练模型,解决了小样本下的过拟合问题。此组合在方法论上具有新颖性。
- 将音乐基础模型MERT应用于通用质量评估:证明了专为音乐理解预训练的MERT,其表征空间在经过轻量级适配后,能有效迁移到感知质量评估这一全新任务,且在跨失真类型(从编码到分离)上展现出良好泛化能力。
- 统一的全参考与非匹配参考评估框架:提出了同一模型架构下的两种变体。全参考模型性能更强;非匹配参考模型(使用不同的干净信号作为参考)在编码失真评估上也优于传统指标,扩展了应用场景。
- 多源替代标签融合训练:在RnC损失中同时使用基于ViSQOL的排序和基于同编码器码率的排序,引导模型从多个维度学习质量特征,提升了模型的鲁棒性。
🔬 细节详述
- 训练数据:使用未公开的内部数据集。包含460小时CD质量音乐(44.1kHz),涵盖多种流派。使用FFmpeg编码为AAC, Opus, mp3三种格式,码率为16-128kbps。生成约122小时/编码器的编码音频和45小时干净音频。数据随机分割为训练集和验证集,训练与验证集的干净音频不重叠,但编码条件匹配。所有音频重采样至24kHz。
- 损失函数:主要使用Rank-n-Contrast (RnC)损失。该损失鼓励模型学习一个嵌入空间,使得在给定标签排序下,锚点样本与更接近的样本在嵌入空间中距离更近,与更远的样本距离更远。总体损失为所有样本的ViSQOL RnC损失与所有编码样本在各自码率标签上的RnC损失之和的平均(公式1&2)。
- 训练策略:
- 优化器:论文未明确说明,但给出了关键超参数。
- 学习率:全参考模型初始学习率为
1e-4,采用指数衰减(每10个停滞epoch衰减0.99)。非匹配参考模型为5e-5。 - Batch Size:32。
- 正则化:权重衰减
0.01,Dropout率0.05。 - LoRA配置:秩=8,缩放因子=16,应用于注意力层的Query和Value投影。
- 关键超参数:MERT输出特征维度13×768;投影头输出维度256;映射函数为三次多项式或三层MLP(ReLU, Sigmoid激活)。
- 训练硬件:未说明。
- 推理细节:直接使用编码器+投影头得到嵌入,计算距离后通过一次前向传播的映射函数得到分数。无复杂解码策略。
- 正则化技巧:主要依赖LoRA防止过拟合,并结合了Dropout和权重衰减。
📊 实验结果
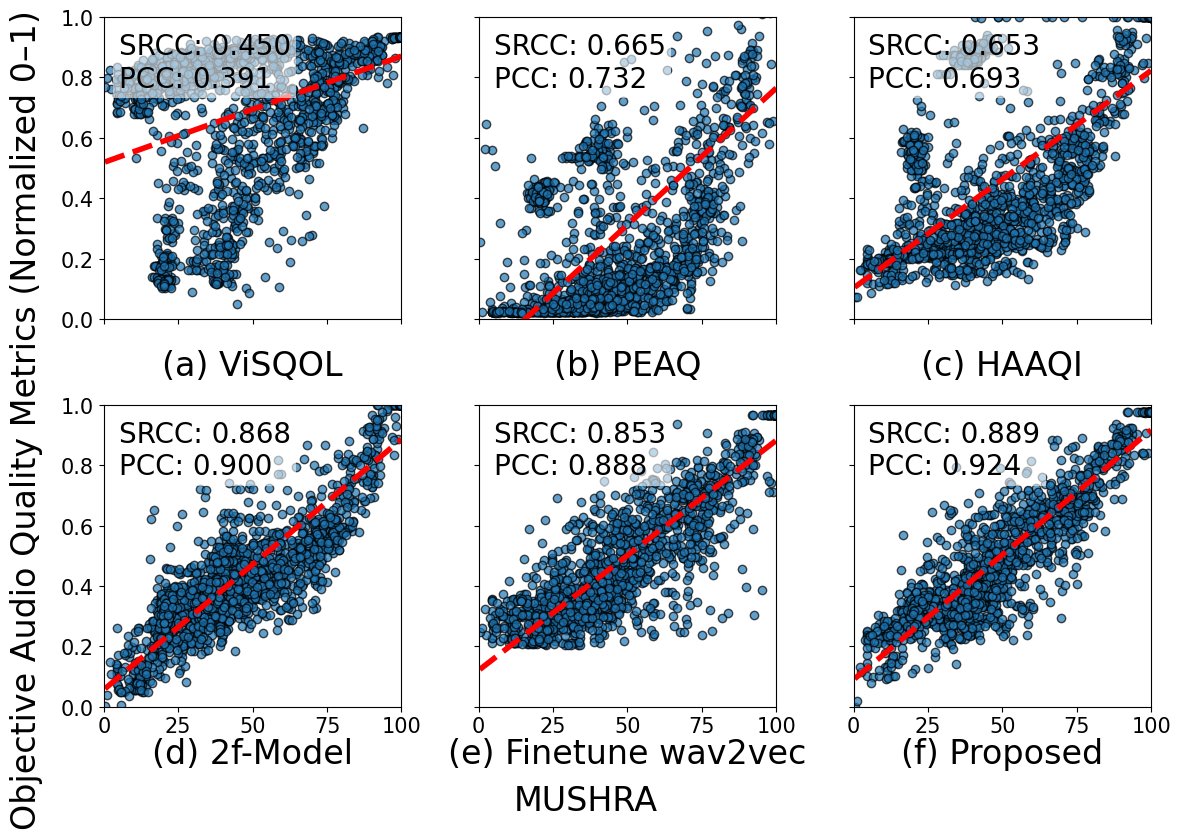
论文在9个听测集上进行了全面评估,覆盖音频编码和音源分离两大任务。核心对比指标是预测分数与主观分数的Pearson线性相关系数(PCC) 和Spearman秩相关系数(SRCC)。
 (散点图描述:展示了六个指标(ViSQOL, PEAQ, HAAQI, 2f-model, 微调wav2vec 2.0, 提出的方法)的预测分数与主观分数在所有测试样本上的散点图及线性回归拟合线。可以直观看出,提出的方法(子图f)的散点更紧密地聚集在拟合线周围,表明其预测更准确,线性关系更强。)
(散点图描述:展示了六个指标(ViSQOL, PEAQ, HAAQI, 2f-model, 微调wav2vec 2.0, 提出的方法)的预测分数与主观分数在所有测试样本上的散点图及线性回归拟合线。可以直观看出,提出的方法(子图f)的散点更紧密地聚集在拟合线周围,表明其预测更准确,线性关系更强。)
关键实验结果表格(节选自Table 1):
| 测试集 | 指标 | ViSQOL v3 | PEAQ-ODG | HAAQI | 2f-model | Fine-tune wav2vec 2.0 | 提出的全参考模型 |
|---|---|---|---|---|---|---|---|
| 音频编码 | |||||||
| IgorC96Multiformat | PCC | 0.939 | 0.767 | 0.899 | 0.931 | 0.870 | 0.954 |
| ODAQ-Overall | PCC | 0.701 | 0.811 | 0.572 | 0.863 | 0.889 | 0.916 |
| USAC t1-Overall | PCC | 0.893 | 0.801 | 0.433 | 0.857 | 0.804 | 0.900 |
| USAC t2-Overall | PCC | 0.835 | 0.801 | 0.303 | 0.755 | 0.785 | 0.875 |
| USAC t3-Overall | PCC | 0.863 | 0.871 | 0.515 | 0.884 | 0.818 | 0.928 |
| 音源分离 | |||||||
| Source Separation Overall | PCC | 0.646 | 0.911 | 0.883 | 0.953 | 0.898 | 0.919 |
| PEASS | PCC | 0.468 | 0.873 | 0.758 | 0.898 | 0.845 | 0.859 |
| SAOC DB | PCC | 0.813 | 0.925 | 0.907 | 0.962 | 0.917 | 0.934 |
| SASSEC | PCC | 0.787 | 0.906 | 0.857 | 0.956 | 0.889 | 0.920 |
| SiSEC08 | PCC | 0.784 | 0.924 | 0.920 | 0.948 | 0.927 | 0.948 |
(注:数值为PCC,已乘以1000。加粗为每行最优。)
消融实验结论:
- 训练策略:在MERT和wav2vec 2.0上,LoRA均表现最佳,尤其在数据有限时,它有效缓解了过拟合。
- 基础模型:微调wav2vec 2.0在语音相关任务上表现好,但在音乐和混合内容上明显弱于基于MERT的提出方法,证明了选择合适基础模型的重要性。
- 损失函数:加入基于码率的RnC损失项,带来了约1-3% 的性能提升。
- 映射函数:原始欧氏距离的SRCC通常高于PCC。使用三次多项式或MLP映射后,PCC大幅提升,SRCC基本不变,表明映射函数对于校正线性相关至关重要。
 (图表内容应与Table 1的数值对应,为不同测试集上的性能对比可视化。)
(图表内容应与Table 1的数值对应,为不同测试集上的性能对比可视化。)
⚖️ 评分理由
- 学术质量(6.0/7):技术路线新颖,将多个前沿技术(基础模型、弱监督度量学习、LoRA)有效整合解决实际问题。实验设计全面,对比充分,结果有说服力。主要扣分点在于训练数据的不透明性,这严重削弱了工作的可验证性和可复现性,是学术严谨性的重大缺陷。
- 选题价值(1.5/2):音频质量评估是重要的基础研究课题,本文提出了一个性能显著优于现有方法的解决方案,具有明确的实用价值和推动领域进步的潜力。分数未给满分是因为该任务相对垂直。
- 开源与复现加成(0.5/1):论文提供了详尽的模型结构、超参数和训练策略描述,为复现提供了重要线索。但致命的缺陷是未公开训练数据、代码和模型权重,导致外部研究者几乎无法完整复现其核心实验。因此,加成有限。