📄 DDSC: Dynamic Dual-Signal Curriculum for Data-Efficient Acoustic Scene Classification Under Domain Shift
#音频场景分类 #课程学习 #领域适应 #低资源
✅ 7.0/10 | 前25% | #音频场景分类 | #课程学习 | #领域适应 #低资源
学术质量 6.0/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Peihong Zhang(School of Advanced Technology, Xi’an Jiaotong-Liverpool University, Suzhou, China)
- 通讯作者:未说明(论文中未明确标注通讯作者)
- 作者列表:Peihong Zhang(School of Advanced Technology, Xi’an Jiaotong-Liverpool University, Suzhou, China)、Yuxuan Liu(同上)、Rui Sang(同上)、Zhixin Li(同上)、Yiqiang Cai(同上)、Yizhou Tan(同上)、Shengchen Li(同上)
💡 毒舌点评
亮点在于巧妙地将“领域不变性”和“学习进度”两个动态信号融合成自适应的课程权重,避免了传统课程学习静态排序的僵化,设计轻量且即插即用。短板则是其动态调整高度依赖已知的设备标签进行原型计算,一旦面对完全无标签或设备信息未知的真实场景,该方法的适用性将面临直接挑战。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及。
- 数据集:使用的是公开的 DCASE 2024 Task 1 数据集,但论文未提供获取链接(可通过 DCASE Challenge 官网获取)。
- Demo:未提及。
- 复现材料:论文给出了算法伪代码(Algorithm 1)和核心公式,但缺失关键超参数的具体数值和完整的训练脚本/配置。
- 论文中引用的开源项目:论文在基线介绍中提到了几个来自挑战赛的提交系统(如 DS-FlexiNet),但未明确说明这些是否为开源项目及其链接。主要依赖的工具(如具体框架 PyTorch/TensorFlow)也未说明。
📌 核心摘要
- 要解决的问题:声学场景分类(ASC)中由录音设备差异引起的领域偏移问题,特别是在可用标注数据有限的低资源场景下,模型性能会严重下降。
- 方法核心:提出动态双信号课程(DDSC)训练策略。该方法不修改模型架构,而是在每个训练 epoch 动态计算并融合两个信号来为每个样本分配训练权重:一个基于设备原型熵的“领域不变性信号”,用于识别与设备无关的样本;一个基于损失平滑变化的“学习进度信号”,用于衡量样本的边际学习价值。
- 新在何处:与之前静态的课程学习方法(如EGCL, SSPL, LCL, CLDG)固定样本排序或权重不同,DDSC 能够根据训练过程中模型表示和决策边界的演变,在线调整每个样本的重要性,实现了真正动态的、由易到难的学习过程。
- 主要实验结果:在 DCASE 2024 Task 1 官方数据集和协议下,DDSC 在多个基线模型和不同标注预算(5%-100%)上均取得一致提升。在最具挑战性的 5% 标注预算下,DDSC 相较于基线平均提升约 4.2% 的总体准确率和 3.9% 的未见设备准确率。 关键结果对比如下表所示:
| 系统 | 总体准确率 (5%) | 未见设备准确率 (5%) | 总体准确率 (100%) | 未见设备准确率 (100%) |
|---|---|---|---|---|
| DCASE2024 Baseline | 44.00% | 42.40% | 56.84% | 46.70% |
| +DDSC (ours) | 48.17% | 46.10% | 58.19% | 46.10% |
| Cai XJTLU (Baseline) | 48.91% | 46.70% | 62.12% | 46.70% |
| +DDSC (ours) | 53.70% | 51.68% | 64.25% | 51.68% |
| Han SJTUTHU (Baseline) | 54.35% | 52.70% | 61.82% | 52.70% |
| +DDSC (ours) | 57.86% | 56.42% | 63.03% | 56.42% |
- 实际意义:为低资源、跨设备音频分类提供了一种有效的即插即用训练策略,能与数据增强、特征对齐等方法互补,提升模型泛化能力,具有实际应用价值。
- 主要局限性:计算领域不变性信号需要每个样本的设备标签,限制了其在完全无监督或设备信息缺失场景下的应用;其动态权重的融合调度函数(如余弦衰减)的超参数需要调优。
🏗️ 模型架构
DDSC 本身并非一个独立的神经网络模型,而是一个轻量级、架构无关的训练调度框架,可以应用于任何现有的音频分类骨干网络。其核心架构与数据流如图2所示。
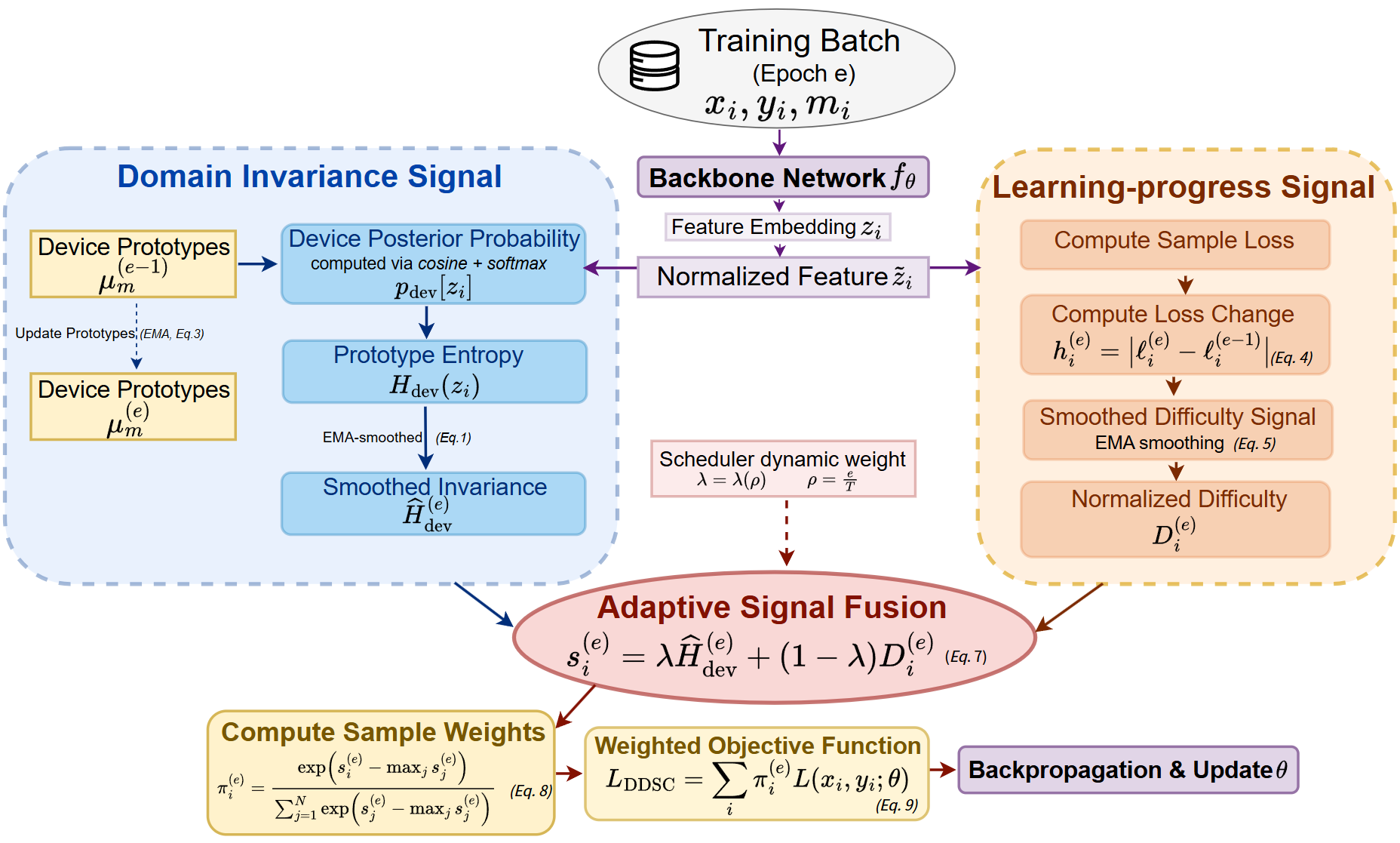 图2:DDSC框架概览。
图2:DDSC框架概览。
- 输入:一批音频样本及其标签和设备ID。
- 骨干网络:一个标准的分类网络(如CNN或Transformer),将音频输入映射为归一化的特征向量
z_i。 - 信号计算:
- 领域不变性信号:利用在线更新的设备原型(每个设备一个原型向量)。计算特征向量与所有设备原型的余弦相似度,经过温度缩放得到设备后验概率分布,再计算其熵
H_dev。高熵表示样本难以区分设备,即具有更强的领域不变性。该信号通过指数滑动平均(EMA)平滑。 - 学习进度信号:记录每个样本的损失在相邻 epoch 间的变化
h_i^(e),并通过 EMA 得到平滑的损失变化D_i^(e),再进行 epoch 内归一化得到D̃_i^(e)。高值表示损失不稳定,样本的学习边际收益高。
- 领域不变性信号:利用在线更新的设备原型(每个设备一个原型向量)。计算特征向量与所有设备原型的余弦相似度,经过温度缩放得到设备后验概率分布,再计算其熵
- 信号融合:一个随训练进度
ρ_e(从0到1)单调递减的调度函数λ(ρ_e)(采用带底值的余弦退火)将两个信号加权融合为一个课程分数s_i^(e)。- 早期(
ρ_e小,λ大):更重视领域不变性信号(高H的样本)。 - 后期(
ρ_e大,λ小):更重视学习进度信号(高D̃的样本)。
- 早期(
- 权重生成:通过 Softmax 函数将所有样本的课程分数转换为归一化的训练权重
π_i^(e)。 - 加权训练:用计算出的权重
π_i^(e)替换均匀平均,构建加权损失函数进行反向传播。 - 更新:训练完成后,更新设备原型(使用当前 epoch 的特征 EMA 和 L2 归一化),并计算新的样本损失用于下一轮信号计算。
关键设计选择:设备原型在线更新(而非离线固定),使得领域不变性信号能与模型共同进化,这是实现“动态”课程的核心。整个过程仅涉及轻量计算,无额外可训练参数,不增加推理开销。
💡 核心创新点
- 动态双信号融合课程:提出了结合领域不变性(基于原型熵)和学习进度(基于损失变化)两个互补信号,并设计了随训练进程自适应变化的融合调度器,实现了真正动态的、由易到难的课程学习,克服了静态课程无法适应模型演化的局限。
- 在线演化的领域不变性度量:摒弃了使用独立、静态的设备分类器来评估样本不变性的传统做法,改为通过在线更新的设备原型计算熵值。这使得评估信号能与主任务模型共同进化,提供了更准确的、实时的样本难度评估。
- 轻量级即插即用设计:DDSC 作为训练策略,无需修改模型架构,不增加模型参数和推理计算量,可以无缝集成到各种现有的 ASC 基线系统中,实用性强。
🔬 细节详述
- 训练数据:使用 DCASE 2024 Task 1 官方数据集,来源于 TAU Urban Acoustic Scenes 2022 Mobile。包含 230,350 段 1 秒音频,10 个声学场景,12 个城市录制。训练设备包括真实设备 A、B、C 和模拟设备 S1-S3,测试设备包括所有训练设备以及三个未见的模拟设备 S4-S6。数据存在不平衡(设备 A 数据量远大于其他)。严格遵循官方低资源协议,使用 5%, 10%, 25%, 50%, 100% 的训练子集。
- 损失函数:论文未指定具体的分类损失函数(如交叉熵),表明 DDSC 与特定损失形式无关,使用基线模型的原始损失
L(x_i, y_i; θ),仅用动态权重π_i^(e)进行加权(公式9)。 - 训练策略:训练轮数
T未具体说明。优化器、学习率、batch size 等细节也未在论文中说明,属于未提及内容。 - 关键超参数:调度函数
λ(ρ_e)中,λ_min = 0.2,通过验证集选择。设备原型更新的滑动平均系数γ和信号平滑的 EMA 系数β,η未说明具体数值。公式(1)中的温度τ和公式(6)中的ε也未说明。 - 训练硬件:论文中未提及使用的 GPU 型号、数量及训练时长。
- 推理细节:DDSC 是训练阶段方法,不改变模型推理过程,因此无额外推理开销。解码策略等不适用。
- 正则化或稳定训练技巧:除了信号本身的 EMA 平滑,论文未提及其他特定的正则化技巧。
📊 实验结果
论文在 DCASE 2024 Task 1 官方评估集上进行了充分实验,比较了 DDSC 与四种现有课程学习方法(LCL, CLDG, EGCL, SSPL)在四个不同基线系统上的效果。
主要对比结果(分类准确率 %): 表2 完整展示了所有对比结果。关键结论:
- 一致性提升:在所有基线、所有标注预算下,添加 DDSC(“+DDSC”)均能带来性能提升。
- 低资源收益更大:提升幅度在低标注预算(如 5%)下最为显著。例如,在
Cai XJTLU基线的 5% 预算下,总体准确率从 48.91% 提升至 53.70%(+4.79%),未见设备准确率从 46.70% 提升至 51.68%(+4.98%)。 - 最佳性能:对于每个基线和预算组合,使用 DDSC 的模型均达到最佳或并列最佳结果。
- 超越现有方法:DDSC 的性能一致性地优于或与其他先进的静态课程学习方法(如 EGCL, SSPL)持平,尤其是在未见设备分割(Unseen)上优势更明显。
图表分析:
- 图1:展示了设备诱导的领域偏移现象。同一场景(公园)在不同设备(A, B, C)录制的频谱图存在明显差异,直观说明了模型在设备C上可能误分类的原因。这为整篇论文的问题定义提供了可视化支持。
- 图2:如前所述,清晰地展示了DDSC作为训练调度框架的整体流程和核心组件。
⚖️ 评分理由
- 学术质��:6.0/7 - 创新性明确(动态双信号融合),技术方案设计合理,有理论和公式支撑。实验非常充分,涵盖了多个基线、多种数据量设置,并与多个强竞争对手进行了全面对比,提供了详实的定量结果。证据可信度高,基于官方挑战赛协议和数据集。扣分点在于部分关键超参数(γ, β, η, τ)和训练细节未披露,一定程度上影响了完整性的评估。
- 选题价值:1.0/2 - 解决的设备偏移和低资源问题是声学场景分类领域的核心挑战之一,具有明确的前沿性和实际应用价值(如移动设备部署)。对于音频/语音研究者,该问题和方法具有普遍参考意义。但相较于一些更具突破性或跨领域影响力的工作,其选题的冲击力有限。
- 开源与复现加成:0.0/1 - 论文未提供代码、模型权重、或详细的超参数配置列表。虽然方法描述清晰,但缺少这些材料使得完全复现实验存在障碍,因此此项不加分也不扣分。