📄 DAT-CFTNet: Speech Enhancement for Cochlear Implant Recipients using Attention-based Dual-Path Recurrent Neural Network
#语音增强 #注意力机制 #双路径RNN #复数值网络 #人工耳蜗
✅ 7.0/10 | 前50% | #语音增强 | #注意力机制 | #双路径RNN #复数值网络
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Nursadul Mamun(Chittagong University of Engineering and Technology, Chittagong, Bangladesh)
- 通讯作者:未明确标注,根据实验室归属推测为John H.L. Hansen(University of Texas at Dallas, USA)
- 作者列表:Nursadul Mamun (Chittagong University of Engineering and Technology), John H. L. Hansen (University of Texas at Dallas; CRSS: Center for Robust Speech Systems; Cochlear Implant Processing Laboratory)
💡 毒舌点评
论文针对人工耳蜗用户这一垂直领域进行了扎实的工程优化,将注意力机制融入双路径RNN瓶颈层,确实看到了性能提升,且提供了轻量化变体的思考。但核心方法更偏向于“拿来主义”的组合(DPRNN + Attention + CFTNet),且实验验证主要局限于自身的变体对比和自建数据集,缺乏在业界公认的大型基准(如VoiceBank-DEMAND)上的横向比对来确立其绝对竞争力。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及是否公开。
- 数据集:使用了IEEE语音库和AURORA噪声集,但未说明其提供的数据是否包含这些原始数据集,或是否发��了处理后的数据集。
- Demo:未提及。
- 复现材料:论文给出了一些训练细节(优化器、学习率、批次大小、训练轮数、损失函数形式),但未提供完整的配置文件或脚本。
- 引用的开源项目:论文未明确列出其代码依赖的开源项目,但其方法基于引用的DPRNN、CFTNet等公开方法。
📌 核心摘要
本文旨在解决人工耳蜗(CI)用户在嘈杂环境中语音感知能力严重受限的问题。为此,作者提出了一种名为DAT-CFTNet的语音增强网络。其核心方法是将一种结合了注意力机制的双路径RNN(DAT-RNN)嵌入到复数值频率变换网络(CFTNet)的瓶颈层中。与基线CFTNet和DCCRN相比,该方法的创新点在于利用DAT-RNN更有效地建模时频表示中的长程依赖和局部特征,并通过注意力机制动态聚焦关键信息。实验在包含多种噪声类型的自建数据集上进行,结果表明,DAT-CFTNet在STOI、PESQ和SISDR等客观指标上均优于基线模型。例如,与未处理语音相比,DAT-CFTNet在STOI、PESQ和SISDR上分别取得了+22.8%,+113.4%,和+10.62 dB的提升;其改进变体DAT-CFTNet-F相比DCCRN和CFTNet,在SISDR上分别实现了+34.3%和+6%的相对提升。该工作的实际意义在于为CI用户提供了一种能更有效抑制非平稳噪声、保持语音清晰度的增强方案。主要局限性在于:1)模型计算复杂度较高,尽管提出了轻量化变体但性能有所下降;2)实验仅使用了IEEE语音库和特定噪声,未在大规模公开基准上进行验证;3)论文未提供针对CI听众的真实心理声学实验或主观听力评估。
🏗️ 模型架构
DAT-CFTNet的整体架构(如图1所示)是一个端到端的时频域语音增强网络,由编码器(Encoder)、解码器(Decoder)和位于两者之间的DAT-RNN瓶颈层组成。其输入为含噪语音的短时傅里叶变换(STFT)谱(复数值),输出为增强后的清洁语音谱,最后通过逆STFT(ISTFT)还原为时域信号。
完整输入输出流程:含噪信号 -> STFT -> 复数编码器(提取特征,降低维度) -> DAT-RNN瓶颈层(建模全局时频依赖) -> 复数解码器(重建语音谱,利用跳跃连接) -> ISTFT -> 增强语音。
主要组件:
- 复数编码器/解码器:采用对称结构,包含多个复数卷积块。每个块使用复数值的2D卷积层提取局部时频模式并降维。编码器中还嵌入了频率变换块(FTB),用于捕获跨频率的全局相关性。解码器对应进行上采样和特征重建,跳跃连接(Skip Blocks)将编码器特征直接传递给解码器,以保留细节信息。
- DAT-RNN瓶颈层:这是本文的核心改进,用于替代CFTNet中的传统GRU单元。它接收编码器输出的降维特征,并对其进行序列建模。如图1(b)所示,其内部包含两个串联的子模块:
- Intra-chunk RNN:使用双向LSTM(Bi-LSTM)处理被分块的时频特征序列。其功能是捕获每个局部“块”内的精细时频模式和动态特性。Bi-LSTM后接一个注意力模块,为块内不同部分分配权重,以突出关键特征。
- Inter-chunk RNN:使用单向LSTM处理所有“块”的聚合信息。其功能是捕获跨越整个时频谱的宏观关系和依赖。同样,其后也接一个注意力模块。
- 注意力模块:接收LSTM/Bi-LSTM层输出的键(Key)和查询(Query)向量,通过计算归一化注意力权重生成上下文向量,并最终产生一个掩码向量(M)。该掩码用于调制原始特征,得到增强后的特征表示。
数据流与交互:编码器特征经层归一化(LN)后进入DAT-RNN,首先被分割为重叠的块。Intra-chunk RNN处理每个块并应用注意力,然后输出传递给Inter-chunk RNN对所有块进行全局处理并再次应用注意力。增强后的特征被传递给解码器进行最终重建。整个设计旨在同时优化局部和全局上下文信息的处理。
💡 核心创新点
注意力增强的双路径RNN(DAT-RNN):
- 是什么:将注意力机制(动态因果注意力)与双路径RNN(DPRNN)相结合,用于语音增强网络的瓶颈层。
- 之前方法的局限:传统RNN(如GRU)在CFTNet中难以有效建模扩展的语音特征序列。DPRNN虽能处理长序列,但缺乏对特征重要性的动态聚焦能力。
- 如何起作用:Intra-chunk Bi-LSTM + 注意力 捕获局部显著特征;Inter-chunk LSTM + 注意力 捕获全局依赖并动态加权。
- 收益:在消融实验中(表2),相比CFTNet+DPRNN,加入注意力(CFTNet+DPRNN+Attn.)使SISDR提升了5.26%,PESQ提升了4.85%,表明注意力机制有效提升了特征表示的质量。
针对人工耳蜗优化的网络设计:
- 是什么:明确将CFTNet架构的改进目标对准人工耳蜗用户的需求,即恢复其仅有约10%的时频听力信息。
- 之前方法的局限:通用语音增强算法(如DCCRN)未针对CI用户的特殊听觉处理机制进行优化。
- 如何起作用:通过更强大的时频表示建模(DAT-RNN + CFTNet),更精确地分离语音和噪声,尤其在低信噪比下。
- 收益:实验表明,模型在嘈杂环境下显著提升了STOI(可懂度)和PESQ(质量),并通过电极图模拟(图2)展示了其在CI模拟信号中保持谐波结构的能力。
轻量化变体(DAT-CFTNet-L):
- 是什么:使用深度可分离卷积(DSC)替代标准卷积,大幅减少模型参数。
- 之前方法的局限:DAT-CFTNet性能好但参数量(12.4M)大,限制了在资源受限设备(如助听器)上的实时应用。
- 如何起作用:DSC将标准卷积分解为深度卷积和逐点卷积,极大降低计算量和参数量。
- 收益:参数从12.4M降至4.7M(约三倍压缩),虽然性能有所下降(如表1所示),但仍优于基线DCCRN,为实际部署提供了可能。
🔬 细节详述
- 训练数据:
- 数据集:使用IEEE语音库(25kHz,后重采样至16kHz)的72个列表(720句),由一男一女朗读。
- 规模与预处理:训练集:1040句(104个列表);验证集:140句(14个列表);测试集:400句。
- 数据增强:从AURORA数据集中选择9种噪声,在-2到14dB的SNR范围内以2dB为步长进行叠加。
- 测试条件:测试集在3种已见噪声(人群、汽车、语音形状噪声)和2种未见噪声(餐厅、火车)下,于-5、0、5dB三个SNR进行评估。
- 损失函数:论文未明确给出损失函数名称,但描述了其组成。总损失为 SISDR损失(LSISDR) 和 基于STFT的损失(LFreq) 的加权和。公式为
Lloss(ŷa, ya) = LSISDR(ŷa, ya) + α · LFreq(ŷa, ya),其中权重因子α设置为25。此设计旨在同时优化信号失真比和频谱重构精度。 - 训练策略:
- 优化器:Adam优化器。
- 学习率:初始学习率为0.0003。
- Batch Size:16。
- 训练轮数:50个epoch。
- 模型选择:在训练阶段保存验证集损失最小的模型。
- 关键超参数:
- STFT参数:帧长32ms,帧移16ms。
- 模型参数量:DAT-CFTNet约为12.4M,DAT-CFTNet-L(使用DSC)约为4.7M。
- 编码器中的FTB数量:在DAT-CFTNet中,每个编码器块后都使用了FTB;在DAT-CFTNet-F变体中,仅在编码器的第一层和最后一层后各放置一个FTB。
- 训练硬件:论文中未提及。
- 推理细节:未提及特殊解码策略或流式设置。
- 正则化或稳定训练技巧:未明确提及除数据增强外的技巧。
📊 实验结果
论文在自建的测试集上进行了评估,主要比较了DAT-CFTNet及其变体与Noisy(未处理)、DCCRN和CFTNet的性能。关键结果如下表所示:
表1:不同网络在三种SNR下的平均客观指标得分
| 模型 | SNR (dB) | PESQ | STOI (%) | SISDR (dB) |
|---|---|---|---|---|
| Noisy | Avg. | 1.12 | 76.00 | -0.01 |
| DCCRN | -5 | 1.38 | 82 | 2.88 |
| 0 | 1.72 | 89 | 7.97 | |
| 5 | 2.11 | 94 | 12.84 | |
| Avg. | 1.74 | 88.33 | 7.90 | |
| CFTNet | -5 | 1.65 | 88 | 5.56 |
| 0 | 2.33 | 93 | 10.36 | |
| 5 | 2.95 | 96 | 14.31 | |
| Avg. | 2.31 | 92.33 | 10.01 | |
| DAT-CFTNet | -5 | 1.73 | 89 | 6.12 |
| 0 | 2.42 | 94 | 10.59 | |
| 5 | 3.01 | 97 | 14.36 | |
| Avg. | 2.39 | 93.33 | 10.36 | |
| DAT-CFTNet-F | -5 | 1.78 | 89 | 6.39 |
| 0 | 2.48 | 94 | 10.88 | |
| 5 | 3.07 | 97 | 14.57 | |
| Avg. | 2.44 | 93.33 | 10.61 | |
| DAT-CFTNet-L | -5 | 1.50 | 86 | 4.27 |
| 0 | 2.08 | 92 | 8.90 | |
| 5 | 2.66 | 96 | 12.86 | |
| Avg. | 2.08 | 91.33 | 8.68 |
主要结论:DAT-CFTNet及其变体在所有SNR和指标上均优于未处理信号和基线DCCRN。DAT-CFTNet-F(改进FTB位置)表现最佳,相比DCCRN,其平均SISDR相对提升了+34.3%,PESQ提升了+5.63%。轻量化的DAT-CFTNet-L性能有所下降,但平均仍优于DCCRN,并与CFTNet相当。
表2:消融研究(各组件贡献)
| 方法 | PESQ | SOPM | STOI | SISDR | LSD | IS |
|---|---|---|---|---|---|---|
| Noisy | 1.12 | 0.74 | 76.00 | 0.002 | 1.92 | 2.40 |
| CFTNet | 2.31 | 0.96 | 93.00 | 10.08 | 0.97 | 0.82 |
| CFTNet + DPRNN | 2.30 | 0.96 | 92.00 | 9.88 | 0.98 | 0.82 |
| CFTNet + DPRNN+ Attn. | 2.39 | 0.96 | 93.00 | 10.36 | 0.92 | 0.81 |
| Mod_CFTNet + DPRNN + Attn. (F) | 2.45 | 0.97 | 93.20 | 10.61 | 0.87 | 0.84 |
| Mod_CFTNet + DPRNN + Attn. + DSC (L) | 2.08 | 0.95 | 91.00 | 8.68 | 0.95 | 1.21 |
消融结论:引入DPRNN替代GRU后,性能有提升。进一步加入注意力机制后,SISDR和PESQ获得明显改善。调整FTB位置(F变体)带来额外提升。使用DSC的L变体参数大幅减少,但多项指标下降,LSD和IS变差。
图2(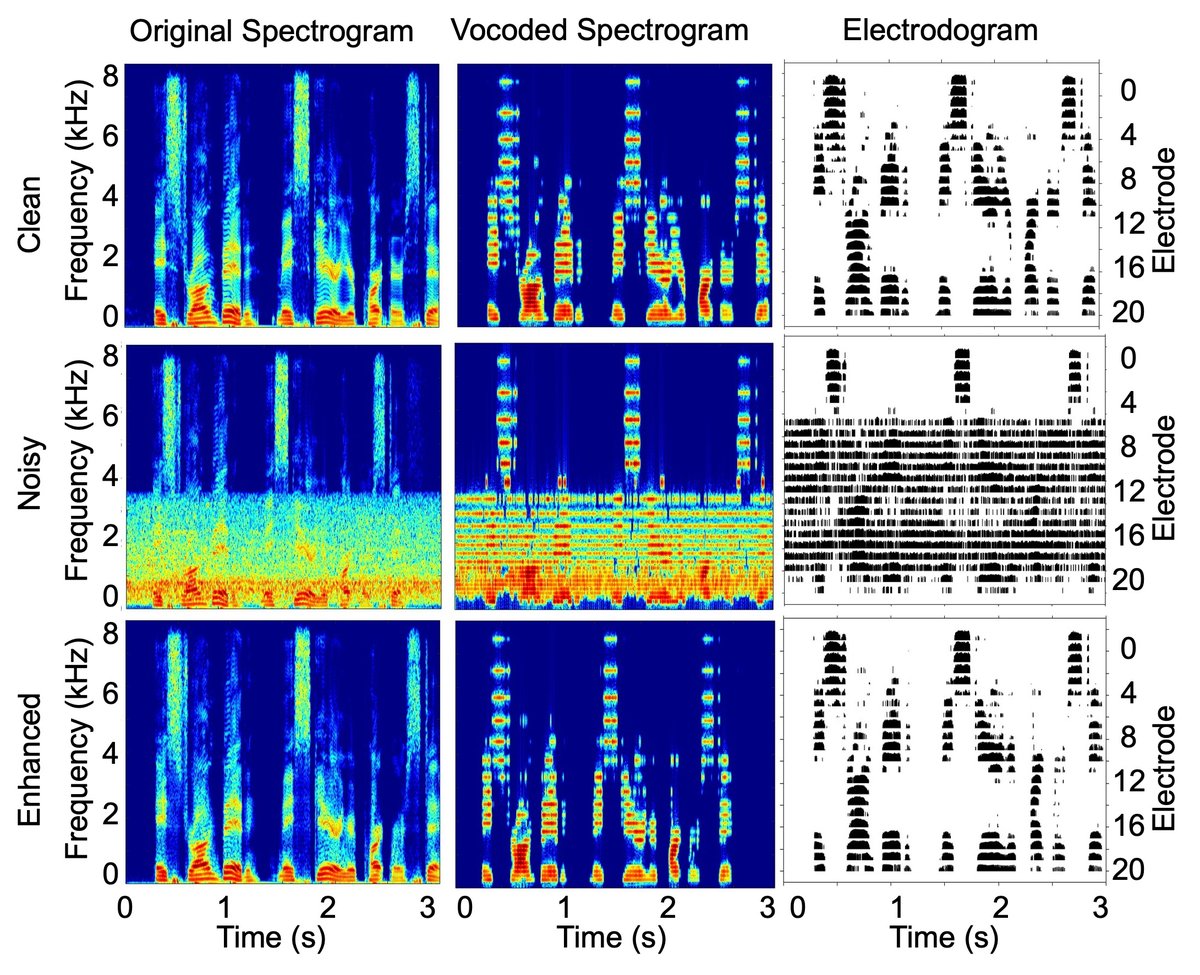)展示了在汽车噪声SNR 0dB条件下,原始、含噪和DAT-CFTNet-F处理后语音的频谱图和人工耳蜗电极图。结果显示,增强后的语音频谱更清晰,电极图保留了清晰的谐波结构,而噪声成分被有效抑制,证明了该方法对CI用户的潜在价值。
⚖️ 评分理由
- 学术质量:5.5/7:论文在工程实现上是完整且正确的,清晰地描述了模型架构、训练细节,并通过充分的消融实验证明了各组件的有效性。然而,其创新点(将Attention、DPRNN与CFTNet结合)属于现有模块的优化集成,在算法原理层面没有重大突破。实验评估仅限于自建数据集,缺乏与业界广泛认可的基准(如VoiceBank-DEMAND)上的SOTA模型对比,削弱了其结论的普适性和说服力。
- 选题价值:1.5/2:选题非常聚焦且有实际意义。语音增强对于改善人工耳蜗用户的生活质量至关重要,是一个值得深入研究且具有社会价值的方向。论文的成果直接针对该需求。
- 开源与复现加成:0.0/1:论文未提供任何代码、模型权重或详细的复现配置。虽然描述了模型结构,但缺乏超参数搜索、数据生成脚本等关键信息,使得完全复现有相当难度。