📄 D3PIA: A Discrete Denoising Diffusion Model for Piano Accompaniment Generation from Lead Sheet
#音乐生成 #扩散模型 #邻域注意力 #钢琴伴奏 #符号音乐生成
✅ 7.5/10 | 前25% | #音乐生成 | #扩散模型 | #邻域注意力 #钢琴伴奏
学术质量 7.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Eunjin Choi(KAIST, Graduate School of Culture Technology)
- 通讯作者:未说明(论文未明确指定通讯作者)
- 作者列表:Eunjin Choi(KAIST, Graduate School of Culture Technology)、Hounsu Kim(KAIST, Graduate School of Culture Technology)、Hayeon Bang(KAIST, Graduate School of Culture Technology)、Taegyun Kwon(KAIST, Graduate School of Culture Technology)、Juhan Nam(KAIST, Graduate School of Culture Technology)
💡 毒舌点评
亮点:巧妙地将离散扩散模型应用于钢琴伴奏生成,结合邻域注意力高效捕捉局部和弦-旋律对齐,在仅2.2M参数下实现了远超基线的和弦保真度与推理速度。短板:彻底放弃了力度(velocity)建模,虽简化了问题但也限制了音乐表现力,且对长程结构与风格多样性的探索不足。
🔗 开源详情
- 代码:论文提供代码仓库链接:https://jech2.github.io/D3PIA/
- 模型权重:论文未明确提及是否公开预训练模型权重,仅提及代码和生成样本公开。
- 数据集:使用公开的POP909数据集,论文中说明了获取和划分方式。
- Demo:论文网页(https://jech2.github.io/D3PIA/)可能包含生成样本演示。
- 复现材料:论文提供了相对详细的训练配置(模型架构细节、超参数、优化器设置、训练时长)和硬件信息,有利于复现。但最终的检查点、附录(如更多实验细节)是否提供未说明。
- 引用的开源项目:论文引用了对比模型(Polyffusion, WSG, FGG, C&E)的相关工作,但D3PIA本身是独立实现。其离散扩散框架参考了D3RM(用于钢琴转录),注意力机制参考了NA和Dilated NA。
📌 核心摘要
这篇论文旨在解决从主旋律谱(Lead Sheet)自动生成符合和弦与旋律约束的钢琴伴奏问题。其核心方法是提出D3PIA,一个基于离散去噪扩散的概率模型,直接在离散化的钢琴卷帘(piano roll)表示上操作。与之前基于连续扩散或Transformer的方法相比,D3PIA的新颖之处在于:1)采用离散扩散处理固有二值化的钢琴卷帘;2)设计了一个基于邻域注意力(NA)的编码器来编码主旋律谱,并用它来条件化解码器,从而有效建模局部对齐关系。实验在POP909数据集上进行,结果表明D3PIA在客观指标(和弦准确率CA=80.1%,和弦相似度CS=93.6%)和主观听感评价上均优于连续扩散(Polyffusion)和Transformer(C&E-E)基线模型,同时模型参数量极小(2.2M)且推理速度快(1.7秒)。该工作的实际意义在于为符号音乐生成提供了一种高效、高保真且易于控制的伴奏生成范式。其主要局限性是未建模音符力度,且仅生成8小节片段,未验证长曲生成能力。
🏗️ 模型架构
D3PIA由一个主旋律谱编码器和一个离散去噪解码器组成,二者共享嵌入层。
- 输入输出流程:
- 输入:一个主旋律谱钢琴卷帘(包含旋律与和弦标签)和一个含噪声的伴奏钢琴卷帘(训练时)。在推理时,仅输入主旋律谱。
- 输出:一个干净的、离散状态的伴奏钢琴卷帘(包含onset, off, sustain, MASK四种状态)。
- 主要组件与数据流:
- 主旋律谱编码器:接收主旋律谱钢琴卷帘。其内部首先经过一个音高方向的双向LSTM,用于捕捉每个音高上的时间过渡。随后,通过一系列NA 2D自注意力模块,该模块能高效地关注局部区域(由扩张邻域注意力定义),从而捕获旋律与和弦之间的垂直(和声)与水平(节奏)对齐关系。编码器的输出特征(图1中深绿色部分)被用于条件化生成过程。
- 离散去噪解码器:接收噪声伴奏钢琴卷帘,并将其与编码器的输出特征在通道维度进行拼接。解码器结构与编码器类似(包含双向LSTM和NA 2D自注意力),但关键区别在于它整合了自适应层归一化(AdaLN),以注入扩散时间步信息(τ)。解码器的任务是预测在当前时间步τ下,每个钢琴卷帘像素的干净离散状态概率分布。
- 数据流:主旋律谱 → 编码器 → 局部对齐特征 → 与噪声伴奏拼接 → 解码器 → 预测的干净伴奏状态分布。
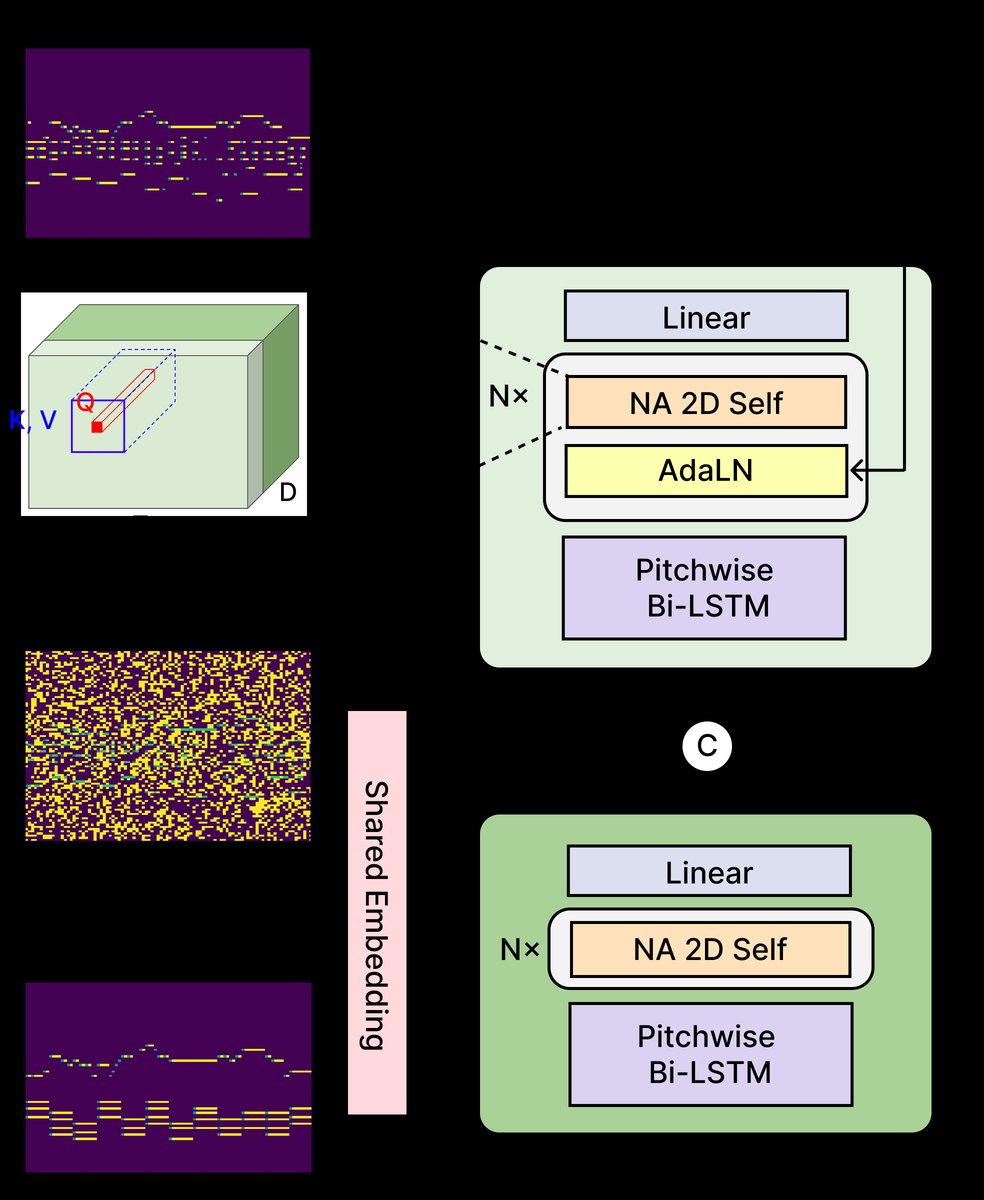
图1清晰地展示了上述流程。左侧是主旋律谱编码器,其输出(深绿色)与中间的噪声钢琴卷帘(浅绿色)拼接(C)后,送入右侧的去噪解码器。两个模块内部都包含NA层(由τ标记的NA 2D Self模块),这确保了模型能关注到主旋律谱与伴奏之间的局部对应关系。解码器独有的AdaLN层使其能适应不同的扩散时间步。
- 关键设计选择与动机:
- 离散表示与扩散:动机是钢琴卷帘本质上是离散的(音符开/关),离散扩散比连续扩散更自然地处理插入、删除等编辑操作,避免了连续扩散可能产生的非物理中间状态。
- 邻域注意力(NA):动机是伴奏生成严重依赖于主旋律谱的局部上下文(如当前小节的旋律与和弦)。NA比标准自注意力计算更高效,且通过扩张率可控制感受野大小,非常适合建模这种局部对齐关系。
- 编码器-解码器结构:明确地将主旋律谱的编码与伴奏的生成解耦,使条件信息(和弦、旋律)被显式、充分地提取并用于指导生成。
💡 核心创新点
- 将离散扩散模型系统地应用于钢琴伴奏生成:之前音乐领域的离散扩散工作较少,且多用于转录或潜在空间。D3PIA首次在钢琴卷帘的离散像素状态上应用离散扩散,并证明了其在生成任务上优于连续扩散基线。这验证了离散扩散在符号音乐生成中的有效性。
- 基于邻域注意力(NA)的局部对齐编码-条件化机制:创新性地设计了一个NA编码器来显式建模主旋律谱与伴奏之间的局部关系,并用其输出来条件化解码器。这比简单的拼接或全局注意力更高效、更具针对性,是模型取得高性能的关键。
- 吸收状态(AS)采样的引入:将原本用于判别性任务(如转录)的AS采样策略引入生成式扩散模型。在推理时设置βt=0,强化了模型“修正”和“细化”音符状态的能力,从而生成更连贯、更符合和弦约束的伴奏。消融实验证明了其对和弦相似度(CS)的显著提升。
🔬 细节详述
- 训练数据:使用公开的POP909数据集,包含909首中文流行歌曲的MIDI文件。按8:1:1比例划分训练/验证/测试集。训练时随机裁剪为8小节片段,并进行-5到+6半音的随机移调增强。测试时使用整个测试集(86首歌,被切分为905个8小节片段进行评估)。
- 损失函数:采用变分下界(VLB)损失,如公式(2)所示。包含两项:一项是最终加噪状态与先验分布的KL散度,另一项是从t到1各步的去噪分布与模型预测分布之间的KL散度。此外,使用了一个辅助损失(权重λ=5.0e-4),论文中未详细说明其具体形式,可能用于稳定训练。
- 训练策略:优化器为AdamW(β=(0.9, 0.96))。初始学习率为1e-3,采用学习率衰减策略:当验证集扩散损失连续25k步不下降时,学习率乘以0.8。训练200k步,batch size为8。
- 关键超参数:扩散时间步长T=100。模型嵌入维度d未明确说明(论文仅说每个状态表示为4维向量)。解码器层数N=10。扩张邻域注意力的窗口大小为5,扩张率序列[1, 2, 4, 8, 16, 1, 2, 4, 8, 16]以扩大感受野。模型总参数量为2.2M。
- 训练硬件:在单张NVIDIA A6000 GPU上训练。
- 推理细节:采用迭代去噪采样。论文特别指出,为增强细化能力,在所有扩散时间步t都设置βt=0(即吸收状态采样),最终从纯MASK状态开始去噪生成。推理时间约为1.7秒(生成一个8小节片段)。
- 正则化/稳定训练技巧:除了学习率衰减和辅助损失,论文未提及使用Dropout等其他明确正则化技巧。
📊 实验结果
主要对比实验(表2): 论文在POP909测试集上与多个基线模型(连续扩散:Polyffusion, WSG-4th, FGG;Transformer:C&E-E)进行了对比。
| 模型 | 参数量 | 推理时间(秒) | OOK (%) (↓) | CA (%) (↑) | CS (%) (↑) | GS (%) (↑) |
|---|---|---|---|---|---|---|
| GT (真实数据) | - | - | 0.0 | 91.6 | 95.7 | 82.7 |
| Polyffusion | 41.1M | 21.4 | 0.0 | 37.5 | 54.0 | 79.9 |
| C&E-E | 66.0M | 18.7 | 14.8 | 58.1 | 70.6 | 80.8 |
| D3PIA (本文) | 2.2M | 1.7 | 0.0 | 80.1 | 93.6 | 82.1 |
| WSG-4th* | 41.6M | 79.0 | 2.4 | 87.6 | 94.6 | 75.4 |
| FGG* | 36.7M | 0.4 | 0.0 | 62.0 | 77.3 | 78.9 |
*注:WSG-4th和FGG需要额外输入(如歌曲结构、onset信息),故不完全公平比较。
关键结论:
- 和弦一致性:D3PIA的CA(80.1%)和CS(93.6%)远高于主要对比模型Polyffusion和C&E-E,且CS值接近真实数据(95.7%),说明其生成的伴奏在和声上高度忠实于给定的和弦条件。OOK为0%,无走调音符。
- 节奏一致性:D3PIA的GS(82.1%)最高,甚至略超真实数据参考值,表明其生成的节奏模式非常稳定和一致。
- 效率:D3PIA参数量极小(2.2M),推理速度极快(1.7秒),远快于大多数基线。
主观听感评估(图2): 13位具有音乐背景的参与者对10个随机样本进行了5分制评分。结果显示,D3PIA在和谐度(Harmony)、一致性(Consistency)、正确性(Correctness)和整体质量(Overall) 四个维度上均获得最高分,显著优于Polyffusion和C&E-E。值得注意的是,WSG-4th虽然客观CA/CS很高,但在主观“和谐度”上得分低于D3PIA,论文分析指出其生成了一些不协和音符(与较高的OOK值一致),这严重影响了听感。
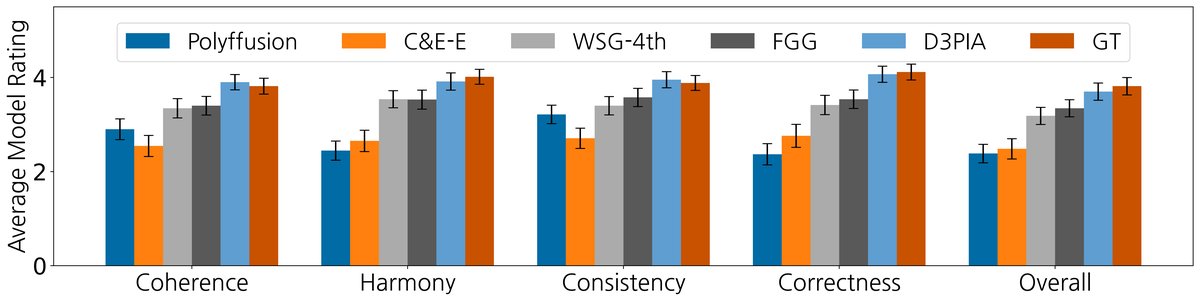 图2显示了主观评分的平均分与95%置信区间。D3PIA(蓝色)在所有维度上均处于顶部,且置信区间不与基线模型(如Polyffusion, C&E-E)重叠,证明了其统计显著的优势。
图2显示了主观评分的平均分与95%置信区间。D3PIA(蓝色)在所有维度上均处于顶部,且置信区间不与基线模型(如Polyffusion, C&E-E)重叠,证明了其统计显著的优势。
消融实验(表3):
| 模型变体 | CA (%) | CS (%) | GS (%) |
|---|---|---|---|
| original D3RM decoder | 79.9 | 78.0 | 74.9 |
| D3RM decoder w/ scale-up | 79.8 | 78.0 | 77.1 |
| D3PIA w/o chord in encoder | 35.9 | 59.2 | 83.9 |
| D3PIA w/o AS sampling | 76.8 | 77.2 | 79.6 |
| D3PIA (full) | 80.1 | 93.6 | 82.1 |
关键结论:
- NA编码器的作用:移除编码器中的和弦输入(w/o chord)导致CS暴跌至59.2%,证明了显式和弦条件编码的关键性。
- 吸收状态采样的作用:移除AS采样(w/o AS)使CS下降约16.4%(从93.6%到77.2%),表明其对生成高质量、细化的和弦音符至关重要。
- 模型扩展的作用:仅使用原始D3RM解码器(小模型)即可达到不错的CA/CS(约80%),但扩展后模型在节奏一致性(GS)上有所提升,且完整的D3PIA架构在所有指标上达到最优。
⚖️ 评分理由
- 学术质量:5.5/7
- 创新性:中等偏上。将离散扩散与邻域注意力结合用于钢琴伴奏生成,思路清晰,针对性设计有效。吸收状态采样的迁移应用也是亮点。
- 技术正确性:高。模型设计合理,理论依据(离散性、局部性)充分,实验验证了设计选择的有效性。
- 实验充分性:中等。对比了多个相关基线(连续扩散、Transformer),进行了充分的客观和主观评估,并有深入的消融实验。但未能与更多最新模型(如GETMusic)对比,且仅评估8小节片段。
- 证据可信度:高。实验设置公平(重新训练所有模型),评估指标全面,消融实验清晰展示了各组件贡献,主观测试有专业参与者。
- 选题价值:1.5/2
- 前沿性:中等。钢琴伴奏生成是音乐AI中的经典且重要的任务,离散扩散在符号音乐中的应用是当前的研究方向之一。
- 潜在影响与应用空间:较高。高效、可控的钢琴伴奏生成有直接应用价值(如辅助作曲、教育)。提出的离散扩散+NA框架可能启发其他符号音乐生成任务。
- 与音频/语音读者相关性:中等。属于音乐生成子领域,与核心语音任务(如ASR, TTS)关联度一般,但对更广泛的音频生成/理解社区有参考意义。
- 开源与复现加成:0.5/1
- 代码与模型:论文明确提供了代码仓库链接(https://jech2.github.io/D3PIA/),并声明模型训练代码和生成样本公开。
- 复现细节:提供了详细的模型配置(层数、NA窗口、优化器、学习率调度等)、训练硬件(A6000)和超参数。
- 数据集:使用公开的POP909数据集,并说明了具体划分和增强方法。
- 不足:未提及提供预训练模型权重。虽然提供了代码链接,但“复现”仍需自行训练模型,存在一定门槛。