📄 DDSR-Net: Robust Multimodal Sentiment Analysis via Dynamic Modality Reliability Assessment
#语音情感识别 #多模态模型 #对比学习 #特征分解
✅ 6.5/10 | 前50% | #语音情感识别 | #对比学习 | #多模态模型 #特征分解
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Jianwen Hou (新疆大学计算机科学与技术学院)
- 通讯作者:Kurban Ubul (新疆大学计算机科学与技术学院)
- 作者列表:Jianwen Hou (新疆大学计算机科学与技术学院), Enguang Zuo (新疆大学智能科学与技术学院, 清华大学电子工程系), Chaorui Shi (新疆大学计算机科学与技术学院), Kurban Ubul (新疆大学计算机科学与技术学院)
💡 毒舌点评
该论文的“评估-修复-聚焦”闭环设计思路巧妙,为处理多模态数据中的质量不均衡问题提供了一个系统性框架,且在主流基准测试上取得了不错的成绩。然而,其核心组件之一“协同重建”的生成器(QGME-Net)内部结构细节在正文和附图中均未清晰展示,这为理解其工作原理和复现带来了障碍。
🔗 开源详情
- 代码:论文中未提及代码链接或开源仓库。
- 模型权重:未提及公开权重。
- 数据集:使用公开的CMU-MOSI和CMU-MOSEI数据集,但未说明具体获取方式或预处理脚本。
- Demo:未提供在线演示。
- 复现材料:论文未提供训练细节(如优化器、学习率、batch size)、超参数配置、检查点或附录说明。
- 论文中引用的开源项目:论文中引用了多个基线模型(如TFN, MulT, Self-MM等)的官方代码仓库([6]-[22]),但未明确说明DDSR-Net���身是否基于或依赖这些项目。
- 总结:论文中未提及任何关于开源计划、代码发布或模型共享的信息。
📌 核心摘要
这篇论文旨在解决多模态情感分析中,现实场景下非对齐数据存在的模态质量动态不均和噪声问题。其核心方法DDSR-Net提出了一种“动态质量感知”的框架,包含四个主要模块:模态质量评估模块(为每个样本的每个模态计算可靠性分数)、特征分解模块(将特征分解为共享和模态特定部分)、协同重建模块(利用高质量模态信息修复低质量模态的特定特征)以及动态聚焦注意力模块(根据质量分数自适应融合特征)。该方法通过“评估-修复-聚焦”的闭环流程,动态处理噪声和不对称性。实验结果在CMU-MOSI和CMU-MOSEI两个基准数据集上,DDSR-Net在多数指标(如MOSI的MAE、Corr、Acc-5)上超越了已有的最先进方法。其实际意义在于提升了多模态情感分析模型在非理想数据下的鲁棒性。主要局限性在于协同重建模块的具体生成器架构描述不够详细,可能影响理解和复现。
DDSR-Net的整体架构如图1所示,是一个端到端的多阶段处理框架,输入为文本(T)、音频(A)、视觉(V)三种模态的非对齐特征序列,最终输出一个连续的情感预测值。
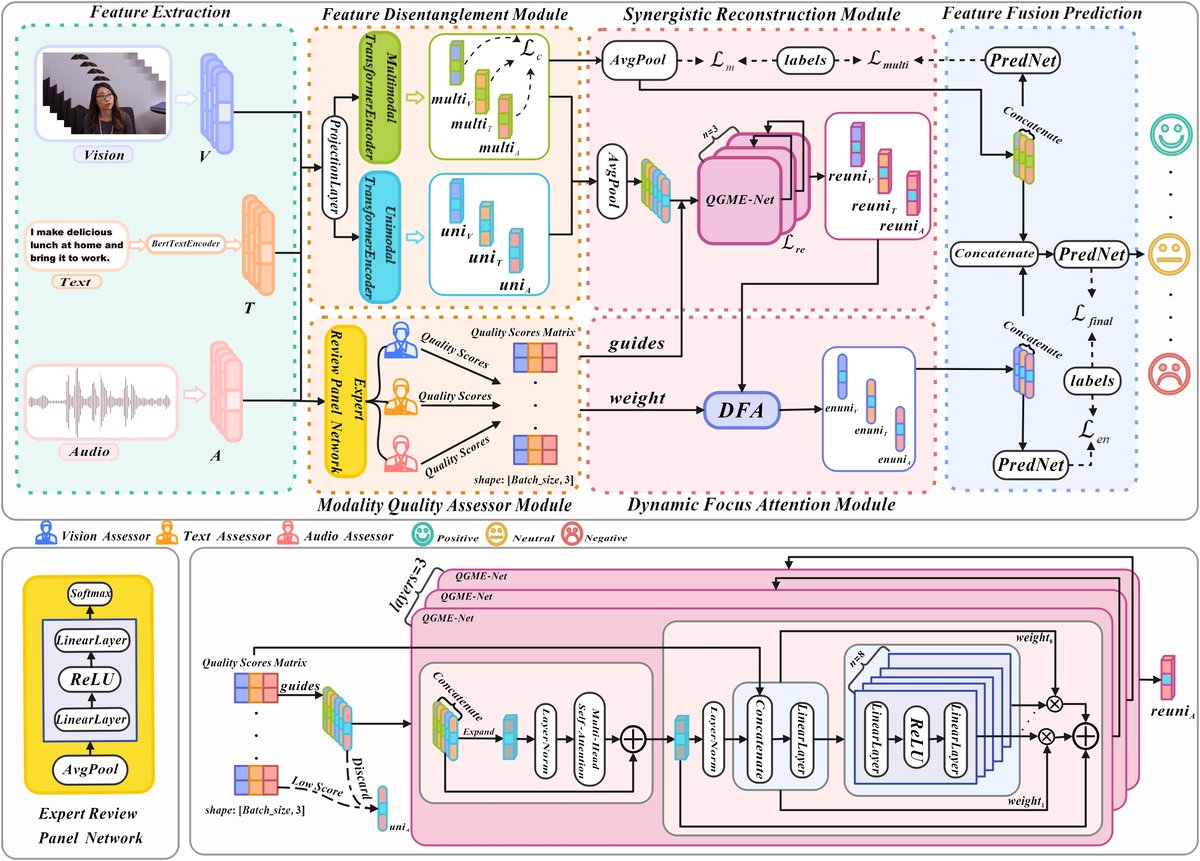
模型主要包含以下四个核心模块:
- 模态质量评估模块 (Modality Quality Assessor Module):为每个模态的特征计算一个可靠性分数。首先对每个模态的特征序列进行平均池化得到全局表示
fm,然后通过一个独立的MLP和Sigmoid函数预测出质量分数qm。所有模态的分数组成向量Qscore。其功能是量化每个模态在当前样本中的信息质量。 - 特征分解模块 (Feature Disentanglement Module):将每种模态的特征
Fm投影到统一维度后,通过一个共享Transformer编码器和三个模态特定Transformer编码器,分别分解出共享特征multim和模态特定特征unim。这一步的动机是分离跨模态通用情感信息和模态独有的信息。 - 协同重建模块 (Synergistic Reconstruction Module):这是核心创新之一。当某个模态的质量分数
qm低于预设阈值θ时,系统会利用其他模态的信息来修复该模态的特定特征。修复的上下文(如式6)由所有模态的共享特征和未受损模态的特定特征池化拼接而成。例如,当音频质量差时,会使用文本和视觉的特征作为上下文,通过一个名为QGME-Net (质量门控混合专家网络) 的生成器来重建音频的特定特征reuniA。高质量模态的特征则保持不变。此模块实现了“用可靠模态增强低质量模态”。 - 动态聚焦注意力模块 (Dynamic Focus Attention Module):对重建后的各模态特定特征进行跨模态注意力增强。例如,用文本特征作为Query,用音频和视觉特征作为Key/Value进行注意力计算,得到增强后的特征
enhancedT。最后,将增强后的特征池化,并与第一步得到的模态质量分数Qscore结合,通过Softmax得到权重α',对各模态特征进行加权融合。此模块实现了“根据可靠性动态聚焦”的自适应融合。
数据流是:输入特征 -> 质量评估(得到分数)与特征分解(得到共享/特定特征)并行进行 -> 协同重建(根据分数修复特定特征)-> 动态融合(利用分数加权)与层级预测。最终的预测结合了共享特征预测、特定特征预测和联合特征预测(式14-16)。
- 动态样本级模态质量评估:与以往方法假设模态重要性固定或仅通过注意力隐式调整不同,DDSR-Net显式地为每个样本的每个模态计算一个可靠性分数。这为后续的修复和融合提供了明确的、数据驱动的指导信号,是处理现实世界噪声和不对称性的关键前提。
- 跨模态协同修复机制:针对低质量模态,设计了选择性的特征重建过程。它并非简单丢弃或降权,而是主动利用来自其他模态(共享和特定)的上下文信息,通过生成器对退化的特征进行“修复”。这超越了传统的注意力加权方法,实现了更积极的信息互补。
- “评估-修复-聚焦”闭环流程:将质量评估、选择性修复和动态注意力融合整合为一个紧密耦合的闭环系统。评估指导修复,修复后的特征输入融合,而融合的权重又直接来源于评估分数。这种设计使得模型能系统性地处理模态质量动态变化问题,形成了完整的应对流水线。
- 设计了多组件、多层次的损失函数:除了任务预测损失,还引入了跨模态生成正则化损失(防止修复模块产生幻觉)、对比损失(对齐共享特征)和分离损失(分离特定特征)。这些损失从不同角度约束了特征学习和修复过程,提升了框架的鲁棒性。
- 训练数据:使用CMU-MOSI和CMU-MOSEI公开数据集。论文未详细说明预处理、数据增强或具体数据划分细节。
- 损失函数:总损失(式17)为四项加权和:
Ltask:层级预测损失,使用Focal L1 Loss(γ=0.5),对最终预测、共享特征预测、特定特征预测进行监督(式18, 19)。Lre:跨模态生成正则化损失,使用L1 Loss约束重建特征与原始特征分布的一致性(式20)。Lc:对比损失,使用InfoNCE损失对齐文本与音频、文本与视觉的共享特征(式21)。Ld:分离损失,使用三元组损失(Triplet Loss),基于情感标签y分离不同类别的特定特征(式22)。- 各损失权重
λtask, λre, λc, λd未说明具体数值。
- 训练策略:论文未提及学习率、优化器、batch size、训练轮数、warmup策略等具体训练细节。
- 关键超参数:质量评估模块中MLP的具体结构未说明;协同重建模块中的质量阈值
θ未说明;特征维度dm、Transformer编码器的层数、注意力头数等未说明。仅从架构图可知使用了Transformer编码器。 - 训练硬件:论文中未提及。
- 推理细节:未提及,应为标准的单次前向传播。
- 正则化技巧:通过多任务损失(对比、分离)和生成正则化损失
Lre实现隐式正则化;未提及Dropout等显式技巧。
论文在MOSI和MOSEI两个基准数据集上进行了实验,主要指标包括MAE↓、Corr↑、Acc-7↑、Acc-5↑、Acc-2↑和F1↑。
表1:在CMU-MOSI和CMU-MOSEI数据集上的主实验结果对比
| 模型 | CMU-MOSI | CMU-MOSEI | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE↓ | Corr↑ | Acc-7↑ | Acc-5↑ | Acc-2↑ | F1↑ | MAE↓ | Corr↑ | Acc-7↑ | Acc-5↑ | Acc-2↑ | F1↑ | |
| TFN | 0.901 | 0.698 | 34.9 | - | -/80.8 | -/80.7 | 0.593 | 0.700 | 50.2 | - | -/82.5 | -/82.1 |
| LMF | 0.917 | 0.695 | 33.2 | - | -/82.5 | -/82.4 | 0.623 | 0.677 | 48.0 | - | -/82.0 | -/82.1 |
| MulT | 0.846 | 0.725 | 40.4 | 46.7 | 81.7/83.4 | 81.9/83.5 | 0.564 | 0.731 | 52.6 | 54.1 | 80.5/83.5 | 80.9/83.6 |
| MISA | 0.804 | 0.764 | - | - | 80.8/82.1 | 80.8/82.0 | 0.568 | 0.724 | - | - | 82.6/84.2 | 82.7/84.0 |
| Self-MM | 0.717 | 0.793 | 46.4 | 52.8 | 82.9/84.6 | 82.8/84.6 | 0.533 | 0.766 | 53.6 | 55.4 | 82.4/85.0 | 82.8/85.0 |
| TFR-Net | 0.721 | 0.789 | 46.1 | 53.2 | 82.7/84.0 | 82.7/84.0 | 0.551 | 0.756 | 52.3 | 54.3 | 81.8/83.5 | 81.6/83.8 |
| FDMER | 0.724 | 0.788 | 44.1 | - | -/84.6 | -/84.7 | 0.536 | 0.773 | 54.1 | - | -/86.1 | -/85.8 |
| AMML | 0.723 | 0.792 | 46.3 | - | -/84.9 | -/84.8 | 0.614 | 0.776 | 52.4 | - | -/85.3 | -/85.2 |
| HyDiscGAN | 0.749 | 0.782 | 43.2 | - | 84.1/86.7 | 83.7/86.3 | 0.533 | 0.761 | 54.4 | - | 81.9/86.3 | 82.1/86.2 |
| DEVA | 0.730 | 0.787 | 46.32 | 51.78 | 84.40/86.29 | 84.48/86.30 | 0.541 | 0.769 | 52.26 | 55.32 | 83.26/86.13 | 82.93/86.21 |
| DDSR-Net | 0.7098 | 0.7989 | 47.08 | 55.54 | 83.09/85.52 | 82.70/85.24 | 0.5327 | 0.7706 | 54.17 | 55.91 | 83.04/86.35 | 83.46/86.33 |
关键结论:
- 在MOSI上,DDSR-Net取得了最低的MAE(0.7098)和最高的相关系数Corr(0.7989),以及最高的Acc-5(55.54%)。在二分类准确率(Acc-2)上略低于DEVA和HyDiscGAN,但差距很小。
- 在MOSEI上,DDSR-Net取得了最低的MAE(0.5327),最高的Acc-5(55.91%),以及最高的二分类F1分数(83.46/86.33)。
- 论文声称在多个指标上达到或接近SOTA,表格数据支持了其在回归任务(MAE)和细粒度分类(Acc-5, Acc-7)上的优势。
表2:在CMU-MOSI和CMU-MOSEI数据集上的消融实验
| 模型 | CMU-MOSI | CMU-MOSEI | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE↓ | Corr↑ | Acc-7↑ | Acc-5↑ | Acc-2↑ | F1↑ | MAE↓ | Corr↑ | Acc-7↑ | Acc-5↑ | Acc-2↑ | F1↑ | |
| DDSR-Net | 0.7098 | 0.7989 | 47.08 | 55.54 | 83.09/85.52 | 82.70/85.24 | 0.5327 | 0.7706 | 54.17 | 55.91 | 83.04/86.35 | 83.46/86.33 |
| w/o Synergistic Reconstruction | 0.7221 | 0.7953 | 46.65 | 53.06 | 82.07/83.99 | 82.02/84.01 | 0.5504 | 0.7615 | 52.78 | 54.58 | 80.77/84.95 | 81.31/84.92 |
| w/o Dynamic Focus | 0.7239 | 0.7917 | 46.79 | 52.62 | 82.51/84.45 | 82.46/84.47 | 0.5639 | 0.7618 | 50.91 | 53.42 | 80.58/84.73 | 81.22/84.80 |
| w/o Dynamic Pipeline | 0.7695 | 0.7711 | 46.50 | 53.21 | 80.61/82.77 | 80.49/82.73 | 0.6029 | 0.7575 | 48.57 | 51.19 | 80.92/84.76 | 81.45/84.74 |
| w/o Lc & Ld | 0.7372 | 0.7786 | 46.21 | 52.77 | 82.36/83.69 | 82.36/83.73 | 0.5509 | 0.7644 | 52.54 | 54.67 | 81.93/85.20 | 82.40/85.19 |
| w/o Hierarchical Supervision | 0.7169 | 0.7870 | 45.77 | 51.60 | 81.34/83.08 | 81.28/83.08 | 0.5619 | 0.7578 | 52.18 | 54.02 | 81.95/85.28 | 82.41/85.26 |
| Use L1 Loss instead of Focal L1 | 0.7456 | 0.7845 | 45.34 | 50.58 | 82.22/83.38 | 82.18/83.40 | 0.5416 | 0.7676 | 53.08 | 54.60 | 78.32/84.42 | 76.20/84.56 |
消融实验结论:
完整模型在所有指标上均优于所有消融变体,证明了各组件的有效性。
移除动态闭环流程 (w/o Dynamic Pipeline) 导致性能下降最为显著,尤其是在MOSEI的MAE(从0.5327升至0.6029)和相关系数上,证明了该流水线的整体价值。
移除协同重建 (w/o Synergistic Reconstruction) 和 移除动态聚焦 (w/o Dynamic Focus) 都造成了明显的性能损失,验证了这两个核心模块的必要性。
移除对比与分离损失 (w/o Lc & Ld) 和 移除层级监督 (w/o Hierarchical Supervision) 也导致了性能下降,表明了这些辅助损失和训练策略对提升特征质量和最终预测的重要性。
将Focal L1 Loss替换为普通L1 Loss后性能显著下降,特别是在MOSEI的二分类F1上,说明Focal L1对于处理情感预测中可能存在的样本难度不平衡问题更为有效。
学术质量:5.5/7。论文提出了一个逻辑清晰、设计完整的框架来解决一个实际且重要的问题(动态模态质量评估与修复)。技术路线正确,实验对比充分,在主流数据集上取得了有竞争力的结果。主要扣分点在于:1) 核心创新(如动态评估、跨模态修复)并非全新概念,是对现有思路的系统化和深化;2) 关键组件(如QGME-Net生成器)的架构细节缺失,影响了方法的透明度和可复现性;3) 缺乏对极端情况(如单模态严重缺失)的深入分析。
选题价值:1.5/2。多模态情感分析是当前人工智能的热点领域,其鲁棒性研究(处理噪声、不对齐)具有明确的理论价值和广泛的应用前景(如人机交互、心理健康)。论文选题紧扣前沿,针对的问题实际。
开源与复现加成:0.0/1。论文中未提及代码、预训练模型、数据集处理脚本或详细的超参数配置等开源信息,复现依赖于从头实现并调优整个复杂框架。
开源详情
- 代码:论文中未提及代码链接或开源仓库。
- 模型权重:未提及公开权重。
- 数据集:使用公开的CMU-MOSI和CMU-MOSEI数据集,但未说明具体获取方式或预处理脚本。
- Demo:未提供在线演示。
- 复现材料:论文未提供训练细节(如优化器、学习率、batch size)、超参数配置、检查点或附录说明。
- 论文中引用的开源项目:论文中引用了多个基线模型(如TFN, MulT, Self-MM等)的官方代码仓库([6]-[22]),但未明确说明DDSR-Net���身是否基于或依赖这些项目。
- 总结:论文中未提及任何关于开源计划、代码发布或模型共享的信息。
🏗️ 模型架构
DDSR-Net的整体架构如图1所示,是一个端到端的多阶段处理框架,输入为文本(T)、音频(A)、视觉(V)三种模态的非对齐特征序列,最终输出一个连续的情感预测值。
模型主要包含以下四个核心模块:
- 模态质量评估模块 (Modality Quality Assessor Module):为每个模态的特征计算一个可靠性分数。首先对每个模态的特征序列进行平均池化得到全局表示
fm,然后通过一个独立的MLP和Sigmoid函数预测出质量分数qm。所有模态的分数组成向量Qscore。其功能是量化每个模态在当前样本中的信息质量。 - 特征分解模块 (Feature Disentanglement Module):将每种模态的特征
Fm投影到统一维度后,通过一个共享Transformer编码器和三个模态特定Transformer编码器,分别分解出共享特征multim和模态特定特征unim。这一步的动机是分离跨模态通用情感信息和模态独有的信息。 - 协同重建模块 (Synergistic Reconstruction Module):这是核心创新之一。当某个模态的质量分数
qm低于预设阈值θ时,系统会利用其他模态的信息来修复该模态的特定特征。修复的上下文(如式6)由所有模态的共享特征和未受损模态的特定特征池化拼接而成。例如,当音频质量差时,会使用文本和视觉的特征作为上下文,通过一个名为QGME-Net (质量门控混合专家网络) 的生成器来重建音频的特定特征reuniA。高质量模态的特征则保持不变。此模块实现了“用可靠模态增强低质量模态”。 - 动态聚焦注意力模块 (Dynamic Focus Attention Module):对重建后的各模态特定特征进行跨模态注意力增强。例如,用文本特征作为Query,用音频和视觉特征作为Key/Value进行注意力计算,得到增强后的特征
enhancedT。最后,将增强后的特征池化,并与第一步得到的模态质量分数Qscore结合,通过Softmax得到权重α',对各模态特征进行加权融合。此模块实现了“根据可靠性动态聚焦”的自适应融合。
数据流是:输入特征 -> 质量评估(得到分数)与特征分解(得到共享/特定特征)并行进行 -> 协同重建(根据分数修复特定特征)-> 动态融合(利用分数加权)与层级预测。最终的预测结合了共享特征预测、特定特征预测和联合特征预测(式14-16)。
💡 核心创新点
- 动态样本级模态质量评估:与以往方法假设模态重要性固定或仅通过注意力隐式调整不同,DDSR-Net显式地为每个样本的每个模态计算一个可靠性分数。这为后续的修复和融合提供了明确的、数据驱动的指导信号,是处理现实世界噪声和不对称性的关键前提。
- 跨模态协同修复机制:针对低质量模态,设计了选择性的特征重建过程。它并非简单丢弃或降权,而是主动利用来自其他模态(共享和特定)的上下文信息,通过生成器对退化的特征进行“修复”。这超越了传统的注意力加权方法,实现了更积极的信息互补。
- “评估-修复-聚焦”闭环流程:将质量评估、选择性修复和动态注意力融合整合为一个紧密耦合的闭环系统。评估指导修复,修复后的特征输入融合,而融合的权重又直接来源于评估分数。这种设计使得模型能系统性地处理模态质量动态变化问题,形成了完整的应对流水线。
- 设计了多组件、多层次的损失函数:除了任务预测损失,还引入了跨模态生成正则化损失(防止修复模块产生幻觉)、对比损失(对齐共享特征)和分离损失(分离特定特征)。这些损失从不同角度约束了特征学习和修复过程,提升了框架的鲁棒性。
🔬 细节详述
- 训练数据:使用CMU-MOSI和CMU-MOSEI公开数据集。论文未详细说明预处理、数据增强或具体数据划分细节。
- 损失函数:总损失(式17)为四项加权和:
Ltask:层级预测损失,使用Focal L1 Loss(γ=0.5),对最终预测、共享特征预测、特定特征预测进行监督(式18, 19)。Lre:跨模态生成正则化损失,使用L1 Loss约束重建特征与原始特征分布的一致性(式20)。Lc:对比损失,使用InfoNCE损失对齐文本与音频、文本与视觉的共享特征(式21)。Ld:分离损失,使用三元组损失(Triplet Loss),基于情感标签y分离不同类别的特定特征(式22)。- 各损失权重
λtask, λre, λc, λd未说明具体数值。
- 训练策略:论文未提及学习率、优化器、batch size、训练轮数、warmup策略等具体训练细节。
- 关键超参数:质量评估模块中MLP的具体结构未说明;协同重建模块中的质量阈值
θ未说明;特征维度dm、Transformer编码器的层数、注意力头数等未说明。仅从架构图可知使用了Transformer编码器。 - 训练硬件:论文中未提及。
- 推理细节:未提及,应为标准的单次前向传播。
- 正则化技巧:通过多任务损失(对比、分离)和生成正则化损失
Lre实现隐式正则化;未提及Dropout等显式技巧。
📊 实验结果
论文在MOSI和MOSEI两个基准数据集上进行了实验,主要指标包括MAE↓、Corr↑、Acc-7↑、Acc-5↑、Acc-2↑和F1↑。
表1:在CMU-MOSI和CMU-MOSEI数据集上的主实验结果对比
| 模型 | CMU-MOSI | CMU-MOSEI | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE↓ | Corr↑ | Acc-7↑ | Acc-5↑ | Acc-2↑ | F1↑ | MAE↓ | Corr↑ | Acc-7↑ | Acc-5↑ | Acc-2↑ | F1↑ | |
| TFN | 0.901 | 0.698 | 34.9 | - | -/80.8 | -/80.7 | 0.593 | 0.700 | 50.2 | - | -/82.5 | -/82.1 |
| LMF | 0.917 | 0.695 | 33.2 | - | -/82.5 | -/82.4 | 0.623 | 0.677 | 48.0 | - | -/82.0 | -/82.1 |
| MulT | 0.846 | 0.725 | 40.4 | 46.7 | 81.7/83.4 | 81.9/83.5 | 0.564 | 0.731 | 52.6 | 54.1 | 80.5/83.5 | 80.9/83.6 |
| MISA | 0.804 | 0.764 | - | - | 80.8/82.1 | 80.8/82.0 | 0.568 | 0.724 | - | - | 82.6/84.2 | 82.7/84.0 |
| Self-MM | 0.717 | 0.793 | 46.4 | 52.8 | 82.9/84.6 | 82.8/84.6 | 0.533 | 0.766 | 53.6 | 55.4 | 82.4/85.0 | 82.8/85.0 |
| TFR-Net | 0.721 | 0.789 | 46.1 | 53.2 | 82.7/84.0 | 82.7/84.0 | 0.551 | 0.756 | 52.3 | 54.3 | 81.8/83.5 | 81.6/83.8 |
| FDMER | 0.724 | 0.788 | 44.1 | - | -/84.6 | -/84.7 | 0.536 | 0.773 | 54.1 | - | -/86.1 | -/85.8 |
| AMML | 0.723 | 0.792 | 46.3 | - | -/84.9 | -/84.8 | 0.614 | 0.776 | 52.4 | - | -/85.3 | -/85.2 |
| HyDiscGAN | 0.749 | 0.782 | 43.2 | - | 84.1/86.7 | 83.7/86.3 | 0.533 | 0.761 | 54.4 | - | 81.9/86.3 | 82.1/86.2 |
| DEVA | 0.730 | 0.787 | 46.32 | 51.78 | 84.40/86.29 | 84.48/86.30 | 0.541 | 0.769 | 52.26 | 55.32 | 83.26/86.13 | 82.93/86.21 |
| DDSR-Net | 0.7098 | 0.7989 | 47.08 | 55.54 | 83.09/85.52 | 82.70/85.24 | 0.5327 | 0.7706 | 54.17 | 55.91 | 83.04/86.35 | 83.46/86.33 |
关键结论:
- 在MOSI上,DDSR-Net取得了最低的MAE(0.7098)和最高的相关系数Corr(0.7989),以及最高的Acc-5(55.54%)。在二分类准确率(Acc-2)上略低于DEVA和HyDiscGAN,但差距很小。
- 在MOSEI上,DDSR-Net取得了最低的MAE(0.5327),最高的Acc-5(55.91%),以及最高的二分类F1分数(83.46/86.33)。
- 论文声称在多个指标上达到或接近SOTA,表格数据支持了其在回归任务(MAE)和细粒度分类(Acc-5, Acc-7)上的优势。
表2:在CMU-MOSI和CMU-MOSEI数据集上的消融实验
| 模型 | CMU-MOSI | CMU-MOSEI | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE↓ | Corr↑ | Acc-7↑ | Acc-5↑ | Acc-2↑ | F1↑ | MAE↓ | Corr↑ | Acc-7↑ | Acc-5↑ | Acc-2↑ | F1↑ | |
| DDSR-Net | 0.7098 | 0.7989 | 47.08 | 55.54 | 83.09/85.52 | 82.70/85.24 | 0.5327 | 0.7706 | 54.17 | 55.91 | 83.04/86.35 | 83.46/86.33 |
| w/o Synergistic Reconstruction | 0.7221 | 0.7953 | 46.65 | 53.06 | 82.07/83.99 | 82.02/84.01 | 0.5504 | 0.7615 | 52.78 | 54.58 | 80.77/84.95 | 81.31/84.92 |
| w/o Dynamic Focus | 0.7239 | 0.7917 | 46.79 | 52.62 | 82.51/84.45 | 82.46/84.47 | 0.5639 | 0.7618 | 50.91 | 53.42 | 80.58/84.73 | 81.22/84.80 |
| w/o Dynamic Pipeline | 0.7695 | 0.7711 | 46.50 | 53.21 | 80.61/82.77 | 80.49/82.73 | 0.6029 | 0.7575 | 48.57 | 51.19 | 80.92/84.76 | 81.45/84.74 |
| w/o Lc & Ld | 0.7372 | 0.7786 | 46.21 | 52.77 | 82.36/83.69 | 82.36/83.73 | 0.5509 | 0.7644 | 52.54 | 54.67 | 81.93/85.20 | 82.40/85.19 |
| w/o Hierarchical Supervision | 0.7169 | 0.7870 | 45.77 | 51.60 | 81.34/83.08 | 81.28/83.08 | 0.5619 | 0.7578 | 52.18 | 54.02 | 81.95/85.28 | 82.41/85.26 |
| Use L1 Loss instead of Focal L1 | 0.7456 | 0.7845 | 45.34 | 50.58 | 82.22/83.38 | 82.18/83.40 | 0.5416 | 0.7676 | 53.08 | 54.60 | 78.32/84.42 | 76.20/84.56 |
消融实验结论:
- 完整模型在所有指标上均优于所有消融变体,证明了各组件的有效性。
- 移除动态闭环流程 (w/o Dynamic Pipeline) 导致性能下降最为显著,尤其是在MOSEI的MAE(从0.5327升至0.6029)和相关系数上,证明了该流水线的整体价值。
- 移除协同重建 (w/o Synergistic Reconstruction) 和 移除动态聚焦 (w/o Dynamic Focus) 都造成了明显的性能损失,验证了这两个核心模块的必要性。
- 移除对比与分离损失 (w/o Lc & Ld) 和 移除层级监督 (w/o Hierarchical Supervision) 也导致了性能下降,表明了这些辅助损失和训练策略对提升特征质量和最终预测的重要性。
- 将Focal L1 Loss替换为普通L1 Loss后性能显著下降,特别是在MOSEI的二分类F1上,说明Focal L1对于处理情感预测中可能存在的样本难度不平衡问题更为有效。
⚖️ 评分理由
- 学术质量:5.5/7。论文提出了一个逻辑清晰、设计完整的框架来解决一个实际且重要的问题(动态模态质量评估与修复)。技术路线正确,实验对比充分,在主流数据集上取得了有竞争力的结果。主要扣分点在于:1) 核心创新(如动态评估、跨模态修复)并非全新概念,是对现有思路的系统化和深化;2) 关键组件(如QGME-Net生成器)的架构细节缺失,影响了方法的透明度和可复现性;3) 缺乏对极端情况(如单模态严重缺失)的深入分析。
- 选题价值:1.5/2。多模态情感分析是当前人工智能的热点领域,其鲁棒性研究(处理噪声、不对齐)具有明确的理论价值和广泛的应用前景(如人机交互、心理健康)。论文选题紧扣前沿,针对的问题实际。
- 开源与复现加成:0.0/1。论文中未提及代码、预训练模型、数据集处理脚本或详细的超参数配置等开源信息,复现依赖于从头实现并调优整个复杂框架。