📄 Deep Spatial Clue Informed Ambisonic Encoding for Irregular Microphone Arrays
#空间音频 #麦克风阵列 #RNN #UNet
✅ 7.0/10 | 前25% | #空间音频 | #麦克风阵列 | #RNN #UNet
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Chaoqun Zhuang (三星中国研究院-北京)
- 通讯作者:未说明
- 作者列表:Chaoqun Zhuang (三星中国研究院-北京),Xue Wen (三星中国研究院-北京),Lin Ma (三星中国研究院-北京),Lizhong Wang (三星中国研究院-北京),Liang Wen (三星中国研究院-北京),Jaehyun Kim (三星电子移动体验业务部),Gangyoul Kim (三星电子移动体验业务部)
💡 毒舌点评
亮点:论文提出了一个清晰且合理的范式转变——将Ambisonic编码从传统的时频域混合转移到学习到的潜在特征空间,并通过实验证明了其在性能和效率上的优势。短板:目前的实验验证局限在一阶水平面Ambisonics上,且未能提供任何开源代码、模型或数据,极大地削弱了其在学术社区和工业界的可复现性与直接影响力,使其看起来更像一篇“闭源的工业报告”。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及。
- 数据集:论文中描述了数据生成流程(基于真实DIR测量和Pyroomacoustics模拟),但未提及公开数据集。
- Demo:未提及。
- 复现材料:提供了详细的网络架构描述、训练超参数(学习率、优化器、批量大小、训练轮数)、STFT设置等,但未提供完整的配置文件或检查点。
- 论文中引用的开源项目:依赖并提及了Pyroomacoustics用于房间混响模��。
- 总体而言,论文中未提及开源计划。
📌 核心摘要
- 问题:针对手机等设备上不规则麦克风阵列进行Ambisonic编码时,由于空间混叠和声场覆盖有限,传统方法和现有深度学习方法存在性能瓶颈。
- 方法:提出了一种端到端的“深度空间线索引导的Ambisonic编码器”。其核心是设计了“空间感知潜在变换(SALT)”模块,该模块首先通过双路径(空间线索编码器和频谱编码器)从输入信号中提取特征并融合,然后在一个学习到的潜在特征空间中,预测一个信号依赖的混合矩阵来完成到Ambisonic域的映射,最后解码回STFT域。
- 创新:与已有方法相比,新在:1)首次引入了潜在空间变换范式,摆脱了在固定STFT分辨率上操作的限制;2)显式融合了IPD/ILD等空间线索,为模型提供物理一致性指导。
- 实验结果:在基于真实智能手机麦克风阵列DIR测量数据构建的多源混响场景数据集上,该方法(特别是RNN(Full)变体)在空间相似性(Mdir)、频谱误差(Meq)和SI-SDR指标上全面优于最小二乘法(LS)和基线神经网络方法(UNet Base, RNN Base),同时参数量更少。关键数据见下表:
| 模型 | 单声源 Mdir(↑) / Meq(↓) / SI-SDR(↑) | 多声源 Mdir(↑) / Meq(↓) / SI-SDR(↑) | 多声源+混响 Mdir(↑) / Meq(↓) / SI-SDR(↑) | 可训练参数 (M) | FLOPS (G) |
|---|---|---|---|---|---|
| LS | 0.866 / 3.905 / 3.967 | 0.876 / 3.727 / 5.939 | 0.752 / 5.368 / 0.471 | N/A | N/A |
| UNet(Base) | 0.967 / 2.379 / 10.206 | 0.947 / 2.637 / 7.742 | 0.782 / 10.932 / 2.192 | 1.93M | 27.678 |
| UNet(Full) | 0.742 / 2.295 / 23.075 | 0.938 / 1.648 / 19.521 | 0.795 / 8.982 / 2.557 | 2.15M | 14.089 |
| RNN(Base) | 0.902 / 20.230 / 6.280 | 0.914 / 24.983 / 7.573 | 0.716 / 11.697 / 0.755 | 0.65M | 36.273 |
| RNN(Full) | 0.927 / 1.709 / 31.570 | 0.938 / 1.467 / 21.492 | 0.821 / 9.260 / 2.676 | 0.74M | 13.060 |
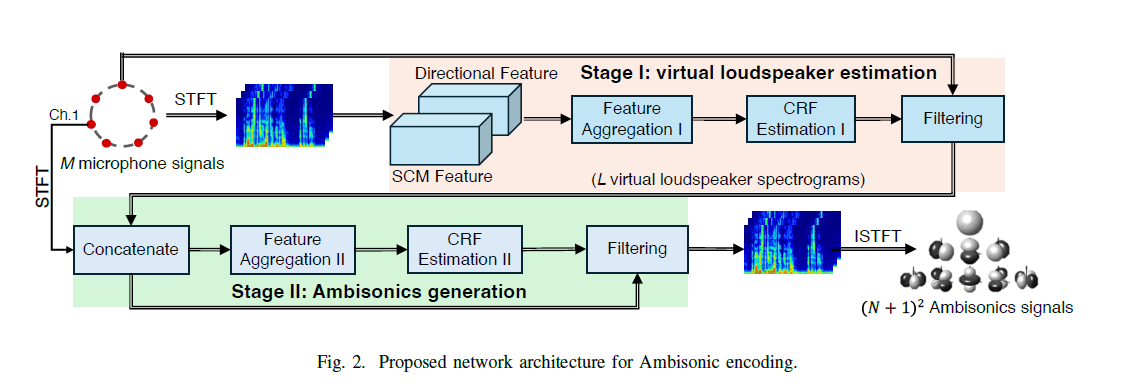 图1展示了整体框架:输入多通道麦克风信号,分别经过“空间线索编码器”(处理IPD/ILD)和“频谱编码器”(处理STFT),提取特征后融合,由SALT模块估计潜在混合矩阵并完成变换,最后通过解码器输出Ambisonic信号。
5. 实际意义:为移动设备等受尺寸和功耗限制的平台实现高质量空间音频捕获提供了可行的、高效的解决方案。
6. 主要局限性:当前实验仅验证了使用三个麦克风的二阶一阶Ambisonics(W, X, Y),未涉及更高阶或完整三维编码;此外,未提供开源实现。
图1展示了整体框架:输入多通道麦克风信号,分别经过“空间线索编码器”(处理IPD/ILD)和“频谱编码器”(处理STFT),提取特征后融合,由SALT模块估计潜在混合矩阵并完成变换,最后通过解码器输出Ambisonic信号。
5. 实际意义:为移动设备等受尺寸和功耗限制的平台实现高质量空间音频捕获提供了可行的、高效的解决方案。
6. 主要局限性:当前实验仅验证了使用三个麦克风的二阶一阶Ambisonics(W, X, Y),未涉及更高阶或完整三维编码;此外,未提供开源实现。
🏗️ 模型架构
模型架构如图1所示,是一个端到端的系统,包含以下核心组件与数据流:
- 输入:来自不规则麦克风阵列的时域信号,经STFT变换得到复数谱
x(t, f)。 - 双路径特征提取(Stage I: Dual-path Adaptive Representation Extraction):
- 空间线索编码器(Spatial Clue Encoder):首先计算所有麦克风对之间的IPD和ILD。IPD归一化至[-1,1],ILD计算后截断归一化至[0,1]。这些显式空间线索被送入一个由BatchNorm2D、Conv2D和ReLU构成的CNN,提取出高维空间特征
fclue。 - 频谱编码器(Spectral Encoder):将多通道复数STFT系数
x(t, f)直接输入另一个CNN,提取深度频谱特征fdeep。该特征包含信号的时频特性以及隐含的空间信息。
- 空间线索编码器(Spatial Clue Encoder):首先计算所有麦克风对之间的IPD和ILD。IPD归一化至[-1,1],ILD计算后截断归一化至[0,1]。这些显式空间线索被送入一个由BatchNorm2D、Conv2D和ReLU构成的CNN,提取出高维空间特征
- 特征融合:将
fclue和fdeep在通道维度上拼接,得到融合特征fmixed。 - 空间感知潜在变换(Stage II: Spatial-Aware Latent Transform, SALT):这是论文的核心创新。一个深度网络(论文中实例化为UNet或DPRNN)基于融合特征
fmixed预测一个潜在的混合矩阵Mlatent。然后,在潜在特征空间中,用该矩阵对fdeep进行线性变换:b_feature = Mlatent * fdeep。这相当于在学习到的、更具表现力的特征空间中完成了从麦克风信号到Ambisonic表示的映射,突破了在浅层STFT域操作的限制。 - 解码器(Decoder):将潜在的Ambisonic表示
b_feature通过一个轻量级的解码器(每子带一个线性层)映射回STFT域,得到最终的Ambisonic编码输出b_hat(t, f)。
关键设计选择:采用双路径分别处理显式空间线索和原始频谱,旨在让模型同时从物理几何约束和信号本身中学习;将变换置于潜在空间是范式核心,动机是潜在特征能更自适应地捕获不规则阵列的复杂空间响应。
💡 核心创新点
- 特征空间变换范式:首次提出将Ambisonic编码从固定的STFT时频域变换转移到一个学习到的、非线性的潜在特征空间中进行。这克服了传统线性映射和浅层谱图混合的表达能力限制。
- 显式空间线索融合:明确地将IPD/ILD等物理空间线索编码并融合到深度特征中,为数据驱动的模型提供了重要的几何先验,增强了其在不规则阵列和噪声环境下的鲁棒性和物理一致性。
- 基于真实设备数据的实证验证:研究并非仅使用合成数据,而是利用了从商用智能手机麦克风阵列在消声室中实际测量的定向脉冲响应(DIR)来构建训练和评估数据集,增强了结论的实用性和可信度。
- 高效的网络设计:通过潜在空间变换和合适的架构选择(如DPRNN),在达到或超越更大模型(如基线UNet)性能的同时,显著降低了参数量和计算量(FLOPS),更贴近移动端部署需求。
🔬 细节详述
- 训练数据:数据基于真实测量的DIR和房间模拟生成。使用商用智能手机(3个麦克风)在消声室测量DIR。然后使用Pyroomacoustics中的图像源法模拟随机房间、声源位置和麦克风位置,生成包含单源、多源(1-3个)及混响的声场。声源信号来自DNS数据集。总共生成20,000个4秒的3通道Mixtures及其对应的一阶Ambisonic(W, X, Y)真值。按80/10/10划分训练、验证、测试集。
- 损失函数:采用SI-SDR(尺度不变信号失真比)损失,这是一种常用于音频分离和增强任务的时域损失函数。
- 训练策略:使用Adam优化器,学习率
lr=1e-4,批量大小batch_size=32。训练100个epoch,采用早停法(patience=10)。所有实验用3个随机种子重复,以报告平均结果。 - 关键超参数:
- 音频采样率:24 kHz。
- STFT参数:FFT长度1024,帧移512,汉宁窗。
- 频域处理:实部和虚部拼接,得到1026个频点,进一步分成5个子带进行处理。
- 模型架构:频谱编码器和空间线索编码器均为CNN;解码器为每子带一个线性层。SALT模块分别用UNet和DPRNN(5个块,隐藏维度64)实现。
- 训练硬件:论文中未说明。
- 推理细节:采用与训练相同的STFT/iSTFT设置。解码过程直接通过解码器网络完成。
- 正则化技巧:空间线索编码器中使用了BatchNorm2D。
📊 实验结果
论文在三个场景(单声源、多声源、多声源+混响)下评估了模型,使用了三个指标:空间相似性Mdir(越高越好)、频谱误差Meq(越低越好)、SI-SDR(越高越好)。主要对比与消融结果见下表:
表1. 不同Ambisonic编码方法及消融设置的对比
| 模型 | 单声源 | 多声源 | 多声源+混响 |
|---|---|---|---|
| Mdir(↑) / Meq(↓) / SI-SDR(↑) | Mdir(↑) / Meq(↓) / SI-SDR(↑) | Mdir(↑) / Meq(↓) / SI-SDR(↑) | |
| LS | 0.866 / 3.905 / 3.967 | 0.876 / 3.727 / 5.939 | 0.752 / 5.368 / 0.471 |
| UNet(Base) | 0.967 / 2.379 / 10.206 | 0.947 / 2.637 / 7.742 | 0.782 / 10.932 / 2.192 |
| UNet+SC | 0.969 / 2.695 / 9.241 | 0.966 / 3.650 / 7.753 | 0.787 / 7.976 / 2.038 |
| UNet+LT | 0.928 / 1.740 / 30.580 | 0.939 / 1.596 / 19.317 | 0.790 / 9.901 / 2.536 |
| UNet(Full) | 0.742 / 2.295 / 23.075 | 0.938 / 1.648 / 19.521 | 0.795 / 8.982 / 2.557 |
| RNN(Base) | 0.902 / 20.230 / 6.280 | 0.914 / 24.983 / 7.573 | 0.716 / 11.697 / 0.755 |
| RNN+SC | 0.912 / 9.366 / 4.316 | 0.920 / 8.968 / 7.306 | 0.744 / 13.290 / 1.448 |
| RNN+LT | 0.927 / 1.682 / 27.708 | 0.937 / 1.521 / 20.369 | 0.811 / 8.463 / 2.603 |
| RNN(Full) | 0.927 / 1.709 / 31.570 | 0.938 / 1.467 / 21.492 | 0.821 / 9.260 / 2.676 |
关键结论:
- 整体性能:所提的Full模型(结合潜在变换LT和空间线索SC)在所有场景和指标上均优于LS和Base模型。特别是在最具挑战性的“多声源+混响”场景中,RNN(Full)达到了最高的
Mdir(0.821)和SI-SDR(2.676),同时Meq也较低。 - 消融分析:
- 添加空间线索(+SC)主要提升空间方向性
Mdir。 - 添加潜在空间变换(+LT)主要大幅提升信号重建质量
SI-SDR和降低频谱误差Meq。 - 两者结合(Full)能取得最佳的综合性能。
- 添加空间线索(+SC)主要提升空间方向性
- 架构对比:在低混响和少源场景,UNet变体在
Mdir上略占优(如UNet+SC在单声源达0.969);而在混响多源条件下,DPRNN变体(RNN(Full))表现更优,更鲁棒。 - 效率:表2 显示了模型的参数量和计算量。RNN(Full)模型仅需0.74M参数和13.06 GFLOPS,显著低于性能相当的UNet(Full)(2.15M参数,14.09 GFLOPS),也远低于RNN(Base)的高计算量(36.27 GFLOPS),展示了极佳的参数效率。
表2. 估算的模型大小与计算量
| 模型 | 可训练参数(M) | FLOPS (G) |
|---|---|---|
| UNet(Base) | 1.93M | 27.678 |
| UNet(Full) | 2.15M | 14.089 |
| RNN(Base) | 0.65M | 36.273 |
| RNN(Full) | 0.74M | 13.060 |
⚖️ 评分理由
- 学术质量:6.0/7:论文提出了一个完整且逻辑自洽的研究框架,创新点明确(潜在空间变换、空间线索融合),实验设计周密(真实数据、多场景、多指标、消融、效率对比),技术实现和结果分析严谨。但创新主要在于集成与框架设计,而非某个算法模块的原创性突破,且评估范围(一阶水平面)相对受限。
- 选题价值:1.5/2:解决移动设备空间音频采集的实际工程痛点,课题具体、实用性强,对VR/AR、沉浸式通信等领域有直接应用价值。属于当前音频处理中活跃且重要的研究方向。
- 开源与复现加成:-0.5/1:论文未提及任何代码、预训练模型、完整数据集或可运行的Demo。虽然文中提供了详细的网络配置和训练参数,但这远不足以让同行便捷地复现其工作,这是一大缺陷。