📄 Deep Dubbing: End-to-End Auto-Audiobook System with Text-to-Timbre and Context-Aware Instruct-TTS
#语音合成 #流匹配 #端到端 #有声书生成
✅ 7.5/10 | 前25% | #语音合成 | #流匹配 | #端到端 #有声书生成
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Ziqi Dai(北京建筑大学智能科学与技术学院,腾讯音乐娱乐Lyra实验室)†
- 通讯作者:Weifeng Zhao(腾讯音乐娱乐Lyra实验室)⋆, Ruohua Zhou(北京建筑大学智能科学与技术学院)⋆
- 作者列表:
- Ziqi Dai†(北京建筑大学智能科学与技术学院,腾讯音乐娱乐Lyra实验室)
- Yiting Chen†(腾讯音乐娱乐Lyra实验室)
- Jiacheng Xu(腾讯音乐娱乐Lyra实验室)
- Liufei Xie(腾讯音乐娱乐Lyra实验室)
- Yuchen Wang(腾讯音乐娱乐Lyra实验室)
- Zhenchuan Yang(腾讯音乐娱乐Lyra实验室)
- Bingsong Bai(北京邮电大学)
- Yangsheng Gao(腾讯音乐娱乐Lyra实验室)
- Wenjiang Zhou(腾讯音乐娱乐Lyra实验室)
- Weifeng Zhao⋆(腾讯音乐娱乐Lyra实验室)
- Ruohua Zhou⋆(北京建筑大学智能科学与技术学院)
💡 毒舌点评
亮点:该工作将“为角色从文本生成声音”和“根据上下文生成情感语音”这两个有声书制作的关键环节进行了系统性建模,并提出了Text-to-Timbre (TTT) 这一新颖任务及其流匹配解决方案。短板:其“端到端”的声明略显模糊,因为核心的上下文理解与指令生成依赖于一个外部的大语言模型,这限制了系统真正的自动化程度和独立性。
🔗 开源详情
- 代码:提供了GitHub仓库链接(https://github.com/TME-Lyra-Lab/DeepDubbing)。
- 模型权重:论文中未提及公开模型权重。
- 数据集:宣布将发布BookVoice-50h合成数据集(用于TTT和CA-Instruct-TTS任务)至Hugging Face。
- Demo:提供了在线演示页面(https://tme-lyra-lab.github.io/DeepDubbing)。
- 复现材料:论文提供了部分模型架构细节、超参数设置(如TTT的DiT层数、隐藏维度等)。但未提供完整的训练配置、检查点、或LLM指令生成的详细代码/模板。
- 论文中引用的开源项目:CosyVoice [1,2], F5-TTS [3], DreamVoice [4], NANSY++ [5], Qwen3-Embedding [3.1.2节提及], Cam++ [24], Whisper [26], BigVGAN [22]。
📌 核心摘要
- 问题:自动化多角色有声书生成面临两大挑战:如何从文本描述自动获取匹配角色的声音音色,以及如何根据叙事上下文生成情感表达丰富、语调自然的语音。
- 方法核心:提出DeepDubbing系统,包含两个核心模型:(1) 基于条件流匹配的Text-to-Timbre (TTT)模型,从结构化文本(如“中年男性,将军,霸气”)生成说话人音色嵌入;(2) 上下文感知指令TTS (CA-Instruct-TTS)模型,该模型以音色嵌入、目标文本和由LLM生成的情感场景指令为输入,合成表达性语音。
- 创新点:首次系统化解决有声书中“文本到音色”映射问题;将细粒度情感场景指令融入TTS过程,提升语境适应性;发布支持这两个新任务的合成数据集BookVoice-50h。
- 主要实验结果:在内部大规模数据集上,TTT-Qwen3-0.6B编码器在性别、年龄准确率和角色匹配度(CMS)上均优于T5和Roberta变体(表2)。CA-Instruct-TTS在自然度(MOS-N: 3.33 vs 3.10)和情感表达(MOS-E: 4.15 vs 3.67)上优于无指令基线(表3),同时保持相近的词错误率(WER: 2.54% vs 2.39%)。
表2: TTT模型在不同年龄段的性能比较
方法 性别准确率(%)↑ 年龄准确率(%)↑ 角色匹配度(CMS)↑ TTT-T5-Large 儿童90.00, 青年98.75, 中年99.38, 老年98.75 儿童23.13, 青年77.50, 中年57.50, 老年46.88 2.38±0.04 TTT-Roberta-Large 儿童98.13, 青年95.63, 中年100.00, 老年100.00 儿童16.25, 青年77.50, 中年75.63, 老年69.38 2.36±0.04 TTT-Qwen3-0.6B 儿童96.25, 青年100.00, 中年100.00, 老年100.00 儿童74.38, 青年74.38, 中年90.00, 老年73.13 2.87±0.04 表3: CA-Instruct-TTS与基线的主观客观评分比较 方法 WER↓ MOS-N↑ (自然度) MOS-E↑ (情感) :— :— :— :— CA-TTS (基线) 2.39% 3.10±0.05 3.67±0.07 CA-Instruct-TTS 2.54% 3.33±0.05 4.15±0.08 - 实际意义:为有声书、广播剧等音频内容的工业化、自动化生产提供了可行的技术方案,有望大幅降低制作成本和时间。
- 主要局限性:TTT模型在儿童声音(尤其是性别区分)生成上表现不佳,受训练数据中真实儿童语音稀缺的限制;系统依赖外部LLM生成指令,增加了复杂性和不确定性;缺乏与当前最先进TTS系统在开放域对话或情感表达上的直接对比。
🏗️ 模型架构
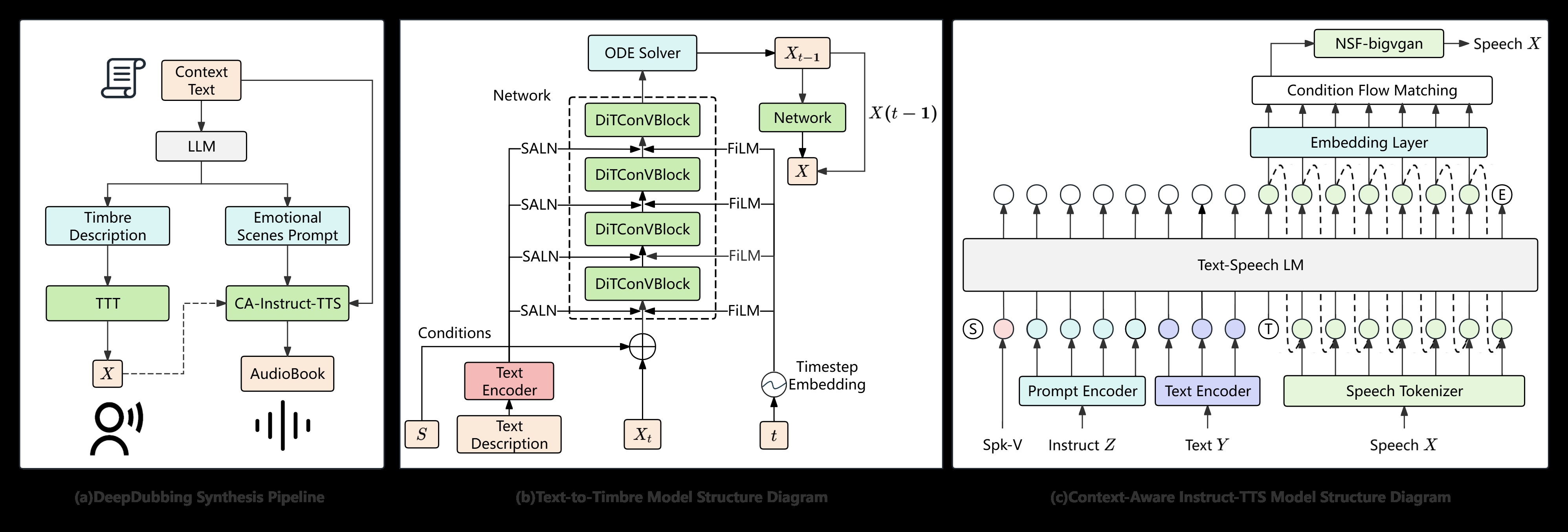
DeepDubbing系统是一个两阶段的自动化流水线(如图1(a)所示):
- 角色音色生成阶段:整个书籍文本由LLM处理,识别所有角色并为每个角色生成结构化的音色描述文本。该文本输入TTT模型,生成对应的说话人音色嵌入向量。
- 情感语音合成阶段:同一LLM分析叙述上下文,为每个对话片段生成“情感|场景”格式的指令文本。CA-Instruct-TTS模型接收三个输入:生成的音色嵌入、当前句子文本、情感场景指令,最终合成表达性语音。
Text-to-Timbre (TTT) 模型架构(如图1(b)所示):
- 核心框架:基于最优传输条件流匹配(OT-CFM)。
- 网络结构:采用一个4层的Diffusion Transformer (DiT)骨干网络。
- 条件注入:
- 文本描述由Qwen3-Embedding-0.6B编码,通过Style-Adaptive Layer Normalization (SALN)注入到DiT的每个块中。
- 时间步信息通过Feature-wise Linear Modulation (FiLM)注入。
- 性别标签通过拼接方式与带噪音色嵌入和文本嵌入一起作为网络输入。
- 训练:网络学习预测从带噪状态
xt到目标音色嵌入x1的速度场ut。训练损失为预测速度与真实速度的均方误差(公式3)。 - 推理:从随机高斯噪声开始,通过Euler求解器(公式4)积分学到的速度场,生成匹配文本描述的音色嵌入。
Context-Aware Instruct-TTS (CA-Instruct-TTS) 模型架构(如图1(c)所示):
- 灵感来源:CosyVoice架构。
- 三个核心组件:
- 文本到声学单元的LLM:一个12层的Transformer语言模型。输入是拼接的四种模态信息(公式5):音色嵌入(
Espk)、指令令牌(Tinstruct)、目标文本令牌(Ttext)和语音声学单元(Tspeech)。该模型从QinYu基座模型持续训练而来。 - 声学单元到梅尔频谱的流匹配模型:使用一个DiT网络,将LLM输出的声学单元序列映射为梅尔频谱图。其条件包括音色嵌入、声学单元序列和被掩码的声学特征。
- 梅尔频谱到波形的声码器:采用NSF-BigVGAN模型,将梅尔频谱转换为高质量波形。
- 文本到声学单元的LLM:一个12层的Transformer语言模型。输入是拼接的四种模态信息(公式5):音色嵌入(
💡 核心创新点
- 提出Text-to-Timbre (TTT) 任务与模型:首次系统化地研究如何从自然语言描述自动生成匹配角色的说话人音色嵌入。与基于扩散的DreamVoice或依赖属性标量的NANSY++相比,TTT使用条件流匹配,结合多尺度文本条件和显式性别控制,能更灵活、可控地从文本生成音色。
- 开发上下文感知指令TTS (CA-Instruct-TTS):创新性地引入由LLM从叙事上下文中提取的“情感|场景”细粒度指令,作为TTS的条件。与TACA-TTS或JELLY相比,该方法提供了更显式、更结构化的场景语义指导,使合成的语音在情感和语调上更贴合复杂对话语境,有效缓解了上下文碎片化问题。
- 构建并发布BookVoice-50h数据集:这是一个支持TTT和CA-Instruct-TTS两项新任务的合成数据集,提供了结构化的音色描述和情感场景指令模板,为相关研究提供了宝贵的基准资源。
🔬 细节详述
- 训练数据:
- 主模型训练数据:一个大型内部多参与者有声书数据集,包含超过4000小时的高质量语音。通过自动化LLM标注流程生成超过30万条TTT音色描述(遵循
性别|年龄|性格|身份模板)和超过200万条CA-Instruct-TTS指令(遵循情感|上下文场景模板,覆盖44种细粒度情感)。使用Cam++模型提取每个语音片段的说话人嵌入作为训练目标。测试集使用未见说话人身份。 - 公开数据集:发布BookVoice-50h合成数据集,用于支持TTT和CA-Instruct-TTS任务。
- 主模型训练数据:一个大型内部多参与者有声书数据集,包含超过4000小时的高质量语音。通过自动化LLM标注流程生成超过30万条TTT音色描述(遵循
- 损失函数:
- TTT模型:均方误差(MSE)损失,用于回归真实速度向量
ut(公式3)。 - CA-Instruct-TTS模型:论文未详细说明LLM和流匹配部分的具体损失函数,推测为自回归语言模型损失(如交叉熵)和流匹配的MSE损失。
- TTT模型:均方误差(MSE)损失,用于回归真实速度向量
- 训练策略:
- TTT模型:应用分类器无关引导(CFG),条件丢弃率为0.2。
- CA-Instruct-TTS模型:LLM组件基于QinYu内部模型持续训练。未说明具体优化器、学习率等细节。
- 关键超参数:
- TTT模型:4层DiT,4个注意力头,392维隐藏维度。文本编码器为Qwen3-Embedding-0.6B,投影到192维。推理时CFG scale为3.0,rescale factor为0.7。
- CA-Instruct-TTS模型:LLM为12层Transformer。流匹配和声码器的具体维度未说明。
- 训练硬件:论文中未提及。
- 推理细节:
- TTT模型:使用Euler求解器进行数值积分(公式4),从
t=0积分到t=1。 - CA-Instruct-TTS模型:LLM自回归生成声学单元,流匹配模型生成梅尔频谱,声码器最终合成波形。未说明具体的解码策略(如温度、beam size)。
- TTT模型:使用Euler求解器进行数值积分(公式4),从
- 正则化或稳定训练技巧:TTT模型中使用了分类器无关引导(CFG)和条件丢弃,这既是条件注入方式也是训练稳定技巧。
📊 实验结果
主要评估指标与结果:
TTT模型评估(表2):使用生成的音色嵌入合成语音后,由专家评估。指标包括性别准确率(SA)、年龄准确率(AA)和角色匹配度(CMS, 0-4分)。结果表明,采用Qwen3-0.6B作为文本编码器的TTT模型在几乎所有指标上均优于基于T5和Roberta的变体,尤其在年龄准确率和CMS上优势明显。但儿童声音的性别分类准确率(96.25%)显著低于其他年龄段。
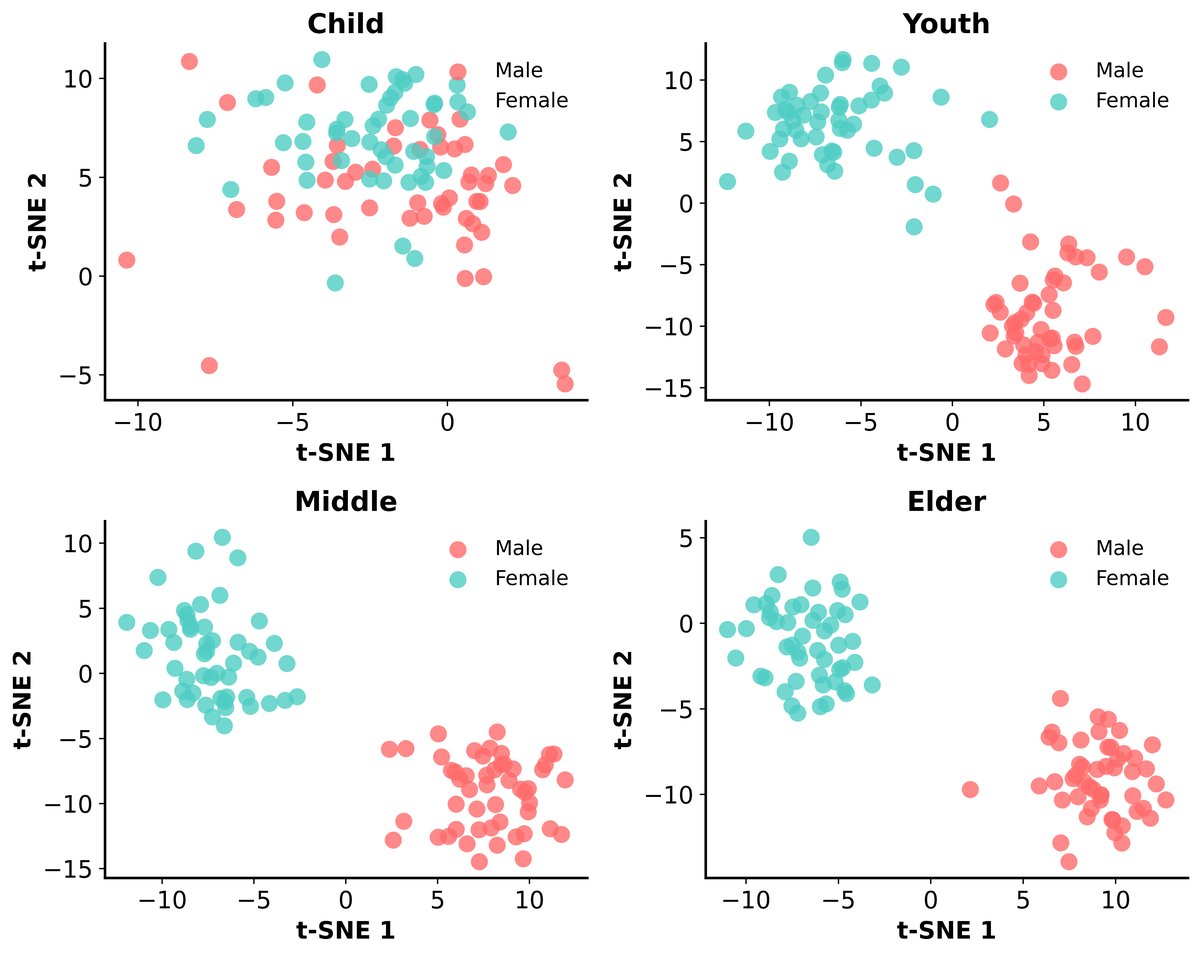 图2的t-SNE可视化展示了不同年龄段说话人嵌入的性别聚类情况。论文指出,儿童组别的性别区分度较差,这与表2中较低的儿童性别准确率一致,并归因于儿童声音声学相似性高以及训练数据中存在成人模仿童声。
图2的t-SNE可视化展示了不同年龄段说话人嵌入的性别聚类情况。论文指出,儿童组别的性别区分度较差,这与表2中较低的儿童性别准确率一致,并归因于儿童声音声学相似性高以及训练数据中存在成人模仿童声。CA-Instruct-TTS模型评估(表3):合成195个覆盖44种情感的语句,由专家评估自然度(MOS-N)和情感表达(MOS-E),同时计算Whisper-large-v3的词错误率(WER)。与无指令基线(CA-TTS)相比,CA-Instruct-TTS在保持相近WER(2.54% vs 2.39%)的同时,自然度(3.33 vs 3.10)和情感表达(4.15 vs 3.67)均有显著提升,证明了上下文指令的有效性。
缺失对比:论文未将CA-Instruct-TTS与当前公开的最先进端到端TTS系统(如CosyVoice 2、F5-TTS)在相同有声书测试集上进行直接对比。实验主要与自身基线(无指令版本)和消融版本(不同文本编码器)进行比较。
⚖️ 评分理由
- 学术质量:6.5/7。工作具有明确的动机和系统性创新(TTT任务、CA-Instruct-TTS指令机制),技术路线(流匹配)选取得当,架构设计完整。实验在内部数据集上充分,有消融研究,结果分析深入(如儿童声音问题)。主要不足是实验对比的广度和深度有限,缺乏与当前业界/学术界最强系统的直接较量,部分实现细节(如LLM指令生成模块)未公开。
- 选题价值:2.0/2。有声书自动化生成是语音合成领域一个重要且需求迫切的应用方向,本工作直击该场景下的核心痛点,提出的解决方案具有很高的实用价值和产业落地潜力。
- 开源与复现加成:-0.5/1。正面:提供了代码仓库链接(GitHub)、发布了合成数据集(BookVoice-50h)。负面:核心模型权重、用于训练的主数据集(4000小时)、以及最关键的上下文指令生成所用的LLM及其���示词工程未公开,使得外部研究者难以完全复现其系统,只能复现其公开的部分组件。